目錄
- 一、關系資料庫與非關系型資料
- 1、關系型資料庫
- 2、非關系型資料庫
- 3、關系資料庫與非關系型資料庫區別
- (1)資料存盤方式不
- (2)擴展方式不同
- (3)對事務性的支持不同
- 4、非關系型資料庫產生背景
- 5、總結
- 二、Redis資料庫概述
- 1、Redis簡介
- 2、Redis 優點
- 三、Redis 安裝部署
- 1、編譯安裝redis
- 2、執行軟體包自帶的install_server.sh腳本檔案設定redid服務相關配置
- 3、把redis的可執行程式檔案放入路徑環境變數的目錄中便于系統識別
- 4、修改配置 /etc/redis/6379.conf 引數
- 四、Redis 命令工具
- 1、redis-cli 命令列工具
- 2、redis-benchmark 測驗工具
- 3、Redis 資料庫常用命令
- (1)set/get 存放/獲取資料
- (2)keys 取值
- (3)exists 判斷值是否存在
- (4)del 洗掉key
- (5)type 獲取值的型別
- (6)rename 重命名(覆寫)
- (7)renamenx 重命名(不覆寫)
- (8)dbsize 查看庫中key的數量
- (9)設定密碼
- 4、Redis 多資料庫常用命令
- (1)多資料庫間切換
- (2)多資料庫間移動資料
- (3)清除資料庫內資料
- 五、Redis 高可用
- 六、Redis 持久化
- 1、RDB 持久化
- (1)觸發條件
- (2)執行流程
- (3)啟動時加載
- 2、AOF 持久化
- (1) 開啟AOF
- (2)執行流程
- (3)檔案重寫的流程
- (4)啟動時加載
- 3、RDB和AOF的優缺點
- 七、Redis 性能管理
- 1、查看Redis記憶體使用
- 2、記憶體碎片率
- 3、記憶體使用率
- 4、內回收key
一、關系資料庫與非關系型資料
1、關系型資料庫
- 一個結構化的資料庫,創建在關系模型(二維表格模型)基礎上
- 一般面向于記錄
- SQL 陳述句(標準資料查詢語言)就是一種基于關系型資料庫的語言
- 用于執行對關系型資料庫中資料的檢索和操作,
- 主流的關系型資料庫包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2 等,
2、非關系型資料庫
- NoSQL(NoSQL = Not Only SQL ),意思是“不僅僅是 SQL”,是非關系型資料庫的總稱,
- 除了主流的關系型資料庫外的資料庫,都認為是非關系型,
- 主流的 NoSQL 資料庫有 Redis、MongBD、Hbase、CouhDB 等,
3、關系資料庫與非關系型資料庫區別
(1)資料存盤方式不
關系型和非關系型資料庫的主要差異是資料存盤的方式,
- 關系型資料天然就是表格式的,因此存盤在資料表的行和列中,資料表可以彼此關聯協作存盤,也很容易提取資料,
- 與其相反,非關系型資料不適合存盤在資料表的行和列中,而是大塊組合在一起,非關系型資料通常存盤在資料集中,就像檔案、鍵值對或者圖結構,
- 你的資料及其特性是選擇資料存盤和提取方式的首要影響因素,
(2)擴展方式不同
SQL和NoSQL資料庫最大的差別可能是在擴展方式上,要支持日益增長的需求當然要擴展,
- 要支持更多并發量,SQL資料庫是縱向擴展,也就是說提高處理能力,使用速度更快速的計算機,這樣處理相同的資料集就更快了,因為資料存盤在關系表中,操作的性能瓶頸可能涉及很多個表,這都需要通過提高計算機性能來客服,雖然SQL資料庫有很大擴展空間,但最終肯定會達到縱向擴展的上限,
- 而NoSQL資料庫是橫向擴展的,因為非關系型資料存盤天然就是分布式的,NoSQL資料庫的擴展可以通過給資源池添加更多普通的資料庫服務器(節點)來分擔負載,
(3)對事務性的支持不同
