目錄
動態可視化展示
專案介紹
專案引入
專案資源
代碼案例
國家社科基金專案資料庫資源挖掘
資料可視化代碼合集
專案類別占比分析
專案總結
每文一語
動態可視化展示
看完記得點個贊喲!
國家社科基金專案資料庫挖掘與分析
專案介紹
專案引入
我們發現在日常的生活中,總是有很多的繁瑣的事情,但是又不知道如何去改善和解解壓,小王在這里給大家提一個小小的建議:多聽聽音樂,可能就是不一樣的心情啦,生活不只有眼前的茍且,還要有未來的詩和遠方,
前期我寫一個《Python爬取全網文字并詞云分析(全程一鍵化!)》在文末提到了一個網站,也就是國家社科基金專案資料庫,最近又有小伙伴來找我,問我可不可以獲取一些資料,進行可視化分析,這樣就可以確定研究的相關的方向,之前只是有詞云展示,僅僅對標題進行可視化研究,聽完她的建議,感覺確實不錯,那么要做就要做最好的,我準備把這個資料庫里面的全部抓取出來,做宏觀的可視化研究,這里只是做一個案例展示,當然你也可以根據你要選擇的方向來進行資料分析和可視化,代碼是智能的,只需要輸入相關的引數即可,

國家社科基金專案資料庫可以用來查詢,當然是查詢了,不過具體的用處我相信需要這個的小伙伴肯定比我要內行,下面我們來看看這個里面的資料吧,資料太多干脆全部爬取下來,要是一頁一頁的復制,不知道要做到猴年馬月,用Python爬取也就20多分鐘而已,資料量總共100000條左右,主要維度太多,手動是不可能的,不然怎么說Python是神器了,哈哈哈,
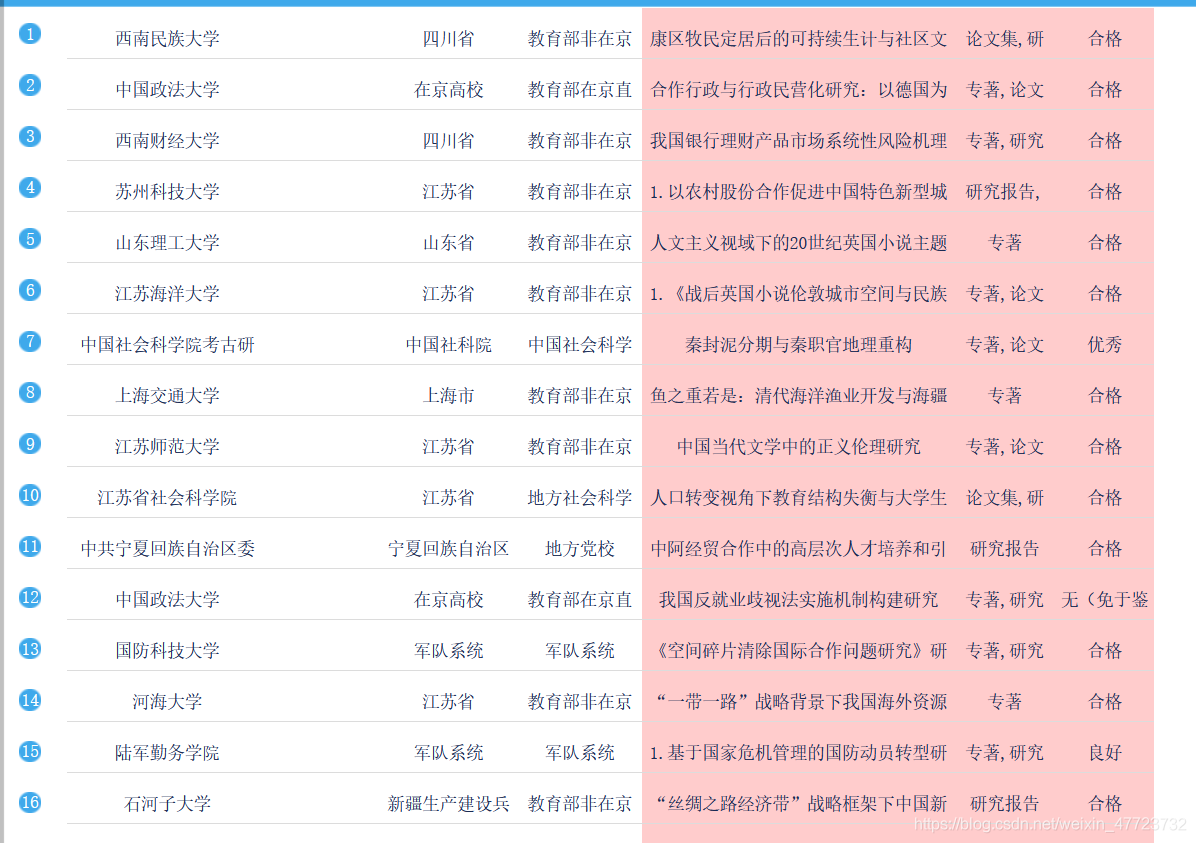
專案資源
資源資料點擊這里下載
代碼資源合集點擊此處下載
代碼案例
國家社科基金專案資料庫資源挖掘
首先匯入需要的第三方庫,這里有很多新的知識,比如模擬點擊可以制約反爬,請求頭的隨機產生,延時請求等模板塊,
import requests
from lxml import etree
from fake_useragent import UserAgent
import pandas as pd
from urllib.parse import quote
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
然后通過網路爬蟲定位資料標簽,這里有點不大合適的就是,因為那個資料庫里面是定期更新的,有很多的專案還沒有一些固定的值,所有我們在爬取的時候需要做到把沒有資料的值,變換為None,也要寫入到CSV檔案,這樣才是正確的資料,
比如我采用此方法定位
text_1 = html_.xpath('//div[@class="jc_a"]//tr//td[1]/span')
get_info['專案批準號'] = text_1[index].text做好資料定位了,我們就需要把資料進行存盤,這里給代碼
df = pd.DataFrame(get_info_list) # 寫入到pd里面,賦給df
if count == 0:
df.to_csv('{}.csv'.format(title), mode='a+', index=False, encoding='utf-8')
print("第1頁資料寫入!!!") # 寫入第一行表頭加資料,表頭默認
count += 1
get_info_list.clear()
else:
