前言:今天單就MySQL主從及原理和遇到問題分析下,當然要支撐高并發僅僅靠MySQL是不可行的,目前我司用的是 MySQL+Nginx+redis+rabitMQ+elasticsearch+mongoDB等來支撐高并發;根據業務場景組合拳吧,下面進入正題.....
如果想從MySQL方便做到支持一定量的并發,那么必然會想到:讀寫分離
MySQL 做讀寫分離的前提,是把 MySQL 集群拆分成“主 + 從”結構的資料集群,這樣才能實作程式上的讀寫分離,并且 MySQL 集群的主庫、從庫的資料是通過主從復制實作同步的,
在面試程序中,我們一般會被問到:
@1.你們公司MySQL有幾臺從庫?每臺從庫作用是什么?(考察你對你用的系統熟悉程度)
@2.主從復制程序原理是什么?(考察你的基礎知識)
總的來講,MySQL 的主從復制依賴于 binlog ,也就是記錄 MySQL 上的所有變化并以二進制形式保存在磁盤上,復制的程序就是將 binlog 中的資料從主庫傳輸到從庫上,這個程序一般是異步的,也就是主庫上執行事務操作的執行緒不會等待復制 binlog 的執行緒同步完成,
1.目前我司一般是1主1從1備份,個別的實體和庫會有多個從庫;
2.主從復制大概分三個程序:
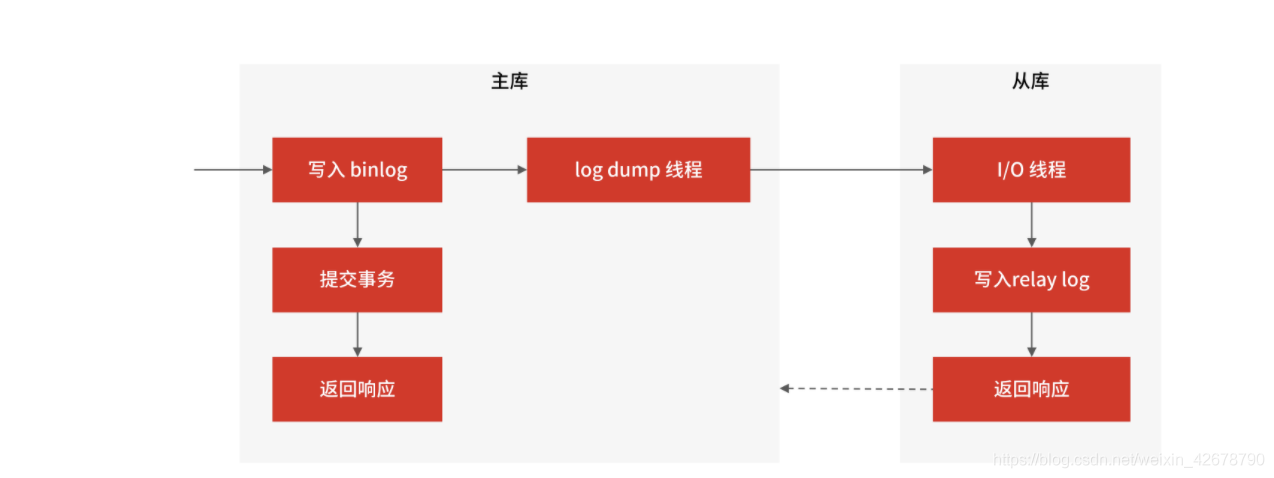
a:MySQL 主庫在收到客戶端提交事務的請求之后,會先寫入 binlog,再提交事務,更新存盤引擎中的資料,事務提交完成后,回傳給客戶端“操作成功”的回應,
b:從庫會創建一個專門的 I/O 執行緒,連接主庫的 log dump 執行緒,來接收主庫的 binlog 日志,再把 binlog 資訊寫入 relay log 的中繼日志里,再回傳給主庫“復制成功”的回應,
c:從庫會創建一個用于回放 binlog 的執行緒,去讀 relay log 中繼日志,然后回放 binlog 更新存盤引擎中的資料,最終實作主從的資料一致性,
下面找了張圖:
在完成主從復制之后,你就可以在寫資料時只寫主庫,在讀資料時只讀從庫,這樣即使寫請求會鎖表或者鎖記錄,也不會影響讀請求的執行,
那么寫入binlog日志記錄資料方式有哪幾種勒?
- statement: 會將對資料庫操作的sql陳述句寫道binlog中
- row: 會將每一條資料的變化寫道binlog中,
- mixed: statement與row的混合,Mysql決定何時寫statement格式的binlog, 何時寫row格式的binlog,(MySQL4.0版本后)
既然可以有多個從庫,那大促流量大時,是不是只要多增加幾臺從庫,就可以抗住大促的并發讀請求了?why?
當然不是;因為:
從庫數量增加,從庫連接上來的 I/O 執行緒也比較多,主庫也要創建同樣多的 log dump 執行緒來處理復制的請求,對主庫資源消耗比較高,同時還受限于主庫的網路帶寬,所以在實際使用中,一個主庫一般跟 2~3 個從庫(1 套資料庫,1 主 2 從 1 備主),這就是一主多從的 MySQL 集群結構,
MySQL 主從復制還有哪些模型?
主要有三種;
@1:同步復制:事務執行緒要等待所有從庫的復制成功回應,
@2:異步復制:事務執行緒完全不等待從庫的復制成功回應,
@3:半同步復制:MySQL 5.7 版本之后增加的一種復制方式,介于兩者之間,事務執行緒不用等待所有的從庫復制成功回應,只要一部分復制成功回應回來就行,比如一主二從的集群,只要資料成功復制到任意一個從庫上,主庫的事務執行緒就可以回傳給客戶端,
主從必會遇到主從延遲問題,怎么解決?
@1:使用資料冗余;
例:在異步呼叫A模塊時,發送A模塊需要的所有資訊,借此避免在從庫中重新查詢資料,但要注意每次呼叫的引數大小,過大的訊息會占用網路帶寬和通信時間,
@2:使用快取解決;(通過快取解決 MySQL 主從復制延遲時,會出現資料庫與快取資料不一致的情況,所以這塊要處理好)
@3:直接查詢主庫;(該方案在使用時一定要謹慎,你要提前明確查詢的資料量不大,不然會出現主庫寫請求鎖行,影響讀請求的執行,最終對主庫造成比較大的壓力)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264467.html
標籤:其他
上一篇:2011年上半年 系統分析師 下午試卷 論文 軟考真題【含答案和答案決議】
下一篇:安裝gl3w