Hello, 大家好!
我是不作死就不會死,智商不在線,但顏值超有品的拆家隊大隊長 ——咖啡汪
一只不是在戲精,就是在戲精路上的極品二哈
前幾天在 InfoQ 公開課上看到了自己感興趣的東西,所以便簡單做了下記錄
附上原視頻鏈接:
微服務架構下如何保證事務的一致性 | InfoQ 公開課
講師:梁桂釗
視頻鏈接:https://www.infoq.cn/video/K7pDdIP5ZvqY9aAbf5vY

前言
課程目錄,你能了解到什么:
什么是分布式事務?
分布式事務用的多嗎?
二階段提交協議/三階段提交協議,為什么業務上用的不多?
二階段提交協議/三階段提交協議,使用案例有哪些?
CAP 理論有哪些誤區?
TCC 模式,有哪些借鑒?
補償模式,在哪些場景下會使用?
可靠事件模式,是否引入訊息佇列,就可以了?
可靠事件模式,反向訊息也存在訊息丟失,如何考慮?
可靠事件模式,如果我們采用廣播模式,怎么辦?
如何設計一個可復用的分布式事務解決組件?
RocketMQ分布式事務模式,是否可靠?
開篇有益
快來隨本汪一起看看吧
1. 單體服務的性能沒有微服務好,是不一定對的,
微服務化后,整個呼叫鏈路會變得非常的長,原來的一次 RPC 呼叫會變成多次 RPC 呼叫,網路上的性能損耗就增加了,
比如說異地多活,他最大的挑戰其實就是網路時延,機房內部呼叫是 1~2 毫秒的延時,同城跨機房一般是十幾毫秒,跨省市比如杭州到上海之前的資料大概是 30~50 毫秒之間,那么之前的專案是廈門到新加坡,極端情況下是會有 100~200 毫秒的延時,網路時延的堆積,會對性能產生很大的影響,
微服務的本質是犧牲網路呼叫的性能,來對機器的資源進行壓榨,
2.跨服務之間資料的一致性問題,也就是分布式事務,
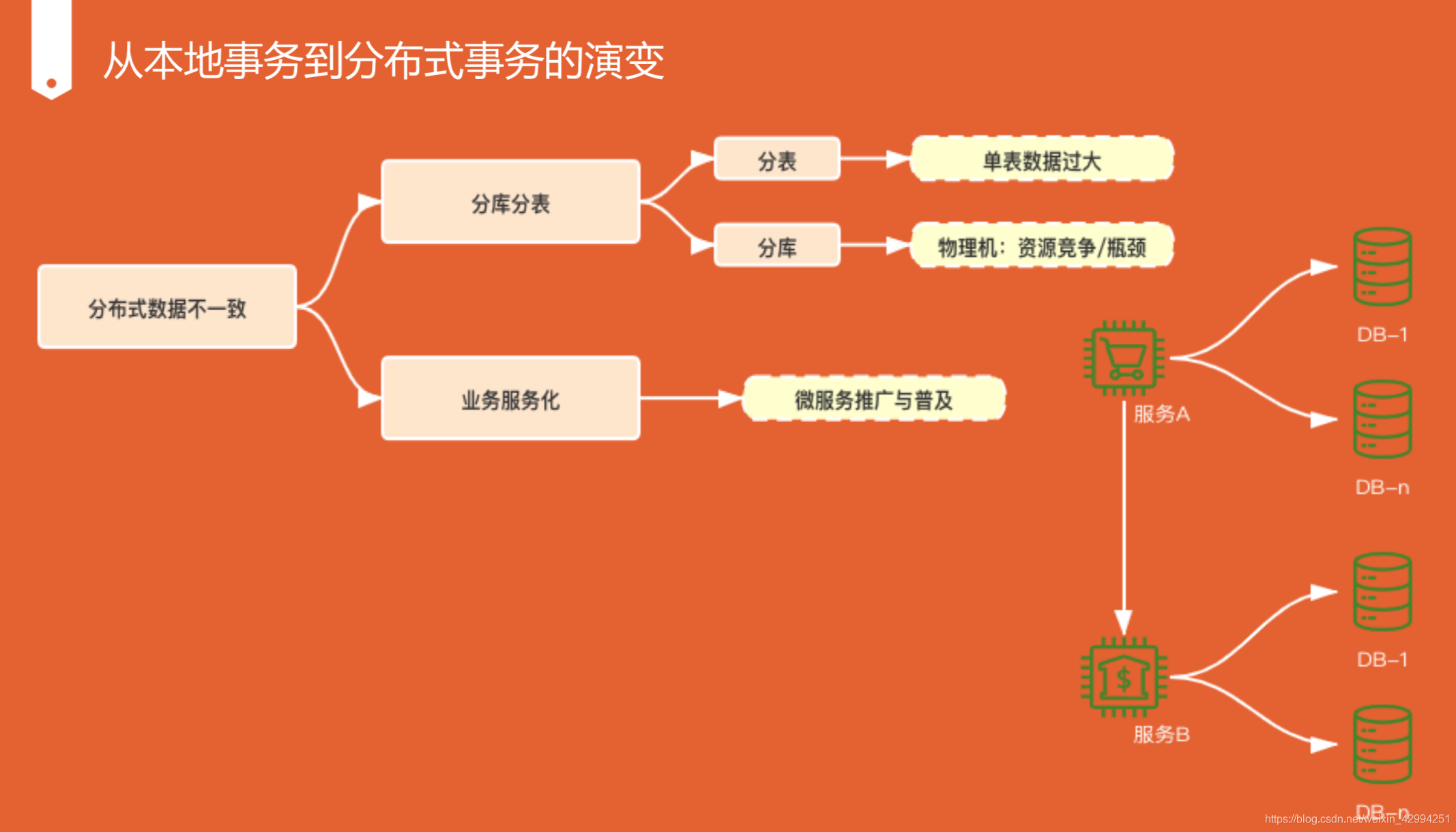
3.從本地事務到分布式事務的演進
思考:什么是分布式事務,為什么會需要分布式事務?
