只是為了做筆記!!!
一,tcp/ip 協議
tcp作業在傳輸層,傳輸包資料
TCP三手握手:
1,客戶端發送一個初始序列號和syn=1請求標志
2,服務端收到后回傳一個syn請求標志,同時發送一個確認標志ack,自己的seq,客戶端的ack+1
3,客戶端收到ack后,發送一個ack,自己的seq對方的ack
三次是為了確保雙方都知道自己接收發送正常
四手揮手:
1,客戶端發出一個fin結束標志,自己的序列號seq=u,進入FIN-WAIT-1的狀態
2,服務端發送ack=1,對方的ack,自己的seq 進入close-wait狀態
3,客戶端進入FIN-WAIT-2狀態,服務端請求斷開,發送seq ack,對方面的ack=對方的序列號+1
4,客戶端收到后,斷開請求,發送ack seq 對方的ack=鄧方的序列號+1
當收到對方的 FIN 報文時,僅僅表示對方不再發送資料了但是還能接收資料,是否結束還需要等待上層應用決定,所以ack和fin分開過需要四次
TCP拆包/粘包
定義: 粘包就是一個較大的包與一個較小的包順序傳輸時,較大的包有部分資料與較小的包粘在了一起,即發生了拆包與粘包
原因:由于沒有明確的包的界限,應用寫入的資料大于套位元組緩沖區,這會發生拆包,反之,粘包
解決辦法:
1,明確邊界,如特殊字符
2,固定長度,不足用0等補足
3,添加包首,包括包長度等資訊
IP作業在網路層
二,mysql
1,mysql架構
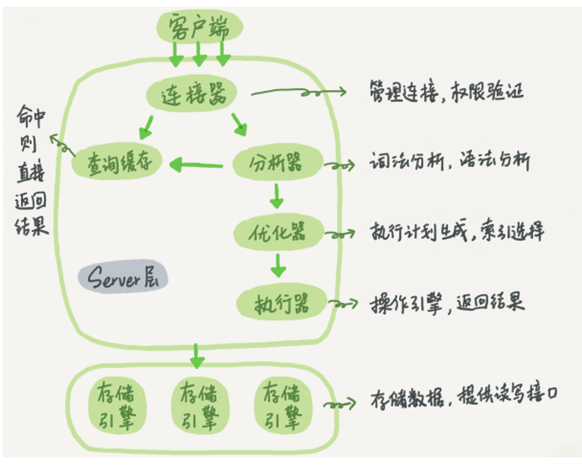
一條sql如果執行的
先從連接器進行權限,用戶校驗,如果有快取則直接回傳結果,如果沒再到第二層的決議器進行語法檢查,然后交給優化器進行索引優化,索引選擇,再到執行器呼叫
engine介面,再回傳
