大三黨,大資料專業,正在為面試準備,歡迎學習交流,
文章詳細總結了插入排序、希爾排序、選擇排序、歸并排序、交換排序(冒泡排序、快速排序)、基數排序、外部排序,從思想到代碼實作,往期文章
緒論-資料結構的基本概念
緒論-演算法
線性表-順序表和鏈式表概念及其代碼實作
查找-順序+折半+索引+哈希
文章目錄
- 1 排序的基本概念
- 1.1 何為排序
- 1.2 穩定排序和不穩定排序
- 1.3 內部排序和外部排序
- 2 插入排序
- 2.1 基本思想
- 2.2 插入排序三步曲
- 2.3 舉例
- 2.4 演算法的代碼描述
- 2.5 時間復雜度
- 2.6 性能總結+改進直接插入的方法
- 3 希爾排序(插入排序的改進方法)
- 3.1 基本思想
- 3.2 排序程序
- 3.3 數值演示
- 3.4 演算法的代碼描述
- 3.5 希爾排序特點
- 3.6 最壞時間復雜度分析及總結
- 4 選擇排序
- 4.1 基本思想
- 4.2 排序程序
- 4.3 演算法的代碼描述
- 4.4 演算法性能分析(復雜度)
- 5 歸并排序
- 5.1 基本思想
- 5.2 二路歸并排序流程
- 5.3 演算法描述
- 5.4 演算法評價
- 6 交換排序
- 6.1 冒泡排序(簡單)
- 6.1.21排序程序
- 6.1.2演算法的實作
- 6.1.3演算法評價(復雜度)
- 6.1.4 冒泡排序的改進(關鍵)
- 6.2 快速排序(復雜)
- 6.2.1 基本思想
- 6.2.2 樞紐的選擇
- 6.2.3 排序程序
- 6.2.4 演算法的實作
- 6.2.5 性能評價(復雜度)
- 6.2.6 快速排序演算法特點
- 7 基數排序
- 7.1 基數排序定義
- 7.2 高位優先多關鍵字排序
- 7.3 低位優先多關鍵字排序
- 7.4 鏈式基數排序操作
- 7.5 順序存盤結構實作鏈式基數排序
- 8 外部排序
- 8.1 外部排序的基本概念
- 8.2 外排序模型
- 8.3 預處理階段
- 8.4 歸并階段之兩路歸并
- 8.5 歸并階段之多路歸并
1 排序的基本概念
1.1 何為排序
將一組資料元素序列重新排列,使得資料元素序列按某個資料項(關鍵字)有序,
1.2 穩定排序和不穩定排序
對于任意的資料元素序列,若排序前后所有相同關鍵字的相對位置都不變,則稱該排序方法稱為穩定的排序方法,
若存在一組資料序列,在排序前后,相同關鍵字的相對位置
發生了變化,則稱該排序方法稱為不穩定的排序方法,
1.3 內部排序和外部排序
若整個排序程序不需要訪問外存便能完成,則稱此類排序問題為內部排序;

反之,若參加排序的記錄數量很大,整個序列的排序程序不可能在記憶體中 完成,則稱此類排序問題為外部排序,
2 插入排序
2.1 基本思想
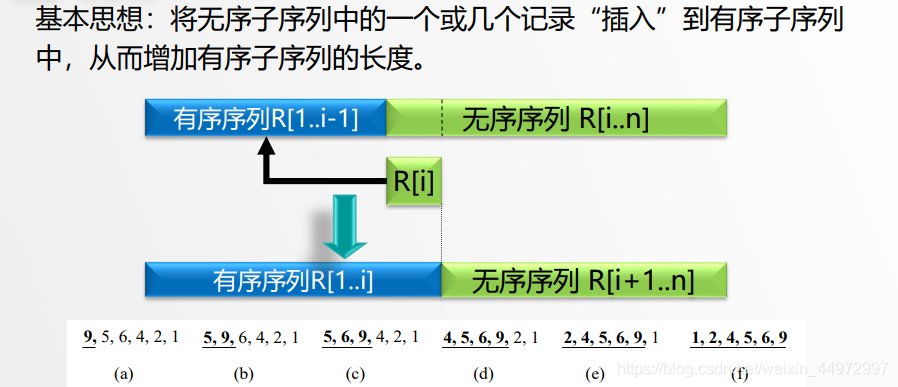
2.2 插入排序三步曲
定位->擠空->插入
- 在R[1…i-1]中查找R[i]的插入位置,
R[1…j].key ? R[i].key < R[j+1…i-1].key; - 將R[j+1…i-1]中的所有記錄均后移 一個位置;
- 將R[i] 插入(復制)到R[j+1]的位置上
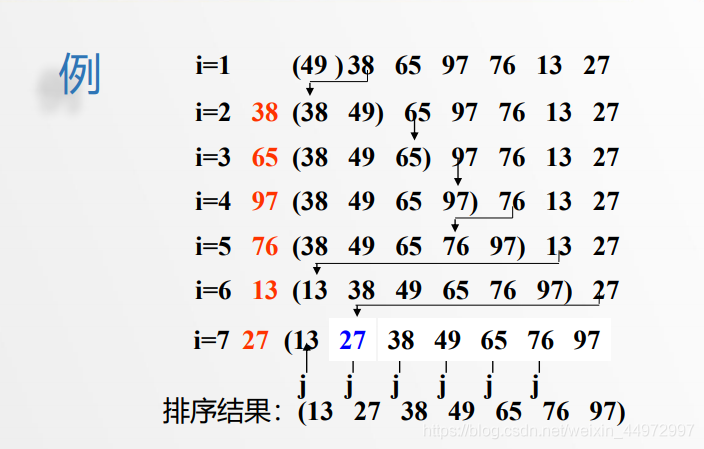
2.3 舉例
排序程序:整個排序程序為n-1趟插入,即先將序列中第
1個記錄看成是一個有序子序列,然后從第2個記錄開始,
逐個進行插入,直至整個序列有序
2.4 演算法的代碼描述
- 兩層回圈外層控制無序序列的取值 內層控制崗哨在有序的排序 找到位置跳出插入
- r[0] 作為崗哨 每次從無序依次取出放入 用來和有序序列比較插入
- j控制有序序列 j=i-1 每次都從有序的最后一個開始
- i控制無序序列 從前往后取 和 j順序相反
- 代碼中從小到大排序
- 需要注意第二個回圈如果崗哨比所有的值都要小最后會r[0] 和r[0]自己比較一樣能夠跳出回圈
補充 重要 崗哨的目的也是為了防止覆寫 可以思考 如果先移動有序序列就會把無序序列的第一個值覆寫
typedef struct
{ int key;//關鍵字
float info;//該成員的其他資訊
}JD;
void straisort(JD r[],int n)//對長度為n的序列
{
int i,j;
for(i=2;i<=n;i++)
{
r[0]=r[i]//第一個需要排序的設為崗哨 不取因為1看做有序 其余n-1看做無序序列
j=i-1;//從后往前
//需要注意第二個回圈如果崗哨比所有的值都要小最后會r[0] 和r[0]自己比較一樣能夠跳出回圈
while(r[0].key<r[j].key)
{
r[j+1]=r[j]
j--;
}
r[j+1]=r[0]
}
}
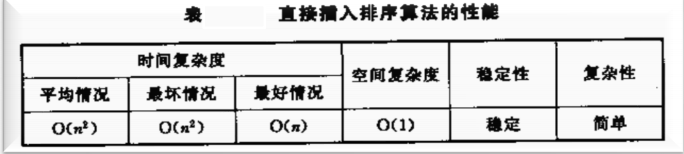
2.5 時間復雜度
最好情況分析:如果n個值比較,開始1個為有序 n-1為無序,需要進行n-1趟的排序,當序列為初始就是順序排列,那么每次取出放入崗哨的值都比有序的大,那么每趟只需要比較一次,比較次數為n-1,由于需要放入崗哨再移動到有序的最后所以每趟移動2次,
最壞情況分析:當序列為初始就是逆序排列,一樣是n-1趟排序,第1趟比較次數為2(特別注意 崗哨除了跟第一個值比較 還要跟自己比較一次才能跳出回圈 回頭看代碼 )所以應該是 2,3,4…n 等引數列相加,第1趟移動為3次(1是移動到崗哨 2是有序值后移 3 是崗哨移到有序值之前的位置)所以應該是 3,3,4…n+1 等引數列相加