- 如果資料操作需要高事務性或者復雜資料查詢需要控制執行計劃,那么傳統的SQL資料庫從性能和穩定性方面考慮是你的最佳選擇,SQL資料庫支持對事務原子性細粒度控制,并且易于回滾事務,
- 雖然NoSQL資料庫也可以使用事務操作,但穩定性方面沒法和關系型資料庫比較,所以它們真正閃亮的價值是在操作的擴展性和大資料量處理方面,
4、非關系型資料庫產生背景
High performance——對資料庫高并發讀寫需求
Huge Storage——對海量資料高效存盤與訪問需求
High Scalability && High Availability——對資料庫高可擴展性與高可用性需求
5、總結
關系型資料庫:
實體–>資料庫–>表(table)–>記錄行(row)、資料欄位(column)
非關系型資料庫:
實體–>資料庫–>集合(collection)–>鍵值對(key-value)
非關系型資料庫不需要手動建資料庫和集合(表),
二、Redis資料庫概述
1、Redis簡介
- Redis 是一個開源的、使用 C 語言撰寫的 NoSQL 資料庫,
- Redis 基于記憶體運行并支持持久化,采用key-value(鍵值對)的存盤形式,是目前分布式架構中不可或缺的一環,
- Redis服務器程式是單行程模型,也就是在一臺服務器上可以同時啟動多個Redis行程,Redis的實際處理速度則是完全依靠于主行程的執行效率,
- 若在服務器上只運行一個Redis行程,當多個客戶端同時訪問時,服務器的處理能力是會有一定程度的下降;
- 若在同一臺服務器上開啟多個Redis行程,Redis在提高并發處理能力的同時會給服務器的CPU造成很大壓力
- 所以在實際生產環境中,需要根據實際的需求來決定開啟多少個Redis行程,
- 若對高并發要求更高一些,可能會考慮在同一臺服務器上開啟多個行程,
- 若 CPU 資源比較緊張,采用單行程即可,
2、Redis 優點
- 具有極高的資料讀寫速度:資料讀取的速度最高可達到 110000 次/s,資料寫入速度最高可達到 81000 次/s,
- 支持豐富的資料型別:支持 key-value、Strings、Lists、Hashes、Sets 及 Ordered Sets 等資料型別操作,
- 支持資料的持久化:可以將記憶體中的資料保存在磁盤中,重啟的時候可以再次加載進行使用,
- 原子性:Redis 所有操作都是原子性的,
- 支持資料備份:即 master-salve 模式的資料備份,
三、Redis 安裝部署
軟體包提取碼zqzq
systemctl stop firewalld
setenforce 0
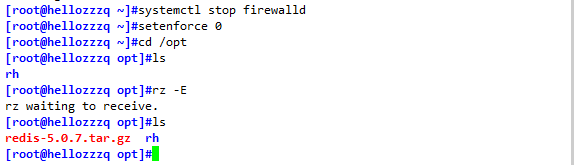
1、編譯安裝redis
cd /opt/
yum install -y gcc gcc-c++ make #安裝編譯環境和編譯器
tar zxvf redis-5.0.7.tar.gz #解壓檔案到當前目錄下
cd /opt/redis-5.0.7/ #切換到解壓出的檔案
make && make PREFIX=/usr/local/redis install #編譯安裝并指定安裝目錄/usr/local/redis
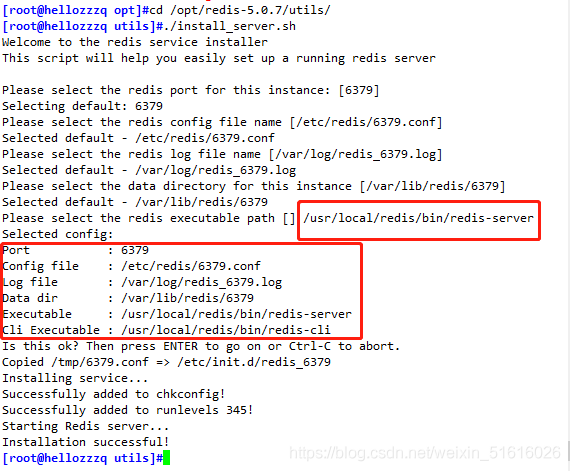
2、執行軟體包自帶的install_server.sh腳本檔案設定redid服務相關配置
cd /opt/redis-5.0.7/utils
./install_server.sh
……
慢慢回車
Please select the redis executable path []
手動輸入 /usr/local/redis/bin/redis-server
#要一次性輸入正確,不然還要重新執行
Selected config:
Port : 6379 #默認偵聽埠為6379