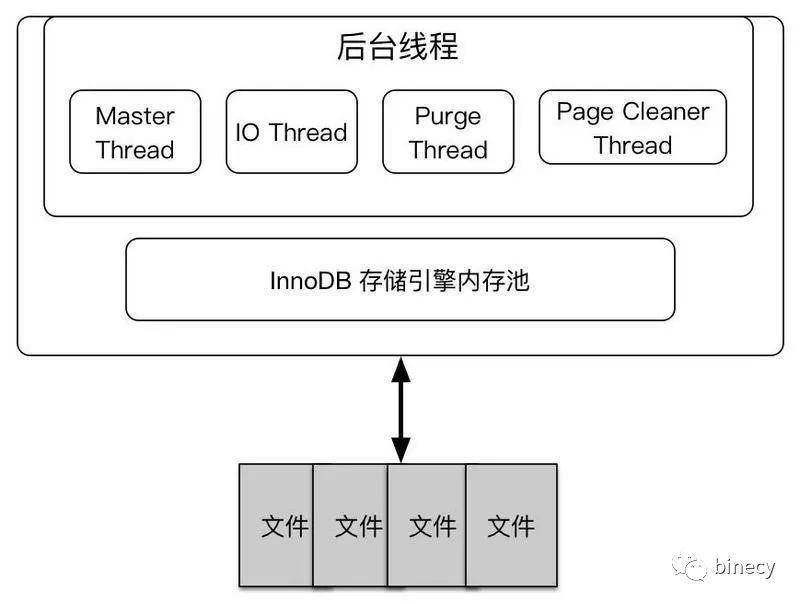
2,InnoDB介紹
2.1 整體架構圖
記憶體池
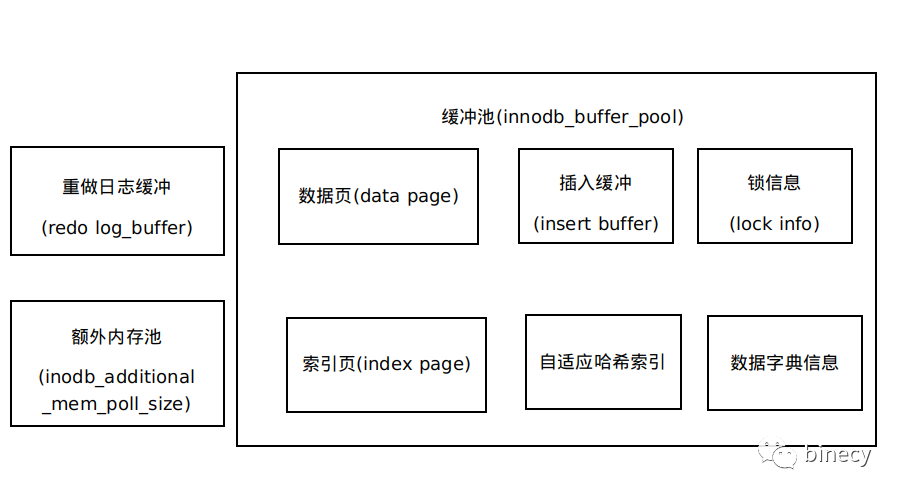
緩沖池( innodb_buffer_pool)
引數:innodb_buffer_pool_size 調整快取大小,通過lru(最近最小使用策略),利用checkpoint(擦除)機制將資料重繪到磁盤(PS:innodb是dml陳述句是先在緩沖區里操作)
重做日志
redo log(已修改記錄日志) 保證事務的原子性,持久性,采用Write ahead Log方式,在事務提交時,先寫重做日志,再修改頁
redo log 在結構上分為兩個部分:一個redo_log_buffer 一個redo_log_file
redo log通常是物理日志,記錄的是資料頁的物理修改,用來恢復資料頁最后一次提交的位置
//引數:
innodb_log_buffer_size ##buffer大小
innodb_flush_log_at_trx_commit ##多少次提交進行一次log file寫入,默認為1
innodb_flush_log_at_timeout ##從緩沖寫入的時間頻率undo log (回滾日志)是一個邏輯日志,用來回滾到行記錄到某個版本
事務
事務的實作就是通過redo log與鎖機制
事務的隔離級別
| 事務隔離級別 | 描述 | 實作原理 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | 一個事務會讀到另一個未提交事務修改過的資料, | 無 | 是 | 是 | 是 |
| READ COMMITTED | 一個事務只能讀到另一個已經提交的事務修改過的資料, | 樂觀鎖+MVCC | 否 | 是 | 是 |
