1.Flink 概述
Apache Flink 官網:https://flink.apache.org/
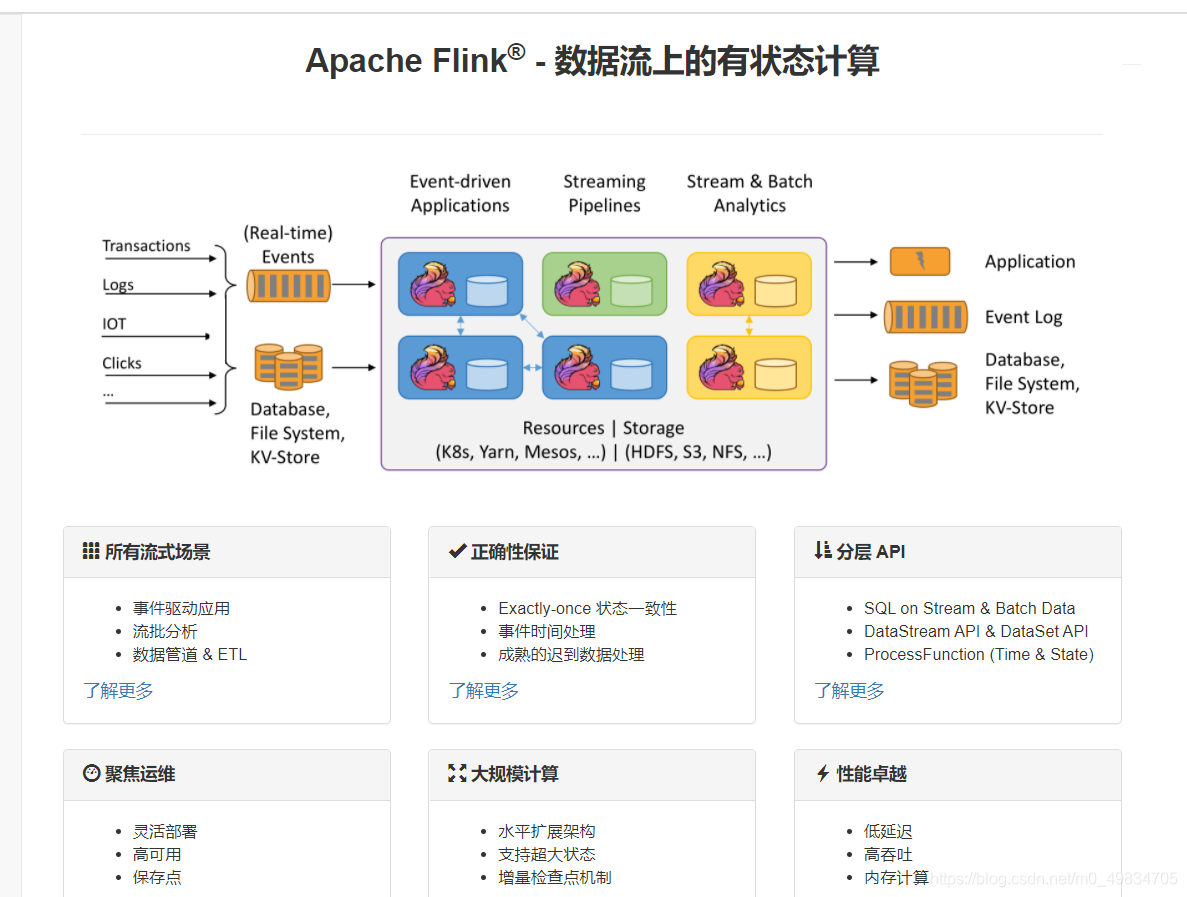
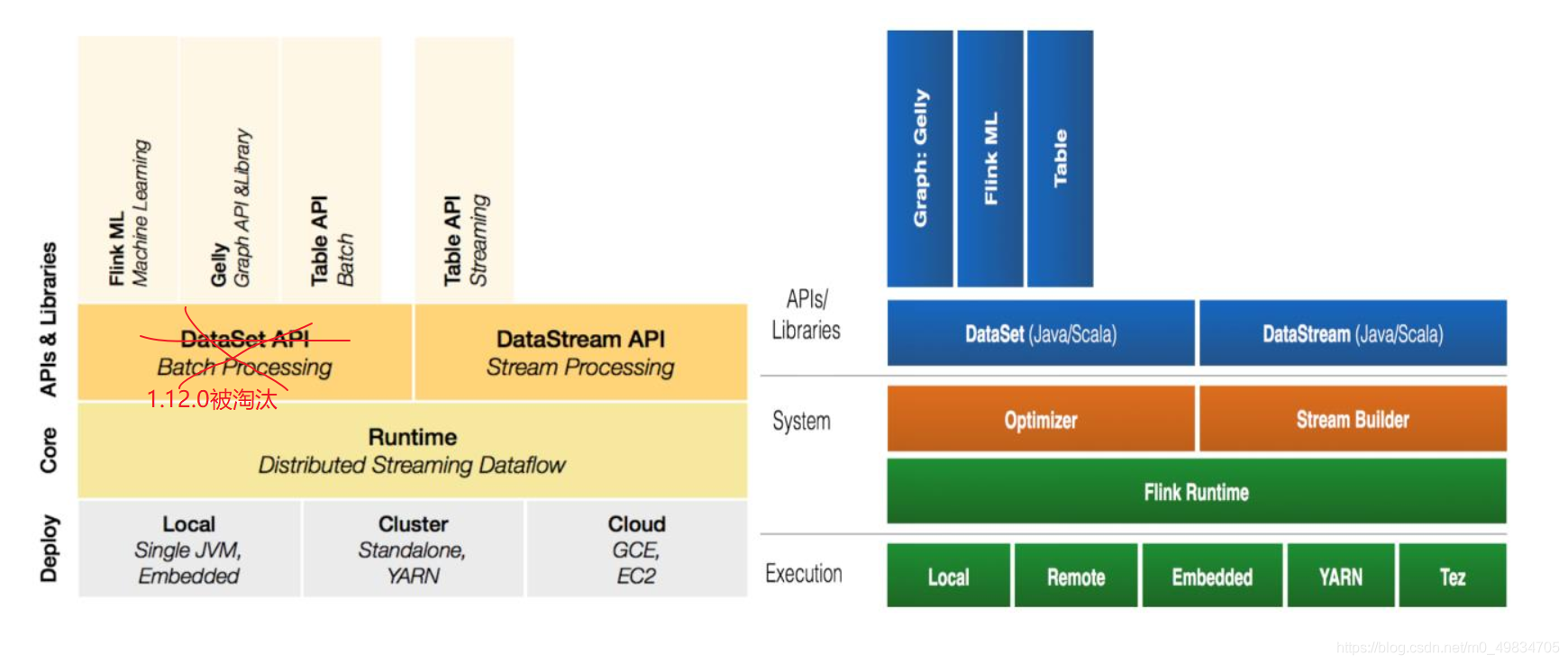
- 注意: 在Flink 1.12.0 中淘汰了 DatasetAPI 統一使用了 DataStreamAPI
2. 實時既未來

為什么說流處理即未來? https://news.qudong.com/article/562521.shtml
3.Flink的背景

- Flink 誕生于歐洲的一個大資料研究專案 StratoSphere,該專案是柏林工業大學的一個研究性專案,早期,Flink 是做 Batch 計算的,但是在 2014 年, StratoSphere 里面的核心成員范訓出 Flink,同年將 Flink 捐贈 Apache,并在后來成為 Apache 的頂級大資料專案,同時 Flink 計算的主流方向被定位為 Streaming, 即用流式計算來做所有大資料的計算,這就是 Flink 技術誕生的背景,
