作為一個小型專案,使用一臺 Redis 服務器已經非常足夠了,然而現實中的 專案通常需要若干臺Redis服務器的支持:
- 從結構上,單個 Redis 服務器會發生單點故障,同時一臺服務器需要承受所有的請求負載,這就需要為資料生成多個副本并分配在不同的服務器上;
- 從容量上,單個 Redis 服務器的記憶體非常容易成為存盤瓶頸,所以需要進行資料分 片,
同時擁有多個 Redis 服務器后就會面臨如何管理集群的問題,包括如何增加節點、故障 恢復等操作, 為此,本章將依次詳細介紹 Redis 中的復制、哨兵(sentinel)和集群(cluster)的使用 和原理,
一、概述
通過持久化功能,Redis保證了即使在服務器重啟的情況下也不會損失(或少量損失)數 據,但是由于資料是存盤在一臺服務器上的,如果這臺服務器出現硬碟故障等問題,也會導 致資料丟失,為了避免單點故障,通常的做法是將資料庫復制多個副本以部署在不同的服務 器上,這樣即使有一臺服務器出現故障,其他服務器依然可以繼續提供服務,
為此, Redis 提供了復制(replication)功能,可以實作當一臺資料庫中的資料更新后,自動將更新的資料 同步到其他資料庫上,
二、配置
在復制的概念中,資料庫分為兩類,一類是主資料庫(master),另一類是從資料庫(slave),
主資料庫可以進行讀寫操作,當寫操作導致資料變化時會自動將資料同步給從數 據庫,
而從資料庫一般是只讀的,并接受主資料庫同步過來的資料,一個主資料庫可以擁有 多個從資料庫,而一個從資料庫只能擁有一個主資料庫
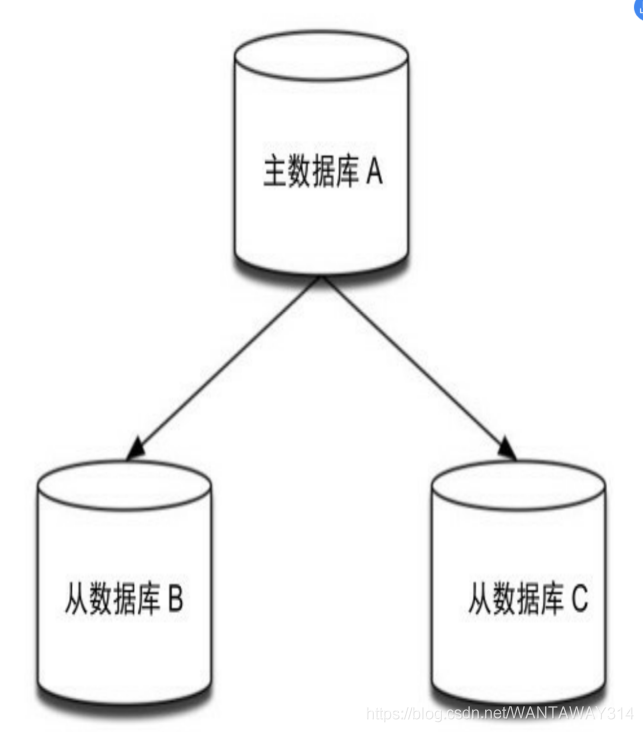
在 Redis 中使用復制功能非常容易,只需要在從資料庫的組態檔中加入“slaveof 主數 據庫地址 主資料庫埠”即可,主資料庫無需進行任何配置,
三、原理
Redis實作復制的程序:
當一個從資料庫啟動后,會向主資料庫發sync命令,主資料庫收到sync命令開始在后臺保存快照(即RDB持久化的程序)并將保存快照期間收到的命令快取起來,當快照完成后,redis會將快照檔案和所有的快取命令發送給從資料庫,從資料庫收到后,會載入快照檔案并執行收到的快取的命令,
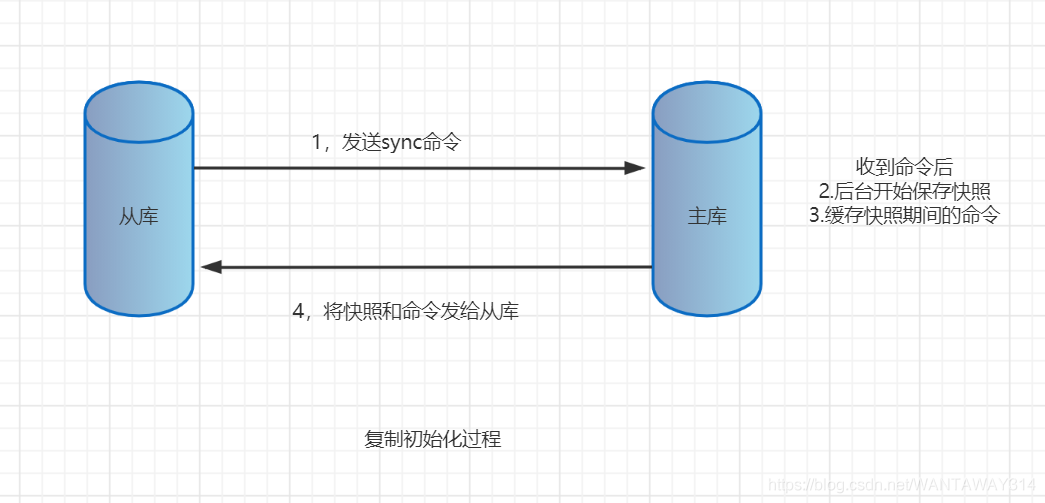
