前言
PCA多用于對資料特征集進行降維,也方便對資料集進行可視化操作,說白了最后進行結果展示那么多特征向量要一起表示的話肯定很難展示,超過三維的資料就很難展示了,而PCA可對特征集進行簡化,通俗的來講也就是合并好理解,PCA應用的范圍很廣因此很有必要要學習,原理肯定還是數學證明,在特征工程上經常使用,希望讀者看完能夠提出錯誤或者看法,博主會長期維護博客做及時更新,純分享,希望大家喜歡,
強烈推薦大家看看這篇Python機器學習筆記:主成分分析(PCA)演算法,寫的很詳細很好,
一、為什么需要PCA?(為什么要降維)
在各個領域進行資料收集或是資料采樣時往往都是存在多個指標或是特征用來表示某一現象或是用來作評估好壞,但是龐大的資料量難以展示,對多維資料分析的難度很大,更重要的是在多數情況下,許多變數之間可能存在相關性,從而增加了問題分析的復雜性,同時對分析帶來不便,如果分別對每個指標進行分析,分析往往是孤立的,而不是綜合的,盲目減少指標會損失很多資訊,容易產生錯誤的結論,
我們常常用二維模型來進行結果展示,通常進行展示的資料都是二維資料,但是想象一下對于四維以及四維以上的資料我們該如何進行展示?
例如我們要對地鐵擁堵情況進行評估和展示,對于評估地鐵擁堵情況,我們將采用
| 日期 | 天氣情況 | 濕度 | 風級 | 降水量 | 體感溫度 | 節假日波動系數 | 突發事件 | 客流量 |
這九個指標進行預測地鐵擁堵情況,我們通常在一張坐標軸上進行效果展示從而進行分析,但在對這些多維資料進行展示的話我們尋常的展示效果圖肯定展示不出來,資料往往擁有超出顯示能力的更多特征,資料顯示并非大規模特征下的唯一難題,對資料進行簡化還有如下一系列的原因:
- 使得資料集更容易使用;
- 降低很多演算法的計算開銷;
- 去除噪聲;
- 使得結果容易理解;
在已標注與未標注的資料上都有降維技術,這里我們將主要關注未標注資料上的降維技術,該技術同時也可以應用于已標注的資料,
而在資料特征工程降維技術中,PCA的應用目前最為廣泛,
二、PCA簡介
主成分分析法(PCA)是設法將原來變數重新組合成一組新的相互無關的幾個綜合變數,同時根據實際需要從中可以取出幾個較少的總和變數盡可能多地反映原來變數的資訊的統計方法叫做主成分分析或稱主分量分析,也是數學上處理降維的一種方法,主成分分析是設法將原來眾多具有一定相關性(比如P個指標),重新組合成一組新的互相無關的綜合指標來代替原來的指標,通常數學上的處理就是將原來P個指標作線性組合,作為新的綜合指標,
