作者:小小明
Python讀取Excel的文本框
基本需求
今天看到了一個很奇怪的問題,要讀取Excel檔案的文本框中的文本,例如這種:

本以為openxlpy可以讀取,但查看openxlpy官方檔案并沒有找到相應的API,咨詢了幾個大佬,他們也沒有處理過類似的問題,
無賴之下,我就準備發揮我較強的資料決議能力,自己寫個方法來讀取這些東西,
處理代碼
xlsx檔案的本質是xml格式的壓縮包,解壓檔案做xml決議提取出相應的資料即可,
本來準備用lxml作xpath決議xml,但實際測驗發現,這些xml檔案存在大量的命名空間,決議起來例外復雜,試了好幾個普通的xml決議的庫,可以順利決議,但我覺得還不如正則方便,所以我最終選擇了使用正則運算式作xml決議,
最終處理代碼如下:
import re
import os
import shutil
from zipfile import ZipFile
def read_xlsx_textbox_text(xlsx_file):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
result = []
for xml_name in xml_names:
with open(xml_name, encoding="utf-8") as f:
text = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", text)
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
result.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
return "\n".join(result)
測驗一下:
result = read_xlsx_textbox_text("test.xlsx")
print(result)
結果:
什么是JSON?
就是一種資料格式;比如說,我們現在規定,有一個txt文本檔案,用來存放一個班級的成績;然后呢,我們規定,這個文本檔案里的學生成績的格式,是第一行,就是一行列頭(姓名 班級 年級 科目 成績),接下來,每一行就是一個學生的成績,那么,這個文本檔案內的這種資訊存放的格式,其實就是一種資料格式,
學生 班級 年級 科目 成績
張三 一班 大一 高數 90
李四 二班 大一 高數 80
ok,對應到JSON,它其實也是代表了一種資料格式,所謂資料格式,就是資料組織的形式,比如說,剛才所說的學生成績,用JSON格式來表示的話,如下:
[{"學生":"張三", "班級":"一班", "年級":"大一", "科目":"高數", "成績":90}, {"學生":"李四", "班級":"二班", "年級":"大一", "科目":"高數", "成績":80}]
其實,JSON,很簡單,一點都不復雜,就是對同樣一批資料的,不同的一種資料表示的形式,
JSON的資料語法,其實很簡單:如果是包含多個資料物體的話,比如說多個學生成績,那么需要使用陣列的表現形式,就是[],對于單個資料物體,比如一個學生的成績,那么使用一個{}來封裝資料,對于資料物體中的每個欄位以及對應的值,使用key:value的方式來表示,多個key-value對之間用逗號分隔;多個{}代表的資料物體之間,用逗號分隔,
...
這樣我們就順利實作了,從一個Excel檔案中,讀取全部的文本框的文本,
注意:如果你有啥特殊的其他需求,可以根據實際情況修改代碼,也可以聯系本文作者(小小明)進行相應的定制,
讀取xls檔案的文本框內容
上面的方法,僅支持xlsx格式檔案的讀取,如果要讀取xls格式,我們需要先進行格式轉換,
完整代碼:
import win32com.client as win32
def read_xls_textbox_text(xls_file):
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
# excel_app.DisplayAlerts = False
try:
wb = excel_app.Workbooks.Open(xls_file)
xlsx_file = xls_file+"x"
wb.SaveAs(xlsx_file, FileFormat=51)
finally:
excel_app.Quit()
return read_xlsx_textbox_text(xlsx_file)
如果你希望存在同名的xlsx檔案時不提示,關閉注釋即可
測驗讀取:
print(read_xls_textbox_text(r"E:\tmp\test2.xls"))
結果:
我們的資料從哪里來?
互聯網行業:網站、app、系統(交易系統,,)
傳統行業:電信,人們的上網、打電話、發短信等等資料
資料源:網站、app
都要往我們的后臺去發送請求,獲取資料,執行業務邏輯;app獲取要展現的商品資料;發送請求到后臺進行交易和結賬
后臺服務器,比如Tomcat、Jetty;但是,其實在面向大量用戶,高并發(每秒訪問量過萬)的情況下,通常都不會直接是用Tomcat來接收請求,這種時候,通常,都是用Nginx來接收請求,并且后端接入Tomcat集群/Jetty集群,來進行高并發訪問下的負載均衡,
比如說,Nginx,或者是Tomcat,你進行適當配置之后,所有請求的資料都會作為log存盤起來;接收請求的后臺系統(J2EE、PHP、Ruby On Rails),也可以按照你的規范,每接收一個請求,或者每執行一個業務邏輯,就往日志檔案里面打一條log,
網站/app會發送請求到后臺服務器,通常會由Nginx接收請求,并進行轉發
...