上面程序稱為復制初始化,,復制初始化結束 后,主資料庫每當收到寫命令時就會將命令同步給從資料庫,從而保證主從資料庫資料一 致,
當主從資料庫之間的連接斷開重連后,Redis 2.6以及之前的版本會重新進行復制初始化 (即主資料庫重新保存快照并傳送給從資料庫),即使從資料庫可以僅有幾條命令沒有收到,主資料庫也必須要將資料庫里的所有資料重新傳送給從資料庫,這使得主從資料庫斷線 重連后的資料恢復程序效率很低下,在網路環境不好的時候這一問題尤其明顯,Redis 2.8版 的一個重要改進就是斷線重連能夠支持有條件的增量資料傳輸,當從資料庫重新連接上主數 據庫后,主資料庫只需要將斷線期間執行的命令傳送給從資料庫,從而大大提高Redis復制的 實用性,
四、圖結構
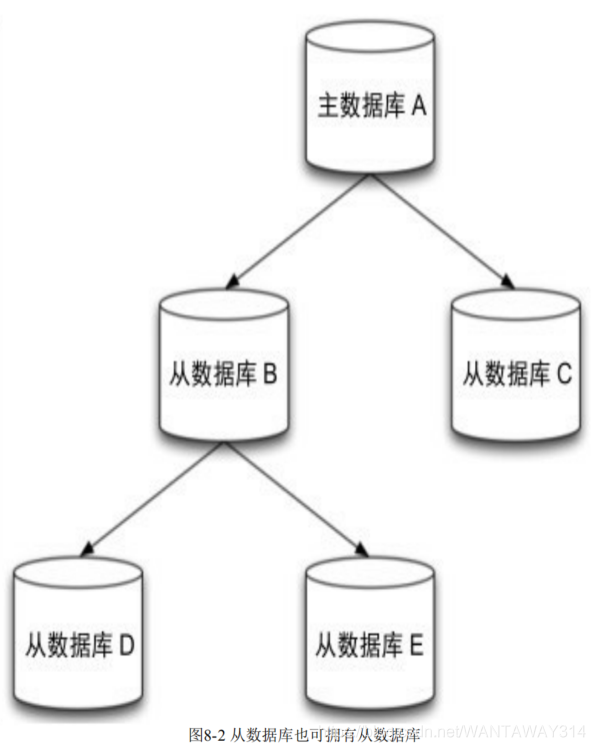
從資料庫不僅可以接收主資料庫的同步資料,自己也可以同時作為主資料庫存在,形成 類似圖的結構,如圖所示,資料庫A的資料會同步到B和C中,而B中的資料會同步到D和E 中,向B中寫入資料不會同步到A或C中,只會同步到D和E中,
五、讀寫分離與一致性
通過復制可以實作讀寫分離,以提高服務器的負載能力,在常見的場景中(如電子商務 網站),讀的頻率大于寫,當單機的Redis無法應付大量的讀請求時(尤其是較耗資源的請
求,如 SORT 命令等)可以通過復制功能建立多個從資料庫節點,主資料庫只進行寫操作, 而從資料庫負責讀操作,這種一主多從的結構很適合讀多寫少的場景,而當單個的主資料庫 不能夠滿足需求時,就需要使用Redis 3.0 推出的集群功能,后續介紹;
六、從資料庫持久化
另一個相對耗時的操作是持久化,為了提高性能,可以通過復制功能建立一個(或若干個)從資料庫,并在從資料庫中啟用持久化,同時在主資料庫禁用持久化,當從資料庫崩潰重啟后主資料庫會自動將資料同步過來,所以無需擔心資料丟失,
然而當主資料庫崩潰時,情況就稍顯復雜了,手工通過從資料庫資料恢復主資料庫資料 時,需要嚴格按照以下兩步進行:
- 在
從資料庫中使用 SLAVEOF NO ONE命令將從資料庫提升成主資料庫繼續服務, - 啟動之前崩潰的主資料庫,然后使用SLAVEOF命令將其設定成新的主資料庫的從 資料庫,即可將資料同步回來,