2.6 性能總結+改進直接插入的方法
 簡單插入排序的本質比較和交換
簡單插入排序的本質比較和交換
簡單插入排序復雜度由逆序個數決定
如何改進簡單插入排序復雜度?
- 分組,比如C(n,2)/2>2C((n/2),2)/2
- 3,2,1有3組逆序對(3,1)(3,2)(2,1)需要交換3次,但相隔較遠的3,1交換一次后1,2,3就沒有逆序對了,
- 基本有序的插入排序演算法復雜度接近O(n)
3 希爾排序(插入排序的改進方法)
3.1 基本思想
分割成若干個較小的子檔案,對各個子檔案分別進行直接插入排序,當檔案達到基本有序時,再對整個檔案進行一次直接插入排序,
對待排記錄序列先作“宏觀”調整,再作“微觀”調整
3.2 排序程序
- 首先將記錄序列分成若干子序列,
- 然后分別對每個子序列進行直接插入排序,
- 最后待基本有序時,再進行一次直接插入排序
如下 
其中,d 稱為增量,它的值在排序程序中從大到小逐漸縮小,直至最后一趟排序減
為 1,
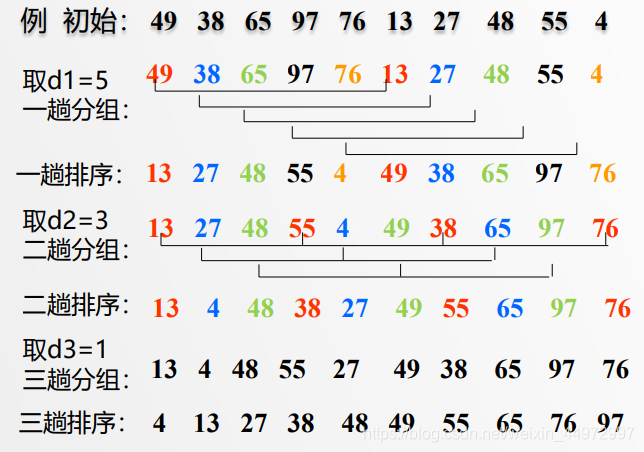
3.3 數值演示
記住思想,若干個部分有序最后達到整體有序,使得復雜度最低,
3.4 演算法的代碼描述
注意看注釋,特別注意d[ ]是什么
1三個回圈嵌套
2最外回圈控制選擇不同的d
3二層回圈控制依次取出間隔為d的兩個值,比較后后移一位
4最內層回圈控制 2個值之間的比較換位置
//r[]表示待排序的序列 n表示個數
//d[]表示增量序列 就是d的取值 7 6 5 ..這樣
// T表示幾種增量序列 d[]的元素個數
void shellsort(JD r[],int
n,int d[],int T)
{
int i,j,k;
JD x;
k=0;
//回圈每一趟進行分組,組內進行簡單插入排序
}
while(k<T)
{
for(i=d[k]+1;i<=n;i++)
//i為未排序記錄的位置
{
x=r[i];
//每組兩個數 位置為 i j j為本組i前面的記錄位置
j=i-d[k];
while((j>0)&&(x.key<r[j].key))
//組內簡單插入排序
{
r[j+d[k]]=r[j];
j=j-d[k];
}
r[j+d[k]]=x;
}
k++;
}
3.5 希爾排序特點
- 子序列的構成不是簡單的“逐段分割”,而是將相隔某個增量的記錄組成一個子序列
- 希爾排序可提高排序速度,因為(分組后n值減小,n2更小,而T(n)=O(n2),所以T(n)從總體上看是減小了)(關鍵字較小的記錄跳躍式前移,在進行最后一趟增量為1的插入排序時,序列已基本有序)
- 增量序列取法(無除1以外的公因子)(最后一個增量值必須為1)
3.6 最壞時間復雜度分析及總結
【定理】使用希爾增量的最壞時間復雜度為 o( N2 ).
如下例子

希爾排序演算法本身很簡單,但復雜度分析很復雜. 他適合于中等資料量大小的排序(成千上萬的資料量).