Config file : /etc/redis/6379.conf #組態檔路徑
Log file : /var/log/redis_6379.log #日志檔案路徑
Data dir : /var/lib/redis/6379 #資料檔案路徑
Executable : /usr/local/redis/bin/redis-server #可執行檔案路徑
Cli Executable : /usr/local/bin/redis-cli #客戶端命令工具
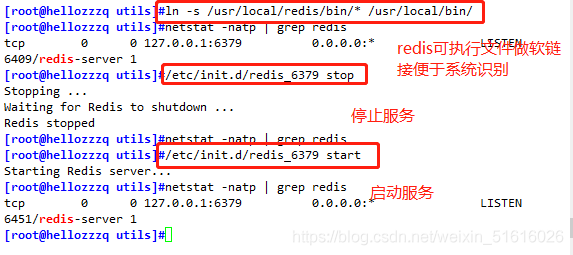
3、把redis的可執行程式檔案放入路徑環境變數的目錄中便于系統識別
ln -s /usr/local/redis/bin/* /usr/local/bin/
#當install_server.sh 腳本運行完畢,Redis服務就已經啟動,默認偵聽埠為6379
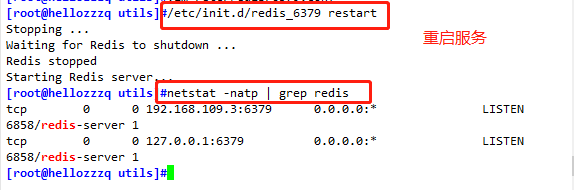
netstat -natp | grep redis
#redis服務控制
/etc/init.d/redis_6379 stop #停止
/etc/init.d/redis_6379 start #啟動
/etc/init.d/redis_6379 restart #重啟
/etc/init.d/redis_6379 status #狀態
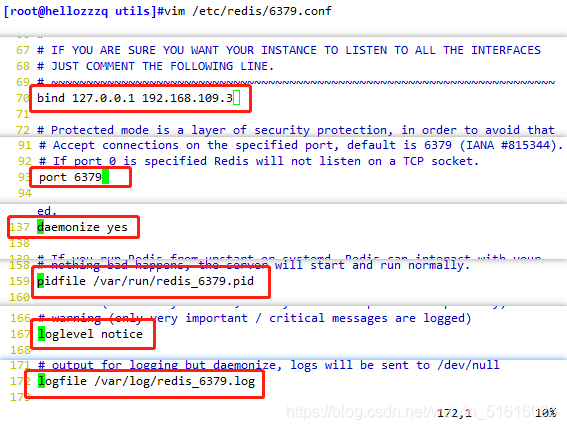
4、修改配置 /etc/redis/6379.conf 引數
vim /etc/redis/6379.conf
#70行;添加;監聽的主機地址
bind 127.0.0.1 192.168.109.3
#93行;Redis默認的監聽埠
port 6379
#137行;啟用守護行程
daemonize yes
#159行;指定 PID 檔案
pidfile /var/run/redis_6379.pid
#167行;日志級別
loglevel notice
#172行;指定日志檔案
logfile /var/log/redis_6379.log
/etc/init.d/redis_6379 restart
四、Redis 命令工具
redis-server 用于啟動 Redis 的工具
redis-benchmark 用于檢測 Redis 在本機的運行效率
redis-check-aof 修復 AOF 持久化檔案
redis-check-rdb 修復 RDB 持久化檔案
redis-cli Redis命令列工具
1、redis-cli 命令列工具
語法:redis-cli -h host -p port -a password
-h 指定遠程主機
-p 指定 Redis 服務的埠號
-a 指定密碼,未設定資料庫密碼可以省略-a 選項
若不添加任何選項表示,則使用 127.0.0.1:6379 連接本機上的 Redis 資料庫
例:
redis-cli -h 192.168.109.3 -p 6379
#此時無密碼,不需要-a直接登陸

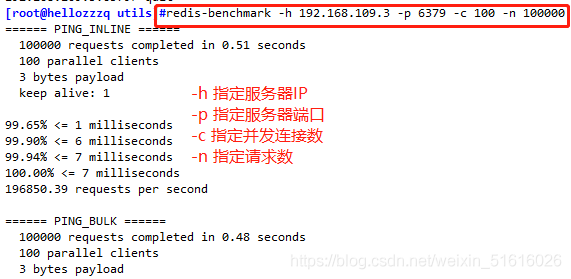
2、redis-benchmark 測驗工具
基本的測驗語法:redis-benchmark [選項] [選項值],
#redis-benchmark 是官方自帶的 Redis 性能測驗工具,可以有效的測驗 Redis 服務的性能,
-h 指定服務器主機名,
-p 指定服務器埠,
-s 指定服務器 socket
-c 指定并發連接數,
-n 指定請求數,
-d 以位元組的形式指定 SET/GET 值的資料大小,
-k 1=keep alive 0=reconnect ,
-r SET/GET/INCR 使用隨機 key, SADD 使用隨機值,
