
Message Passing Attention Networks for Document Understanding
https://github.com/giannisnik/mpad.
1.Motivation
將MP(message passing)架構應用于文本表示學習,
2 Message Passing Neural Networks
對于一個圖
G
G
G=(
V
V
V,
E
E
E),考慮節點
v
v
v∈
V
V
V,在
t
t
t
+
+
+
1
1
1時刻,一個massage 向量由節點
v
v
v的鄰居計算得出:
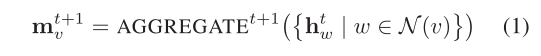
然后,通過將其當前特征向量
h
h
h
t
^t
t
v
_v
v?與訊息向量
m
m
m
t
^t
t
+
^+
+
1
^1
1
v
_v
v?相結合來計算節點
v
v
v的新表示
h
h
h
t
^t
t
+
^+
+
1
^1
1
v
_v
v?:
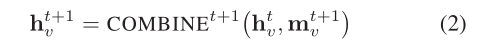
訊息按時間步長傳遞,每一步都由MP的不同層實作,因此,迭代對應于網路深度,最終的特征向量
h
h
h
T
^T
T
v
_v
v?是基于從以
v
v
v為根高度為
T
T
T的子樹中的所有節點的訊息傳播,
如果需要圖級特征向量,例如用于分類或回歸,則應使用必須對排列不變的
R
R
R
E
E
E
A
A
A
D
D
D
O
O
O
U
U
U
T
T
T函式
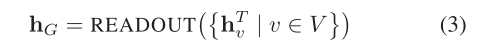
3 Message Passing Attention network for Document understanding (MPAD)
3.1 Word co-occurrence networks
將檔案表示為一個滑動視窗大小為2的詞共現網路,表示為 G G G=( V V V, E E E),檔案中的每個唯一單詞由 G G G中的一個節點表示,如果在發現兩個節點在一起(在視窗范圍內),則添加一條邊, G G G是有向加權的:邊方向和權重分別捕獲文本流向和共現次數,
在 G G G中,同一個句子中的連續單詞為鄰居,這些節點通過公共鄰居連接在一起,
也就是說,長度為2的路徑對應于二元模型,長度超過2的路徑可以對應于傳統的n-grams,也可以對應于寬松的n-gram,即從不同句子中共現,
Master node.
圖 G G G還包括一個特殊的檔案節點,它通過單位權重雙向邊鏈接到所有其他節點,
這里是否會因為圖太過密集導致資訊傳遞混亂,甚至丟失?
3.2 Message passing
A
A
A
G
G
G
G
G
G
R
R
R
E
E
E
G
G
G
A
A
A 函式:
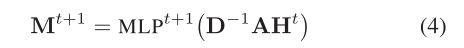
其中
H
H
H
t
^t
t∈
R
R
R
n
^n
n
×
^×
×
d
^d
d為節點特征(在
t
t
t=0時,
d
d
d等于預訓練單詞嵌入的維數,),
A
A
A∈
R
R
R
n
^n
n
×
^×
×
n
^n
n是
G
G
G的鄰接矩陣,由于
G
G
G是有向的,所以
A
A
A是非對稱的,此外,設定
A
A
A的對角線為零,不考慮節點本身的特征,只考慮其傳入鄰居的特征,因為
G
G
G是加權的,所以
A
A
A的行表示節點
v
i
v_i
vi?上傳入邊的權重,
D
D
D∈
R
R
R
d
^d
d
×
^×
×
d
^d
d為度矩陣(度矩陣是對角陣,對角上的元素為各個頂點的度,頂點
v
i
v_i
vi?的度表示和該頂點相關聯的邊的數量,),
M
M
M
t
^t
t
+
^+
+
1
^1
1∈
R
R
R
n
^n
n
×
^×
×
d
^d
d表示massage矩陣,
接下來使用GRU聚合:
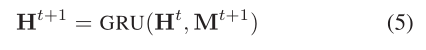
忽略偏置有:
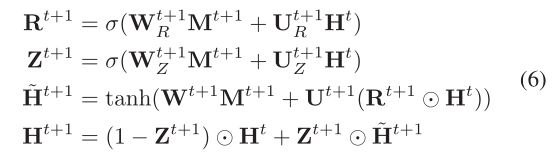
3.3 Readout
在訊息傳遞和執行 T T T次迭代的更新之后,就可獲得包含最終頂點表示的矩陣 H H H T ^T T∈ R R R n ^n n × ^× × d ^d d,設 G G G ? ^- ?為無特殊節點(主節點)及其相鄰邊的圖,則矩陣 H H H ? ^- ? T ^T T∈ R R R ( ^( ( n ^n n ? ^- ? 1 ^1 1 ) ^) ) × ^× × d ^d d為對應的表示矩陣,
隨后將應用于
H
H
H
?
^-
?