在數學上更簡單的理解我們可以把它想象為對很多個坐標點通過映射方法到一根函式直線上,通過這種方法我們肯定會得到新的特征用來表示這個事件,新的特征剔除了原有特征的冗余資訊,因此更有區分度,新的特征基于原有特征,它能夠重建原有特征,主成分分析要保留最有可能重建原有特征的新特征,從而達到資料降維的作用,
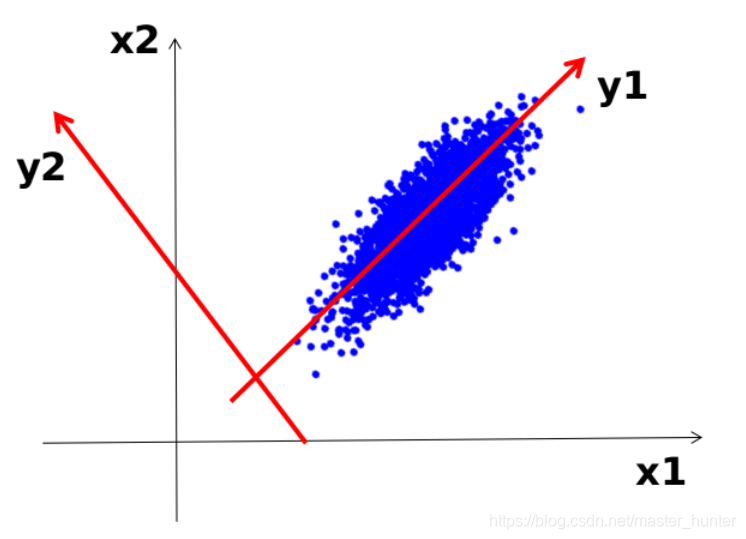
例如我們得到了一個二維資料集,里面一個標簽僅僅只用兩個()特征就能表示,但是我們只能用一個特征去描述這件事,在原始的
坐標軸上,我們無論刪掉
或者是
我們都不能完整的表達出這個點來,但是我們可以通過PCA,將資料從原來的坐標系轉換到了新的坐標系,新坐標系的選擇是由資料本身決定的,第一個新坐標軸選擇的是原始資料中方差最大的方向,第二個新坐標軸的選擇和第一個坐標軸正交且具有最大方差的方向,該程序一直重復,重復次數為原始資料中特征的數目,就通過該資料集(
),我們通過該方法構建出
坐標系,在該坐標系中我們可以發現資料基本都集中在
軸上面,而
這條短軸上則差距很小,在極端的情況,短軸如果退化成一點,那只有在長軸的方向才能夠解釋這些點的變化了;這樣,由二維到一維的降維就自然完成了,
三、PCA演算法推導
要詳細了解PCA演算法原理還是需要一定的數學基礎的,不是那么容易理解推匯出來的,但是可以盡可能的簡化推導程序,但是還是有必須清楚掌握的數學知識,
1.投影
首先我們知道在笛卡爾直角坐標系中上面的點都可以用一個二維向量表示,當然如果是維向量可以等價表示為
維空間中的一條從原點發射的有向線段,只不過就是很那表示,假設我們就在二維笛卡爾直角坐標系中,有
,那么在二維平面上A和B可以用兩條發自原點的有向線段表示,如下圖:
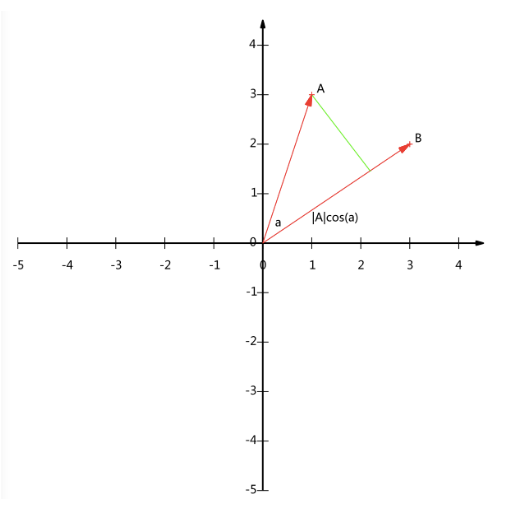
我們知道垂線與B的交點叫做A在B上的投影,再假設A與B的夾角為a,則投影的矢量長度為(這里假設向量B的模為1).
就是A點的模,也就是A線段的標量長度,
而且我們知道:,
如果B向量的模為1的話,我們就可以發現得到.
2.基
一個二維向量可以對應二維笛卡爾直角坐標系中從原點出發的一條有向線段,對于()來說,那么他們對應的坐標軸就是:
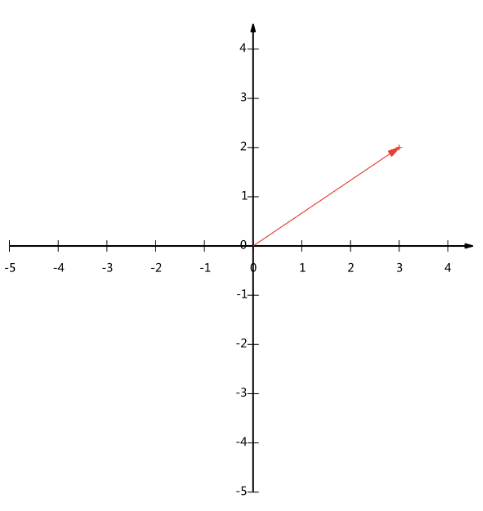
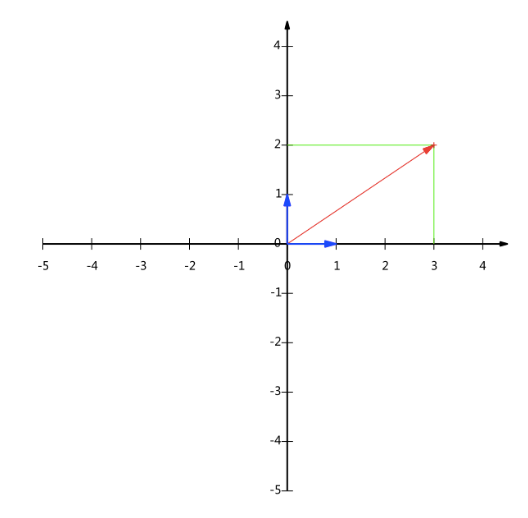
我們假設有一點,而它對應的向量就為從原點到
的有向線段,而我們知道該向量在軸上的投影值3,在
軸上的投影值為2,我們設該點為
,
在軸上:
,而在
軸上我們可以設它的模為1,
可為
.