-P 通過管道傳輸請求,
-q 強制退出 redis,僅顯示 query/sec 值,
--csv 以 CSV 格式輸出,
-l 生成回圈,永久執行測驗,
-t 僅運行以逗號分隔的測驗命令串列,
-I Idle 模式,僅打開 N 個 idle 連接并等待,


3、Redis 資料庫常用命令
(1)set/get 存放/獲取資料
set 存放資料,命令格式為 set key value
get 獲取資料,命令格式為 get key

(2)keys 取值
keys 命令可以取符合規則的鍵值串列,通常情況可以結合*、?等選項來使用,
#存放鍵
set a1 1
set a2 2
set a33 3
set b1 4
set b2 5
set b33 6
keys * #查看所有鍵
keys b* #查看b開頭所有鍵
keys b? #查看b開頭且后面跟任意一位的鍵
keys b?? #查看b開頭且后面跟任意兩位的鍵
(3)exists 判斷值是否存在
exists 命令可以判斷鍵值是否存在,

(4)del 洗掉key
del 命令可以洗掉當前資料庫的指定 key,

(5)type 獲取值的型別
type 命令可以獲取 key 對應的 value 值型別

(6)rename 重命名(覆寫)
使用rename命令進行重命名時,無論目標key是否存在都進行重命名,且源key的值會覆寫目標key的值,在實際使用程序中,建議先用 exists 命令查看目標 key 是否存在,然后再決定是否執行 rename 命令,以避免覆寫重要資料,
rename 命令是對已有 key 進行重命名,(覆寫)
命令格式:rename 源key 目標key

(7)renamenx 重命名(不覆寫)
renamenx 命令的作用是對已有 key 進行重命名,并檢測新名是否存在,如果目標 key 存在則不進行重命名,(不覆寫)
命令格式:renamenx 源key 目標key

(8)dbsize 查看庫中key的數量
dbsize 命令的作用是查看當前資料庫中 key 的數目,

(9)設定密碼
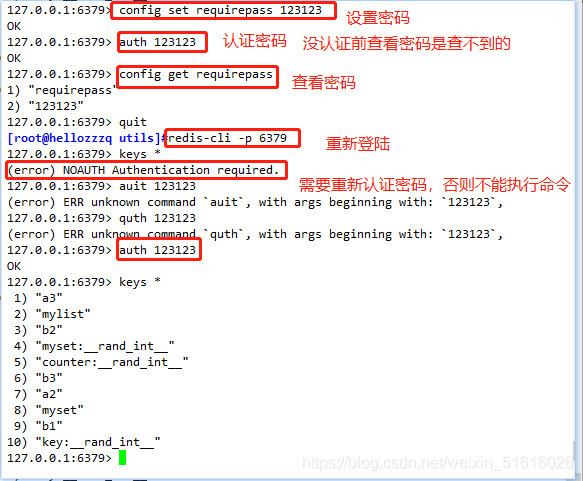
使用config set requirepass password命令設定密碼
使用config get requirepass命令查看密碼(一旦設定密碼,必須先驗證通過密碼,否則所有操作不可用)
例:
config set requirepass 123123
auth 123123
config get requirepass
quit
redis-cli
keys *
auth 123123
keys *
4、Redis 多資料庫常用命令
Redis 支持多資料庫,Redis 默認情況下包含 16 個資料庫,資料庫名稱是用數字 0-15 來依次命名的,
多資料庫相互獨立,互不干擾,
(1)多資料庫間切換
命令格式:select 序號
使用 redis-cli 連接 Redis 資料庫后,默認使用的是序號為 0 的資料庫,
127.0.0.1:6379> select 10 #切換至序號為 10 的資料庫
127.0.0.1:6379[10]> select 15 #切換至序號為 15 的資料庫
127.0.0.1:6379[15]> select 0 #切換至序號為 0 的資料庫

(2)多資料庫間移動資料
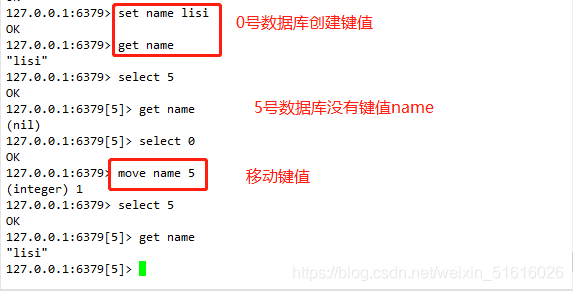
格式:move 鍵值 序號
例:
set name lisi
get name
select 5
get name
select 0
move name 5
get name
select 5
get name
(3)清除資料庫內資料
FLUSHDB :清空當前資料庫資料
FLUSHALL :清空所有資料庫的資料,慎用!