注意 當開啟復制且主資料庫關閉持久化功能時,一定不要使用 Supervisor 以及類似的行程管理工具令主資料庫崩潰后自動重啟,同樣當主資料庫所在的服務器因故關閉時,也要避免直接重新啟動,這是因為當主資料庫重新啟動后,因為沒有開啟持久化功能,所以資料庫 中所有資料都被清空,這時從資料庫依然會從主資料庫中接收資料,使得所有從資料庫也被 清空,導致從資料庫的持久化失去意義,
無論哪種情況,手工維護從資料庫或主資料庫的重啟以及資料恢復都相對麻煩,好在 Redis提供了一種自動化方案哨兵來實作這一程序,避免了手工維護的麻煩和容易出錯的問 題,
七、無硬碟復制
前面介紹Redis復制的作業原理時介紹了復制是基于RDB方式的持久化實作的,即主數 據庫端在后臺保存 RDB 快照,從資料庫端則接收并載入快照檔案,這樣的實作優點是可以 顯著地簡化邏輯,復用已有的代碼,但是缺點也很明顯,
- 當主資料庫禁用RDB快照時(即洗掉了所有的組態檔中的save陳述句),如果執行 了復制初始化操作,Redis依然會生成RDB快照,所以下次啟動后主資料庫會以該快斬訓復數 據,因為復制發生的時間不能確定,這使得恢復的資料可能是任何時間點的,
- 因為復制初始化時需要在硬碟中創建RDB快照檔案,所以如果硬碟性能很慢(如 網路硬碟)時這一程序會對性能產生影響,舉例來說,當使用 Redis 做快取系統時,因為不 需要持久化,所以服務器的硬碟讀寫速度可能較差,但是當該快取系統使用一主多從的集群 架構時,每次和從資料庫同步,Redis都會執行一次快照,同時對硬碟進行讀寫,導致性能降 低,
因此從2.8.18版本開始,Redis引入了無硬碟復制選項,開啟該選項時,Redis在與從資料 庫進行復制初始化時將不會將快照內容存盤到硬碟上,而是直接通過網路發送給從資料庫, 避免了硬碟的性能瓶頸,
目前無硬碟復制的功能還在試驗階段,可以在組態檔中使用如下配置來開啟該功能: repl-diskless-sync yes
八、增量復制
前面在介紹復制的原理時提到當主從資料庫連接斷開后,從資料庫會發送SYNC命令 來重新進行一次完整復制操作,這樣即使斷開期間資料庫的變化很小(甚至沒有),也需要 將資料庫中的所有資料重新快照并傳送一次,在正常的網路應用環境中,這種實作方式顯然 不太理想,Redis 2.8版相對2.6版的最重要的更新之一就是實作了主從斷線重連的情況下的增量復制,
增量復制是基于如下3點實作的.