df.to_csv('{}.csv'.format(title), mode='a+', index=False, header=False, encoding='utf-8')
a += 1 # 寫入后面的其他資料,不寫入資料表頭,所以為False
print("第{}頁資料寫入!!!".format(a))
get_info_list.clear()需要注意的是,這里的資料量是比較大的,我們不要按照傳統的固定模式,把資料存在串列記憶體里面,然后一下全部寫入,雖然也可以,但是我不建議你這樣做,按照一次一頁資料就寫入,這樣耗損的資源也較少,代碼的優化型也還不錯,
主函式
if __name__ == '__main__':
print("\t\t\t如果想要使用默認引數輸入0即可!")
title = input("請輸入儲存資料的路徑及名稱如桌面:C:\\Users\\48125\\Desktop\\\n")
xmname = input("請輸入專案名稱:")
xmtype = input("請輸入專案類別:")
xktpye = input("請輸入學科類別:")
times = input("請輸入立項時間:")
xmtype1 = quote(xmtype, 'utf-8')
xktpye1 = quote(xktpye, 'utf-8')
xmname = quote(xmname, 'utf-8')
url = ("http://fz.people.com.cn/skygb/sk/index.php/index/seach/?" \
"pznum=&xmtype={}" \
"&xktype={}" \
"&xmname={}&lxtime={}" \
"&xmleader=&zyzw=0&gzdw=&dwtype=0&szdq=0&ssxt=0&cgname=&cgxs=0&cglevel=0&jxdata=0&" \
"jxnum=&cbs=&cbdate=0&zz=&hj=".format(xmtype1, xktpye1, xmname, times))
page = dj(url)
print("該種類一共有{}頁數資料".format(page))
pages = int(input("請輸入你要爬取的頁數:"))
Data(title, pages, xmtype, xktpye, xmname, times)
還記得之前的文章里面需要我們去瀏覽器手動點擊一下末頁,看看有多少也頁數,然后輸入,這次的程式升級了,采用模擬點擊的方法自動獲取頁數,當然是模擬人操作瀏覽器點擊末頁,這樣是比較方便的,而且在一些反爬措施,模擬簡單也是可選的一個利器,但是各有各的好處與局限性,模擬點擊相對于直接請求網頁的速度要慢一點,如果是做資料采集的話,就不是最優的選擇了,這就需要我們去開啟另一扇大門了,
部門代碼如下
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get(url) # 打開網頁
# driver.maximize_window() #最大化視窗
time.sleep(2) # 加載等待學而不思則罔,思而不學則殆,其他的留給你自己思考喲!
資料可視化代碼合集
如果說做資料可視化我最先選擇的是pyecharts,當然這也要看具體的商業場景,如果有興趣的小伙伴可以移步到我的Python繪制柱狀圖之可視化神器pyecharts(一)
資料可視化之美專欄一起探索資料可視化的美感和魅力!