五、Redis 高可用
在web服務器中,高可用是指服務器可以正常訪問的時間,衡量的標準是在多長時間內可以提供正常服務(99.9%、99.99%、99.999%等等),
但是在Redis語境中,高可用的含義似乎要寬泛一些,除了保證提供正常服務(如主從分離、快速容災技術),還需要考慮資料容量的擴展、資料安全不會丟失等,
在Redis中,實作高可用的技術主要包括持久化、主從復制、哨兵和集群,下面分別說明它們的作用,以及解決了什么樣的問題,
- 持久化:持久化是最簡單的高可用方法(有時甚至不被歸為高可用的手段),主要作用是資料備份,即將資料存盤在硬碟,保證資料不會因行程退出而丟失,
- 主從復制:主從復制是高可用Redis的基礎,哨兵和集群都是在主從復制基礎上實作高可用的,主從復制主要實作了資料的多機備份,以及對于讀操作的負載均衡和簡單的故障恢復,
- 缺陷:故障恢復無法自動化;寫操作無法負載均衡;存盤能力受到單機的限制,
- 哨兵:在主從復制的基礎上,哨兵實作了自動化的故障恢復,
- 缺陷:寫操作無法負載均衡;存盤能力受到單機的限制,
- 集群:通過集群,Redis解決了寫操作無法負載均衡,以及存盤能力受到單機限制的問題,實作了較為完善的高可用方案,
六、Redis 持久化
持久化的功能:Redis是記憶體資料庫,資料都是存盤在記憶體中,為了避免服務器斷電等原因導致Redis行程例外退出后資料的永久丟失,需要定期將Redis中的資料以某種形式(資料或命令)從記憶體保存到硬碟;當下次Redis重啟時,利用持久化檔案實作資料恢復,除此之外,為了進行災難備份,可以將持久化檔案拷貝到一個遠程位置,
Redis 提供兩種方式進行持久化
- RDB 持久化:原理是將 Reids在記憶體中的資料庫記錄定時保存到磁盤上,
- AOF 持久化(append only file):原理是將 Reids 的操作日志以追加的方式寫入檔案,類似于MySQL的binlog,
總結:由于AOF持久化的實時性更好,即當行程意外退出時丟失的資料更少,因此AOF是目前主流的持久化方式,不過RDB持久化仍然有其用武之地,
1、RDB 持久化
RDB持久化:指在指定的時間間隔內將記憶體中當前行程中的資料生成快照保存到硬碟(因此也稱作快照持久化),用二進制壓縮存盤,保存的檔案后綴是rdb;當Redis重新啟動時,可以讀取快照檔案恢復資料,
(1)觸發條件
手動觸發
- save命令和bgsave命令都可以生成RDB檔案,
- save命令會阻塞Redis服務器行程,直到RDB檔案創建完畢為止,在Redis服務器阻塞期間,服務器不能處理任何命令請求,
- 而bgsave命令會創建一個子行程,由子行程來負責創建RDB檔案,父行程(即Redis主行程)則繼續處理請求,
- bgsave命令執行程序中,只有fork子行程時會阻塞服務器,而對于save命令,整個程序都會阻塞服務器,因此save已基本被廢棄,線上環境要杜絕save的使用,
自動觸發
- 在自動觸發RDB持久化時,Redis也會選擇bgsave而不是save來進行持久化,
- 自動觸發最常見的情況是在組態檔中通過save m n,指定當m秒內發生n次變化時,會觸發bgsave,
vim /etc/redis/6379.conf
#---------219行以下三個save條件滿足任意一個時,都會引起bgsave的呼叫-----
save 900 1 :當時間到900秒時,如果redis資料發生了至少1次變化,則執行bgsave
save 300 10 :當時間到300秒時,如果redis資料發生了至少10次變化,則執行bgsave
save 60 10000 :當時間到60秒時,如果redis資料發生了至少10000次變化,則執行bgsave
#---------242行是否開啟RDB檔案壓縮---------------------------------------
rdbcompression yes
#---------254行指定RDB檔案名----------------------------------------------
dbfilename dump.rdb
#---------264行指定RDB檔案和AOF檔案所在目錄-------------------------------
dir /var/lib/redis/6379
其他自動觸發機制
- 除了save m n 以外,還有一些其他情況會觸發bgsave:
- 在主從復制場景下,如果從節點執行全量復制操作,則主節點會執行bgsave命令,并將rdb檔案發送給從節點,
- 執行shutdown命令時,自動執行rdb持久化,
(2)執行流程
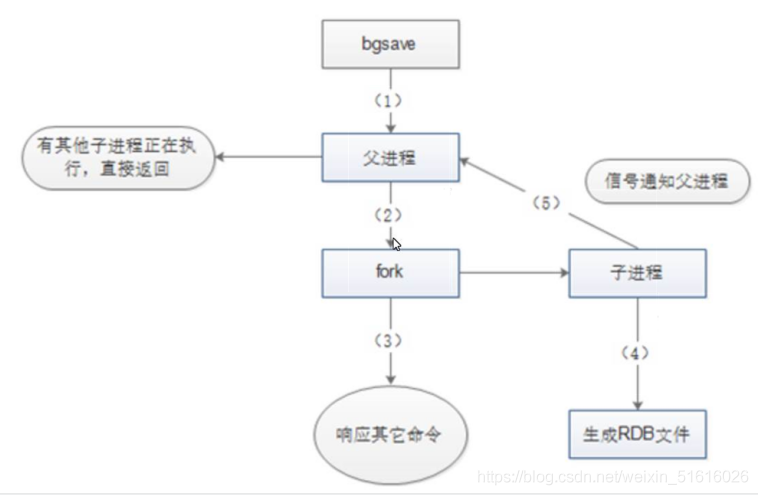
第一步:Redis父行程首先判斷:當前是否在執行save,或bgsave/bgrewriteaof的子行程,如果在執行則bgsave命令直接回傳, bgsave/bgrewriteaof的子行程不能同時執行,主要是基于性能方面的考慮:兩個并發的子行程同時執行大量的磁盤寫操作,可能引起嚴重的性能問題,