單體服務之下,程式經常被部署在單個物理機,資料庫也是一個,可以使用資料庫的ACID 原子性,一致性,隔離性,持久性來保證資料的一致,
瓶頸:CPU, 記憶體,磁盤IO, 網路帶寬這些都是硬體的資源瓶頸,
但每個資料庫仍可以保證自己的 ACID
重點:分表,通過哈希取模,把它分成1024張表,但他們在一個庫下,仍可以通過ACID 保證強一致性,通過時間取模,像退款,物流,日志,我們根據時間周期,按年,按季度來分,只要他在統一個庫下,他資料庫的基本特性都是可以用的,
分庫不一樣,各個庫之間是不感知的,
概念:分布式事務是保證不同資料庫中資料一致性的解決方案,
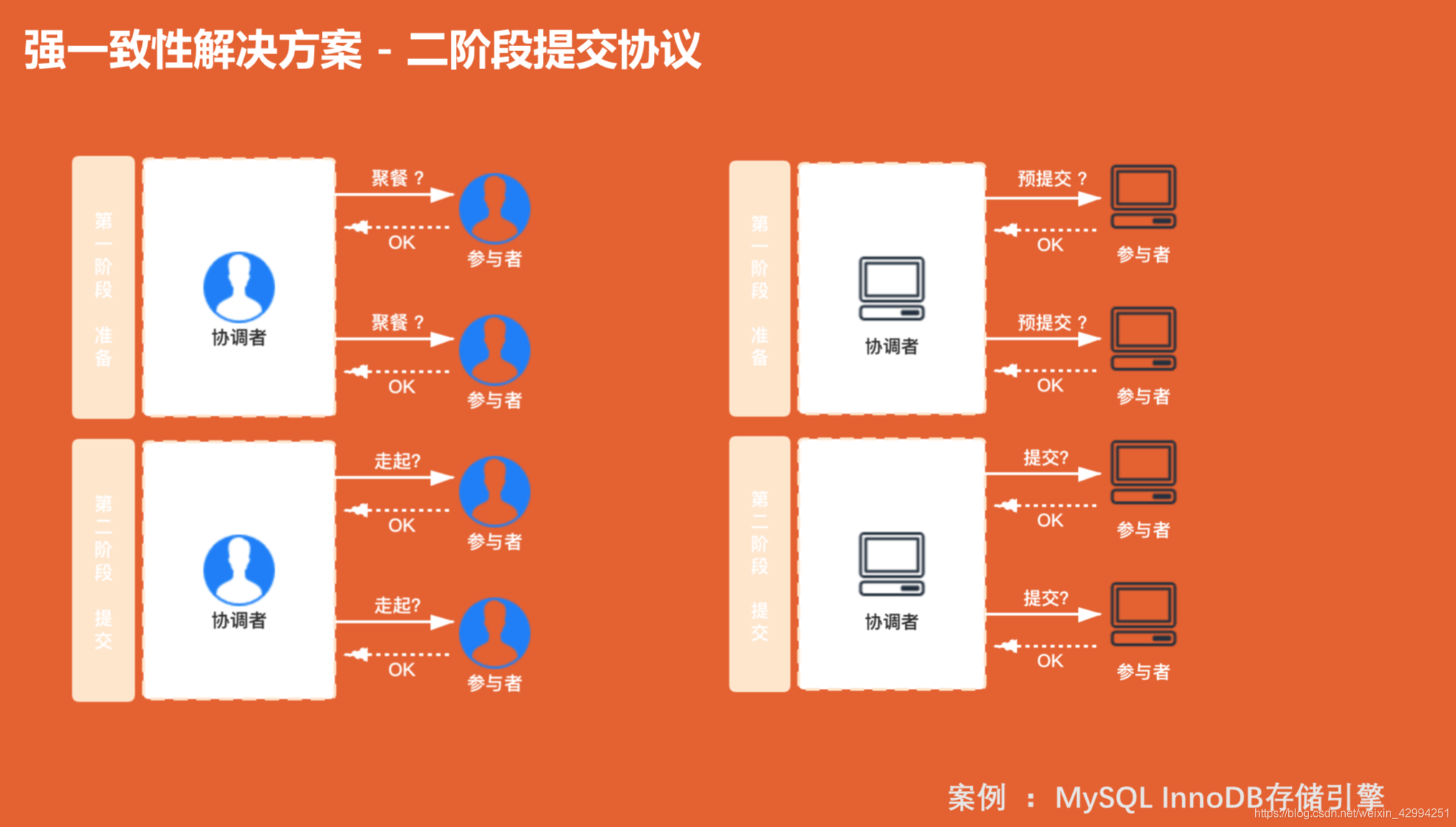
4.強一致性解決方案 - 二階段提交協議
兩個階段:第一階段準備;第二階段提交
兩個角色: 一個協調者,負責任務的協調;一個參與者,負責具體的參與執行的,
簡單例子助理解:
團隊聚餐,共10個人,愿意去的回1,大家給出各自的答復,大家都回復1,再決定是否開始走,
真實體子:
協調者詢問參與者是否預提交?全部參與者都回復預提交成功,才可以發起正式提交;有一個參與者回復預提交失敗,則協調者回復全部參與者,執行回滾,該次提交失敗;
注意:這有一個問題!
二階段提交是同步等待的,假如有參與者一直聯系不上,或者有參與者一直不回復,這個程序就會很長,甚至是死等待,同步就導致他非常耗時,
