- rabbitmq
- rabbitmq的訊息可靠性
- rabbitmq-冪等引出的性能分析
- rocketmq
- 從rabbitmq到rocketmq
- kafka
- 從rocketmq到kafka:集群、一致性與重平衡
- pulsar
- 本篇
- 綜合對比
- 本篇
先來談談 pulsar
pulsar 可以簡單的看做是 broker 集群 + bookkeeper集群 構成,broker 集群屬于無狀態集群,只處理業務邏輯;而 bookkeeper 集群屬于有狀態集群,負責處理資料存盤,
這樣的組合和我們平時的開發多么相似,無狀態(業務)服務負責執行業務邏輯,有狀態資料存盤負責持久化資料,
那么,從這個角度理解,最起碼我們對 pulsar 中為什么需要 broker 有了認識,最復雜的部分還是在于 bookkeeper,bookkeeper是什么呢?
A scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads
pulsar 為什么選擇 bookkeeper?對應我們日常開發中的存盤方案選型,說明 bookkeeper 的某些特性非常適合pulsar定位的功能場景,至于特性是什么,在最后會推薦相關文章,
其實同理,當我們自研一款訊息佇列時,我們甚至可以用mysql來實作訊息存盤,為什么可以選擇mysql呢?
前面已經學過,innodb也是順序寫入,支持WAL,innodb中也存在 Buffer Pool,可以批量快取訊息,并且訊息本身不更新,總之,這些特性不會對性能造成太大影響,
而且可以將mysql單表看做是一個磁區(佇列),每個topic可以對應多張表,則這樣也可以支持業務服務實作佇列模型和發布-訂閱模型,
經過這樣的對比,現在我們就可以把關注點放到 bookkeeper,
bookkeeper是有狀態服務,并且可以集群化,那么必然涉及到兩個關鍵點:
-
資料寫入磁盤的形式,以及資料存盤形式
-
集群資料同步時,與CAP理論的博弈
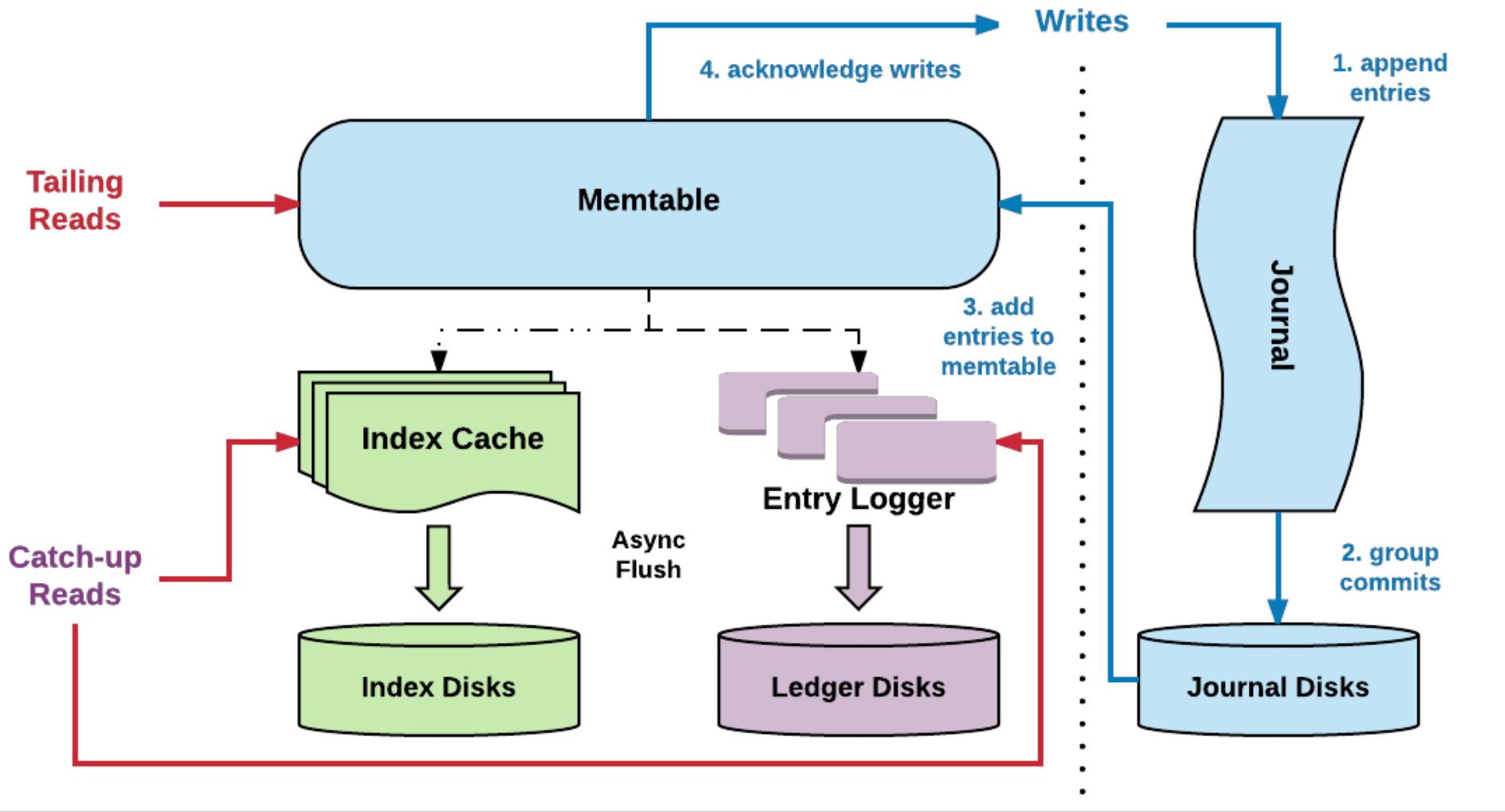
我們先來看單機bookkeeper,也就是 bookie,如上圖(引自Pulsar-Cloud Native Messaging & Streaming),先看藍色部分,總共四個步驟:
-
append entries(追加):順序寫入,類似mysql的日志寫入
-
組提交:類似mysql中的組提交機制,bookie將資料寫入磁盤同樣采用同步刷盤機制,所以為了避免高并發寫入時刷盤機制的影響,故可以利用組提交機制優化效果
-
寫入快取:類似Buffer Pool
-
回應給客戶端:所以客戶端收到成功ack,表示bookie的資料已經寫入了磁盤
針對讀取的執行路徑:
-
快取中資料會定期刷盤存盤,存盤前會進行排序等預處理,
-
并且同時增加一個索引存盤,思想也類似于rocketmq中commitlog,
通過這樣的設計實作了讀寫分離,接著看一下集群資料同步的設計,
在我們之前看過的raft等協議中,通常是領導者模型,只有領導者負責寫入,這樣的好處是避免并發寫,將偏序變成了全序,但是缺點是領導者容易成為瓶頸,不過我們可以通過構建多個raft小集群的方式來緩解領導者壓力,
而在 bookkeeper 中,在資料之上,又抽象出了 ledger 這個邏輯存盤單元,那么顯然的,一個 ledger對應的是多個資料條目,而這些資料條目可以來自于不同的 bookie,
ledger帶來兩大影響:
首先對于客戶端來說(實際就是 pulsar 的broker),不關心資料實際如何存盤,只關心和 ledger 的互動,
