HDFS 集群的機架感知
- 1、背景
- 1.1、Hadoop 的設計目的
- 1.2、Hadoop 的設計考慮
- 1.3、副本存放策略
- 2、配置機架感知
- 2.1、修改組態檔 core-site.xml
- 2.2、驗證機架感知
- 3、補充
- 3.1、增加 datanode 節點
- 3.2、節點間距離計算
- 4、學習內容
1、背景
1.1、Hadoop 的設計目的
解決海量大檔案的處理問題,主要指大資料的存盤和計算問題,
其中,HDFS 解決資料的存盤問題;MapReduce 解決資料的計算問題,
1.2、Hadoop 的設計考慮
設計分布式的存盤和計算解決方案架構在廉價的集群之上,所以,服務器節點出現宕機的情況是常態,資料的安全是重要考慮點,HDFS 的核心設計思路就是對用戶存進 HDFS 里的所有資料都做冗余備份,以此保證資料的安全,
那么 Hadoop 在設計時考慮到資料的安全,資料檔案默認在 HDFS 上存放三份,顯然,這三份副本肯定不能存盤在同一個服務器節點,那怎么樣的存盤策略能保證資料既安全也能保證資料的存取高效呢?
1.3、副本存放策略
HDFS 分布式檔案系統的內部有一個副本存放策略:以默認的副本數=3 為例:
(1)第一個副本塊存本機;
(2)第二個副本塊存跟本機同機架內的其他服務器節點;
(3)第三個副本塊存不同機架的一個服務器節點上;
好處:
(1)如果本機資料損壞或者丟失,那么客戶端可以從同機架的相鄰節點獲取資料,速度肯定要比跨機架獲取資料要快,
(2)如果本機所在的機架出現問題,那么之前在存盤的時候沒有把所有副本都放在一個機架內,這就能保證資料的安全性,此種情況出現,就能保證客戶端也能取到資料,
HDFS 為了降低整體的網路帶寬消耗和資料讀取延時,HDFS 集群一定會讓客戶端盡量去讀取近的副本,那么按照以上頭解釋的副本存放策略的結果:
(1)如果在本機有資料,那么直接讀取;
(2)如果在跟本機同機架的服務器節點中有該資料塊,則直接讀取;
(3)如果該 HDFS 集群跨多個資料中心,那么客戶端也一定會優先讀取本資料中心的資料,
但是 HDFS 是如何確定兩個節點是否是統一節點,如何確定的不同服務器跟客戶端的遠近呢?答案就是機架感知,!!!!
在默認情況下,HDFS 集群是沒有機架感知的,也就是說所有服務器節點在同一個默認機架中,那也就意味著客戶端在上傳資料的時候,HDFS 集群是隨機挑選服務器節點來存盤資料塊的三個副本的,
那么假如,datanode1 和 datanode3 在同一個機架 rack1,而 datanode2 在第二個機架 rack2,那么客戶端上傳一個資料塊 block_001,HDFS 將第一個副本存放在 dfatanode1,第二個副本存放在 datanode2,那么資料的傳輸已經跨機架一次(從 rack1 到 rack2),然后 HDFS 把第三個副本存 datanode3,此時資料的傳輸再跨機架一次(從 rack2 到 rack1),顯然,當 HDFS 需要處理的資料量比較大的時候,那么沒有配置機架感知就會造成整個集群的網路帶寬的消耗非常嚴重,
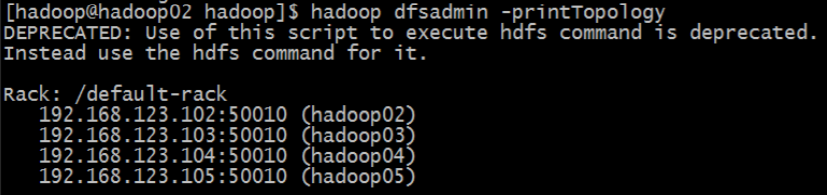
下圖是沒有配置機架感知的 HDFS 集群拓撲:
2、配置機架感知
2.1、修改組態檔 core-site.xml
給 NameNode 節點的 core-site.xml 組態檔增加一項配置:
<property>
<name>topology.script.file.name</name>
<value>/home/hadoop/apps/hadoop-2.6.5/etc/hadoop/topology.sh</value>
</property>
這個配置項的 value 通常是一個執行檔案,該執行檔案是一個 shell 腳本 topology.sh,該腳本接收一個引數,輸出一個值,
接收的引數:datanode 節點的 IP 地址,比如:192.168.123.102
輸出值:datanode 節點所在的機架配置資訊,比如:/switch1/rack1
Namenode 啟動時,會判斷該配置選項是否為空,如果非空,則表示已經啟用機架感知的配置,此時 namenode 會根據配置尋找該腳本,并在接收到每一個 datanode 的 heartbeat(心跳) 時,將該 datanode 的 ip 地址作為引數傳給該腳本運行,并將得到的輸出作為該 datanode 所屬的機架 ID,保存到記憶體的一個 map 中,