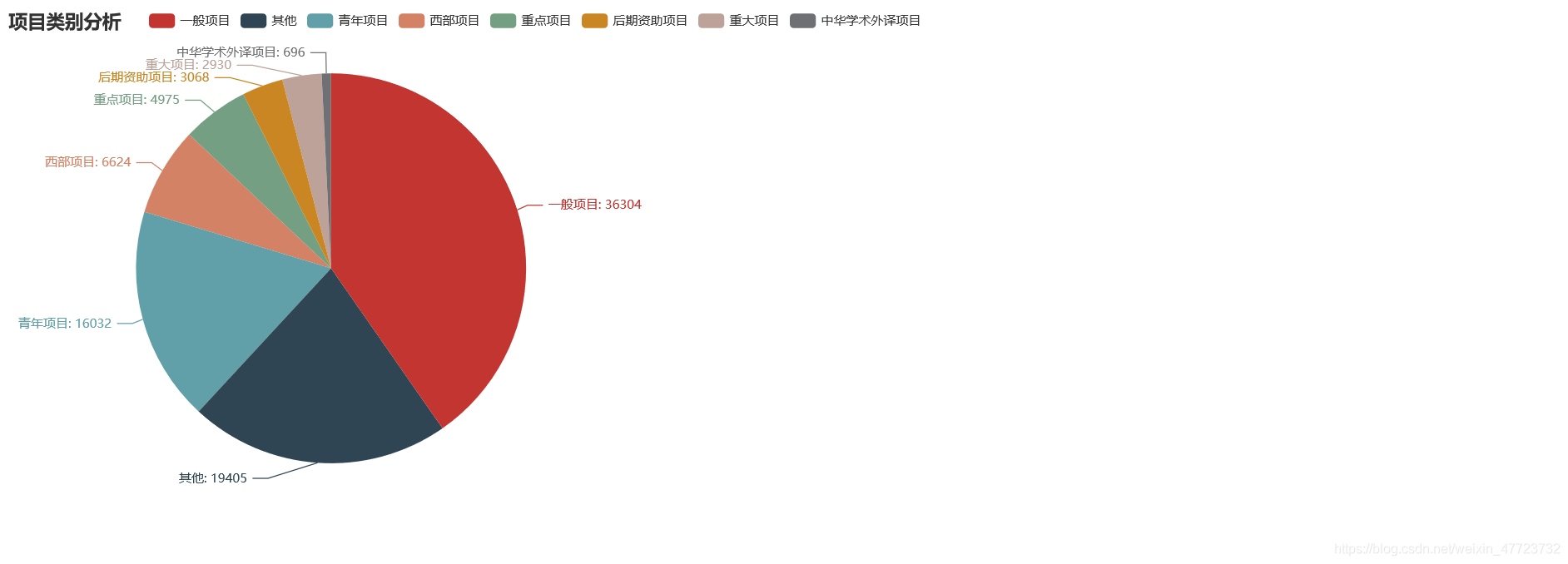
專案類別占比分析
from pyecharts import options as opts
from pyecharts.charts import Pie
import pymysql
conn = pymysql.connect(
host='localhost',
user='root',
password='2211',
database='科研專案',
port=3306,
charset='utf8'
)
cur = conn.cursor()
sql = "select `專案類別`,COUNT(*) as `數量` from `data` GROUP BY `專案類別` ORDER BY `數量` DESC LIMIT 8;"
cur.execute(sql)