4 選擇排序
4.1 基本思想
從無序子序列中“選擇”關鍵字最小或最大的記錄,并將它加入到有序子序列中,以此方法增加記錄的有序子序列的長度,
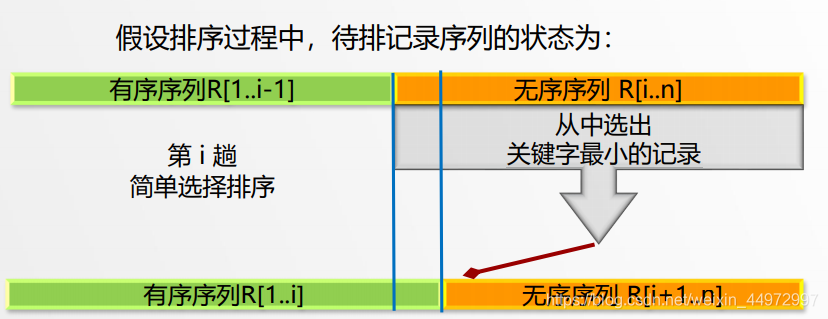
4.2 排序程序
- 首先通過n-1次關鍵字比較,從n個記錄中找出關鍵字最小的記錄,將它與第一個記錄交換
- 再通過n-2次比較,從剩余的n-1個記錄中找出關鍵字次小的記錄,將它與第二個記錄交換
- 重復上述操作,共進行n-1趟排序后,排序結束
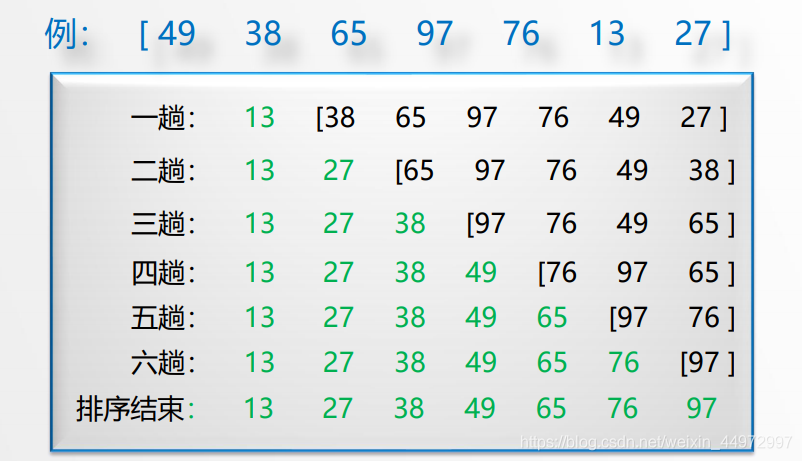
4.3 演算法的代碼描述
兩層回圈
外層回圈控制每次比較的序列從n 到n-1 …2 每次減去1(也可以理解成初始坐標從 1 到n-1 逐漸后移)
內層回圈找到最小值的坐標
然后交換每趟第一個值和最小值的位置(只變換兩個)
void smp_selesort(JD r[], int n){
int i, j, k;
JD x;
for (i = 1;i<n;i++){
k = i;//初始把每趟第一個坐標設為最小關鍵字坐標
//回圈找到未排序的最小關鍵字下標
for (j = i + 1;j <= n;j++)
{
if (r[j].key<r[k].key)
k = j;
}
//如果最小坐標不是原來的 交換
if (i != k)
{
x = r[i];
r[i] = r[k];
r[k] = x;
}
}
4.4 演算法性能分析(復雜度)
- 若n個記錄,需要n-1趟,當2個值需要比較1次 3個值比較2次 n個值比較n-1次,等引數列求和得到總次數,
- 當序列順序不需要移動
- 當序列逆序,每趟需要移動3次,如下代碼
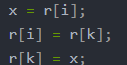
- 由于需要額外的一個空間所以復雜度為常數1,就是上面的x
總結如下

補充-穩定性分析
5 歸并排序
5.1 基本思想
歸并——將兩個或兩個以上的有序表組合成一個新的有序表,叫歸并排序
5.2 二路歸并排序流程
設初始序列含有n個記錄,則可看成n個有序的子序列,每個子序列長度為1兩兩合并,得到【n/2】個長度為2或1的有序子序列再兩兩合并,……如此重復,直至得到一個長度為n的有序序列為止



5.3 演算法描述
待補充
5.4 演算法評價

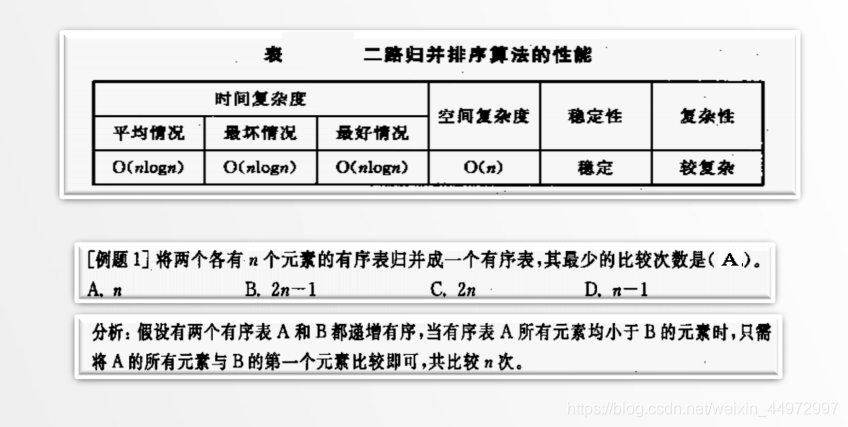
6 交換排序
通過“交換”無序序列中的記錄從而得到其中關鍵字
最小或最大的記錄,并將它加入到有序子序列中,以此方法增加記錄的有序子序列的長度,
- 冒泡排序(簡單)
- 快速排序(復雜)
6.1 冒泡排序(簡單)
6.1.21排序程序
- 將第一個記錄的關鍵字與第二個記錄的關鍵字進行比 較,若為逆序r[1].key>r[2].key,則交換;然后比較第二個記錄與第三個記錄;依次類推,直至第n-1個 記錄和第n個記錄比較為止——第一趟冒泡排序,結果關鍵字最大的記錄被安置在最后一個記錄上
- 對前n-1個記錄進行第二趟冒泡排序,結果使關鍵字 次大的記錄被安置在第n-1個記錄位置
- 重復上述程序,直到“在一趟排序程序中沒有進行過 交換記錄的操作”為止