| REPEATABLE READ | 一個事務只能讀到另一個已經提交的事務修改過的資料,而且該事務第一次讀過某條記錄后,即使其他事務修改了該記錄的值并且提交,該事務之后再讀該條記錄時,讀到的仍是第一次讀到的值, | 樂觀鎖+MVCC | 否 | 否 | 是 |
| SERIALIZABLE | 事務串行化執行 | 悲觀鎖 | 否 | 否 | 否 |
Purge 最終實作delete update的操作,由于innodb支持mvcc,所以記錄不能在事務提交時立即處理,因為還有其它事務在參考這行資料undo log (未修改記錄日志) 保證事務的原子性,可回滾操作,和MVCC的實作
MVCC原理
1,表中每行的隱藏列:記錄了一個事務的ID,一個指向上一個版本undo log的指標
2,undo log的版本鏈
3,read view(快照):在RR級別下,開啟事務后,select時,會創建一個快照,把其它活躍的事務記錄下來,RC就是每個select都會生成快照
4,可見性判斷:當前事務ID:trx_id_current,最早的事務ID up_limit_id,最晚的事務ID:low_limit_id
口訣:當前事務ID小于最早的,可見;大于最晚的,不可見,在兩者之間,如果這個事務ID存在不可見,不在可見,需要查找undo log上一個版本
輔記點:事務ID越早越可見
鎖
| 定義 | 實作/原因 | 解決辦法 |
| 每次操作都會被其事務修改,所以會加鎖 | mysql使用共享鎖與排它鎖,行鎖 | |
| 只有在修改時才會加鎖 | 版本號或Cas提交 | |
| 讀一行資料 | ||
| 更新/洗掉一行 | ||
| 鎖單行 | ||
| 間隙鎖,不包括本身 | ||