第二步:父行程執行fork操作創建子行程,這個程序中父行程是阻塞的,Redis不能執行來自客戶端的任何命令
第三步:父行程fork后,bgsave命令回傳”Background saving started”資訊并不再阻塞父行程,并可以回應其他命令
第四步:子行程創建RDB檔案,根據父行程記憶體快照生成臨時快照檔案,完成后對原有檔案進行原子替換
第五步:子行程發送信號給父行程表示完成,父行程更新統計資訊
(3)啟動時加載
- RDB檔案的載入作業是在服務器啟動時自動執行的,并沒有專門的命令,
- 但是由于AOF的優先級更高,因此當AOF開啟時,Redis會優先載入 AOF檔案來恢復資料;
- 只有當AOF關閉時,才會在Redis服務器啟動時檢測RDB檔案,并自動載入,服務器載入RDB檔案期間處于阻塞狀態,直到載入完成為止,
- Redis載入RDB檔案時,會對RDB檔案進行校驗,如果檔案損壞,則日志中會列印錯誤,Redis啟動失敗,
2、AOF 持久化
- RDB持久化是將行程資料寫入檔案,而AOF持久化,則是將Redis執行的每次寫、洗掉命令記錄到單獨的日志檔案中,查詢操作不會記錄; 當Redis重啟時再次執行AOF檔案中的命令來恢復資料,
- 與RDB相比,AOF的實時性更好,因此已成為主流的持久化方案,
(1) 開啟AOF
#Redis服務器默認開啟RDB,關閉AOF;要開啟AOF,需要在組態檔中配置
vim /etc/redis/6379.conf
#700行;修改;開啟AOF
appendonly yes
#704行;指定AOF檔案名稱
appendfilename "appendonly.aof"
#796行是否忽略最后一條可能存在問題的指令
aof-load-truncated yes
/etc/init.d/redis_6379 restart
(2)執行流程
命令追加(append):
將Redis的寫命令追加到緩沖區aof_buf;
Redis先將寫命令追加到緩沖區,而不是直接寫入檔案,主要是為了避免每次有寫命令都直接寫入硬碟,導致硬碟IO成為Redis負載的瓶頸,
命令追加的格式是Redis命令請求的協議格式,它是一種純文本格式,具有兼容性好、可讀性強、容易處理、操作簡單避免二次開銷等優點,在AOF檔案中,除了用于指定資料庫的select命令(如select 0為選中0號資料庫)是由Redis添加的,其他都是客戶端發送來的寫命令,
檔案寫入(write)和檔案同步(sync):
根據不同的同步策略將aof_buf中的內容同步到硬碟;
Redis提供了多種AOF快取區的同步檔案策略,策略涉及到作業系統的write函式和fsync函式,說明如下:
為了提高檔案寫入效率,在現代作業系統中,當用戶呼叫write函式將資料寫入檔案時,作業系統通常會將資料暫存到一個記憶體緩沖區里,當緩沖區被填滿或超過了指定時限后,才真正將緩沖區的資料寫入到硬碟里,這樣的操作雖然提高了效率,但也帶來了安全問題:如果計算機停機,記憶體緩沖區中的資料會丟失;因此系統同時提供了fsync、fdatasync等同步函式,可以強制作業系統立刻將緩沖區中的資料寫入到硬碟里,從而確保資料的安全性,
AOF快取區的同步檔案策略存在三種同步方式,它們分別是:
- appendfsync always: 命令寫入aof_buf后立即呼叫系統fsync操作同步到AOF檔案,fsync完成后執行緒回傳,這種情況下,每次有寫命令都要同步到AOF檔案,硬碟IO成為性能瓶頸,Redis只能支持大約幾百TPS寫入,嚴重降低了Redis的性能;即便是使用固態硬碟(SSD),每秒大約也只能處理幾萬個命令,而且會大大降低SSD的壽命,
- appendfsync no: 命令寫入aof_buf后呼叫系統write操作,不對AOF檔案做fsync同步;同步由作業系統負責,通常同步周期為30秒,這種情況下,檔案同步的時間不可控,且緩沖區中堆積的資料會很多,資料安全性無法保證,
- appendfsync everysec: 命令寫入aof_buf后呼叫系統write操作,write完成后執行緒回傳;fsync同步檔案操作由專門的執行緒每秒呼叫一次,everysec是前述兩種策略的折中,是性能和資料安全性的平衡,因此是Redis的默認配置,也是我們推薦的配置,
vim /etc/redis/6379.conf
#----------729行----------
#appendfsync always
appendfsync everysec
#appendfsync no
檔案重寫(rewrite):
定期重寫AOF檔案,達到壓縮的目的,
隨著時間流逝,Redis服務器執行的寫命令越來越多,AOF檔案也會越來越大;過大的AOF檔案不僅會影響服務器的正常運行,也會導致資料恢復需要的時間過長,
檔案重寫是指定期重寫AOF檔案,減小AOF檔案的體積,需要注意的是:
- AOF重寫是把Redis行程內的資料轉化為寫命令,同步到新的AOF檔案;不會對舊的AOF檔案進行任何讀取、寫入操作!
