1.1 LDPC碼介紹
低密度校驗碼(LDPC碼)是一種前向糾錯碼,它最初在 1962年由麻省理工學院的Galfager在其博士論文中提出,那時候,世界才剛剛脫離真空管,進入第一代晶體管時代,實驗仿真所要求的的計算能力并不發達,所以LDPC碼無與倫比的潛能沒能引起人們的重視,而被長久地忽視了35年,同一時期,主流的前向糾錯技
術是高度結構化的代數分組碼和卷積碼,盡管上述這些糾錯碼技術在實際中獲得了巨大的成功,但是它們的性能卻遠沒有達到Shalmon在其 1948年發表的開創性論文中所指出的理論可達限,到了20實際80年代末,經過幾十年的嘗試,學者們已經接受了這個理論與實際之間無法逾越的鴻溝,
編碼學研究經過了相當的一段沉寂之后,被“turbo碼”的出現徹底喚醒,turbo碼由B~u,Glavieux和Thitimajshima在1993年提出,它徹底顛覆了所有人們認為成功的糾錯碼所要具備的因素:turbo碼涉及非常少的代數,運用迭代,分布的演算法,專注于平均(而非最差)性能,同時仰賴從信道中獲取的軟(或者似然)信
息,一夜之間,在復雜度可控的譯碼器的協助下,達到Shannon限所要越過的鴻溝已不復存在,
LDPC碼不僅蘊含有很高的理論價值,而且已經為衛星數字視頻廣播標準和長途光通信標準所采納,還極有可能被吸收入IEEE無線局域網標準中,人們還正在考慮把LDPC碼應用到第四代移動電話系統的長期發展規劃中,
1.2 LDPC碼的特點
LDPC碼是一種分組碼,其校驗矩陣只含有很少量非零元素,正是校驗矩陣H的這種稀疏性,保證了譯碼復雜度和最小碼距都只隨碼長呈現線性增加,
除了校驗矩陣H是稀疏矩陣外,LDPC碼本身與任何其它的分組碼并無二致,其實如果現有的分組碼可以被稀疏矩陣所表達,那么用于LDPC碼的迭代譯碼演算法也可以成功的移植到它身上,然而,一般來說,為現有的分組碼找到一個稀疏矩陣并不實際,不同的是,LDPC碼的設計是以構造一個校驗矩陣開始的,然后才通過它確定一個生成矩陣進行后續編碼,而LDPC的編碼就是本論文所要討論的主體內容,
譯碼方法是LDPC碼與經典的分組碼之間的最大區別,經典的分組碼一般是用ML類的譯碼演算法進行譯碼的,所以它們一般碼長較小,并通過代數設計以減低譯碼作業的復雜度,但是LDPC碼碼長較長,并通過其校驗矩陣H的影像表達而進行迭代譯碼,所以它的設計以校驗矩陣H的特性為核心考慮之一,
目前的研究均表明LDPC碼是信道編碼中糾錯能力最強的一種碼,而且由于其譯碼器結構簡單,可以用較少的資源消耗獲得極高的吞吐量,因此應用前景相當廣泛,
1.3 LDPC 碼的歷史和現狀
LDPC 碼于 1962 年由 Gallager 提出,因此它也被稱為 Gallager 碼,它是Turbo 碼之外的另一種逼近香農極限的碼字,雖然 Gallager 證明了 LDPC 碼是漸進好碼,但是受限于當時的計算能力,LDPC 碼一度被認為是一種無法實作的信道編碼方式,在很長一段時間內沒有得到人們的重視,1981 年隨著 Tanner 著作的出現,LDPC 碼可以用圖論的角度進行新的理解和詮釋,然而不幸的是這一理論成果依然沒有得到人們的重視,知道 90 年代初,隨著 Turbo 碼的出現,這才引發了學者們對于 LDPC 碼研究的熱情,Mackay和 Neal 在上世紀九十年代利用隨機構造的 Tanner 圖研究了 LDPC 碼的性能,采用 Belief Propagation(BP 演算法)譯碼演算法的 LDPC 碼字具有與 Turbo 碼相似的譯碼性能,長的 LDPC 碼在 BP 譯碼演算法下性能甚至超過了 Turbo 碼,它可以達到距離香農限只有 0.1dB 的距離,這個發現是的 LDPC 碼比 Turbo 碼在需要高度可靠性的通信和存盤系統糾錯中更具有競爭力,從此以后,有關 LDPC碼的文獻大量涌現,
2.1 LDPC碼的編碼方法
2.1.1 LDPC碼的標準編碼方法
設LDPC碼的碼長為n,資訊碼長度為k,校驗碼長度為m=n-k.已經討論過,校驗矩陣H經過高斯消元可以化為:
H=[H Im*m]
其中H:是尺寸為mxk的二進制矩陣,可以得到:Imxm是尺寸為m、m的單位矩陣,于是可以得到:
G=[Ik*k H1]
通過生成矩陣G就可以進行編碼,以下用一個例子說明如何由校驗矩陣H得到生成矩陣G.
