文章目錄
- 前言
- 1、DaSiamRPN
- 2、SiamRPN++
前言
??本文分析下近幾年比較火的幾篇基于anchor的目標跟蹤論文:Siam系列,其中包括SiamRPN、DaSiamRPN、SiamRPN++,SiamRPN分析請翻看我之間的文章有詳解,后面的分析僅代表個人理解,
??SiamRPN論文鏈接
??DaSiamRPN論文鏈接
??SiamRPN++論文鏈接
1、DaSiamRPN
??在這之前孿生網路跟蹤演算法的問題有如下
- 特征提取網路提取的特征只能區分前景和非語意背景,這里解釋下非語意背景,可以理解為不含有用資訊的背景,比如一張影像上有二人個(A、B)和一輛汽車C,跟蹤的物件是A,前景就是A,B和C就是包含具體語意背景,當影像存在類間干擾B時跟蹤器很容易發生偏移,
- 訓練資料集的物體類別較少,不足以訓練具有泛化能力的特征表達,SiamRPN使用vid(20 classes)和ytbb(30 classes)兩個訓練集,極端情況下,跟蹤器漂移到汽車C處,
- 大部分跟蹤器都是短期跟蹤,短期跟蹤從另一種角度講是跟蹤程序中,目標總是出現,
??針對這三個問題,一一來看下DaSiamRPN是如何解決的
-
提取的特征只能區分前景和非語言背景的原因是:訓練時語意背景和非語意背景樣本極度不平衡,大多數anchor是非語意的,如下圖所示,影像中紅色是非語意背景,綠色是語意背景,可以看到樣本多不平衡增加具有語意背景的訓練樣本,
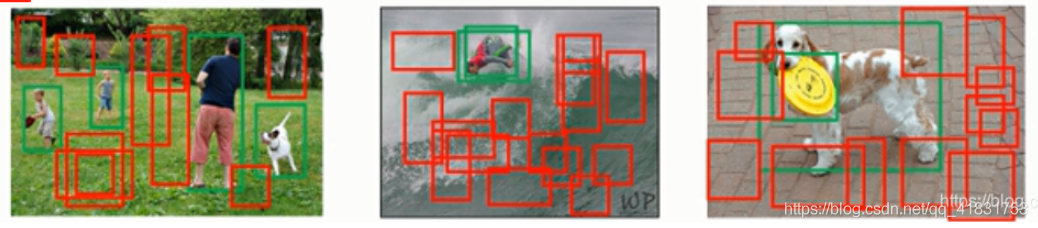 所以,DaSiamRPN在訓練程序中增加含有語意背景的訓練樣本,增加的訓練樣本有兩類,類間語意背景和異類語意背景,如論文Fig.2,
所以,DaSiamRPN在訓練程序中增加含有語意背景的訓練樣本,增加的訓練樣本有兩類,類間語意背景和異類語意背景,如論文Fig.2,
-
為了解決訓練資料集類別少的問題,DaSiamRPN引入了兩個新的資料集,coco和det,極大地擴展了正樣本對的類別,如下圖,這些類別在實際應用中,幾乎不現實,但使用它們來訓練網路可以有效增強特征表達的泛化能力,并且通過對資料集增強技術(平移、旋轉、運動模糊等),可以使用檢測資料集靜止的影像生成跟蹤領域動態的影像,
 通過1、2兩部的訓練策略,模型的泛化能力已經夠好了,能夠排除一定的類間干擾,但是對一些及其相似的物體(類似下圖情況),仍然很難區分,
通過1、2兩部的訓練策略,模型的泛化能力已經夠好了,能夠排除一定的類間干擾,但是對一些及其相似的物體(類似下圖情況),仍然很難區分, 所以DaSiamRPN提出了一種感知干擾物增量學習(Distractor-aware Incremental Learning),可以有效地將泛化的特征表示轉移到某特征視頻領域,而不僅僅使用以往Siam跟蹤器的度量方式,先回顧下以往的度量方式,運算式如下,簡單使用互相關來度量相似度,順便再貼張SiamRPN的圖方便分析,
所以DaSiamRPN提出了一種感知干擾物增量學習(Distractor-aware Incremental Learning),可以有效地將泛化的特征表示轉移到某特征視頻領域,而不僅僅使用以往Siam跟蹤器的度量方式,先回顧下以往的度量方式,運算式如下,簡單使用互相關來度量相似度,順便再貼張SiamRPN的圖方便分析,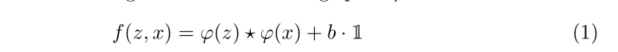