- 對于AOF持久化來說,檔案重寫雖然是強烈推薦的,但并不是必須的;即使沒有檔案重寫,資料也可以被持久化并在Redis啟動的時候匯入;因此在一些實作中,會關閉自動的檔案重寫,然后通過定時任務在每天的某一時刻定時執行,
檔案重寫之所以能夠壓縮AOF檔案,原因在于:
- 過期的資料不再寫入檔案
- 無效的命令不再寫入檔案
- 如有些資料被重復設值(set mykey v1, set mykey v2)、有些資料被洗掉了(sadd myset v1, del myset)等,
- 多條命令可以合并為一個
- 如sadd myset v1, sadd myset v2, sadd myset v3可以合并為sadd myset v1 v2 v3,
檔案重寫的觸發,分為手動觸發和自動觸發:
手動觸發:直接呼叫bgrewriteaof命令,該命令的執行與bgsave有些類似:都是fork子行程進行具體的作業,且都只有在fork時阻塞,
自動觸發:通過設定auto-aof-rewrite-min-size選項和auto-aof-rewrite-percentage選項來自動執行BGREWRITEAOF, 只有當auto-aof-rewrite-min-size和auto-aof-rewrite-percentage兩個選項同時滿足時,才會自動觸發AOF重寫,即bgrewriteaof操作,
- auto-aof-rewrite-percentage 100 :當前AOF檔案大小(即aof_current_size)是上次日志重寫時AOF檔案大小(aof_base_size)兩倍時,發生BGREWRITEAOF操作
- auto-aof-rewrite-min-size 64mb :當前AOF檔案執行BGREWRITEAOF命令的最小值,避免剛開始啟動Reids時由于檔案尺寸較小導致頻繁的BGREWRITEAOF
vim /etc/redis/6379.conf
#771行---------------------------------------------------
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
關于檔案重寫的流程,有兩點需要特別注意:
- 重寫由父行程fork子行程進行;
- 重寫期間Redis執行的寫命令,需要追加到新的AOF檔案中,為此Redis引入了aof_rewrite_buf快取,
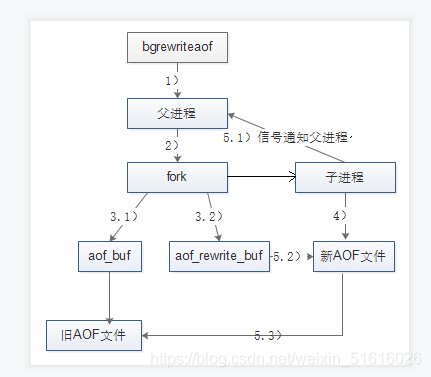
(3)檔案重寫的流程
(1)Redis父行程首先判斷當前是否存在正在執行bgsave/bgrewriteaof的子行程,如果存在則bgrewriteaof命令直接回傳,如果存在 bgsave命令則等bgsave執行完成后再執行,
(2)父行程執行fork操作創建子行程,這個程序中父行程是阻塞的,
(3.1)父行程fork后,bgrewriteaof命令回傳”Background append only file rewrite started”資訊并不再阻塞父行程, 并可以回應其他命令,Redis的所有寫命令依然寫入AOF緩沖區,并根據appendfsync策略同步到硬碟,保證原有AOF機制的正確,
(3.2)由于fork操作使用寫時復制技術,子行程只能共享fork操作時的記憶體資料,由于父行程依然在回應命令,因此Redis使用AOF重寫緩沖區(aof_rewrite_buf)保存這部分資料,防止新AOF檔案生成期間丟失這部分資料,也就是說,bgrewriteaof執行期間,Redis的寫命令同時追加到aof_buf和aof_rewirte_buf兩個緩沖區,
(4)子行程根據記憶體快照,按照命令合并規則寫入到新的AOF檔案,
(5.1)子行程寫完新的AOF檔案后,向父行程發信號,父行程更新統計資訊,具體可以通過info persistence查看,
(5.2)父行程把AOF重寫緩沖區的資料寫入到新的AOF檔案,這樣就保證了新AOF檔案所保存的資料庫狀態和服務器當前狀態一致,
(5.3)使用新的AOF檔案替換老檔案,完成AOF重寫,
(4)啟動時加載
- 當AOF開啟時,Redis啟動時會優先載入AOF檔案來恢復資料;
- 只有當AOF關閉時,才會載入RDB檔案恢復資料,
- 當AOF開啟,但AOF檔案不存在時,即使RDB檔案存在也不會加載,