在軸上:
,而在
軸上我們可以設它的模為1,
可為
.
經過簡單的數學變換,向量()實際上表示線性組合:
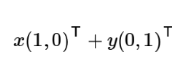
不難證明所有二維向量都可以表示為這樣的線性組合,此處和
叫做二維空間的一組基,
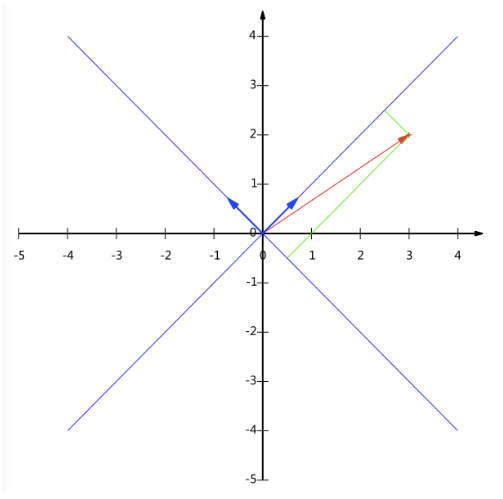
所以,要準確描述向量,首先要確定一組基,然后給出基所在的各個直線上的投影值,就可以了,只不過我們經常省略第一步,而默認以和
為基,
當然我們也可以以其他向量為基底,和
也可以成為一組基,
一般來說,我們希望基的模是1,因為從內積的意義可以看到,如果基的模式1,那么就可以方便的用向量點乘基而直接獲得其在新基上的坐標了!實際上,對應于任何一個向量我們總可以找到其同方向上模為1的向量,只要讓兩個分量分別除以模就好了,例如上面的基就可以變為:,
,
現在我們想獲得在新基上的坐標,即在兩個方向上的投影矢量值,那么根據內積的幾何意義,我們只要分別計算
和兩個基的內積,不難得到新的坐標為(
),
3.基變換的矩陣表示
將變換為新基上的坐標,就是用
與第一個基做內積運算,作為第一個新的坐標分量,然后用
與第二個基做內積運算,作為第二個新坐標的分量,實際上,我們可以用矩陣想成的形式簡潔的表示這個變換:
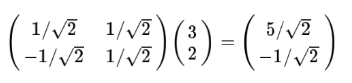
那么對于多個二維向量,例如(1,1),(2,2),(3,3)想變換到剛才那組基上,則可以變為這樣:
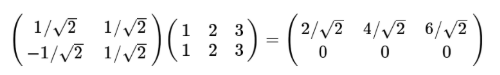
一般地,如果我們有M個N維向量,想將其變換為由R個N維向量表示的新空間中,那么首先將R個基按照行組成矩陣A,,然后將向量按照列組成矩陣B,那么兩個矩陣的乘積AB就是變換結果,其中AB的第m列為A中的第M列變換后的結果,
數學表示為:
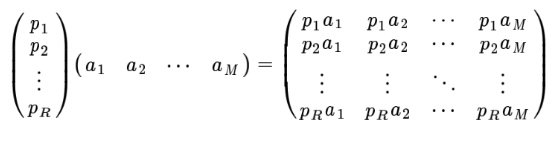
特別要注意的是,這里R可以小于N,而R決定了變換后資料的維數,也就是說,我們可以將一個N維資料變換到更低維度的空間中去,變換后的維度取決于基的數量,因此這種矩陣相乘的表示也可以表示為降維變換,
4.方差
現在我們知道可以通過將原始矩陣(特征集)通過投影的方式映射到不同的基底上從而構建新的特征,經過變換后達到降維的目的,而現在我們要知道如何選擇正確的基底來幫助我們降維,
我們知道要使得向量經過投影之后更具有區分性,經過投影后要盡可能的分散,而這種分散程度,可以用數學上的方差來表述,
此處,一個欄位的方差可以看做事每個元素與欄位均值的差的平方和的均值,即:
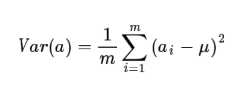
但如果每一次計算方差都要減去一個欄位均值顯然更加累贅,我們可以通過對資料的預處理使得欄位的均值為0,例如我們的資料由五條記錄組成,將它們表示為矩陣形式:
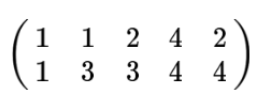
我們通過減去均值得到:
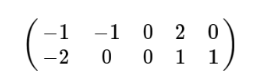
這樣的話就為0了,因此方差可以直接用每個元素的平方和除以元素個數表示:
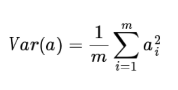
于是上面的問題被形式化表示為:尋找一個一維基,使得所有資料變換為這個基上的坐標表示后,方差值最大,
5.協方差
上述方法只能解決二維到一維的降維,但是對于多維資料我們第一步選擇方差最大化的降第一維方式,那么我們第二步該如何選擇呢?