使用場景:Mysql InnoDB 存盤引擎就是用的二階段提交協議,他的 binlog(二進制日志) 和 (事務日志)redolog就是用的二階段提交協議來保證一致性的,
具體執行程序:我們現在更新一條資料,他會先執行一個 redolog , 就是一個預提交狀態,然后寫出 一個binlog ,并寫入磁盤,正式提交,更新完成,資料庫中有協調者來完成,
為什么資料庫中用,實際業務中用不到呢?
重要的問題是我們在微服務中,是禁止 DB 直連的,就經常要跨服務呼叫,這樣就好存在網路時延,甚至會請求失敗,二階段提交協議,由于是同步的,碰上網路抖動或其他故障,就容易失敗,所以微服務中一般不會使用到他,
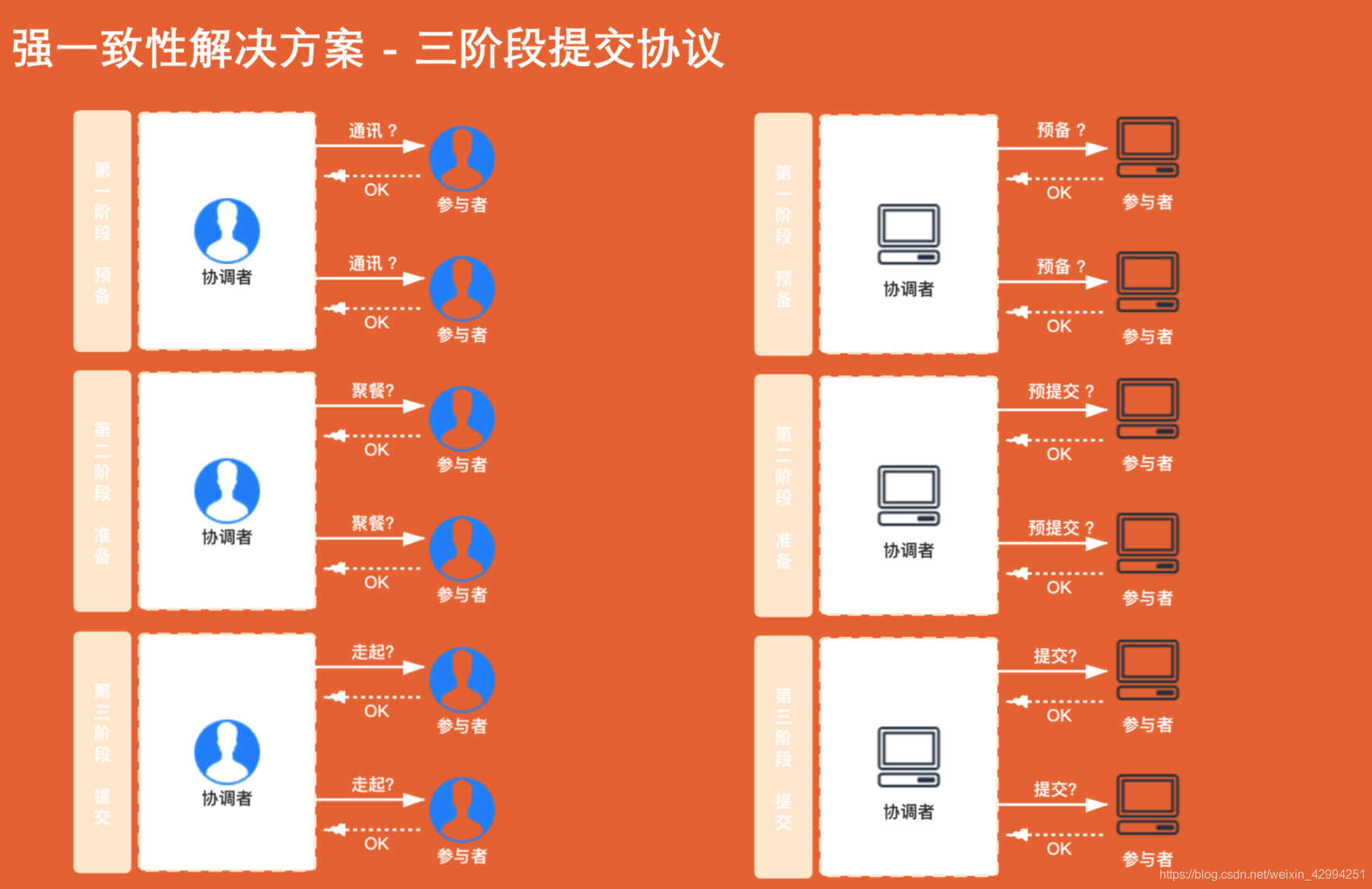
5.強一致性解決方案-三階段提交協議
三階段提交協議是二階段提交協議的一個改良版本,
三階段采取了超時機制來解決同步問題,他加入了預備階段,在執行任務的早期第二階段準備,第三階段提交之前,盡可能地發現問題
超時機制是一個默認機制,但仍有問題,比如說:我超時默認提交成功,但是這個服務實際是出現了例外,其他服務發生回滾,那么這樣的情況下,還是會出現資料不一致,
所以即使使用了二階段、三階段提交,還是需要資料補償的,需要最終一致性方案來兜底,這是不用他們的一個原因,
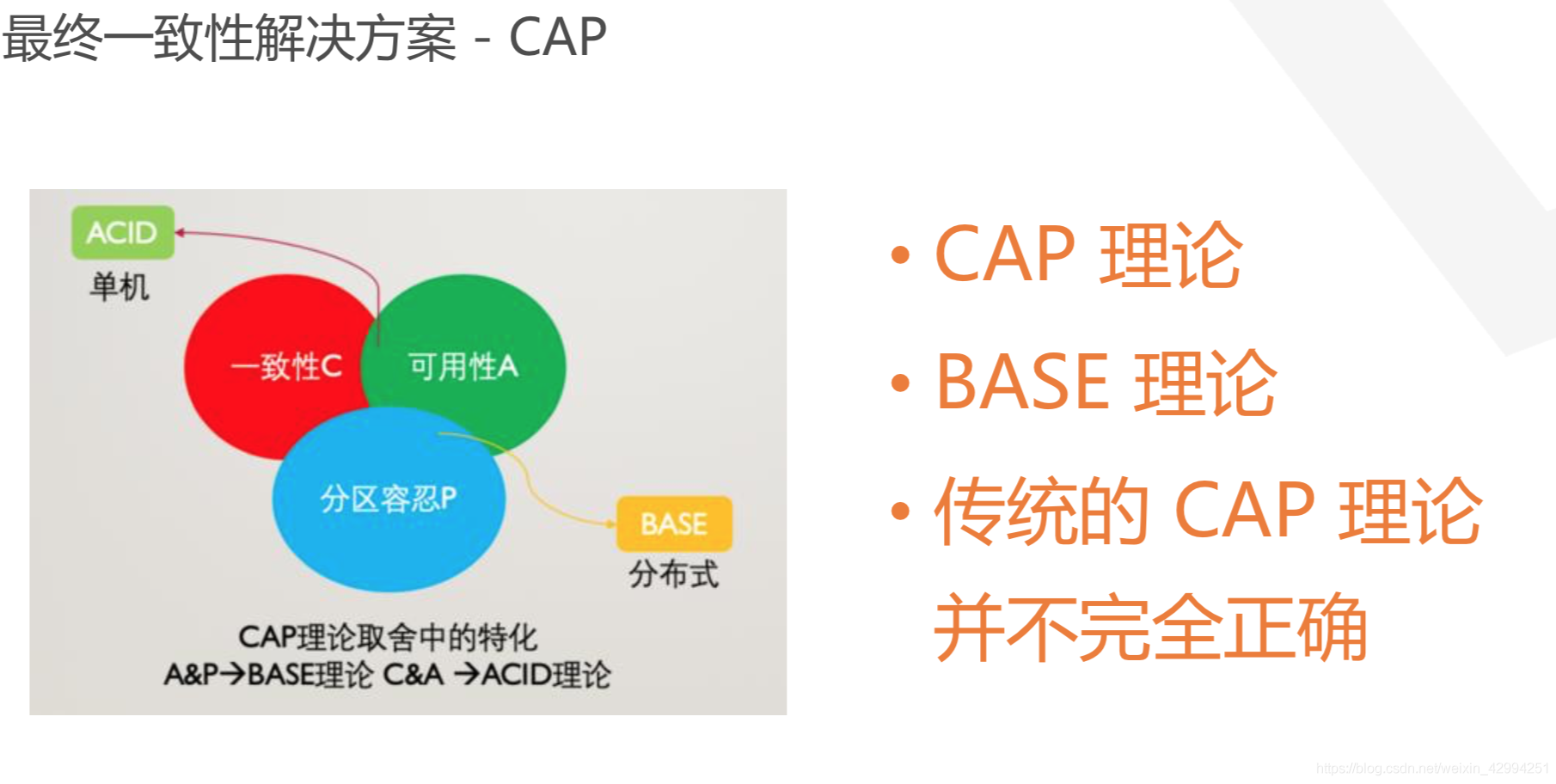