T
^T
T的self-attention與最終檔案節點表示的連接作為
R
R
R
E
E
E
A
A
A
D
D
D
O
O
O
U
U
U
T
T
T函式:
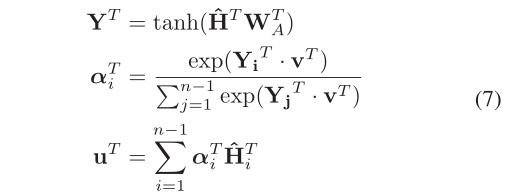
H H H ? ^- ? T ^T T首先傳遞到由矩陣 W W W T ^T T A _A A?∈ R R R d ^d d × ^× × d ^d d引數化的稠密層,然后通過點積比較密集層 Y Y Y T ^T T∈ R R R ( ^( ( n ^n n ? ^- ? 1 ^1 1 ) ^) ) × ^× × d ^d d與可訓練向量 v T v^T vT∈ R d R^d Rd(隨機初始化)的輸出注意力權重向量 α α α,最后加權得到檔案的整體表示,
這里與poly-encoder 同樣設定了不同的v,但是結果卻相反,poly-encoder 的v增大結果編號,本文報告了不好的結果,
Master node skip connection
h h h T ^T T G _G G?∈ R R R 2 ^2 2 d ^d d通過連接 u T u^T uT和最終主節點表示獲得,即主節點向量繞過了注意機制,這種選擇背后的原因是,作者期望特殊檔案節點學習關于檔案的高級摘要,例如它的大小、詞匯等,因此,通過使主節點繞過注意力層,直接將關于檔案的全域資訊注入到它的最終表示中,
Multi-readout
隨著迭代的進行,雖然節點特征捕獲越來越多的全域資訊,但是保留更多的本地資訊可能也是有用的,因此本文并不是將讀出函式僅應用于
t
t
t =
T
T
T,而是將其應用于所有時間步長并連接結果,最侄訓得
h
h
h
G
_G
G?∈
R
R
R
T
^T
T
×
^×
×
2
^2
2
d
^d
d:
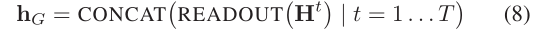
3.4 Hierarchical variants of MPAD
本文提出了MPAD的幾個變體,在所有這些方法中,檔案中的每個句子表示為一個單詞共現網路,并通過應用如前所述的MPAD來獲得它的嵌入,
MPAD-sentence-att.
句子嵌入是通過自我關注來簡單組合的,
MPAD-clique
構建一個完整的圖,其中每個節點代表一個句子,然后,將該圖輸入到MPAD,舒適化節點為句子的embedding加權平均,
MPAD-path
不是一個完整的圖,本文根據文本的自然流動建立一個路徑,也就是說,如果兩個節點所代表的兩個句子在檔案中相互跟隨,則這兩個節點通過有向邊連接,
4 Experiments
4.1datasets
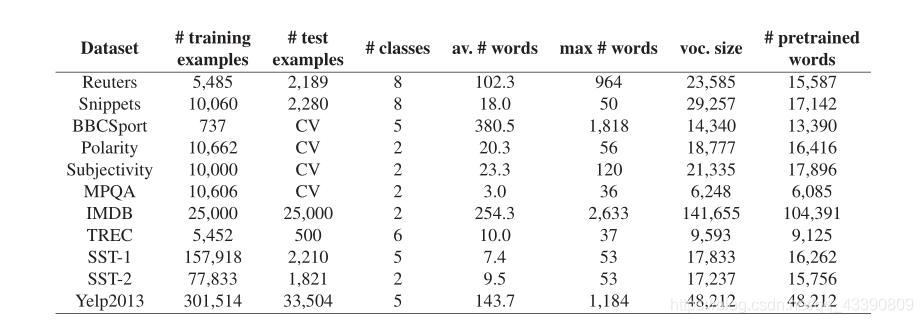
實驗引數設定
MP iterations (T=2)
d = 128
window of size 2
所有層:ReLU activation
learning rate of 0.001
dropout 0.5
結果
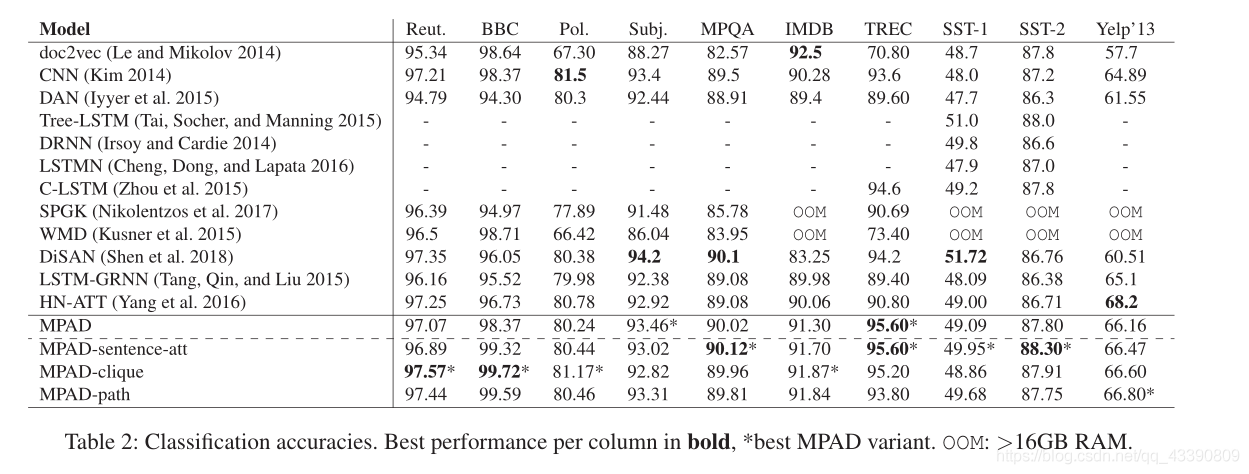
消融

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264463.html
標籤:其他