如果我們還是單純的只選擇方差最大的方向,很顯然,這個方向與第一個方向應該是“幾乎重合在一起”,顯然這樣的維度是沒有用的,因此應該有其他約束條件,
數學上可以用兩個欄位的協方差表示其相關性
- 是一種用來度量兩個隨機變數關系的統計量,
- 只能處理二維問題,
- 計算協方差需要計算均值,

由于已經讓每個欄位均值為0,則:
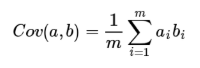
可以看出,在欄位均值為0的情況下,兩個欄位的協方差簡潔的表示為其內積除以元素數m,協方差的絕對值越大,則二個變數相互影響越大,
當協方差為0時,表示兩個欄位完全獨立,為了讓協方差為0,我們選擇第二個即時只能在與第一個基正交的方向上選擇,因此最終選擇的兩個方向一定是正交的,
至此,我們得到了降維問題的優化目標:將一組N維向量降維k維(K大于0,小于N),其目標是選擇K個單位(模為1)正交基,使得原始資料變換到這組基上后,各欄位兩兩間協方差為0,而欄位的方差則盡可能大(在正交的約束下,取最大的k個方差),
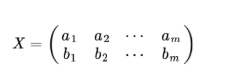
然后我們用X乘以X的轉置,并乘上系數1/m:
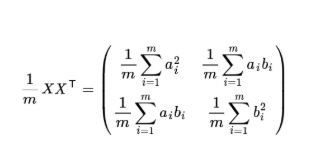
這時候我們會發現,這個矩陣對角線上的兩個元素分別是兩個欄位的方差,而其他元素是a和b的協方差,兩者被統一到了一個矩陣的,
根據矩陣相乘的運演算法則,這個結論很容易被推廣到一般情況:
設我們有m個n維資料記錄,將其按列排成n乘m的矩陣X,設,則C是一個對稱矩陣,其對角線分別是各個欄位的方差,而第l行j列和j行i列元素相同,表示i和j兩個欄位的協方差,
6.協方差矩陣
假設我們只有a和b 兩個欄位,那么我們將他們按行組成矩陣X:
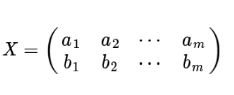
- 協方差矩陣能處理多維問題;
- 協方差矩陣是一個對稱的矩陣,而且對角線是各個維度上的方差,
- 協方差矩陣計算的是不同維度之間的協方差,而不是不同樣本之間的,
- 樣本矩陣中若每行是一個樣本,則每列為一個維度,所以計算協方差時要按列計算均值,
如果資料是3維,那么協方差矩陣是:
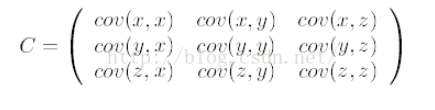
7.特征值與特征向量

對于也可以寫作:

8.協方差矩陣對角化
設原始資料矩陣X對于的協方差矩陣為C,而P是一組基按行組成的矩陣,設Y=PX,則Y為X對P做基變換后的資料,設Y的協方差矩陣為D,我們推導一下D與C的關系:
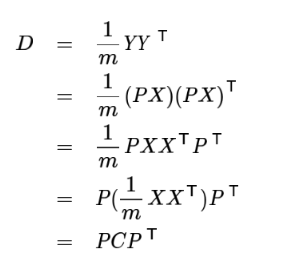
其實到這里快差不多了,優化目標變成了尋找一個矩陣P,滿足PCPT是一個對角矩陣,并且對角元素按照從大到小依次排列,那么P的前K行就是要尋找的基,用P的前K行就是要尋找的基,用P的前K行組成的矩陣乘以X就使得X從N維降到了K維并滿足上述優化條件,
協方差矩陣C是一個對稱矩陣,在線性代數上,實對稱矩陣有一系列非常好的性質:
- 實對稱矩陣不同特征值對應的特征向量必然正交,
- 設特征向量 λ 重數為r,則必然存在r個線性無關的特征向量對應于 λ,因此可以將這r個特征向量單位正交化,
一個n行n列的實對稱矩陣一定可以找到n個單位正交特征向量,設這n個特征向量為e1, e2, ...en,我們將其按照列組成矩陣:
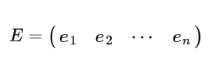
則對協方差矩陣C有如下結論:
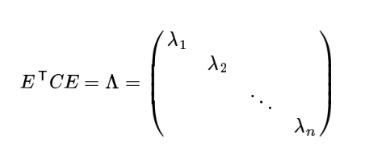
其中 Λ 為對稱矩陣,其對角元素為各特征向量對應的特征值(可能有重復),
到這里,我們發現我們已經找到了需要的矩陣P:
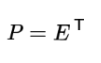