data = cur.fetchall()
x=[]
y=[]
for i in list(data):
if i[0]==None:
x.append("其他")
y.append(i[1])
else:
x.append(i[0])
y.append(i[1])
print(x)
print(y)
c = (
Pie()
.add(
"",
[list(z) for z in zip(x, y)],
center=["35%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="專案類別分析"),
legend_opts=opts.LegendOpts(pos_left="15%"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("專案類別占比分析.html")
)
import pyecharts.options as opts
from pyecharts.charts import Line
import pymysql
conn = pymysql.connect(
host='localhost',
user='root',
password='2211',
database='科研專案',
port=3306,
charset='utf8'
)
cur = conn.cursor()
sql = "select `立項時間`,COUNT(*) as `數量` from `data` GROUP BY `立項時間` ORDER BY `立項時間`;"
cur.execute(sql)
data = cur.fetchall()
x=[]
y=[]
for i in list(data):
if i[0]==None:
print(None)
else:
x.append(i[0])
y.append(i[1])
print(x)
print(y)
def line_base():
c = (
Line(init_opts=opts.InitOpts(width="1400px", height="600px")) # 畫布大小
.add_xaxis(x) # 添加x軸
.add_yaxis('立項時間', y, is_symbol_show=False, color=['green']) # 添加第一個y軸
.set_global_opts(
title_opts=opts.TitleOpts(title='國家社科基金專案', subtitle="立項時間追蹤"),
# 設定x軸的label字體的走向,由于x軸過多,顯示不全,在這調整旋轉角度
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90)),