xls格式批量轉xlsx
假如我們有一批xls檔案,希望批量轉換為xlsx:
我的實作方式是整個檔案夾都轉換完畢再關閉應用,這樣相對來說處理更快一些,但可能更耗記憶體,代碼如下:
import win32com.client as win32 # 匯入模塊
from pathlib import Path
import os
def format_conversion(xls_path, output_path):
if not os.path.exists(output_path):
os.makedirs(output_path)
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xls_path).glob("[!~]*.xls"):
dest_name = f"{output_path}/{filename.name}x"
wb = excel_app.Workbooks.Open(filename)
wb.SaveAs(dest_name, FileFormat=51)
print(dest_name, "保存完成")
finally:
excel_app.Quit()
測驗一下:
excel_path = r"F:\excel檔案"
output_path = r"E:\tmp\excel"
format_conversion(excel_path, output_path)
結果:
E:\tmp\excel/008.離線日志采集流程.xlsx 保存完成
E:\tmp\excel/009.實時資料采集流程.xlsx 保存完成
E:\tmp\excel/011.用戶訪問session分析-模塊介紹.xlsx 保存完成
E:\tmp\excel/012.用戶訪問session分析-基礎資料結構以及大資料平臺架構介紹.xlsx 保存完成
E:\tmp\excel/013.用戶訪問session分析-需求分析.xlsx 保存完成
E:\tmp\excel/014.用戶訪問session分析-技術方案設計.xlsx 保存完成
E:\tmp\excel/015.用戶訪問session分析-資料表設計.xlsx 保存完成
E:\tmp\excel/018.用戶訪問session分析-JDBC原理介紹以及增刪改查示范.xlsx 保存完成
E:\tmp\excel/019.資料庫連接池原理.xlsx 保存完成
...
批量提取xlsx檔案的文本框文本
上面我們已經獲得了一個xlsx檔案的檔案夾,下面我們的需求是,提取這個檔案夾下每個xlsx檔案的文本框內容將其保存為對應的txt格式,
處理代碼:
from pathlib import Path
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
filename = str(filename)
destname = filename.replace(".xlsx", ".txt")
print(filename, destname)
txt = read_xlsx_textbox_text(filename)
with open(destname, "w") as f:
f.write(txt)
執行后,已經順利得到相應的txt檔案:
需求升級
上面的讀取方法是將整個excel檔案所有的文本框內容都合并在一起,但有時我們的excel檔案的多個sheet都存在文本框,我們希望能夠對不同的sheet進行區分:
下面我們改進我們的讀取方法,使其回傳每個sheet名對應的文本框文本,先測驗一下,
首先解壓所需的檔案:
from zipfile import ZipFile
from pathlib import Path
import shutil
import os
import tempfile
import re
xlsx_file = "test3.xlsx"
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
print(xml_names, sheets_names, ids)
結果:
['C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing1.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing2.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing3.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing4.xml', 'C:\\Users\\Think\\AppData\\Local\\Temp/xl/drawings/drawing5.xml'] C:\Users\Think\AppData\Local\Temp/xl/workbook.xml [0, 1, 2, 4, 5]
讀取sheet名稱:
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
sheet_names
結果:
['JSON', '資料庫連接池', '實時資料采集', '工廠設計模式', '頁面轉化率']
決議:
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
result
結果(省略了大部分文字):
{'JSON': '什么是JSON?....',
'資料庫連接池': 'java程式\n資料庫連接\n資料庫連接\n資料庫連接\nMySQL...',
'實時資料采集': '...實時資料,通常都是從分布式訊息佇列集群中讀取的,比如Kafka....',
'工廠設計模式': '如果沒有工廠模式,可能會出現的問題:....',
'頁面轉化率': '用戶行為分析大資料平臺\n\n頁面單跳轉化率,....'}
可以看到已經順利的讀取到每個sheet對應的文本框內容,而且一一對應,
分別讀取每個sheet對應文本框文本
我們整合并封裝一下上面的程序為一個方法:
import re
import os
from zipfile import ZipFile
import tempfile
def read_xlsx_textbox_text(xlsx_file, combine=False):
tempdir = tempfile.gettempdir()
basename = os.path.basename(xlsx_file)
xml_names = []
sheets_names = None
ids = []
with ZipFile(xlsx_file) as zip_file:
for name in zip_file.namelist():
if name.startswith("xl/drawings/drawing"):
zip_file.extract(name, tempdir)
destname = f"{tempdir}/{name}"
xml_names.append(destname)
elif name == "xl/workbook.xml":
zip_file.extract(name, tempdir)