至于腳本的撰寫,就需要將真實的網路拓樸和機架資訊了解清楚后,通過該腳本能夠將機器的 ip 地址和機器名正確的映射到相應的機架上去,一個簡單的實作如下:
#!/bin/bash
HADOOP_CONF=/home/hadoop/apps/hadoop-2.6.5/etc/hadoop
while [ $# -gt 0 ] ;
do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line
do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]
then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ]
then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
那么通過閱讀腳本內容知道,我們需要準備一個 topology.data 的檔案,topology.data 的內容如下:
192.168.123.102 hadoop02 /switch1/rack1
192.168.123.103 hadoop03 /switch1/rack1
192.168.123.104 hadoop04 /switch2/rack2
192.168.123.105 hadoop05 /switch2/rack2
其中 switch 表示交換機,rack 表示機架,
需要注意的是,在 Namenode 上,該檔案中的節點必須使用 IP,使用主機名無效,而 ResourceManager 上,該檔案中的節點必須使用主機名,使用 IP 無效,所以,最好 IP 和主機名都配上,
**
注意:以上兩個檔案都需要添加可執行權限
chmod 777 topology.data topology.sh
**
2.2、驗證機架感知
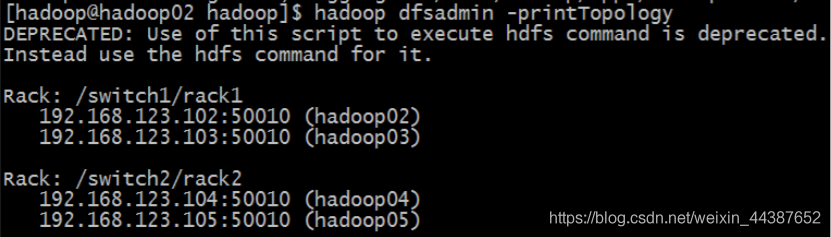
以上配置做好之后,啟動集群,啟動完集群之后,在使用命令:
hdfs dfsadmin -printTopology
查看整個集群的拓撲圖:
3、補充
3.1、增加 datanode 節點
增加 datanode 節點,不需要重啟 namenode,
非常簡單的做法:
在 topology.data 檔案中加入新加 datanode 的資訊,然后啟動起來就 OK,
3.2、節點間距離計算
有了機架感知,NameNode就可以畫出下圖所示的datanode網路拓撲圖,D1,R1都是交換機,最底層是 datanode,則 H1 的 rackid=/D1/R1/H1,H1 的 parent 是 R1,R1 的是 D1,這些 rackid 資訊可以通過 topology.script.file.name 配置,有了這些 rackid 資訊就可以計算出任意兩臺 datanode 之間的距離,得到最優的存放策略,優化整個集群的網路帶寬均衡以及資料最優分配,
計算結果:
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的 datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一 rack 下的不同 datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一 IDC 下的不同 datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同 IDC 下的 datanode
4、學習內容
上節學習內容:Hadoop2.7.5 高可用(HA)集群搭建
下節學習內容:Hive 基本概念(特點,架構,資料存盤,OLTP,OLAP)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/266651.html
標籤:其他
上一篇:Java微服務面試題:SpringCloud+Eureka快速搭建微服架構
下一篇:GO語言學習—基礎概念