# 下面這是調整是否可以縮放的
datazoom_opts=opts.DataZoomOpts(is_show=True),
)
)
return c
# 生成html檔案, 或者在jupyter 里面直接出圖
line_base().render("立項時間追蹤折線圖.html") 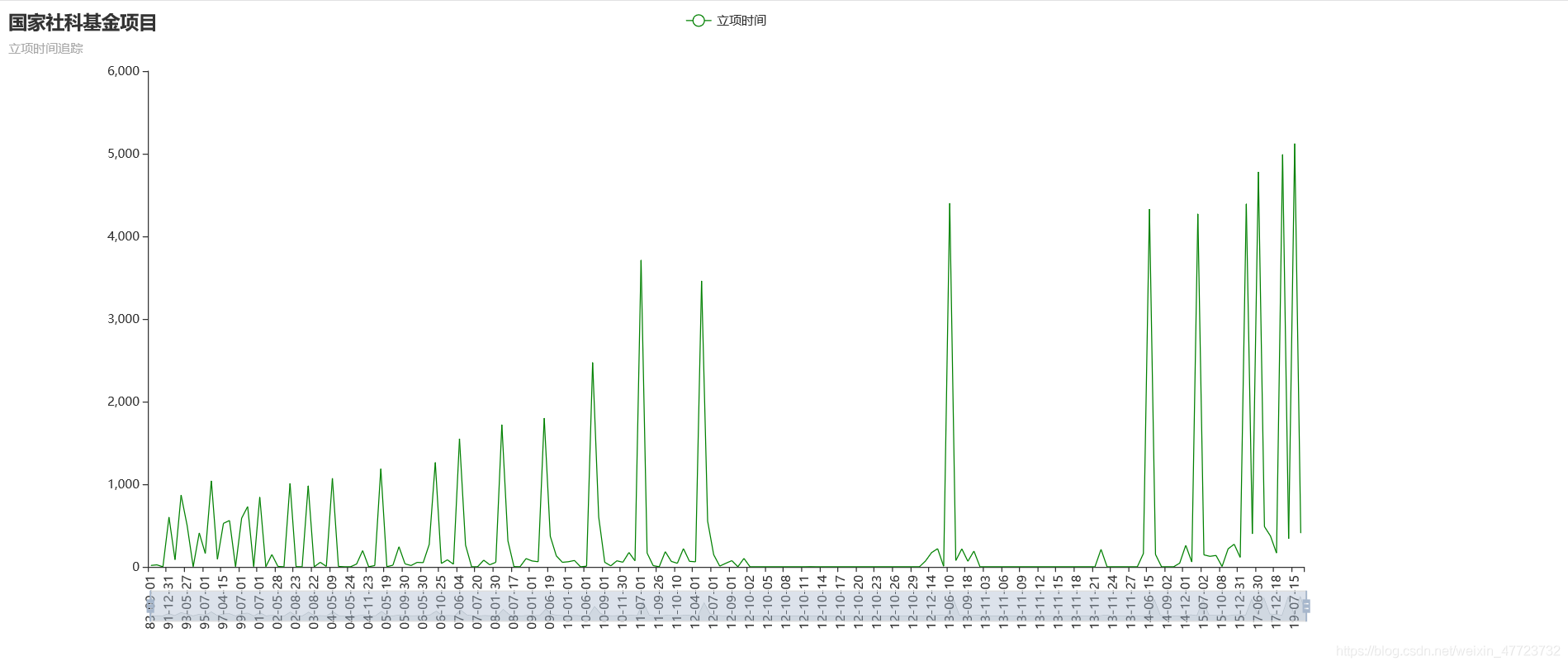
其他的代碼我就不做展示了,如果有需要可點擊這里下載
直接展示相關可視化圖例
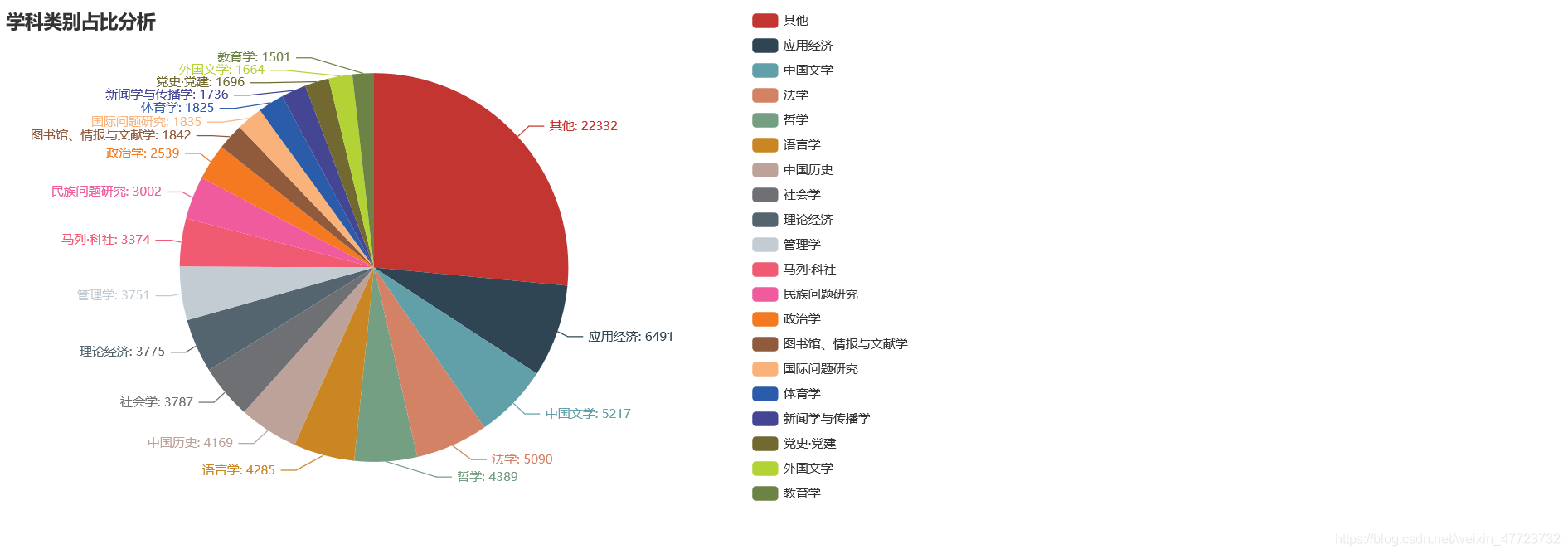
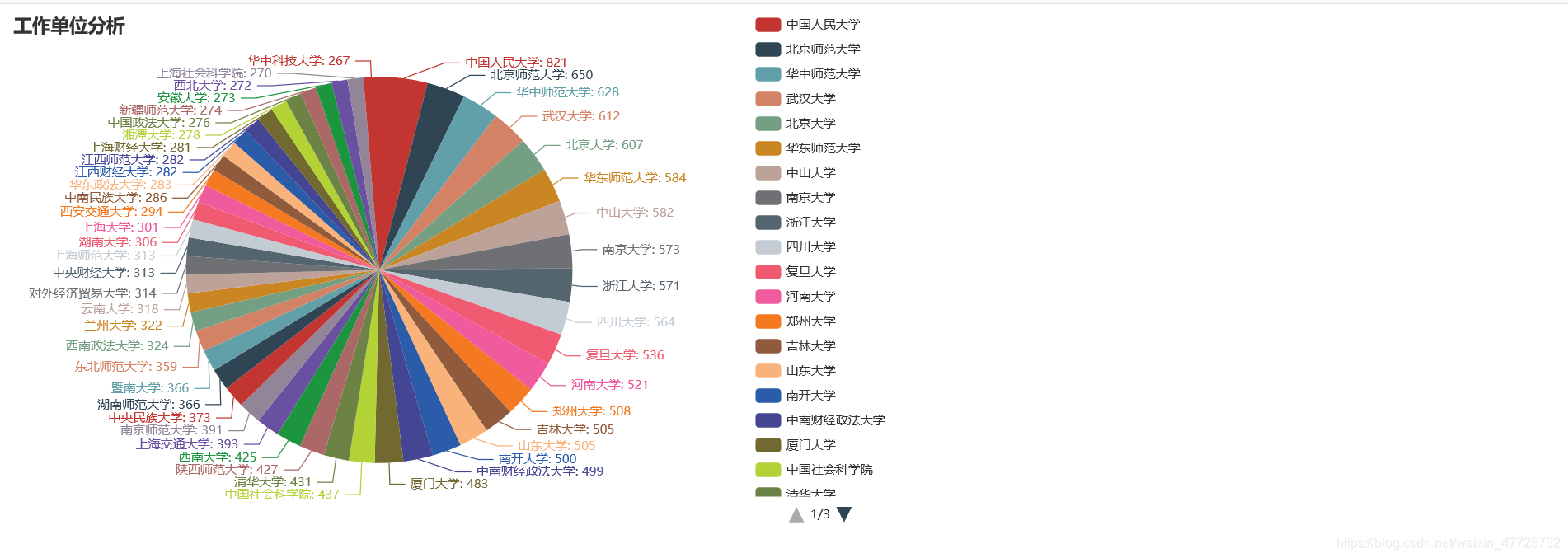
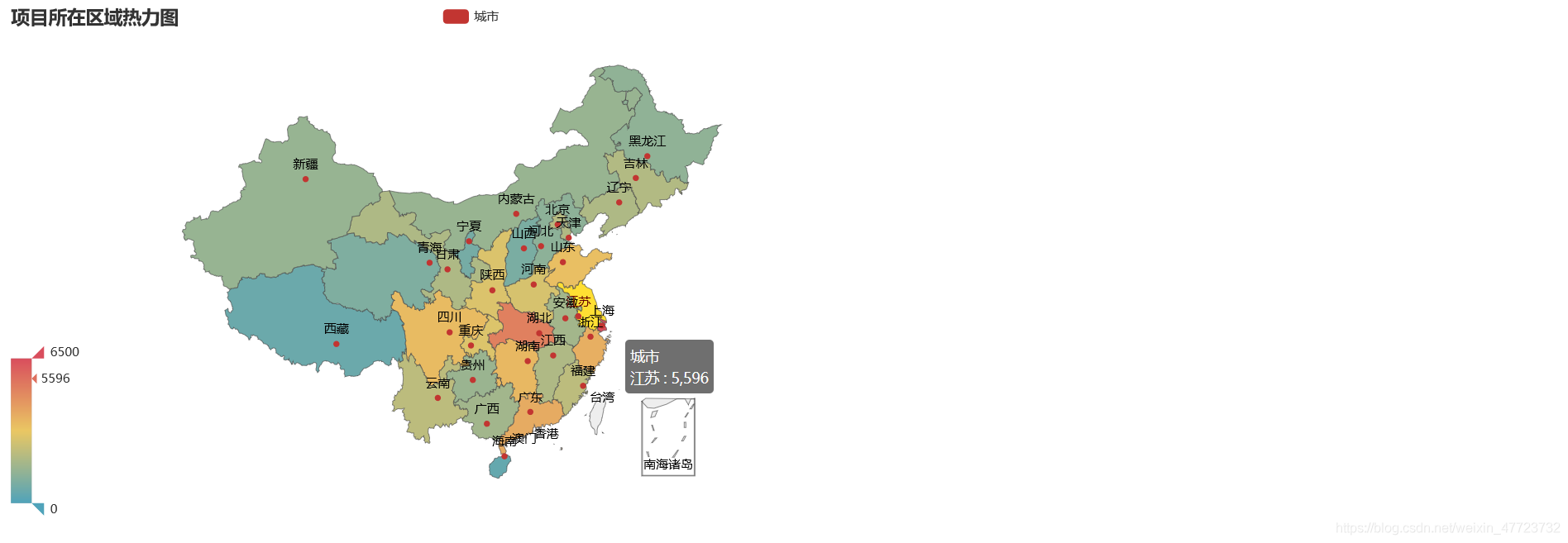