sheets_names = f"{tempdir}/{name}"
elif name.startswith("xl/worksheets/_rels/sheet"):
tmp = name.lstrip("xl/worksheets/_rels/sheet")
ids.append(int(tmp[:tmp.find(".")])-1)
with open(sheets_names, encoding="utf-8") as f:
text = f.read()
sheet_names = re.findall(
'<sheet .*?name="([^"]+)" .*?/>', text)
tmp = []
for inx in ids:
tmp.append(sheet_names[inx])
sheet_names = tmp
result = {}
for sheet_name, xml_name in zip(sheet_names, xml_names):
with open(xml_name, encoding="utf-8") as f:
xml = f.read()
lines = re.findall("<a:p>(.*?)</a:p>", xml)
tmp = []
for line in lines:
runs = re.findall("<a:t>(.*?)</a:t>", line)
tmp.append("".join(runs).replace('<', '<').replace(
'>', '>').replace('&', '&'))
result[sheet_name] = "\n".join(tmp)
if combine:
return "\n".join(result.values())
return result
呼叫方式:
result = read_xlsx_textbox_text("test3.xlsx")
print(result)
可以傳入combine=True,將sheet的結果合并到一個文本,但這樣不如直接呼叫之前撰寫的方法,
批量提取文本框文本分sheet單獨保存
下面,我們的需求是對每個xlsx檔案創建一個同名檔案夾,每個檔案夾下根據sheet名稱單獨保存文本框的文本,
處理代碼:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
for filename in Path(xlsx_path).glob("[!~]*.xlsx"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_xlsx_textbox_text(filename)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
經測驗順利的為每個excel檔案創建了一個目錄,每個目錄下根據哪些sheet存在文本框就有相應的sheet名檔案,
使用Python呼叫VBA解決最終需求
VBA官方檔案地址:https://docs.microsoft.com/zh-cn/office/vba/api/overview/excel
整體而言,上面自行決議xml的方法還是挺麻煩的,在寫完上面的方法后我靈機一動,VBA不就有現成的讀取文本框的方法嗎?而Python又可以全兼容的寫VBA代碼,那問題就簡單了,通過VBA,不僅代碼簡單,而且不用考慮格式轉換的問題,直接可以解決問題,讀取代碼如下:
import win32com.client as win32
def read_excel_textbox_text(excel_file, app=None, combine=False):
if app is None:
excel_app = win32.gencache.EnsureDispatch('Excel.Application')
else:
excel_app = app
wb = excel_app.Workbooks.Open(excel_file)
result = {}
for sht in wb.Sheets:
if sht.Shapes.Count == 0:
continue
lines = []
for shp in sht.Shapes:
try:
text = shp.TextFrame2.TextRange.Text
lines.append(text)
except Exception as e:
pass
result[sht.Name] = "\n".join(lines)
if app is None:
excel_app.Quit()
if combine:
return "\n".join(result.values())
return result
測驗讀取:
result = read_excel_textbox_text(r'F:\jupyter\test\提取word圖片\test3.xlsx')
print(result)
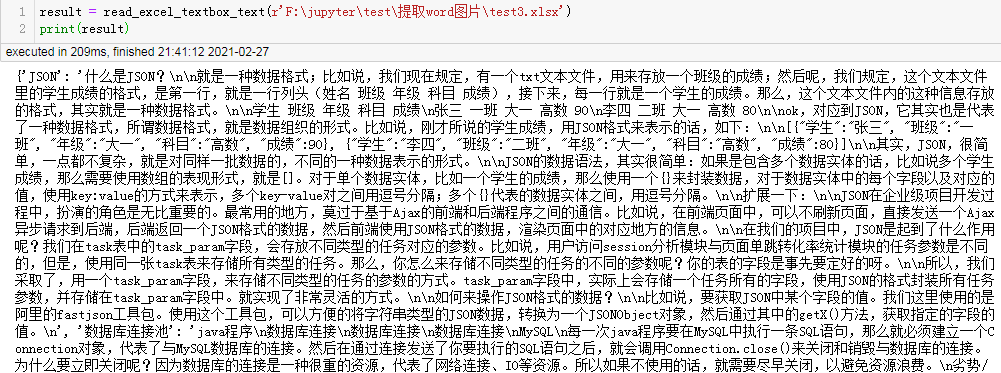
順利讀出結果,
批量處理:
from pathlib import Path
import os
xlsx_path = r"E:\tmp\excel"
app = win32.gencache.EnsureDispatch('Excel.Application')
try:
for filename in Path(xlsx_path).glob("[!~]*.xls"):
dest = filename.with_suffix("")
if not os.path.exists(dest):
os.mkdir(dest)
filename = str(filename)
print(filename, dest)
result = read_excel_textbox_text(filename, app)
for txtname, txt in result.items():
with open(f"{dest}/{txtname}", "w") as f:
f.write(txt)
print(f"\t{dest}/{txtname}")
finally:
app.Quit()
經測驗,VBA處理的缺點也很明顯,63個檔案耗時達到25秒,而直接決議xml耗時僅259毫秒,性能差別不在一個數量級,
總結
讀取excel中的資料,基本沒有VBA干不了的事,python呼叫VBA也很簡單,直接使用pywin32即可,當然2007的xlsx本質上是xml格式的壓縮包,決議xml文本也沒有讀不了的資料,只是代碼撰寫起來例外費勁,當然也得你對xlsx的存盤原理較為了解,
這樣VBA與直接決議xml的優劣勢就非常明顯了:
- VBA是excel應用直接支持的API,代碼撰寫起來相對很簡單,但執行效率低下,
- 直接決議xml檔案,需要對excel的存盤格式較為了解,編碼起來很費勁,但是執行效率極高,
作為讀者的你有何看法呢?歡迎你在下方留言區發表你的看法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264524.html
標籤:其他
上一篇:Golang面向物件編程—方法