6.最終一致性解決方案 -CAP
(1)CAP 理論
無法三個都滿足,但必須三個選兩個滿足,磁區容錯性是最基本的要求,
如果我們選擇了一致性和磁區容錯性,那么網路問題就會導致不可用,
如果我們選擇了可用性和磁區一致性,那么資料同步程序就可能存在資料不一致,
(2)BASE 理論
在分布式系統中,允許損失一部分的一致性,通過一段時間的修復來保證資料的最終一致,
(3)傳統的 CAP 理論并不完全正確
1) CAP 中的一致性和我們 ACID 里的一致性不一樣,一致性 = 可線性化
方法A操作之后B操作,那么B操作的結果來看的話,認為A操作的結果是完成的,看起來資料只有一份,但是可以有多個資料副本,
2)CAP 的可用性和我們微服務的可用性不完全一樣,因為我們微服務的可用性,一般會通過 SLA 來衡量
eg: 我們有兩個資料中心,當兩個機房的網路中斷時,我們采用一致性和可用性,我們把另一個資料中心的服務給關閉掉,所有的讀寫都在一個中心,然后把用戶的流量切到這個資料中心,這不就以為著網路中斷就一定會造成系統停服!
多個資料中心,通過異步的方案,binlog 進行資料同步,很多時候不是因為網路的故障而是因為網路的延遲,絕大部分都是網路延遲導致了資料的不一致,

7.最終一致性解決方案 - TCC
三個:嘗試,提交和撤銷,
try嘗試會做資源的檢測和預留,
confirm 執行業務的提交操作,
