前言
最近在面試,每天會被考到很多知識點,這些知識點有些我已經看了十幾遍,還是會反應慢或者記不住,回想我在學習程序中,也是學了忘忘了學,沒有重復個幾十遍根本難以形成永久記憶,這次我復習和整理面試知識點的時候決定把CNN里面的關鍵創新點、容易疏忽的點都記錄下來,方便快速查找回顧,于是就有了這篇像詞典一樣的永久更新的文章,
一、輕量化網路
| 網路名稱 | 記憶點 | 備注 |
| MobileNetV1 | 深度可分離卷積替換傳統卷積 | 計算量和引數量下降為原來的1/Dk^2(Dk為卷積核kernel size,一般為3,所以計算量約為1/9) |
| 深度卷積的激活函式是Relu6 | 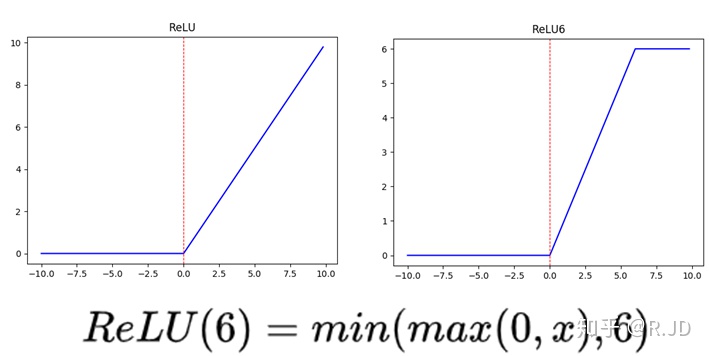 | |
| 下采樣是通過3x3的深度卷積 | stride=2 | |
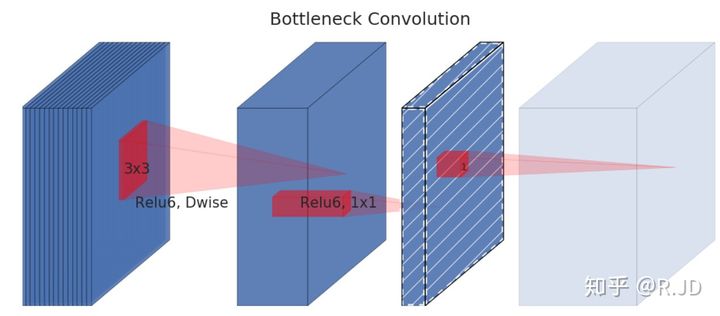
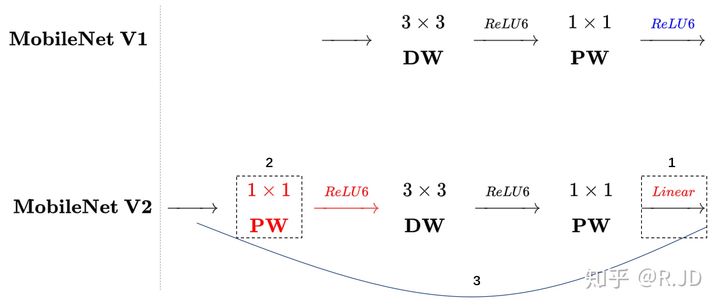
| MobileNetV2 | Linear Bottelneck | 最后的Relu6換成了Linear
|
| Inverted Residuals | 1.點卷積擴充通道,再做深度卷積,再通過點卷積壓縮通道,這樣的好處是3x3卷積在更深的通道上可以提取到更豐富的特征, 2.對于stride=1的Block加入Residual結構,stride=2的resoution變了,因此不添加,
| |
| MobileNetV3 | NAS | 網路的架構基于NAS實作的MnasNet platform-aware NAS + NetAdapt |
| SE | squeeze and excitation 注意力機制 | |
| 模型的后半段使用h-swish | swish(x) :f(x) = x * sigmoid(βx) h-swish是因為sigmoid函式在端上計算耗時而提出的改進方案,
| |
| 末端調整 | Avg提前,好處是計算量減小, |
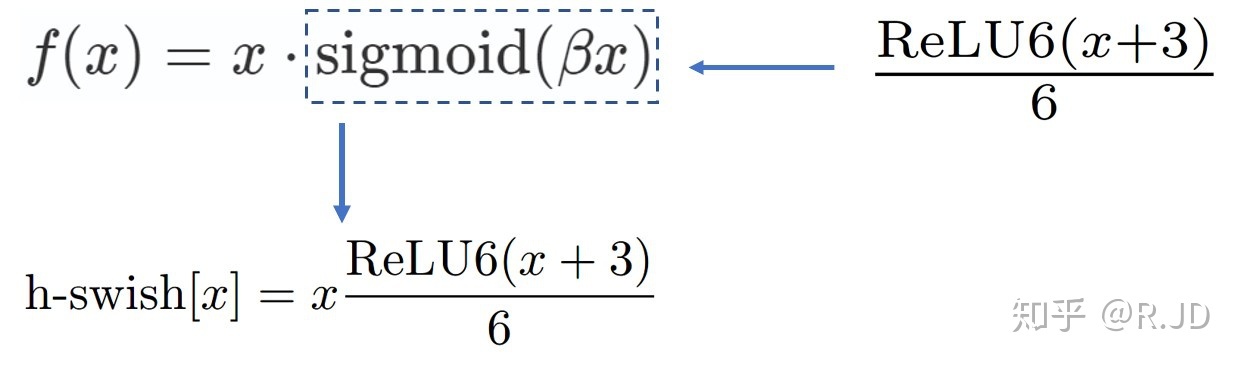
二.基礎知識
2.1 BatchNorm/LayerNorm/InstanceNorm/GroupNorm
| 基礎知識點 | 記憶點 | 備注 |
| Batch Norm | 達到的效果 | BatchNorm就是在深度神經網路訓練程序中使得每一層神經網路的輸入保持相同分布, |
| 出發點 | 解決covariate shift:如果ML系統實體集合<X,Y>中的輸入值X的分布老是變,這不符合IID假設,網路模型很難穩定的學規律, 問題:分布變化=>非線性輸出向兩端移動=>梯度消失=>網路收斂慢 解決:BN=>將隱藏層的輸入拉回到(0,1)正態分布=>使激活值落在非線性區域=>使得梯度變大=>加快網路收斂 | |