- Redis載入AOF檔案時,會對AOF檔案進行校驗
- 如果檔案損壞,則日志中會列印錯誤,Redis啟動失敗,
- 但如果是AOF檔案結尾不完整(機器突然宕機等容易導致檔案尾部不完整),且aof-load-truncated引數開啟,則日志中會輸出警告,Redis忽略掉AOF檔案的尾部,啟動成功,
- 配置中aof-load-truncated引數默認是開啟的,
3、RDB和AOF的優缺點
(1)RDB持久化
優點:RDB檔案緊湊,體積小,網路傳輸快,適合全量復制;恢復速度比AOF快很多,當然,與AOF相比,RDB最重要的優點之一是對性能的影響相對較小,
缺點:RDB檔案的致命缺點在于其資料快照的持久化方式決定了必然做不到實時持久化,而在資料越來越重要的今天,資料的大量丟失很多時候是無法接受的,因此AOF持久化成為主流,此外,RDB檔案需要滿足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB檔案),
對于RDB持久化,一方面是bgsave在進行fork操作時Redis主行程會阻塞,另一方面,子行程向硬碟寫資料也會帶來IO壓力,
(2)AOF持久化
與RDB持久化相對應,AOF的優缺點:
優點:支持秒級持久化、兼容性好;
缺點:檔案大、恢復速度慢、對性能影響大,
對于AOF持久化,向硬碟寫資料的頻率大大提高(everysec策略下為秒級),IO壓力更大,甚至可能造成AOF追加阻塞問題,
AOF檔案的重寫與RDB的bgsave類似,會有fork時的阻塞和子行程的IO壓力問題,相對來說,由于AOF向硬碟中寫資料的頻率更高,因此對 Redis主行程性能的影響會更大,
七、Redis 性能管理
1、查看Redis記憶體使用
redis-cli -h 192.168.109.3 -p 6379
info memory
2、記憶體碎片率
作業系統分配的記憶體值used_memory_rss除以Redis使用的記憶體值used_memory計算得出;
記憶體碎片是由作業系統低效的分配/回收物理記憶體導致的(不連續的物理記憶體分配)
跟蹤記憶體碎片率對理解Redis實體的資源性能是非常重要的:
- 記憶體碎片率稍大于1是合理的
- 這個值表示記憶體碎片率比較低
- 記憶體碎片率超過1.5
- 說明Redis消耗了實際需要物理記憶體的150%,其中50%是記憶體碎片率,
- 需要在redis-cli工具上輸入shutdown save 命令,并重啟 Redis 服務器,
- 記憶體碎片率低于1的
- 說明Redis記憶體分配超出了物理記憶體,作業系統正在進行記憶體交換,
- 需要增加可用物理記憶體或減少 Redis 記憶體占用,
3、記憶體使用率
redis實體的記憶體使用率超過可用最大記憶體,作業系統將開始進行記憶體與swap空間交換,
避免記憶體交換發生的方法:
- 針對快取資料大小選擇安裝 Redis 實體
- 盡可能的使用Hash資料結構存盤
- 設定key的過期時間
4、內回收key
保證合理分配redis有限的記憶體資源,
當達到設定的最大閥值時,需選擇一種key的回收策略,默認情況下回收策略是禁止洗掉,
#組態檔中修改 maxmemory-policy 屬性值:
vim /etc/redis/6379.conf
#---------598取消注釋---------------------------------------------------------------------------
maxmemory-policy noenviction
| 屬性值 | 含義 |
|---|---|
| volatile-lru | 使用LRU演算法從已設定過期時間的資料集合中淘汰資料 |
| volatile-ttl | 從已設定過期時間的資料集合中挑選即將過期的資料淘汰 |
| volatile-random | 從已設定過期時間的資料集合中隨機挑選資料淘汰 |
| allkeys-lru | 使用LRU演算法從所有資料集合中淘汰資料 |
| allkeys-random | 從資料集合中任意選擇資料淘汰 |
| noenviction | 禁止淘汰資料 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/266354.html
標籤:其他
上一篇:一文搞懂MySQL體系架構!!