cancel進行資源的回滾和補償,
基本沒用過,因為他對業務代碼有一定的侵入性,他是個同步的方案,且會導致業務代碼因引入這三個方法而變得不簡潔,但是 TCC 仍有一些框架,
用到的話,要注意 TCC 的一些例外情況:
1)慷訓滾 在 try 操作下沒有執行,就呼叫了第二階段 cancel 撤銷, 假如服務宕機了或網路例外,沒有執行 try ,故障恢復之后,他會執行一個回滾,
2)冪等 多次提交,導致臟資料記錄,
3)懸掛cancel 的操作比 try 快,先執行 cancel ,后執行 try,
場景如下: try 超時重試,導致 try 的執行周期比較晚,會在比較晚的節點執行,
解決方法: 我們引入一個事務表,我們把每一個 try, confirm, cancel 的操作都記錄下來,
比如我們在呼叫 cancel 時,發現沒有呼叫 try ,那么我們就不呼叫 cancel 方法了,
冪等也是這樣,執行時先查看是否執行過,執行過了的我們就不執行了,
但是,會有一個并發安全的問題需要注意,

8.最終一致性解決方案 - 補償機制
重試機制:固定時間,固定次數,比如 RocketMQ, 他默認是重試 3 次,但他最多可以重試 16 次,
為什么要有固定時間,因為 CPU 執行速度非常快,不設定重試時間,可能一秒內 16 次就都重試完了,增加了系統負載,意義也不大,1秒,3秒,7秒,1分鐘,2分鐘,1小時,2小時,