P是協方差矩陣的特征向量單位化后按照行排列出的矩陣,其中每一行都是C的一個特征向量,如果設P按照 Λ 中特征值從大到小,將特征向量從上到下排列,則用P的前K行組成的矩陣乘以原始資料矩陣X,就可以得到我們需要的降維后的資料矩陣Y,
至此,我們完成了整個PCA的數學原理討論,
四、PCA運用流程

- 1) 將原始資料按列組成n行m列矩陣X
- 2)將X的每一行(代表一個屬性欄位)進行零均值化(去平均值),即減去這一行的均值
- 3)求出協方差矩陣 C= 1/m*X*XT
- 4)求出協方差矩陣的特征值及對應的特征向量
- 5)將特征向量按對應特征值大小從上到下按行排列成矩陣,取前k行組成矩陣P(保留最大的k各特征向量)
- 6)Y=PX 即為降維到K維后的資料
將資料轉換成前N個主成分的偽代碼大致如下:
去除平均值
計算協方差矩陣
計算協方差矩陣的特征值和特征向量
將特征值從大到小排序
保留最上面的N個特征向量
將資料轉換到上述N個特征向量構建的新空間中from numpy import *
#從一個文本檔案中讀入一個資料集,資料集示例如下:
'''
8.805945 10.575145
9.584316 9.614076
11.269714 11.717254
9.120444 9.019774
7.977520 8.313923
'''
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float,line) for line in stringArr]
return mat(datArr)
#基于numpy實作pca演算法
def pca(dataMat, topNfeat=9999999): #原資料 m*n
meanVals = mean(dataMat, axis=0) #均值:1*n
meanRemoved = dataMat - meanVals #去除均值 m*n
covMat = cov(meanRemoved, rowvar=0) #協方差矩陣 n*n
eigVals,eigVects = linalg.eig(mat(covMat)) #特征矩陣 n*n
eigValInd = argsort(eigVals) #將特征值排序
eigValInd = eigValInd[:-(topNfeat+1):-1] #僅保留p個列(將topNfeat理解為p即可)
redEigVects = eigVects[:,eigValInd] # 僅保留p個最大特征值對應的特征向量,按從大到小的順序重組特征矩陣n*p
lowDDataMat = meanRemoved * redEigVects #將資料轉換到低維空間lowDDataMat: m*p
reconMat = (lowDDataMat * redEigVects.T) + meanVals #從壓縮空間重構原資料reconMat: m*n
return lowDDataMat, reconMat
參閱:
Python機器學習筆記:主成分分析(PCA)演算法
https://baike.baidu.com/item/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90/829840?fromtitle=%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90%E6%B3%95&fromid=2652206&fr=aladdin
PCA原理
均值,方差,協方差,協方差矩陣,特征值,特征向量
https://blog.csdn.net/wiborgite/article/details/83513234
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/266708.html
標籤:其他
上一篇:現在的年輕人怎么了?才20幾歲就在焦慮35歲后的出路!說程式員是青春飯的都是因為自己菜!
下一篇:烤面筋的第十一場