- 2014 年 Flink 作為主攻流計算的大資料引擎開始在開源大資料行業內嶄露頭角,區別于Storm、Spark Streaming 以及其他流式計算引擎的是:它不僅是一個高吞吐、低延遲的計算引擎,同時還提供很多高級的功能,比如它提供了有狀態的計算,支持狀態管理,支持強一致性的資料語意以及支持 基于Event Time的WaterMark對延遲或亂序的資料進行處理等
4. Flink技術堆疊
- Flink分層組件堆疊如下圖所示:
5. Flink的四大基石
- Flink之所以能這么流行,離不開它最重要的四個基石:Checkpoint、State、Time、Window,


6. Flink的應用場景
http://www.liaojiayi.com/flink-IoT/
https://flink.apache.org/zh/usecases.html
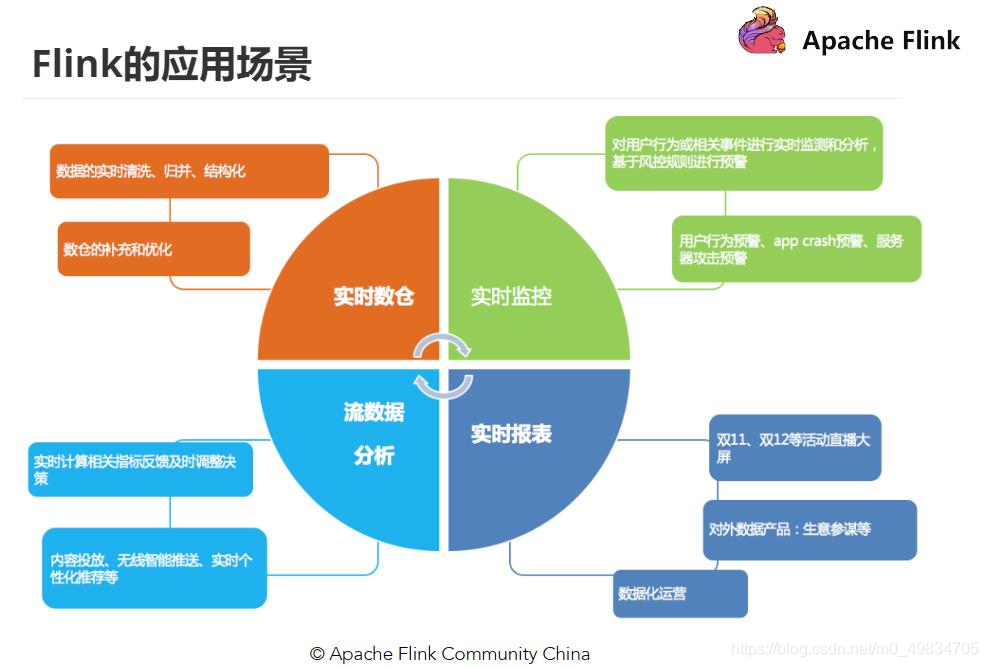
從很多公司的應用案例發現,其實Flink主要用在如下三大場景:
- Event-driven Applications(事件驅動應用):

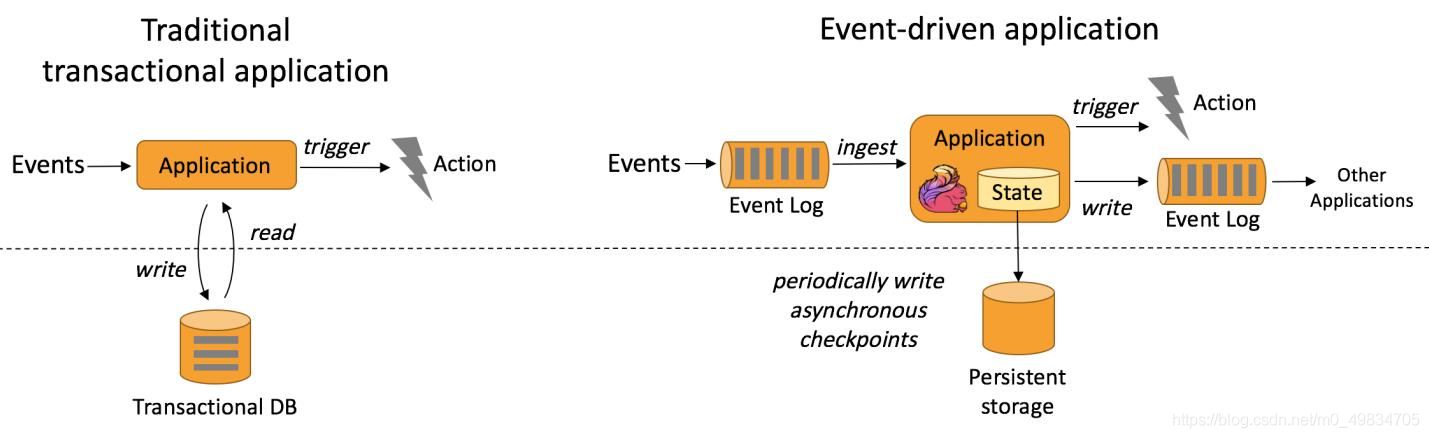
- 流計算本質上是Data Driven 計算,
- 應用較多的如風控系統,當風控系統需要處理各種各樣復雜的規則時,Data Driven 就會把處理的規則和邏輯寫入到Datastream 的API 或者是ProcessFunction 的API 中,然后將邏輯抽象到整個Flink 引擎,當外面的資料流或者是事件進入就會觸發相應的規則,這就是Data Driven 的原理,在觸發某些規則后,Data Driven 會進行處理或者是進行預警,這些預警會發到下游產生業務通知,這是Data Driven 的應用場景,Data Driven 在應用上更多應用于復雜事件的處理.