6.1.2演算法的實作
兩層回圈
外層回圈控制排序的序列長度 從前n個 到 前n-1個 …前2個
內層回圈控制前后兩個數兩兩比較及交換位置,下標1 和 2 ;2 和 3;…
注意這邊設定flat標志位 如果一層外層回圈中沒有交換 那么直接退出外層回圈
void bubble_sort(JD r[], int n)
{
int m, i, j, flag = 1;
JD x;
m = n ;
while ((m>1) && (flag == 1))/*趟數*/
{
flag = 0;/*本趟是否有交換操作標識初始化*/
for (j = 1;j < m;j++)//*本趟將最大元素放到為排序序列的最后*/
if (r[j].key>r[j + 1].key)
{
flag = 1;
x = r[j];
r[j] = r[j + 1];
r[j + 1] = x;
}
m--;
}
}
6.1.3演算法評價(復雜度)
最壞情況一樣用等差序列的計算 n-1趟 每趟的值逐漸減小1
交換用到一個額外的空間 所以空間復雜度為1

6.1.4 冒泡排序的改進(關鍵)
- 冒泡排序的結束條件為,最后一趟沒有進行“交換記錄”,
- 一般情況下,每經過一趟“冒泡”,“m減1”,但并不是每趟都如此,
只需要一個變數指向最后一次交換的位置,作為下一次的m

6.2 快速排序(復雜)
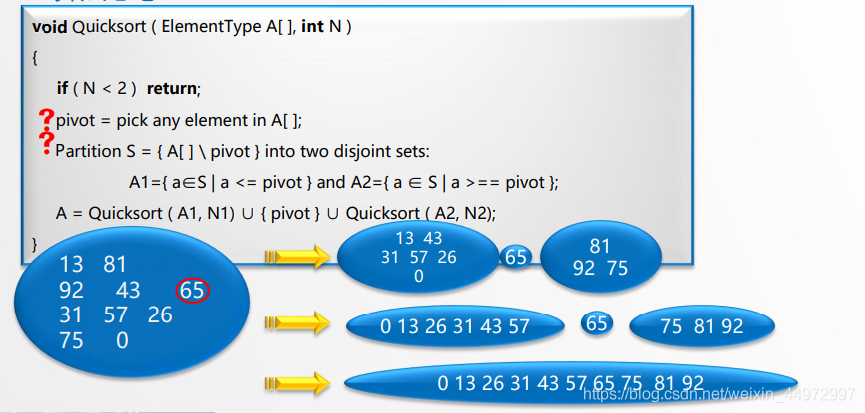
6.2.1 基本思想
選擇一個樞紐,把其他的元素分為兩個不相交的兩個集合A1 A2,A1中的元素全部都小于樞紐,A2中的元素全部都大于樞紐, 同樣的對A1,A2也這樣處理,如此反復,
結束條件,個數小于2,
6.2.2 樞紐的選擇
6.2.3 排序程序
- 對r[s……t]中記錄進行一趟快速排序,附設兩個指標i和j,設劃分元記錄rp=r[s],x=rp.key
- 初始時令i=s,j=t
- 首先從j所指位置向前搜索第一個關鍵字小于x 的記錄,并和rp交換
- 再從i所指位置起向后搜索,找到第一個關鍵字大于x的記錄,和rp交換
- 重復上述兩步,直至i==j為止
- 再分別對兩個子序列進行快速排序,直到每個子序列只含有一個記錄為止
6.2.4 演算法的實作
嵌套的兩個while比較難理解,嵌套中其實并沒有交換,只是把值覆寫樞紐位置的值,樞紐并沒有更換過來,當外回圈結束再把樞紐填入到中間位置,此時i=j,
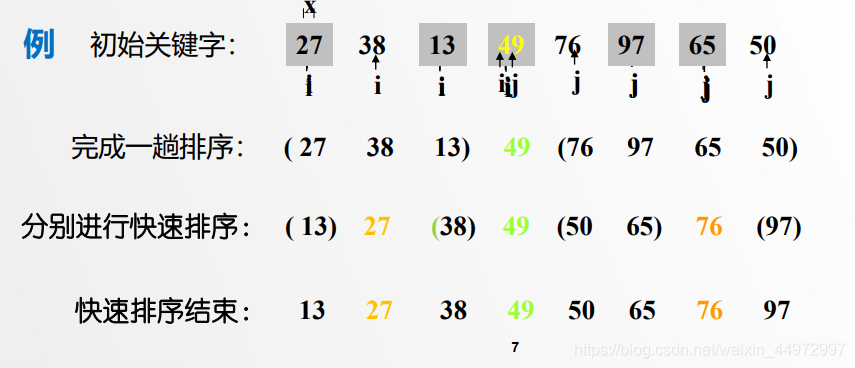
例如初始值 如下 樞紐為10 亮的位置是樞紐的現在位置 代碼中實際變化如下
10(i) 8 11 7(j) --》 10比7大 7覆寫10的位置(樞紐的位置) 并沒有馬上更換原本7為10(也就是沒有馬上更換樞紐的現在位置)
7 8(i) 11 7(j) --》i后移一個到8比10小 不變
7 8 11(i) 7(j) --》i后移一個到11比10大 11覆寫7的位置(樞紐的位置)
7 8 11(i j) 11 --》i=j結束
7 8 10 11 --》 退出外while回圈 把樞紐填入
void qksort(JD r[], int t, int w)
{//t=low,w=high
int i, j, k;//i j表示兩個移動的坐標(指標)(頭和尾)
JD x;
if (t >= w) return;//結束條件
i = t; j = w; x = r[i]; //賦值操作 同時把第一個值作為樞紐x
while (i<j)
{
while ((i<j) && (r[j].key >= x.key)) j--;//樞軸后面的值大于樞軸
if (i<j) { r[i] = r[j]; i++; }//當不滿足時,與樞軸交換
while ((i<j) && (r[i].key <= x.key)) i++;//樞軸前面的值小于樞軸
if (i<j) { r[j] = r[i]; j--; }//不滿足,與樞軸交換
}
r[i] = x;
qksort(r, t, j - 1);
qksort(r, j + 1, w);
}
6.2.5 性能評價(復雜度)
待補充這部分(空間的不是很明白)