| 保障非線性 | BN為了保證非線性的獲得,對變換后的滿足均值為0方差為1的x又進行了scale加上shift操作(y=scale*x+shift) 核心思想應該是想找到一個線性和非線性的較好平衡點,既能享受非線性的較強表達能力的好處,又避免太靠非線性區兩頭使得網路收斂速度太慢, | |
| 推理時的引數 | 推理的引數scale和shift是在訓練的時候記住每個batch內的引數,然后求出平均值和方差的期望,這樣在全域上估計的這組引數更加準確, | |
| 正則化作用 | 在BN層中,每個batch計算得到的均值和標準差是對于全域均值和標準差的近似估計,這為我們最優解的搜索引入了隨機性,從而起到了正則化的作用, | |
| BN的缺陷 | 帶有BN層的網路錯誤率會隨著batch_size的減小而迅速增大,當我們硬體條件受限不得不使用較小的batch_size時,網路的效果會大打折扣, | |
| BN/LN/IN/GN | 示意圖 | 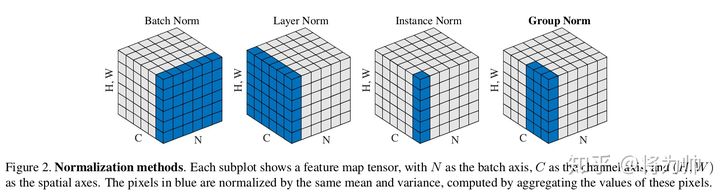 |
| 均值方差的作用位置 |
| |
| 相比BN為什么好? | LN/IN和GN都沒有對batch作平均,所以當batch變化時,網路的錯誤率不會有明顯變化 | |
| 經驗表現 | LN和IN 在時間序列模型(RNN/LSTM)和生成模型(GAN)上有很好的效果,而GN在視覺模型上表現更好, |
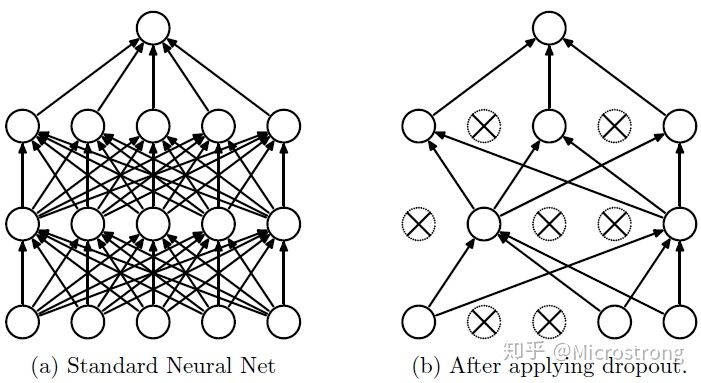
2.2 關于dropout
| 基礎知識點 | 記憶點 | 備注 |
| dropout | 概念 | 在每個訓練批次中,神經元的激活值以一定的概率p停止作業 |
| 目的 | 起到正則化作用,可以使模型泛化性更強,因為模型不會太依賴某些區域的特征, | |
| 示意圖 |
面試問到是凍結權重還是凍結神經元? 答凍結神經元, | |
| 為什么緩解過擬合? 為什么有人說dropout類似model ensemble的效果? |
|
三.常見loss函式
| loss函式 | 記憶點 | 備注 |
| CE | 交叉熵的推理 | 1.資訊量的表示
2.熵是資訊量的期望
3.相對熵(KL散度)表示兩個分布的差異
4.交叉熵是相對熵的數學變形
前面是p(x)的熵,是一個常量,后面就是交叉熵,
|
| loss的形式 | 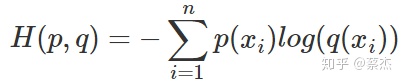 | |
| 分類loss為什么prefer交叉熵than MSE? | MSE不能保證誤差越大,梯度越大,學習越快,而交叉熵可以,因此收斂更好更快, | |
| Focal | 解決的問題 | 1.解決類別不平衡 2.難易樣本分布不平衡 |