典型實體: - 欺詐檢測(Fraud detection)、例外檢測(Anomaly detection)
- 基于規則的告警(Rule-based alerting)
- 業務流程監控(Business process monitoring)
- Web應用程式(社交網路)
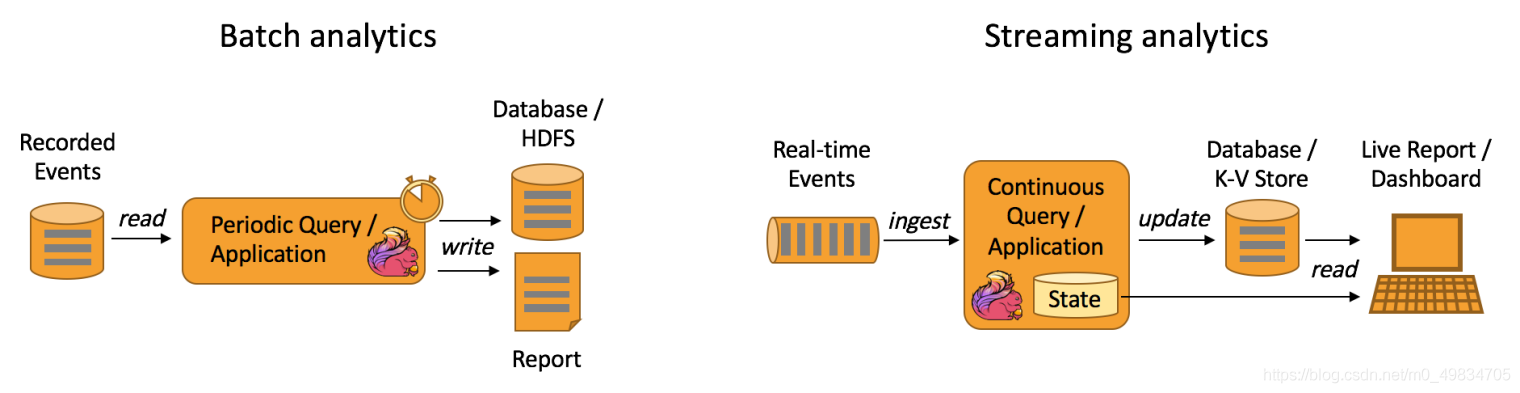
- Data Analytics Applications
資料分析任務需要從原始資料中提取有價值的資訊和指標,如下圖所示,Apache Flink 同時支持流式及批量分析應用,

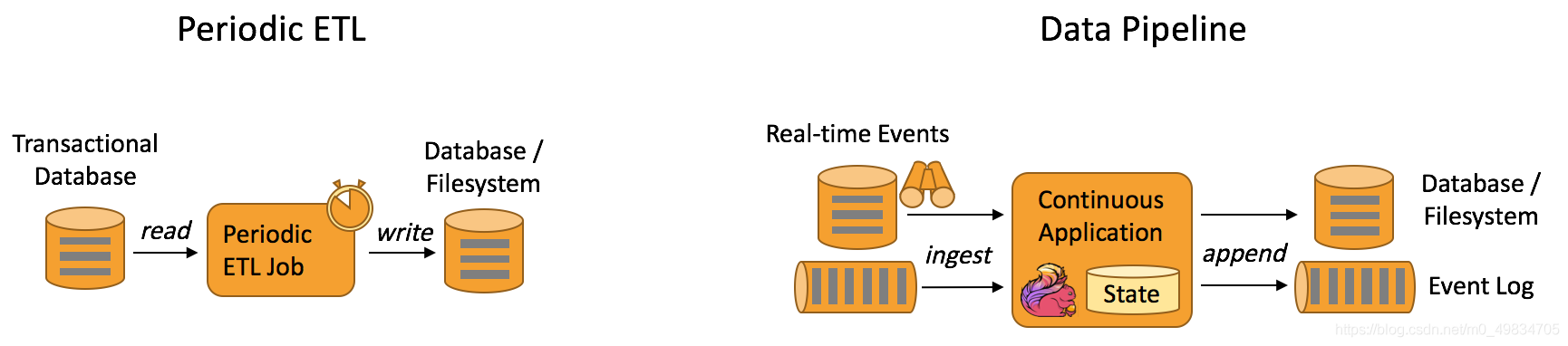
- Data Pipeline Applications:
資料管道: 提取-轉換-加載(ETL)是一種在存盤系統之間進行資料轉換和遷移的常用方法,
- ETL 作業通常會周期性地觸發,將資料從事務型資料庫拷貝到分析型資料庫或資料倉庫,
- 資料管道和 ETL 作業的用途相似,都可以轉換、豐富資料,并將其從某個存盤系統移動到另一個,但資料管道是以持續流模式運行,而非周期性觸發,因此資料管道支持從一個不斷生成資料的源頭讀取記錄,并將它們以低延遲移動到終點,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/265887.html
標籤:其他
上一篇:前端構架模式MVC與MVVM
下一篇:Java真的要沒落了?