- 從資料庫會存盤主資料庫的運行ID(run id),每個Redis 運行實體均會擁有一個 唯一的運行ID,每當實體重啟后,就會自動生成一個新的運行ID,
- 在復制同步階段,主資料庫每將一個命令傳送給從資料庫時,都會同時把該命令 存放到一個積壓佇列(backlog)中,并記錄下當前積壓佇列中存放的命令的偏移量范圍,
- 同時,從資料庫接收到主資料庫傳來的命令時,會記錄下該命令的偏移量,
這3點是實作增量復制的基礎,回到之前的主從通信流程,可以看到,當主從連接準 備就緒后,從資料庫會發送一條 SYNC 命令來告訴主資料庫可以開始把所有資料同步過來 了,而 2.8 版之后,不再發送 SYNC命令,取而代之的是發送 PSYNC,格式為“PSYNC主數 據庫的運行 ID 斷開前最新的命令偏移量”,主資料庫收到 PSYNC命令后,會執行以下判斷 來決定此次重連是否可以執行增量復制,
- 首先主資料庫會判斷從資料庫傳送來的運行ID是否和自己的運行ID相同,這一步 驟的意義在于確保從資料庫之前確實是和自己同步的,以免從資料庫拿到錯誤的資料(比如 主資料庫在斷線期間重啟過,會造成資料的不一致),
- 然后判斷從資料庫最后同步成功的命令偏移量是否在積壓佇列中,如果在則可以 執行增量復制,并將積壓佇列中相應的命令發送給從資料庫,
如果此次重連不滿足增量復制的條件,主資料庫會進行一次全部同步(即與Redis 2.6的 程序相同),
大部分情況下,增量復制的程序對開發者來說是完全透明的,開發者不需要關心增量復 制的具體細節,2.8 版本的主資料庫也可以正常地和舊版本的從資料庫同步(通過接收SYNC 命令),同樣 2.8 版本的從資料庫也可以與舊版本的主資料庫同步(通過發送 SYNC命 令),唯一需要開發者設定的就是積壓佇列的大小了,
積壓佇列在本質上是一個固定長度的回圈佇列,默認情況下積壓佇列的大小為 1 MB, 可以通過組態檔的repl-backlog-size選項來調整,很容易理解的是,積壓佇列越大,其允許 的主從資料庫斷線的時間就越長,根據主從資料庫之間的網路狀態,設定一個合理的積壓隊 列很重要,因為積壓佇列存盤的內容是命令本身,如 SET foo bar,所以估算積壓佇列的大小 只需要估計主從資料庫斷線的時間中主資料庫可能執行的命令的大小即可,
與積壓佇列相關的另一個配置選項是repl-backlog-ttl,即當所有從資料庫與主資料庫斷開 連接后,經過多久時間可以釋放積壓佇列的記憶體空間,默認時間是1小時,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/265448.html
標籤:其他
上一篇:【天工Godwork精品教程】任務二:匯入控制點、POS權重設定、連接點分布檢查、自由空三
下一篇:Linux執行緒的創建與回收