| loss的形式 | 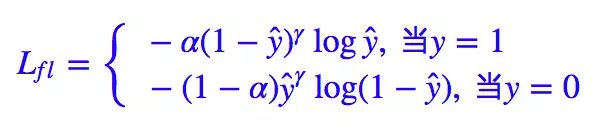 | |
| loss的引數 | 基于交叉熵演變而來, γ用來調節樣本難易程度,一般取2,γ提升了預測與GT差距大的樣本對loss的貢獻比(困難樣本), α用來調節樣本類別的比例,默認α=0.25,將前景的loss放大而背景的loss縮小, | |
| Dice | 解決的問題 | 語意分割中正負樣本不平衡 |
| loss的形式 | Dice系數:
Dice loss:
Laplace Smoothing:
| |
| Dice的優勢劣勢 |
|
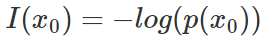
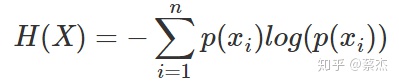
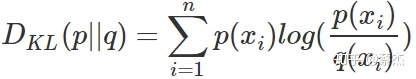
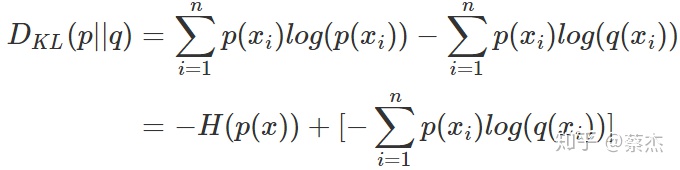
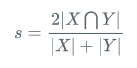
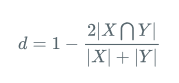
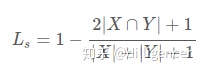
四.常見衡量指標
| 指標名稱 | 記憶點 | 備注 |
| MAP(目標檢測) | TP、TN、FP、FN | 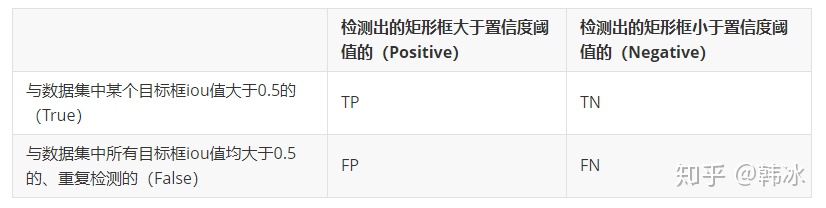 |
| Precision & Recall | Precision = TP / (TP + FP) Recall = TP / (TP + FN) | |
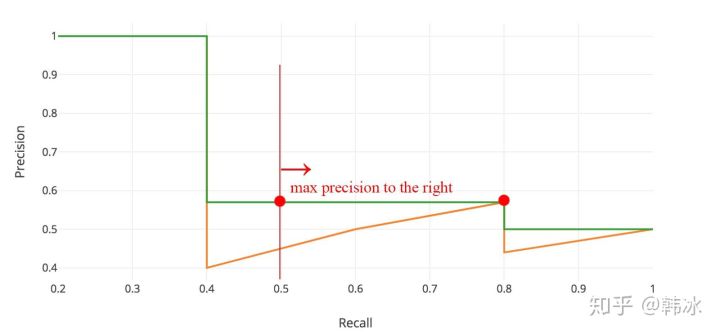
| AP | 按照模型給出的置信度,對每個類的所有預測框進行排序: 逐個計算Precision 和 Recall,繪制PR曲線,AP就是PR曲線上的Precision值求均值, 實際應用中就會對PR曲線最做平滑:
| |
| MAP | MAP就是對所有類的AP做平均值, | |
| MIOU(語意分割)
| IOU | IOU的定義:計算真實值和預測值兩個集合的交集和并集之比 IOU=TP/(FP+FN+TP) |
| MIOU | 對于不同類別的IOU求平均值 | |
| MIOU的數學表達 |
pij表示真實值為i,被預測為j的數量, K+1是類別個數(包含空類),pii是真正的數量,pij、pji則分別表示假正和假負, |
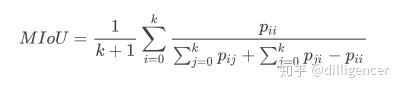
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/266356.html
標籤:其他