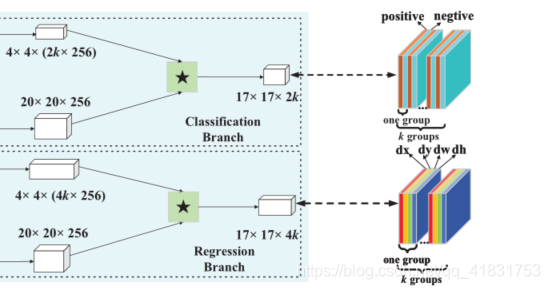 如論文所述,先使用NMS策略得到一些不重疊的proposals(proposals必定也存在待跟蹤目標),當影像中出現相似物體時,這些proposals必定存在干擾物體,然后選擇n個大于給定閾值的干擾proposals,這個閾值是根據相關值得來的
如論文所述,先使用NMS策略得到一些不重疊的proposals(proposals必定也存在待跟蹤目標),當影像中出現相似物體時,這些proposals必定存在干擾物體,然后選擇n個大于給定閾值的干擾proposals,這個閾值是根據相關值得來的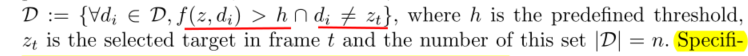 函式f(z,di)表示z與di的互相關,zt是第t幀選擇的目標,第1幀的話它就是groundtruth,最后,得到了n個proposals,
函式f(z,di)表示z與di的互相關,zt是第t幀選擇的目標,第1幀的話它就是groundtruth,最后,得到了n個proposals,
??接著使用distractor-aware objective function對這k個相似性最大的proposals重新排序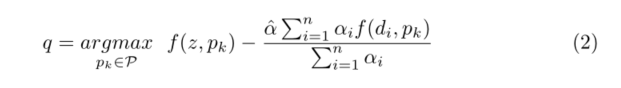
最終選擇的物件標記為q,這個公式可以看出,當它取最大值時,也就是目標與某個proposal的相似值減去某個proposal與干擾物的相似值的值最大,即前者盡可能大,后者盡可能小,
??但是上式的計算復雜度和記憶體使用量增加了n倍,由于互相關是線性因子,所以作者使用結合律減小計算量
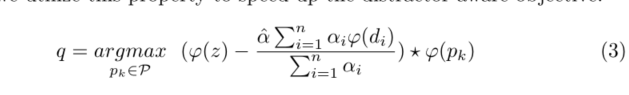
有了這種策略,就可以在每一幀跟蹤時學習一個增量,下一幀跟蹤時就可以利用前一幀的增量資訊來找到準確目標,如下式,同時考慮了T幀的增量資訊,類似于常用的模板更新策略,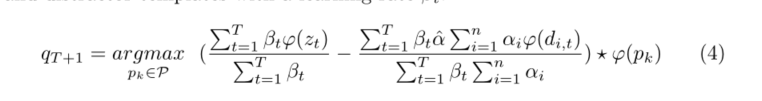
-
DaSiamRPN提出了一種長期跟蹤策略,這種策略比較簡單,但也是得益于DaSiamRPN才能實作,當跟蹤失敗時,加大搜索影像區域即可,重點在于,如何判斷失敗,我們人當然肉眼可見,但跟蹤器如何得知呢?SiamRPN就無法使用該策略,因為在跟蹤程序中,一直選擇相似值最大的proposal作為跟蹤,即使在視野消失的情況下,這個值仍然會很高,也就是說,SiamRPN的特征表示不具有指向性,簡而言之,就是跟蹤器在跟蹤某物體時并不知道它是什么,而DaSiamRPN由于訓練和測驗的一系列優化,提取的特征具有指向性,比如要跟蹤的目標是人,那么他就不會漂移到其他類別位置上去,
2、SiamRPN++
??SiamRPN++的分析流程是提出問題——>解決
問題
??之前Siamese跟蹤器都是利用AlexNet等較為淺層的網路來提取特征,在使用深層網路,如resnet等時,性能反而下降,論文給出了造成性能下降的原因是深層網路不具備空間平移不變性,而且跟蹤任務不同于分類,淺層特征有助于目標的精確定位而不僅僅使用深層語意特征取識別,
??造成深層網路平移不變性的主要因素是卷積程序中padding的影響,平移不變性可以這么理解:
原
始
圖
像
中
目
標
相
對
于
圖
像
中
心
的
位
移
?