更新修復:自我修正,減少瞬時壓力幾十萬條,可以用調度器;幾千萬條,就需要分時段,在每一個用戶請求環節,分散瞬時壓力,就內容分發場景,點贊,評論等社交場景,增加冗余表,把資料冗余出來,
自我修正:資料一致保證,不用定時任務,用戶去請求文章,判斷他的請求的周期是否超過更新時間,比如說超過24小時,異步重繪資料,只要有一個用戶去請求,那么就會觸發資料的重繪,這樣其他用戶就可以看到最新資料,但如果一直沒有用戶請求,這個資料不更新也沒有什么關系,
定時機制:定時重試,定時核對,
資料核對:微服務下,DB 禁止直連,調介面時資料量特別大,介面會有限流,超過5000 介面就限流了,在加上網路抖動,這時資料請求就很不穩定,通過介面呼叫數百萬資料非常不現實,所以一般會在這個域,通過同步機制,binlog -> kafka -> 事件廣播 通過監聽事件,把資料寫到自己的域內,

9.最終一致性解決方案 - 可靠事件機制
如果采用自動應答機制,訊息一定會丟失,
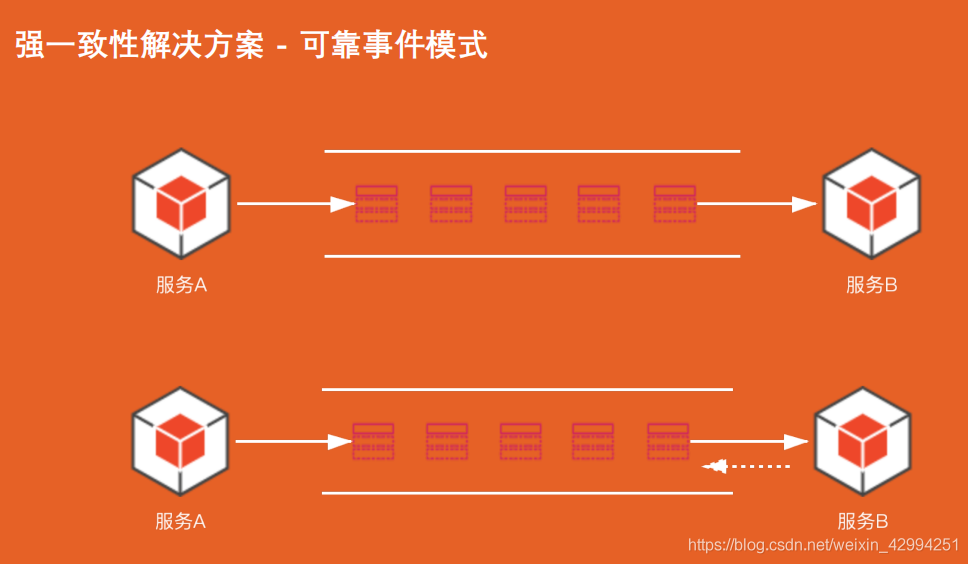
場景1:
服務 A 向服務 B 發送訊息, 服務 B 收到之后自動應答,就告訴訊息佇列我已經收到訊息了,你把持久化訊息清除掉吧,結果 B 在進行訊息消費的時候失敗了,此時 服務B 已經無法重新獲取訊息了, 所以我們一定要開啟手動應答,手動 ACK.