2.1.2 LU分解編碼演算法
首先推匯出根據校驗矩陣直接編碼的等式,將尺寸為mxn校驗矩陣H寫成如下形式:
H=[H1,H2]
其中H1的尺寸為M*K,H2的尺寸為m* m ,設編碼后的碼字行向量為x,它的長度為n,把它寫成如下形式:
c=[s p]
其中s是資訊碼行向量,長度為k,p為校驗碼行向量,長度為m.根據校驗等式有H×CT=O
上式展開得:
展開該矩陣方程,并考慮到運算是在GF(2)中進行,得到:
p·H2T=S·HT (2.1)
如果校驗矩陣H是非奇異,則HZ滿秩,所以有:
p=s·HT·H T (2.2)
式 (2.1)和式 (2.2)就是不通過生成矩陣而直接由校驗矩陣進行編碼的等式,一切只依賴校驗矩陣的編碼都是通過這兩個式子實作的,
從式(2.1)可以看出,一般來說,只要校驗矩陣具有下三角結構,它總是能夠通過迭代方法進行編碼的,引入了迭代,就大大降低了編碼的復雜度,LU分解編碼演算法就是以這個思想為基礎的,2.2 LDPC譯碼演算法
2.2.1訊息傳遞演算法:
在訊息傳遞 (MessagePassing,MP)演算法中,概率資訊依據二分圖在變數節點和校驗節點之間傳遞,逐步進行迭代譯碼,節點沿邊發送的資訊與上次從接收到的資訊無關,而取決于和相連的其它邊上接收的資訊,目的在于使得任一條邊上,只有外來資訊傳遞,從而保證譯碼性能,如果 1DPC碼對應的二分圖中不存在環,則任一節點接受的資訊都與從該節點發出的資訊無關,從而保證了迭代譯碼的性能,如果二分圖中存在環,經過一定次數的迭代之后,節點收到的資訊將將與其發出的資訊存在相關性,這將影響譯碼演算法的性能,
2.2.2最小和譯碼演算法:
最小和(Min一sum)譯碼演算法是根據對數域BP譯碼演算法提出的一種近似簡化演算法,它利用求最小值的運算簡化了函式運算,大大降低了運算復雜度且不需要對信道噪聲進行估計,但其性能也有一定程度的降低,
2.2.3位元翻轉譯碼演算法:
位元翻轉(Bit一Flipping,BF)譯碼演算法首先將輸入譯碼器的資料進行硬判決,然后將得到的“O”、“1”序列代入所有的校驗方程,找出使校驗方程不成立數目最多的變數節點,最后將該變數節點所對應的位元位翻轉,至此完成一次迭代,整個譯碼程序不斷地進行迭代,直到所有的校驗方程都成立或者達到了設定的最大迭代次數,位元翻轉譯碼演算法只進行位元位的翻轉等兒種簡單的運算,沒有復雜的操作,因此非常適合硬體實作,但其性能相對于BP譯碼演算法有所降低,適用于硬體條件受限而性能要求較低的場合,
附一部分關于位元翻轉譯碼仿真程式:
function vHat = decodeBitFlipping(rx, H, iteration)
% rx : Received signal vector (column vector)
% H : LDPC matrix
% iteration : Number of iteration
% vHat : Decoded vector (0/1)
[M N] = size(H);
% Prior hard-decision
ci = 0.5*(sign(rx') + 1);
% Initialization
rji = zeros(M, N);
% Asscociate the ci matrix with non-zero elements of H
qij = H.*repmat(ci, M, 1);
for n = 1:iteration
% ----- Horizontal step -----
for i = 1:M
c1 = find(H(i, :));
for k = 1:length(c1)
rji(i, c1(k)) = mod(sum(qij(i, c1)) + qij(i, c1(k)), 2);
end
end
% ------ Vertical step ------
for j = 1:N
r1 = find(H(:, j));
numOfOnes = length(find(rji(r1, j)));
for k = 1:length(r1)
% Update qij, set '1' for majority of 1s else '0', excluding r1(k)
if numOfOnes + ci(j) >= length(r1) - numOfOnes + rji(r1(k), j)
qij(r1(k), j) = 1;
else
qij(r1(k), j) = 0;
end
end
if numOfOnes + ci(j) >= length(r1) - numOfOnes
vHat(j) = 1;
else
vHat(j) = 0;
end
end
end
附一部分編碼程式:
function [c, newH] = makeParityChk(dSource, H, strategy)
% Generate parity check vector bases on LDPC matrix H using sparse LU decomposition
%
% dSource : Binary source (0/1)
% H : LDPC matrix
% strategy: Strategy for finding the next non-zero diagonal elements
% {0} First : First non-zero found by column search
% {1} Mincol : Minimum number of non-zeros in later columns
% {2} Minprod: Minimum product of:
% - Number of non-zeros its column minus 1
% - Number of non-zeros its row minus 1