6.2.6 快速排序演算法特點
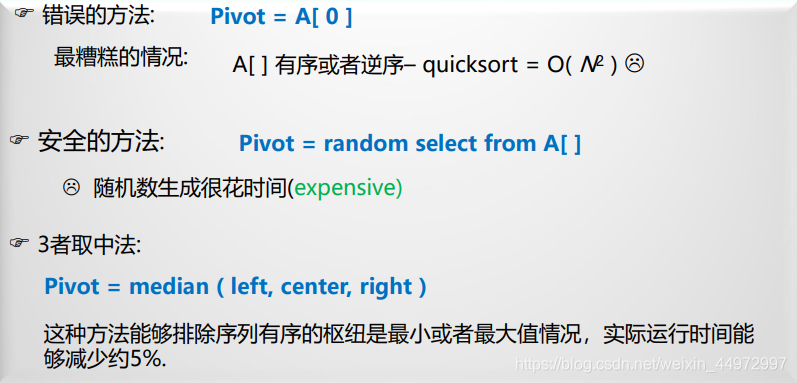
- 快速排序演算法是不穩定的–對待排序序列 49 49’ 38 65,快速排序結果為: 38 49’ 49
65 - 快速排序的性能跟初始序列中關鍵字的排列和選取的樞紐有關
- 當初始序列按關鍵字有序(正序或逆序)時,性能最差,蛻化為冒泡排序,時間復雜度為O(n2)
- 常用“三者取中”法來選取劃分記錄,即取首記錄r[s].key.尾記錄r[t].key和中間記錄r[(s+t)/2].key三者的中間值為劃分記錄,
- 快速排序演算法的平均時間復雜度為O(nlogn)

7 基數排序
7.1 基數排序定義

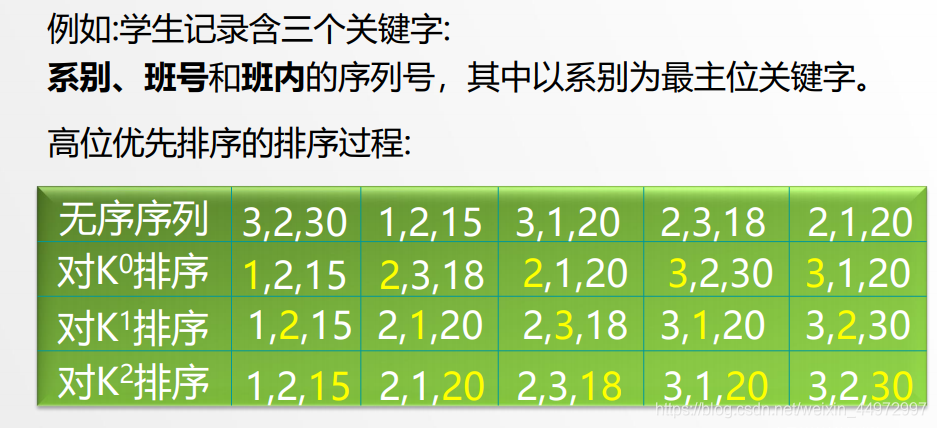
7.2 高位優先多關鍵字排序
先對K0進行排序,并按 K0 的不同值將記錄序列分成若干子序列之后,分別對 K1 進行排序,……, 依次類推,直至對最次位關鍵字Kd-1排序完成為止,
7.3 低位優先多關鍵字排序
首先按關鍵字 Kd-1進行排序,然后按關鍵字Kd-2進行排序,……,依次類推,直最后對最主位關鍵字K0排序完成為止,