場景2:
雙11 大促,把訊息全部填過了,再通過 MQ 做一個訊息的積壓,然后慢慢地把訊息消費掉, 但這個程序中有一個問題,服務 B 無法及時把訊息消費掉,如果說周期特別長,比如說 RocketMQ 超過了兩個小時,那么訊息就會被記錄到 MQ 的死信佇列里去,那么這些訊息就需要人工干預才能處理了,這些訊息即時不丟,也不會重試了,對于服務 B 而言,這些訊息看起來就已經丟了,因為我們沒辦法再消費了,
流程: 服務 A 將資料存入資料庫中,然后把訊息標識為待發送狀態,緊接著服務 A 投遞訊息到訊息佇列,服務 B 消費訊息成功,回傳一個 ACK ; 同時服務 B 再往另一個訊息佇列中發送一個訊息,服務 A 收到這個訊息之后,在去資料庫將資料設定成完成狀態,
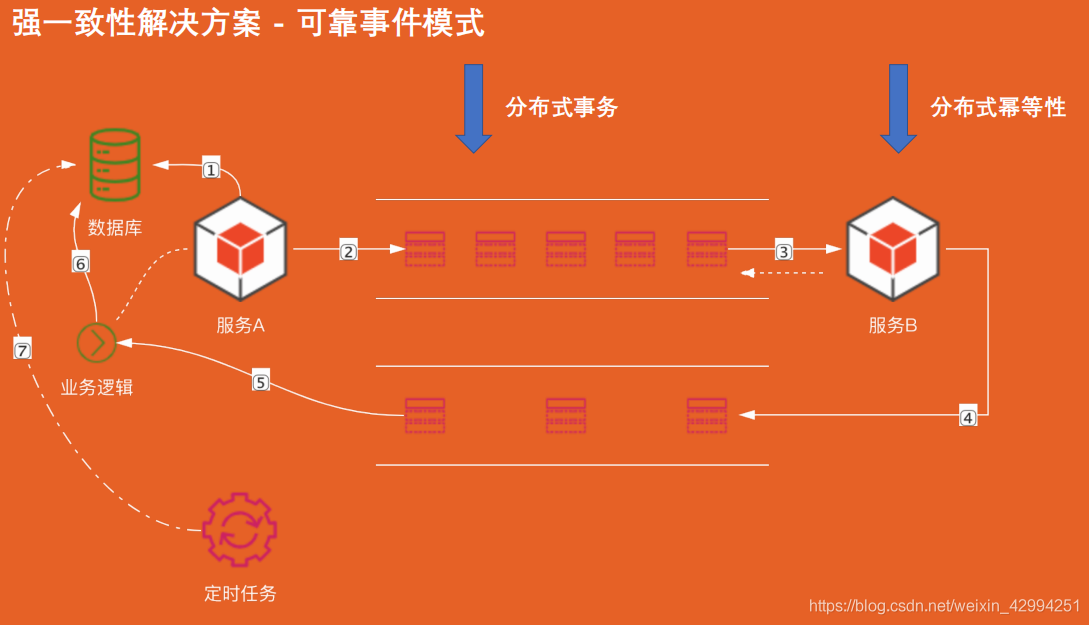
定時任務,掃描未投遞成功的訊息進行重新投遞,3~ 5次之后,如果還沒有投遞成功,就需要進行人工干預了,
冪等性:單庫建一個唯一索引,根據冪等欄位來保證唯一性,冪等的核心,就是保證資源的唯一性,
資料量特別大,就需要分庫分表,一般常見的方式有兩種:
- 先查后插,需要注意到并發安全性問題,一主多子,一個主訂單多個子訂單,一般情況下多個子訂單是同時創建的,那么這種情況下,就會有并發安全問題,我們需要加分布式鎖來解決臨界狀態的并發安全問題,但需要注意一個問題,分布式鎖有一個過期時間,比如 30 分鐘,但比如我們重試的周期超過了 30 分鐘,鎖失效掉了,就還會出現并發安全問題,或加入狀態機,通過狀態機的狀態約束,狀態流轉來保證唯一性,
業務場景:
我們是一個買家,我們在淘寶買了一個商品,然后覺得他不好,我們就去發起一個退款,那么退款,這個工單就會以售后工單的形式流轉到買家,買家的客服就會去看這個單子,去看下單子的訂單,定價資訊,交易資訊,退款理由,退款金額,看你個各種評論,各種風控,看完沒問題,就把錢給你退 了,錢就到賬了,
退款和自動化退款,自動化退款,基于強規則,退款規則,訂單規則,比如7天無理由的,訂單小于100 的,就自動退掉了,