| record lock + gap lock | ||
| 兩個事務都在請求同一個資源而持續等待無法釋放程序 | 1,兩個事務加鎖的順序不一致 | 1,編碼時注意查詢與寫入的順序 |
死鎖
多個事務在請求同一個資源而互相等待對方釋放的程序
查看方法:
//查看當前所有鎖的情況
show status like '%lock%';
//查看當前行程
show processlist;
1:查看當前的事務
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
2:查看當前鎖定的事務
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
3:查看當前等鎖的事務
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS; 造成原因及解決方法:兩個(或以上)的Session加鎖的順序不一致
從操作資料庫的動作來分析
1.Delete洗掉不存在的資料導致死鎖
容易造成區間鎖
解決方法:
①先檢查記錄是否存在,否則不洗掉,
②對于同一條記錄,建議使用update
③如果鎖是gap鎖,這種死鎖需要將事務的隔離級別設定為read commit,
④對于等待鎖的的會話使用innodb_lock_wait_timeout,防止過載,
2,insert update時造成死鎖
解決方法:
1,使用mysql自有的方法
1,on duplicate key update
2,使用replace來解決2,使用redis自增Key
3, 雪花演算法
3,select for update(行鎖)
Innodb關鍵特性
1,插入緩沖 insert buffer 由于非聚集索引即輔助索引是非連續的,所以在刷盤之前先進行判斷是否在索引快取頁中,如果存在即直接插入或修改,如果不再就放入insert buffer中以一定頻率和輔助索引頁的節點進行合并再刷盤,內部實作也為一果b+tree
2,雙寫:寫redo log和redo log副本,幫且災難恢復
3,自適應hash,監控表的查詢情況,建立一個hash表,不需要建立hash索引
4,異步I/O 預讀,預寫都是通過異步進行
5,重繪鄰近頁:即為同時鄰近臟頁資料
Innodb索引:
原理:使用B+樹的結構,采用聚集索引的結構,葉子節點才會存放行記錄或主鍵記錄,而且索引與資料檔案放在一起的,一張表就是一個聚集索引,myisam是非聚集
優點:按索引排序,方便查詢與order等操作,檢索更快
主索引:葉子節點存放的是行記錄
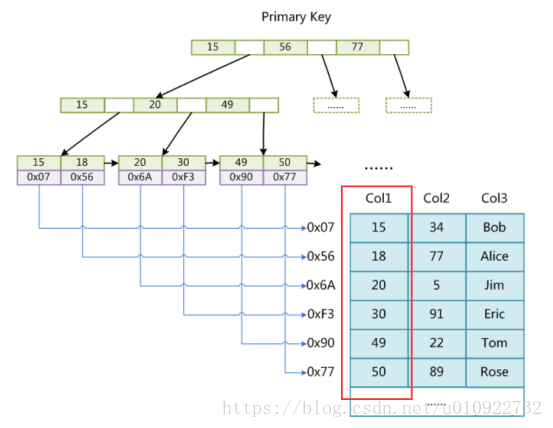
輔助索引:葉子節點存放的主鍵ID,有一個回表的操作,I/O次數為通常為(樹高-1,ps:這個-1是因為根節點常駐記憶體)
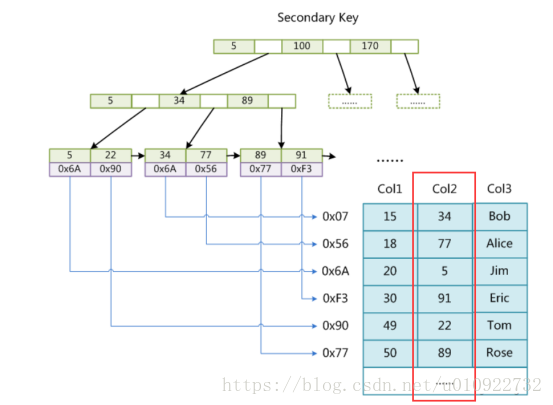
前綴索引:由于mysql的資料頁為16K,一個頁在索引樹上為一個節點,如果要存放更多的索引值,就需要減少索引的長度,而本身索引的長度是有限制的小于767個位元組,組合索引不能超過307位元組,引出一個問題,為什么是3073呢,還是與page 16K相關,因為要預留頁空間和輔助,如果一個頁不能存放一個索引值就退化成了鏈表,不符合設計思想
覆寫索引:用一個sql說明,簡單易懂:select a,b,c from user where a and b and c (a,b,c)union_index
PS:索引下推(5.6后mysql服務器將在判斷條件里有索引的列交給存盤引掣進行判斷,減少底層訪問表的次數,也減少了mysql呼叫存盤引掣的次數)