%
% c : Check bits
% newH : Rearrange H
% Get the matric dimension
[M, N] = size(H);
% Set a new matrix F for LU decomposition
F = H;
% LU matrices
L = zeros(M, N - M);
U = zeros(M, N - M);
% Re-order the M x (N - M) submatrix
for i = 1:M
% strategy {0 = First; 1 = Mincol; 2 = Minprod}
switch strategy
% Create diagonally structured matrix using 'First' strategy
case {0}
% Find non-zero elements (1s) for the diagonal
[r, c] = find(F(:, i:end));
% Find non-zero diagonal element candidates
rowIndex = find(r == i);
% Find the first non-zero column
chosenCol = c(rowIndex(1)) + (i - 1);
% Create diagonally structured matrix using 'Mincol' strategy
case {1}
% Find non-zero elements (1s) for the diagonal
[r, c] = find(F(:, i:end));
colWeight = sum(F(:, i:end), 1);
% Find non-zero diagonal element candidates
rowIndex = find(r == i);
% Find the minimum column weight
[x, ix] = min(colWeight(c(rowIndex)));
% Add offset to the chosen row index to match the dimension of the...
% original matrix F
chosenCol = c(rowIndex(ix)) + (i - 1);
% Create diagonally structured matrix using 'Minprod' strategy
case {2}
% Find non-zero elements (1s) for the diagonal
[r, c] = find(F(:, i:end));
colWeight = sum(F(:, i:end), 1) - 1;
rowWeight = sum(F(i, :), 2) - 1;
% Find non-zero diagonal element candidates
rowIndex = find(r == i);
% Find the minimum product
[x, ix] = min(colWeight(c(rowIndex))*rowWeight);
% Add offset to the chosen row index to match the dimension of the...
% original matrix F
chosenCol = c(rowIndex(ix)) + (i - 1);
otherwise
fprintf('Please select columns re-ordering strategy!\n');
end % switch
% Re-ordering columns of both H and F
tmp1 = F(:, i);
tmp2 = H(:, i);
F(:, i) = F(:, chosenCol);
H(:, i) = H(:, chosenCol);
F(:, chosenCol) = tmp1;
H(:, chosenCol) = tmp2;
% Fill the LU matrices column by column
L(i:end, i) = F(i:end, i);
U(1:i, i) = F(1:i, i);
% There will be no rows operation at the last row
if i < M
% Find the later rows with non-zero elements in column i
[r2, c2] = find(F((i + 1):end, i));
% Add current row to the later rows which have a 1 in column i
F((i + r2), :) = mod(F((i + r2), :) + repmat(F(i, :), length(r2), 1), 2);
end % if
end % for i
% Find B.dsource
z = mod(H(:, (N - M) + 1:end)*dSource, 2);
% Parity check vector found by solving sparse LU
c = mod(U\(L\z), 2);
% Return the rearrange H
newH = H;
fprintf('Message encoded.\n');
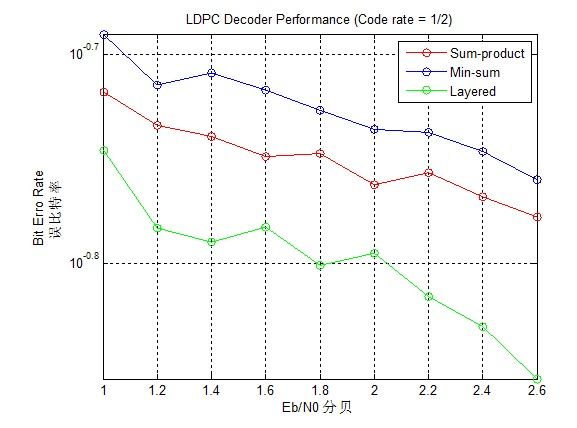
基本仿真結果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/264526.html
標籤:其他
下一篇:長江雨課堂