7.4 鏈式基數排序操作
例如三位整數,百位優先級>十位優先級>個位優先級,取值0~9,我們可以給出10個桶如下,每個桶都有頭指標節點和尾指標節點,當我們采用低位優先可以將資料根據個位數放入到對應的桶子中,相同桶子資料依次穿成鏈表,當資料全部放入我們從第一個桶子開始,每一個尾指標指向下一個非空桶的頭指標節點,最后拉直,完成,
由于有三個關鍵字需要進行3趟,具體實作如下圖,
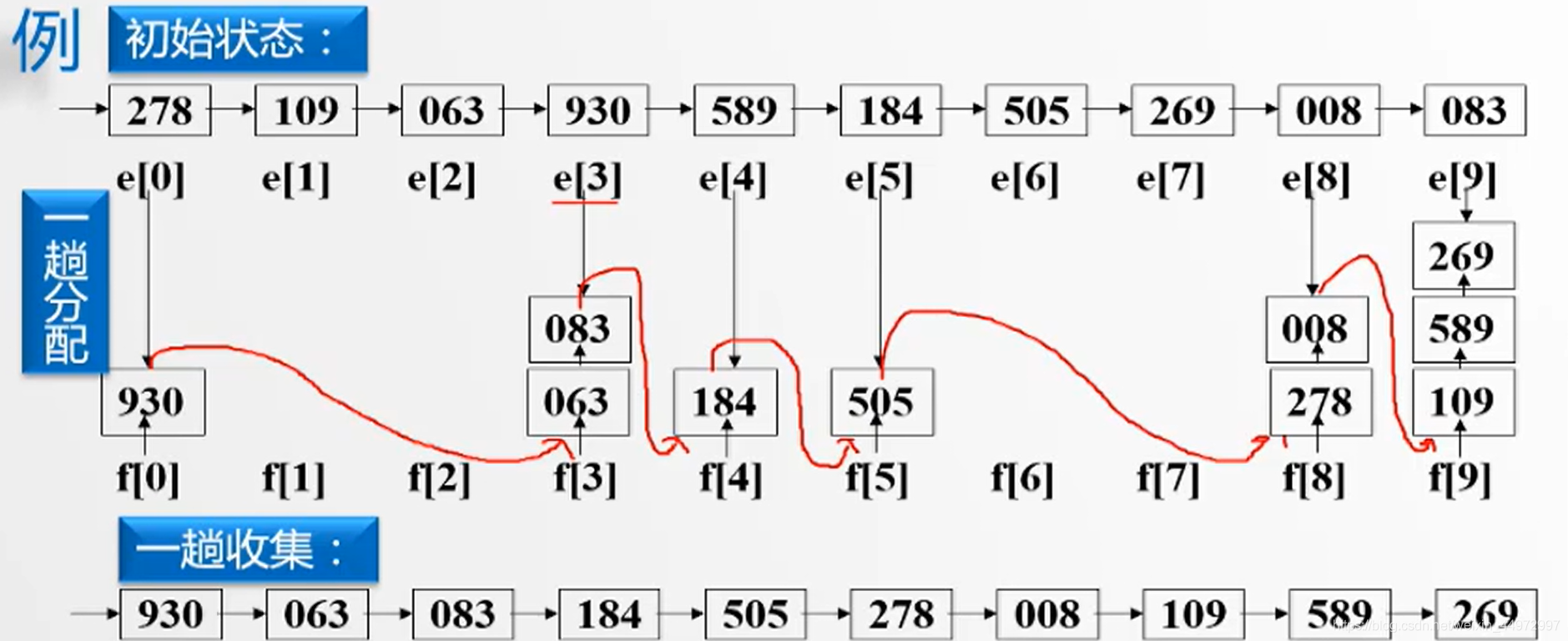
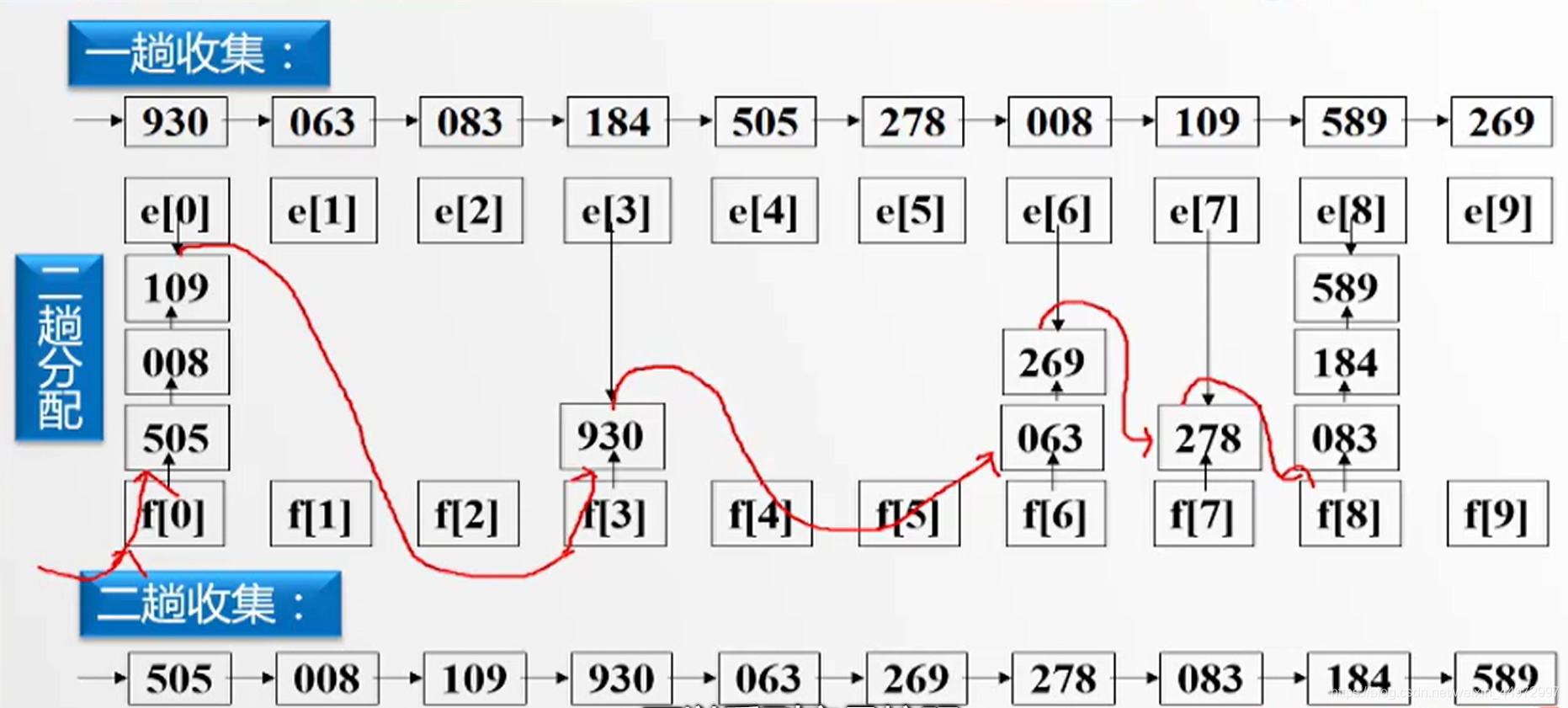
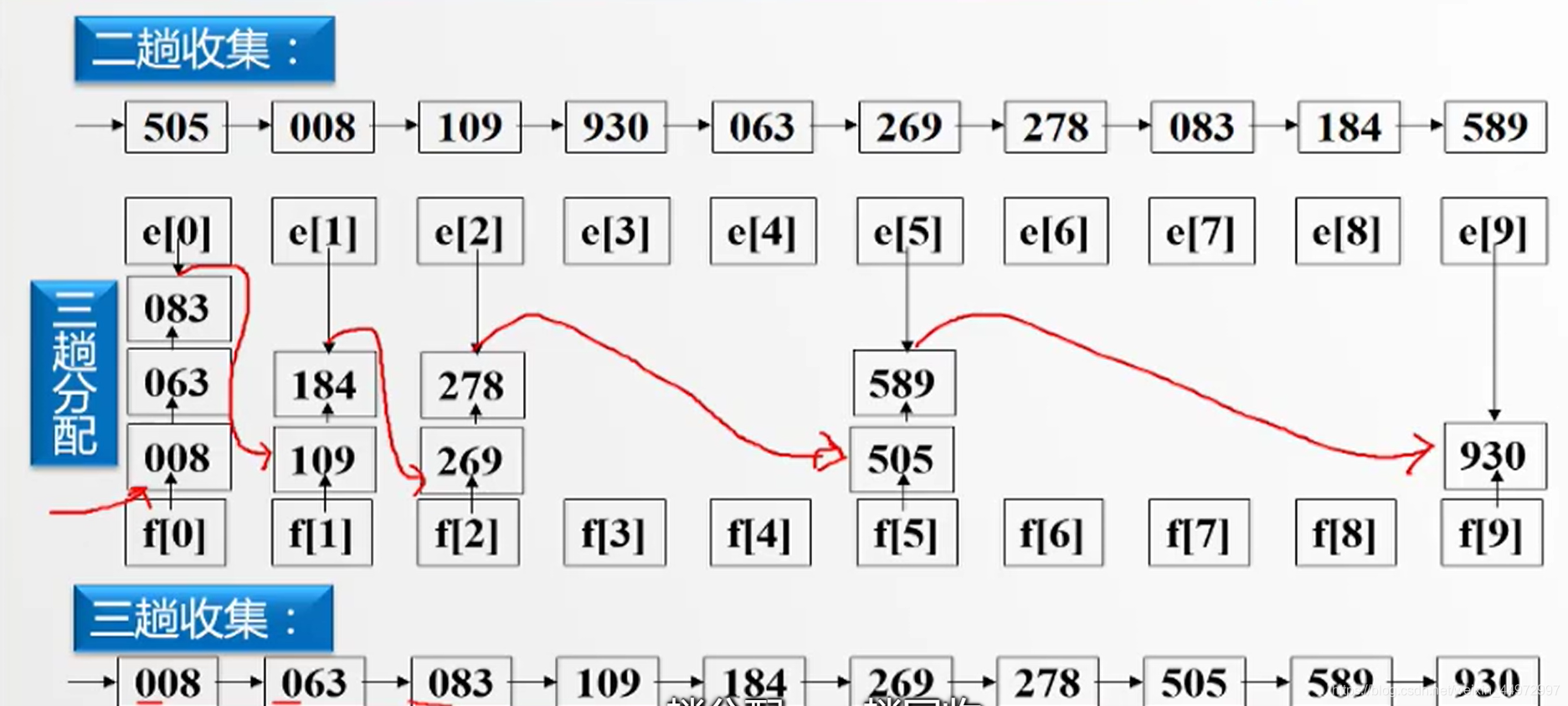
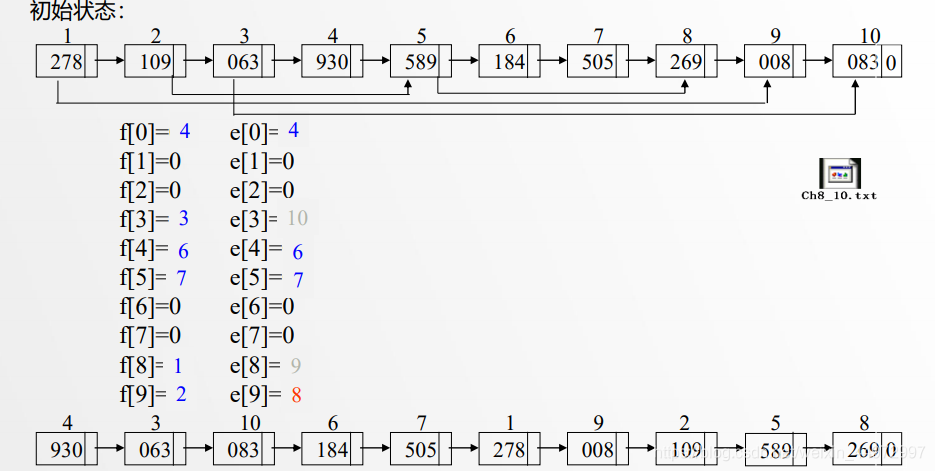
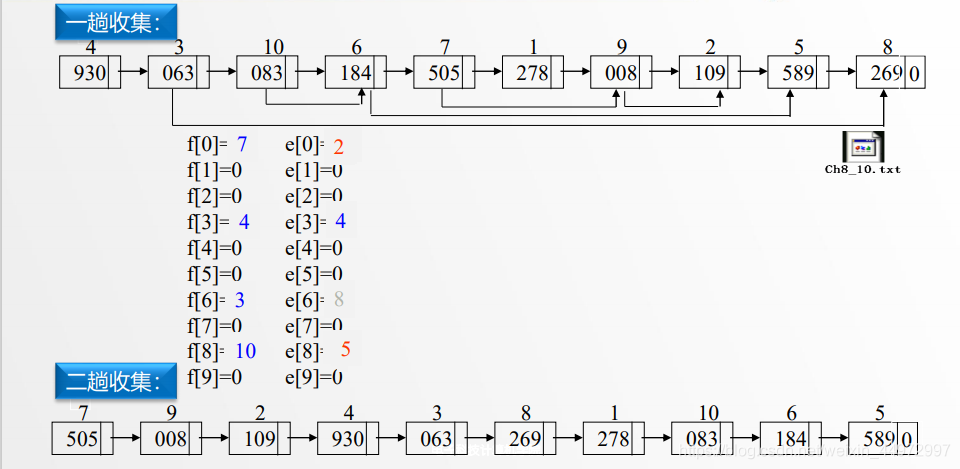
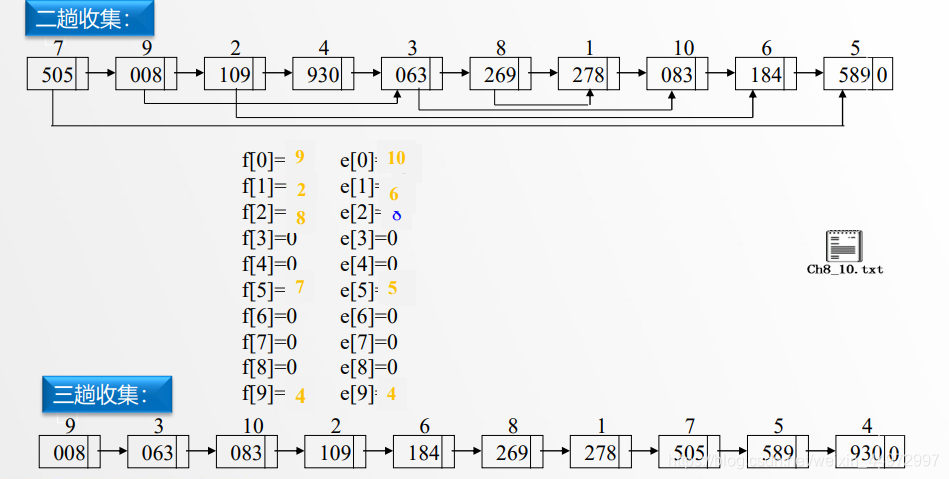
7.5 順序存盤結構實作鏈式基數排序
類似的原理,我們可以設定頭指標和尾指標,但是需要注意的是 f[] e[] 分別記錄的是第一個資料的坐標和最后一個資料的坐標,而不是指標,
8 外部排序
8.1 外部排序的基本概念
大多數內排序演算法都是利用了記憶體是直接訪問的事實,讀寫一個資料是常量的時間,如果輸入是在磁帶上,磁帶上的元素只能順序訪問,甚至資料是在磁盤上,效率還是下降,因為轉動磁盤和移動磁頭會產生延遲,
8.2 外排序模型
- 外排序具有設備依賴性,這里考慮的演算法作業在磁帶上
- 完成有效的排序至少需要兩個磁帶機
- 三個磁帶機可以簡化問題
- 外排序由兩個階段組成:預處理階段 歸并階段
8.3 預處理階段