Mysql主從同步
1,架構圖
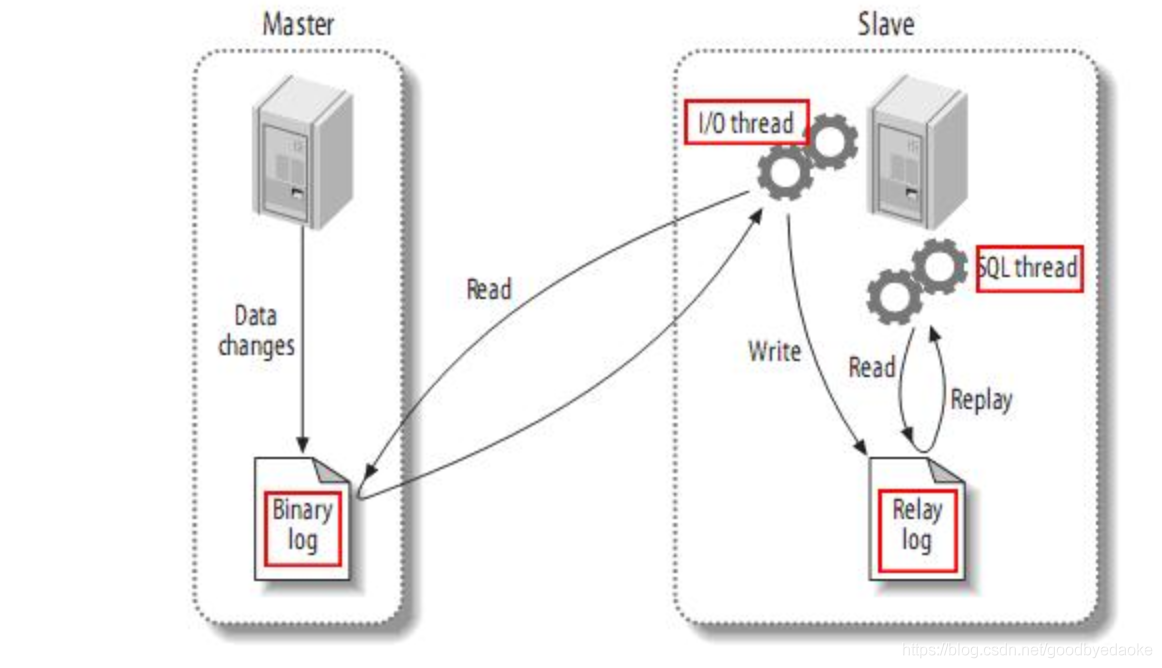
2,同步方式
2.1 異步同步:在master上開啟binlog功能一個I/O同步執行緒,在從庫上配置,兩個執行緒(一個IO執行緒,一個請求執行緒)
//主
server-id=1
log-bin=mysql-bin
//從
log_bin = mysql-bin
server_id = 2
relay_log = mysql-relay-bin
log_slave_updates = 1
read_only = 1
2.2 半同步 master會等待slave至少發送一個寫入relay log成功后提交,否則一直等待至超時(10s)
2.3 多執行緒同步:slave多個執行緒從master同步binlog日志,再順序寫入
3,兩種格式:statment (陳述句);raw(行記錄),一個mixed(混合)
參考檔案 https://zhuanlan.zhihu.com/p/158978012
https://blog.csdn.net/weixin_30311605/article/details/96400293?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control&dist_request_id=1328602.26741.16150133251090833&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.control
三,redis
1,redis的五種常用型別及資料結構(string,list,hash,set,zset)