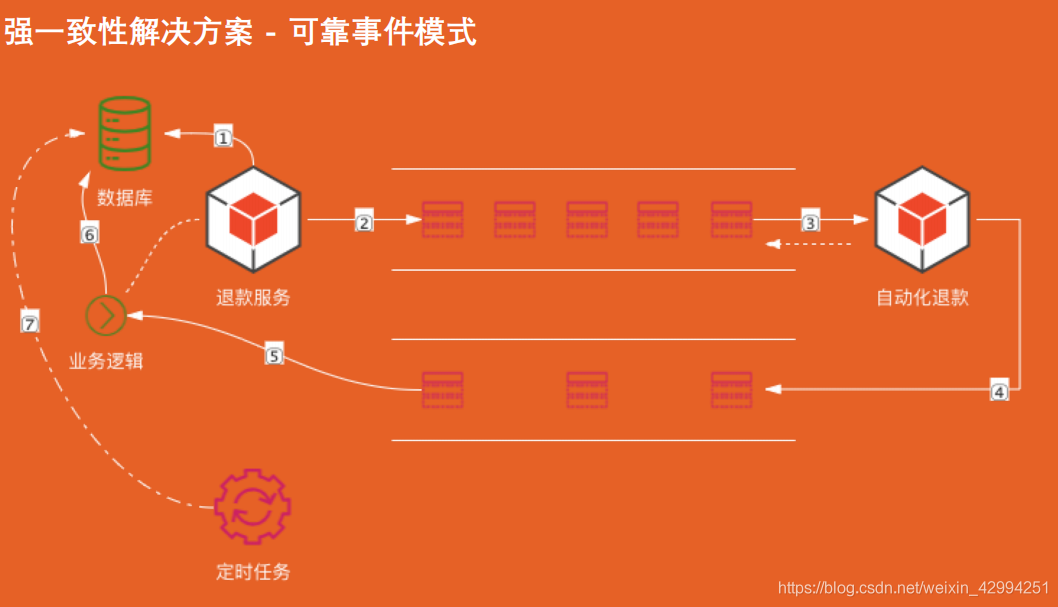
流程:用戶發起退款服務后,退款服務會先寫入本地資料庫,然后持久化這筆退款,接著發送訊息投遞到訊息佇列,退款服務無需同步等待退款結果,他就可以繼續做其他事情,退款成功后,自動化系統將退款成功的訊息推入另一個訊息佇列,退款服務收到訊息后,就會把該退款單設定成完成狀態,
定時任務去資料庫掃描未完成的退款工單,進行重試,最后失敗的就需要進行人工干預了,
通過兩個訊息佇列,正反向投遞,保證訊息的投遞成功,
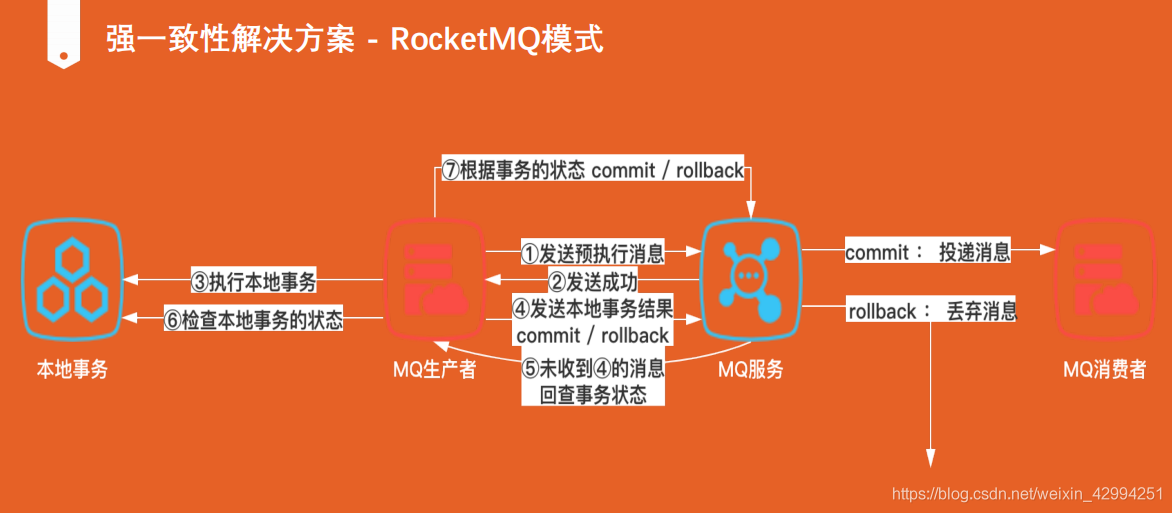
10.最終一致性解決方案 - RocketMQ 模式
這里有一個非常巧妙的設計,大家可以去學習一下,它其實是用來解決生產者發送訊息與本地事務的原子性問題,換句話說,本地事務執行不成功,則不會發送訊息,但有一個問題,本地事務執行成功,MQ 不一定能執行成功,本地事務就需要回滾,RocketMQ 實際上解決了這個問題,也是我們需要去學習的一點,
半投遞狀態機制,RocketMQ 先發送一個預執行訊息到佇列,去測驗一下 MQ 的連通性,但是此時訊息不執行,接著再去執行本地事務,本地事務執行成功后,在對預執行訊息就行執行,如果 本地事務執行失敗了,那么我們就需要對 RocketMQ 佇列中的訊息給洗掉掉,
需要注意:訊息發到了 MQ ,但是由于一些限流,或者是服務的不可用,導致訊息無法正常消費掉,或訊息進入了死信佇列,實際上我們的下游,還是不知道的,他是不可靠的,還是需要補償模式保證最終一致性,
(免責宣告:咖啡汪譯文博客目的在于傳遞更多資訊,不代表本人的觀點和立場,文章內容僅供參考,)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264135.html
標籤:其他
上一篇:Java ManagementFactory獲取運行時資訊
下一篇:理解VUE雙向資料系結原理和實作