概述:根據記憶體的大小將一個有n個記錄的檔案分批讀入記憶體,用各種內排序演算法排序,形成一個個有序片段,
- 最簡單的方法是按照記憶體的容量盡可能多地讀入資料記錄,然后在記憶體進行排序,排序的結果寫入檔案,形成一個已排序片段,
- 每次讀入的記錄數越小,形成的初始的已排序片段越多,而已排序片段越多,歸并的次數也越多,
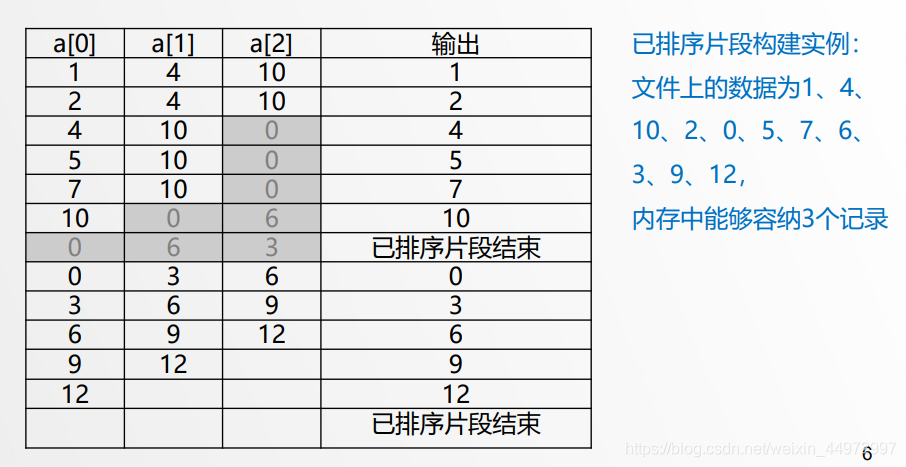
- 如果能夠讓每個初始的已排序片段包含更多的記錄,就能減少排序時間,置換選擇可以讓我們在只能容納p個記錄的記憶體中生成平均長度為2p的初始的已排序片段,
置換選擇
- 如何更有效地構造已排序片段
- 事實上,只要第一個元素被寫到輸出磁帶上,它所用的記憶體空間就可以給別的元素使用,如果輸入磁帶上的下一個元素比剛剛輸出的元素大,它能被放入這個已排序片段,
置換選擇流程(看下圖很容易理解)
- 初始時,將M個元素讀入記憶體,用一個優先佇列存盤這M個元素,
- 執行一次取最小元素操作,把最小的元素寫入輸出磁帶,
- 從輸入磁帶讀入下一個元素,
- 1如果它比剛才寫出去的元素大,則把它加入到優先級佇列;
- 2.否則,它不可能進入當前的已排序片段,因為優先級佇列比以前少了一個元素,該元素就被放于優先級佇列的空余位置,
- 繼續這個程序,直到優先級佇列的大小為0,此時該已排序片段結束,我們重新構建一個優先級佇列,開始了一個新的已排序片段,此時用了所有存放在空余位置中的元素,
置換選擇實體演示流程
8.4 歸并階段之兩路歸并
文字描述可能比較復雜配合看圖的實體演示比較容易
-
假設我們有四條磁帶A1,A2,B1和B2,兩個用于輸入,兩個用于輸出,開始時資料在A1上
-