網
絡
步
距
=
特
征
圖
中
目
標
相
對
于
特
征
圖
中
心
的
位
置
原始影像中目標相對于影像中心的位移*網路步距=特征圖中目標相對于特征圖中心的位置
原始圖像中目標相對于圖像中心的位移?網絡步距=特征圖中目標相對于特征圖中心的位置而包含padding操作的卷積+池化下采樣的組合會破壞這種性質,padding會在特征圖上引入其他資訊(0填充引入的值為0),當這些資訊大于附近的像素時,那么最大池化下采樣之后的網路傳播將會使用padding的資訊,而不是原圖有用的資訊,這樣就會造成最終得到的特征圖邊緣可能出現大量0的值,論文對該問題基于了證明,證明結果如下所示: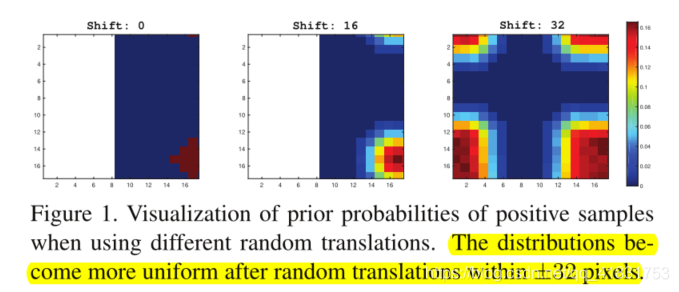 直接看左側圖就行,可以看到左側很大一部分的資訊都是填充的無用資訊,
直接看左側圖就行,可以看到左側很大一部分的資訊都是填充的無用資訊,
解決
-
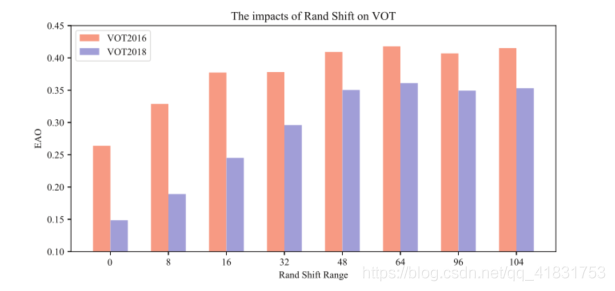
提出了一個簡單而有效的采樣方式,打破了深度網路深層的空間限制,如上圖所示,只是在訓練程序中簡單對目標進行隨機的位移,達到收斂后,測驗出來的效果就很好,中間圖的隨機位移范圍(Rand Shift Range)是-64~16,右側圖是-32 ~32,可以從圖中直觀看到這種方式的有效性,那么理論上該如何解釋呢?SiamRPN++在訓練程序中使用這些策略,使得目標的位置不在影像中心,那么達到收斂后模型就會對padding具有很大的魯棒性,因為從本質上講,padding操作也會使目標發生位移,在進行了一系列范圍取值后在VOT2018資料集上實驗,如下,最終SiamRPN++選擇的shift范圍是(-64,64)
-
有了上述簡單而有效的策略,就可以使用resnet50等深層網路結構作為特征提取了,并且在從基礎上,SiamRPN++提出了一種特征整合結構給互相關操作,這樣可以豐富相似度度量的特征使用量,而且在理論上,resnet50使用這種整合策略比淺層網路更有效,因為resnet50整合的不同層資訊的感受野差變化很大,換句話講,不同層的特征資訊差異更大、更豐富,接下來結合論文給的框架圖和代碼進行分析
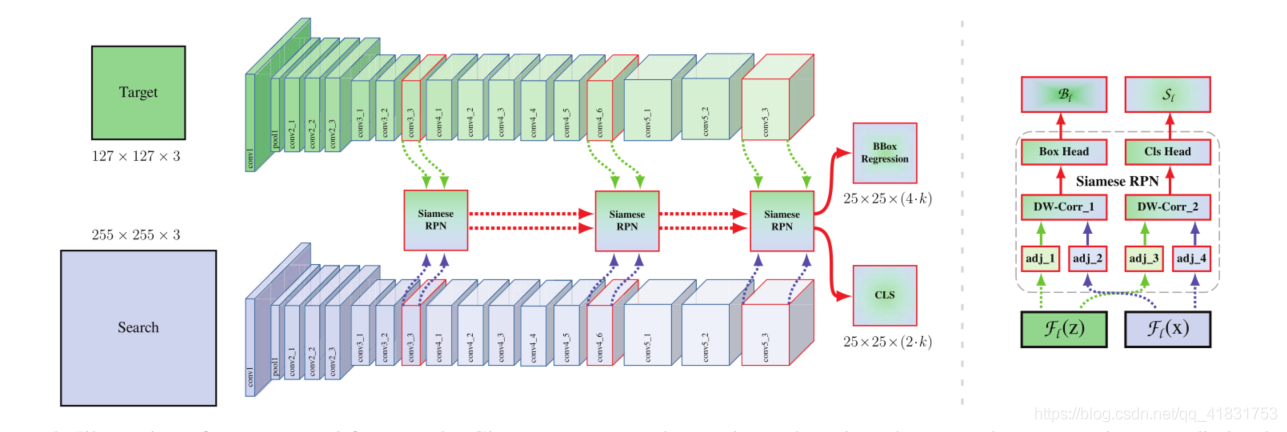 從圖中,可以看出融合了3層的特征,具體輸出形式如代碼中注釋
從圖中,可以看出融合了3層的特征,具體輸出形式如代碼中注釋def forward(self, template, detection): zf = self.features(template) #[8,512,15,15] [8,1024,15,15] [8,2048,15,15] xf = self.features(detection) #[8,512,31,31] [8,1024,31,31] [8,2048,31,31] zf = self.neck(zf) #3個[8,256,7,7] xf = self.neck(xf) #3個[8,256,31,31] cls, loc = self.head(zf, xf) #[8,10,25,25] [8,20,25,25]這里僅看self.features即可,可以看到輸出了3個大小相同的feature map,然后將它們融合,具體的融合公式如下:
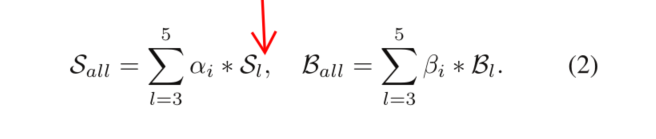 其中
β
\beta
β和
α
\alpha
α是融合權重,個數圖融合層數一致,為3,直接嵌入網路中在訓練時學習,S和B是分類回歸和邊界框回歸,即
其中
β
\beta
β和
α
\alpha
α是融合權重,個數圖融合層數一致,為3,直接嵌入網路中在訓練時學習,S和B是分類回歸和邊界框回歸,即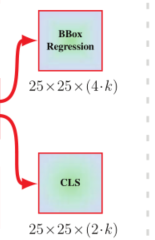 而不是feature map,融合的物件是不同層feature map得到的B和S,
而不是feature map,融合的物件是不同層feature map得到的B和S, -
SiamRPN++還提出了Depth-Wise的分組相關操作,該相關操作提出的原因在于SiamRPN上下通道的引數不平衡,上通道引數太多導致訓練學習困難,論文給出了SiamRPN引數量上下通道的引數量
 為了克服這個缺陷,Depth-Wise分組相關操作由此提出,下面以代碼的形式講解SiamFC、SiamRPN、SiamRPN++所使用的互相關,
為了克服這個缺陷,Depth-Wise分組相關操作由此提出,下面以代碼的形式講解SiamFC、SiamRPN、SiamRPN++所使用的互相關,# from pysot : https://github.com/STVIR/pysot def xcorr_fast_siamfc(x, kernel): #x.shape=(8,256,22,22) kernel.shape=(8,256,6,6) """group conv2d to calculate cross correlation, fast version """ batch = kernel.size()[0] #6 pk = kernel.view(-1, x.size()[1], kernel.size()[2], kernel.size()[3]) #(8,256,6,6) px = x.view(1, -1, x.size()[2], x.size()[3]) #(1,256*8,22,22) po = F.conv2d(px, pk, groups=batch) #(1,8,17,17) po = po.view(batch, -1, po.size()[2], po.size()[3]) #(8,1,17,17) return po def xcorr_fast_siamrpn(x, kernel): #x.shape=(8,256,20,20) kernel.shape=(8,256*2k,4,4) 對應*4k回歸類似分析 """group conv2d to calculate cross correlation, fast version """ batch = kernel.size()[0] #8 pk = kernel.view(-1, x.size()[1], kernel.size()[2], kernel.size()[3]) #(8*2k,256,4,4) px = x.view(1, -1, x.size()[2], x.size()[3]) #(1,256*8,20,20) po = F.conv2d(px, pk, groups=batch) #(1,8*2k,17,17) po = po.view(batch, -1, po.size()[2], po.size()[3]) #(8,2k,17,17) return po def xcorr_depthwise(x, kernel): #x.shape=(8,256,31,31) kernel.shape=(8,256,7,7) """depthwise cross correlation """ batch = kernel.size(0) #8 channel = kernel.size(1) #256 x = x.view(1, batch*channel, x.size(2), x.size(3)) #(1,8*256,31,31) kernel = kernel.view(batch*channel, 1, kernel.size(2), kernel.size(3)) #(8*256,1,7,7) out = F.conv2d(x, kernel, groups=batch*channel) #(1,8*256,25,25) out = out.view(batch, channel, out.size(2), out.size(3)) #(8,256,25,25) return outSiamRPN與SiamFC的相關操作其實是一樣的,只不過SiamRPN相關kernel的通道數更多,代碼假設進入相關之前就已經增加了通道數,注釋中給出了明確的推導程序,depthwise最后的結果是(8,256,25,25),然后在經過網路層的調整之后變為(8,10,25,25),就是論文所要得到的分類feature map,最后,對兩者作一個直觀的對比驗證,
if __name__ == '__main__': z = torch.randn([8,256,6,6]) x = torch.randn([8,256,22,22]) out = xcorr_fast(x,z) #(8,1,17,17) out_depthwise = xcorr_depthwise(x,z) #(8,256,17,17)
??最后,再來看一下SiamRPN++的實驗結果分析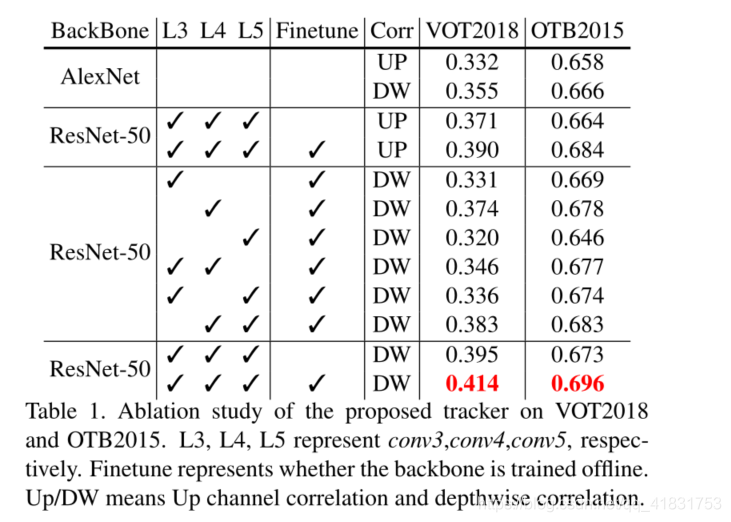 ??Finetune表示是否采用離線訓練的方法,采用DepthWise性能提升有:VOT2018 0.414-0.390=2.4% ;OTB2015 0.696-0.684=0.8%,
??Finetune表示是否采用離線訓練的方法,采用DepthWise性能提升有:VOT2018 0.414-0.390=2.4% ;OTB2015 0.696-0.684=0.8%,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/263314.html
標籤:其他
上一篇:二叉樹經典題目(2)
下一篇:CSDN請你吃湯圓啦!