其次對于資料來說,被邏輯地劃分為多個 ledger,所以同樣可以看做是一種邏輯磁區,有了邏輯磁區,那么不同磁區之間就不存在并發寫入導致的偏序問題,并且,bookkeeper 規定一個ledger只能被一個客戶端寫入,這樣也就解決了同一個邏輯磁區中,多個客戶端并發寫入的問題,也就解決了偏序問題,
所以,bookkeeper(簡稱BK)中,每一個 bookie 都是平等的,并不需要有一個領導者bookie來維持全序關系,
到這里,我們可以看到,通過引入 ledger 這層抽象,系統設計也變得完全不同,所以抽象是多么的重要,編碼、考慮問題、生活中也需要這樣的抽象思維,
知道了 bookie 是平等的,那么肯定是客戶端具有了領導者這樣的意味,所以客戶端是如何寫入資料的呢?
這里 BK 采用了類似 NWR 機制,客戶端可以靈活配置寫入數量,比如有10個bookie(bookie平等,所以可以擴容),客戶端可以決定一條訊息需要同時發往n個bookie,并且當n個bookie中的m個bookie 回傳成功后(m <= n),就認為寫入成功,
客戶端就是pulsar中的broker,當然,BK還有其他優化和特殊處理,這里不再做進一步對比,
以上是對 pulsar 的簡要介紹,那么接著我們來對比一下 pulsar、rabbitmq、rocketmq、kafka 的選型問題,
先來看rabbitmq,基于erlang語言開發已經注定了rabbitmq在語言生態上的劣勢,這就決定rabbitmq不會被用到高流量場景中,因為難以深度定制,當然,rabbitmq已支持豐富的客戶端語言而出名,并且簡單易用,多說一句,這就和最近的基金一樣,機構抱團,強者越強,rocketmq、kafka、pulsar都是JVM生態,所以再次強調,社區非常重要,
對于rocketmq來說,最大的特點有兩個:一是tag機制,可以定義子主題,這個機制就在很多場景下起到了關鍵作用;二是無縫支持canal等產品,基于這兩個特點,就決定了rocketmq的應用場景,
然后是kafka,高性能就不說了,最關鍵的是kafka的定位不同,官網定義:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
對比rocketmq:
Apache RocketMQ? is a unified messaging engine, lightweight data processing platform.
再看一下rabbitmq的定義:
RabbitMQ is the most widely deployed open source message broker.
這樣就沒必要繼續比較了,kafka不光是訊息佇列,更是流計算平臺,所以要往流計算、大資料考慮,kafka肯定適合,
最后看看pulsar的定義:
Apache Pulsar is a cloud-native, distributed messaging and streaming platform
全面對標kafka,采用全新的架構,解決kafka中讓人頭疼的重平衡,但是pulsar真的是未來的主流嗎?這句話不一定對,不過可以預見,未來新涌現的訊息佇列中,會有相當一部分采用pulsar類似的架構思想:存盤和計算分離,
關于訊息佇列的內容本篇就全部完結,本系列針對訊息佇列的文章,更多的是為了聯系之前學過的知識,加深印象,并從已有知識中分析新的知識,這也符合費曼學習法,Over!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/262180.html
標籤:其他
上一篇:終于有阿里技術大牛把困擾我多年的【計算機組成原理:網路通信】講明白了丨TCP/IP 協議丨IO/NIO丨Redis/Netty 丨馬士兵全套視頻分享
下一篇:服務熔斷與限流:Sentinel