記憶體一次能排序M個記錄
-
作業流程
-
1 從輸入磁帶上一次讀入M個記錄,對它們進行內排序,然后把已排序片段輪流寫到B1和B2,回繞所有的磁帶 ,–預處理
-
2 取每條磁帶上的第一個已排序片段,把它們歸并起來,并把結果寫到A1,然后,從每條磁帶上取下一個已排序片段,把它們歸并起來,結果寫到A2,繼續這個程序,輪流把結果寫到A1和A2,
-
3 回繞四條磁帶,重復同樣的步驟,這次使用A磁帶作為輸入,而B磁帶作為輸出,
-
4 重復步驟二和三,直到剩下一個長度為N的已排序片斷
-
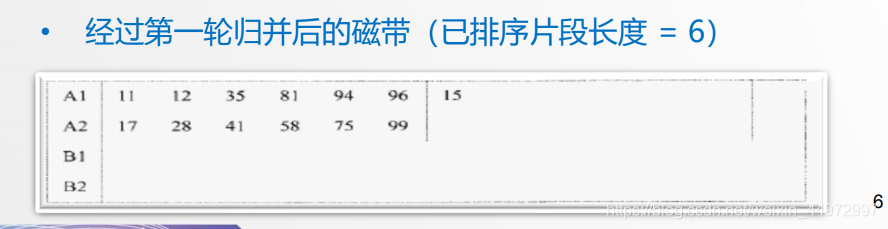
實體演示如下
-
每次讀入3個到記憶體,排序后全部輸出到B1,第二次再讀入3個到記憶體排序輸出到B2,第三次輸出到B1如此反復,
-
每次B1三個值和B2三個值歸并輸入到A1,下一次輸入到A2如此反復和上面一樣,
-
同理,A1 A2作為輸出,每次各取6個歸并輸入到B1,下一次輸入到B2,如此反復
-
最后B1 B2作為輸入 ,B1取12個 B2取出僅剩的一個歸并輸出到A1,結束,




時間分析

8.5 歸并階段之多路歸并
如果還有額外的磁帶,則可以用多路歸并(multiwaymerge)或K路歸并(K-way merge)來減少排序輸入資料所需要的歸并處理次數, 與兩路歸并原理一致



時間效益

內容較多,如果有遺漏和錯誤的地方,歡迎指出,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/267171.html
標籤:其他
上一篇:leetcode453. 最小操作次數使陣列元素相等(賊難的簡單題)
下一篇:機器學習01-基本概念