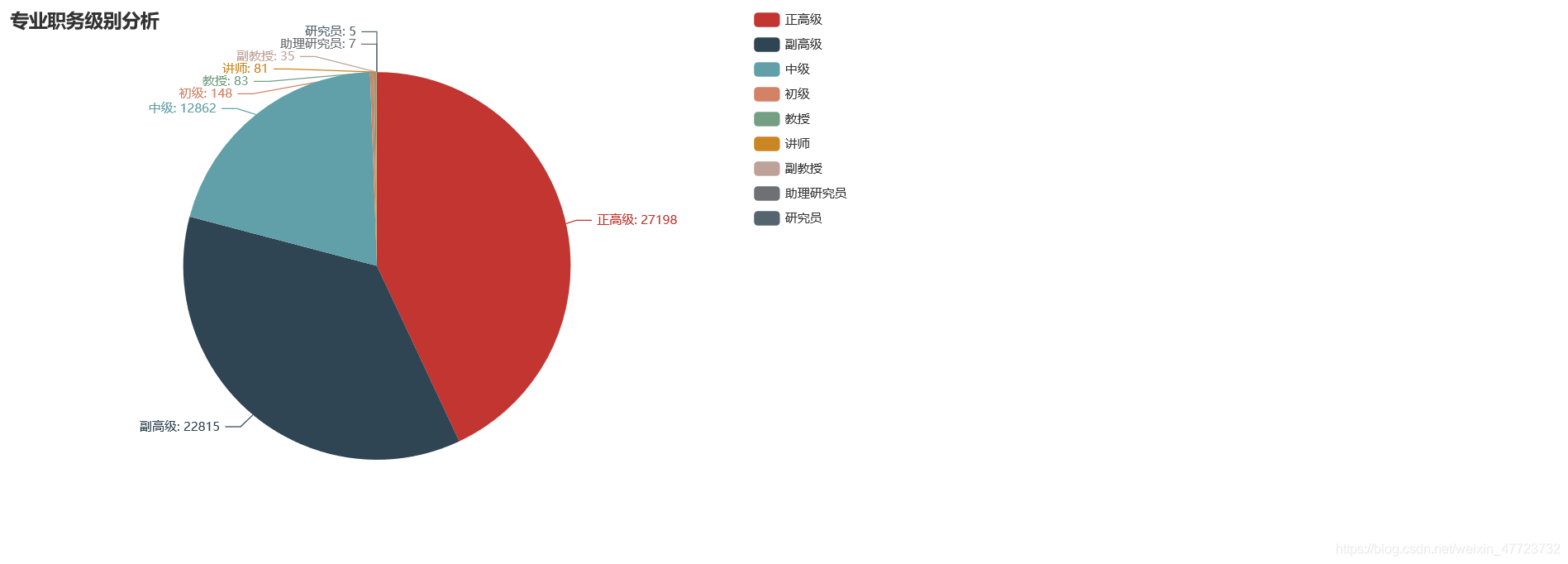
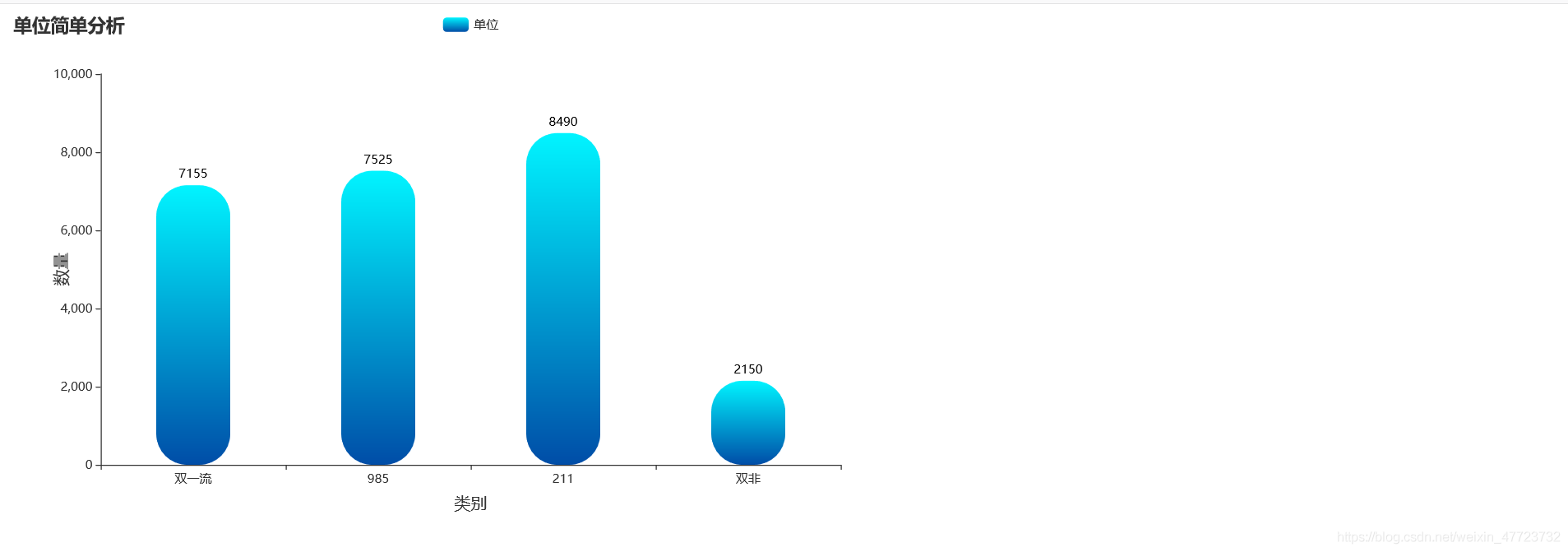
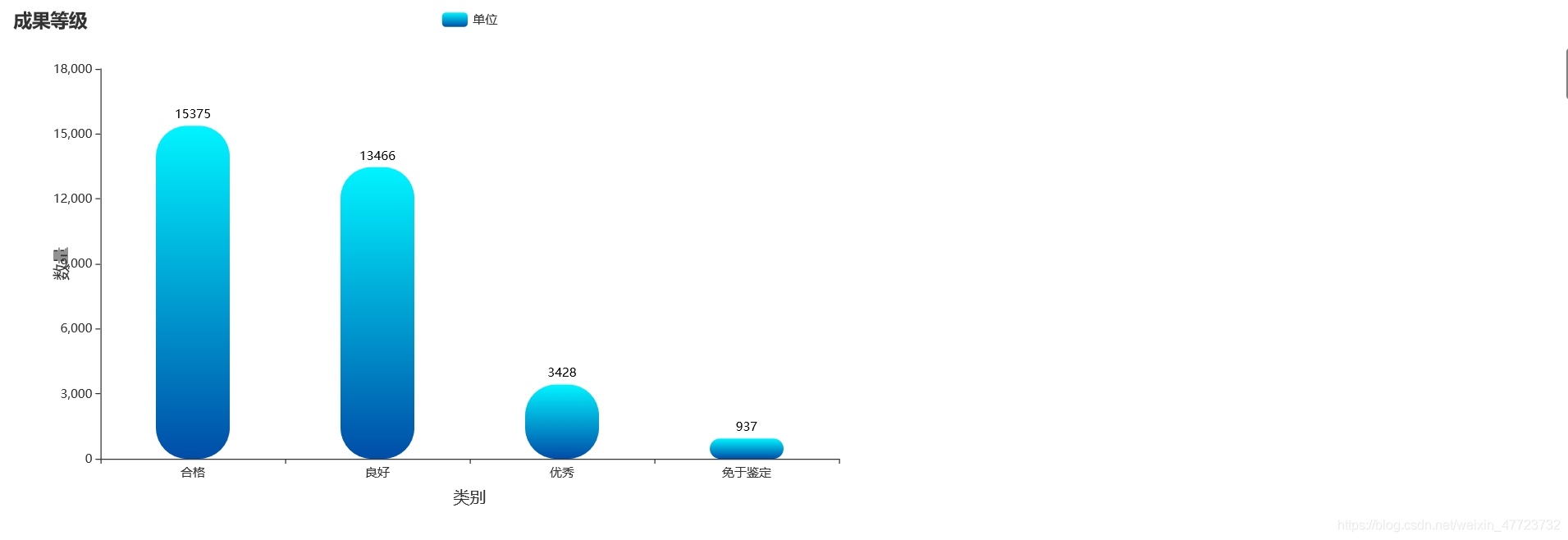
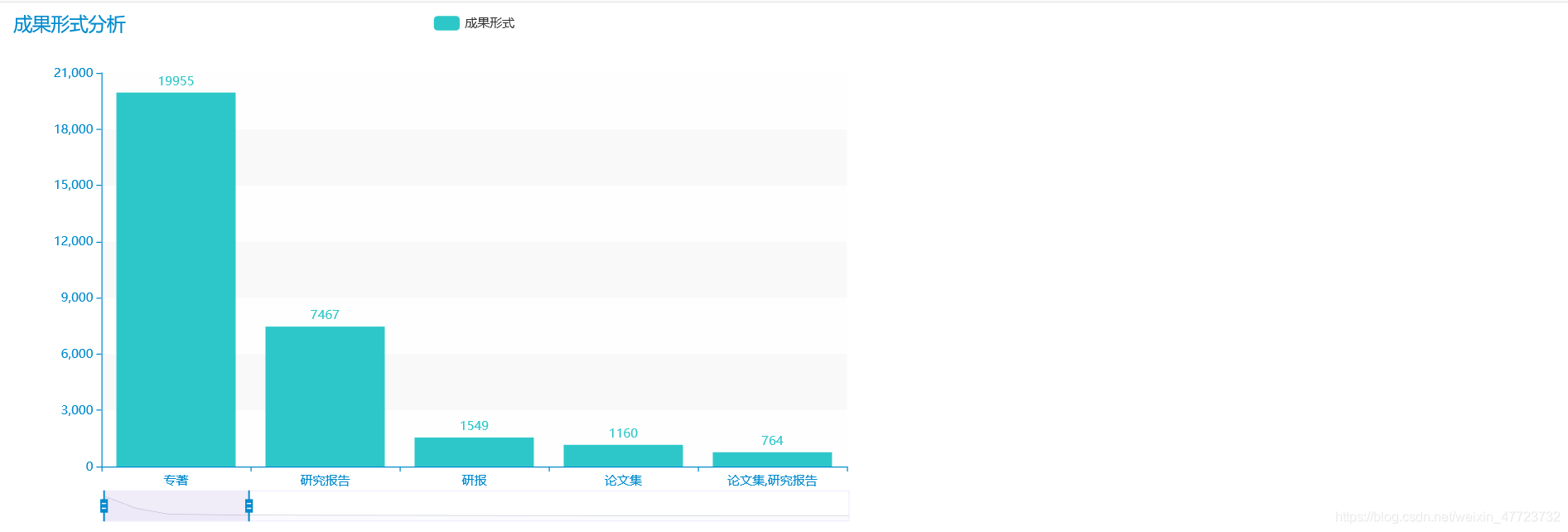
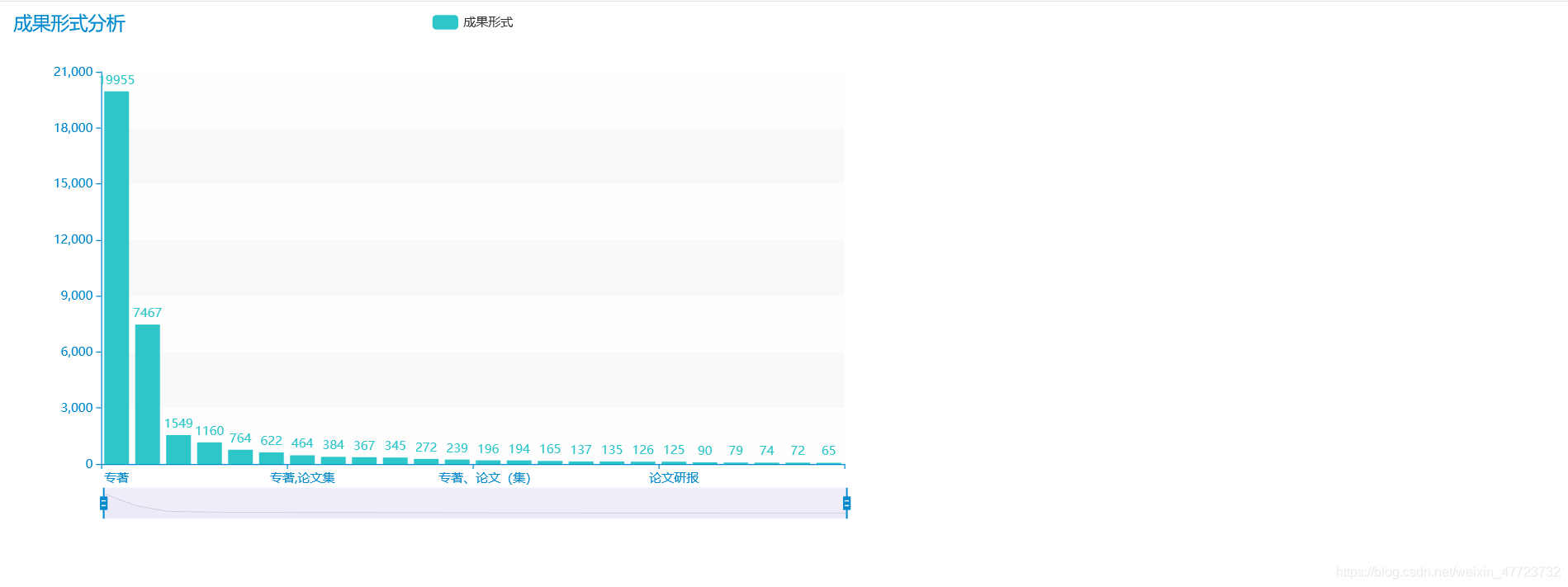
專案總結
1.采用智能的引數提示爬取需要的資料資訊
2.炫酷可視化之pyecharts
3.模擬點擊之selenium
4.Python底層原生態代碼設計
5.資料庫之MySQL
6.視頻動態展示
每文一語
謀大事者必先布大局
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/262090.html
標籤:其他
上一篇:單鏈表的增刪查改