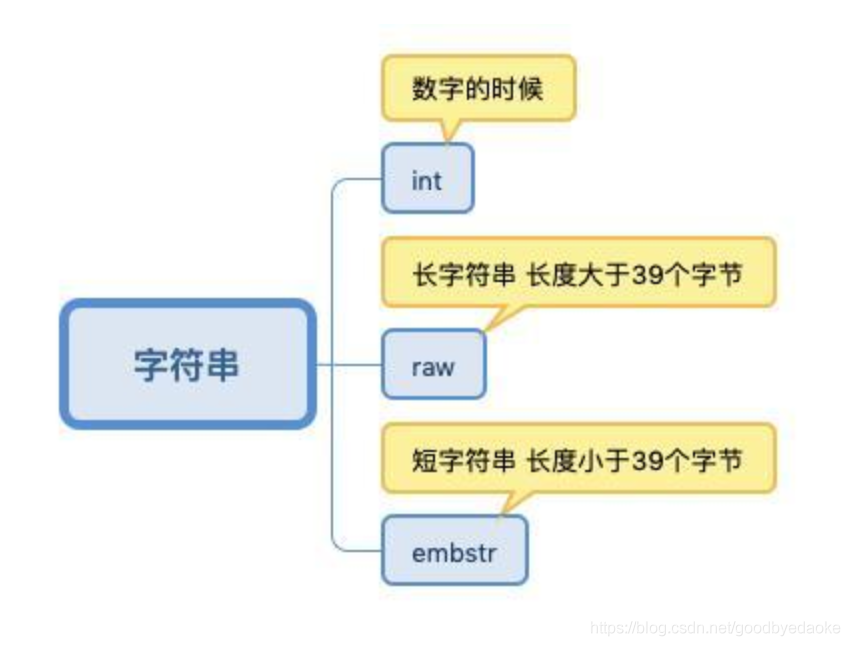
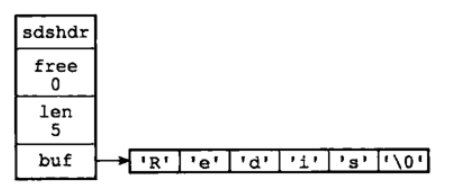
SDS simple synamic string:支持自動動態擴容的位元組陣列,遍歷O(N),獲取長度O(1),二進制安全,有一個特定的結束符\0
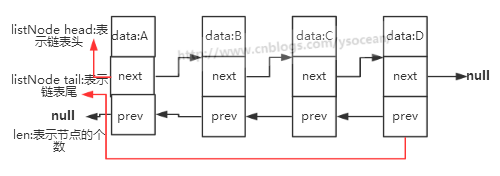
list :鏈表,雙向,無環,長度計數,多型
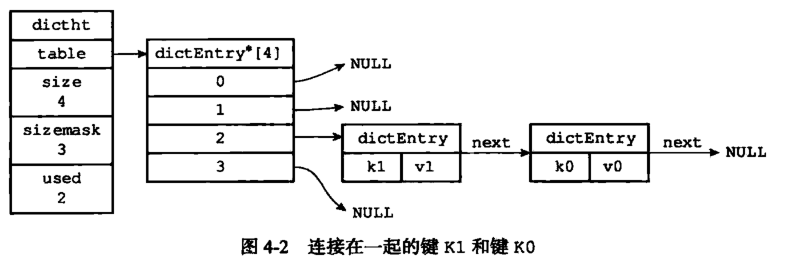
dict :使用雙哈希表實作的, 支持平滑擴容的字典
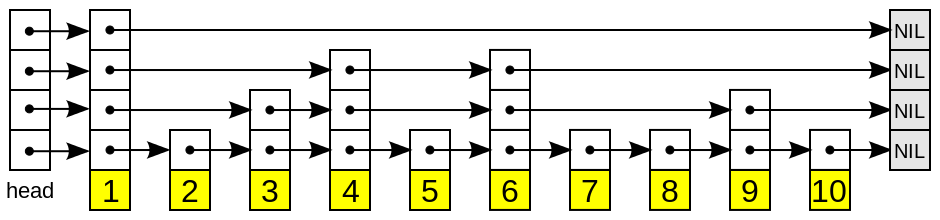
zskiplist :附加了后向指標的跳躍表
intset : 用于存盤整數數值集合的自有結構
ziplist :一種實作上類似于TLV, 但比TLV復雜的, 用于存盤任意資料的有序序列的資料結構
quicklist:一種以ziplist作為結點的雙鏈表結構, 實作的非常不錯
zipmap : 一種用于在小規模場合使用的輕量級字典結構 String:
list:
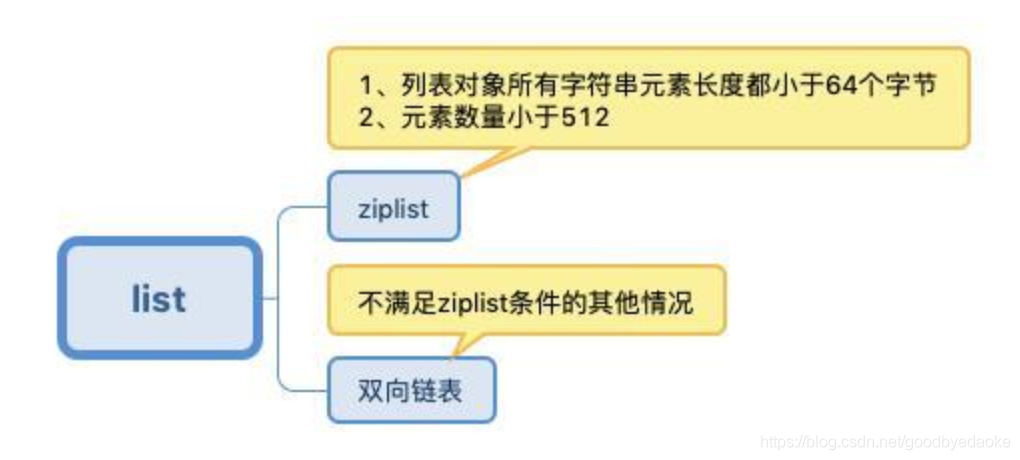
hash:
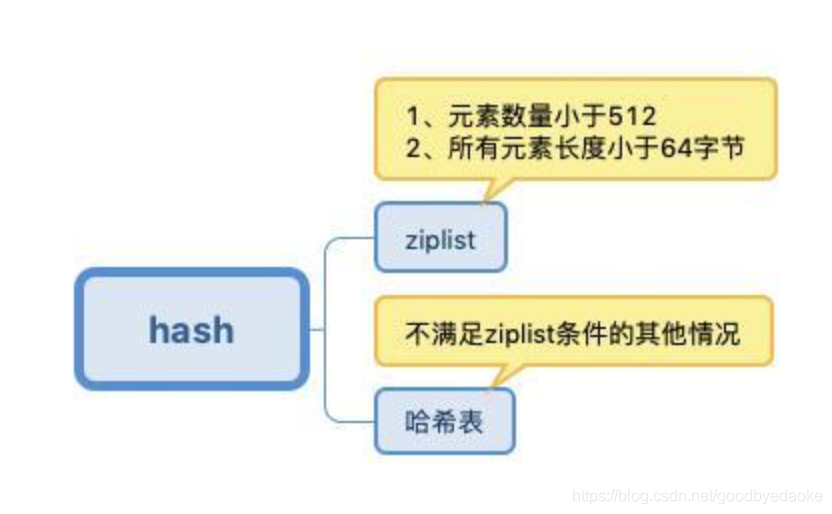
set:
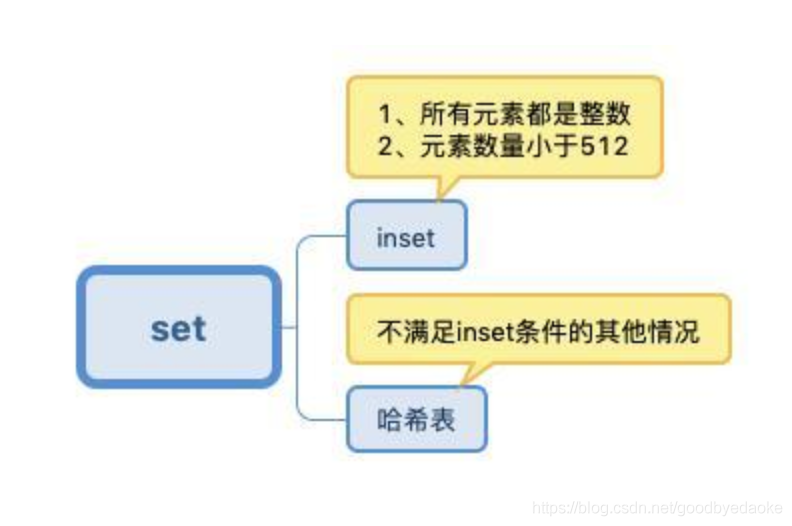
zset有三種還有一種是用hash(字典)
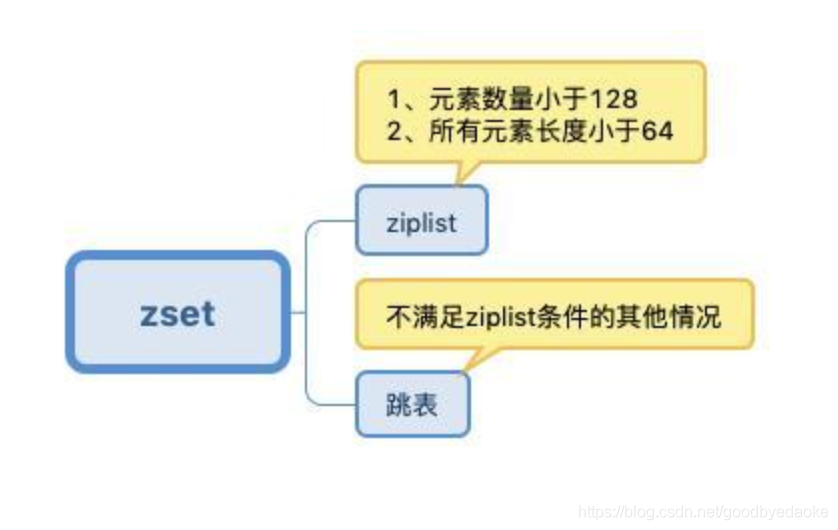
sds做為string的底層結構
list 做為list的底層結構
hashTable做hash的底層結構之一
skiplist 跳表 用兩張表
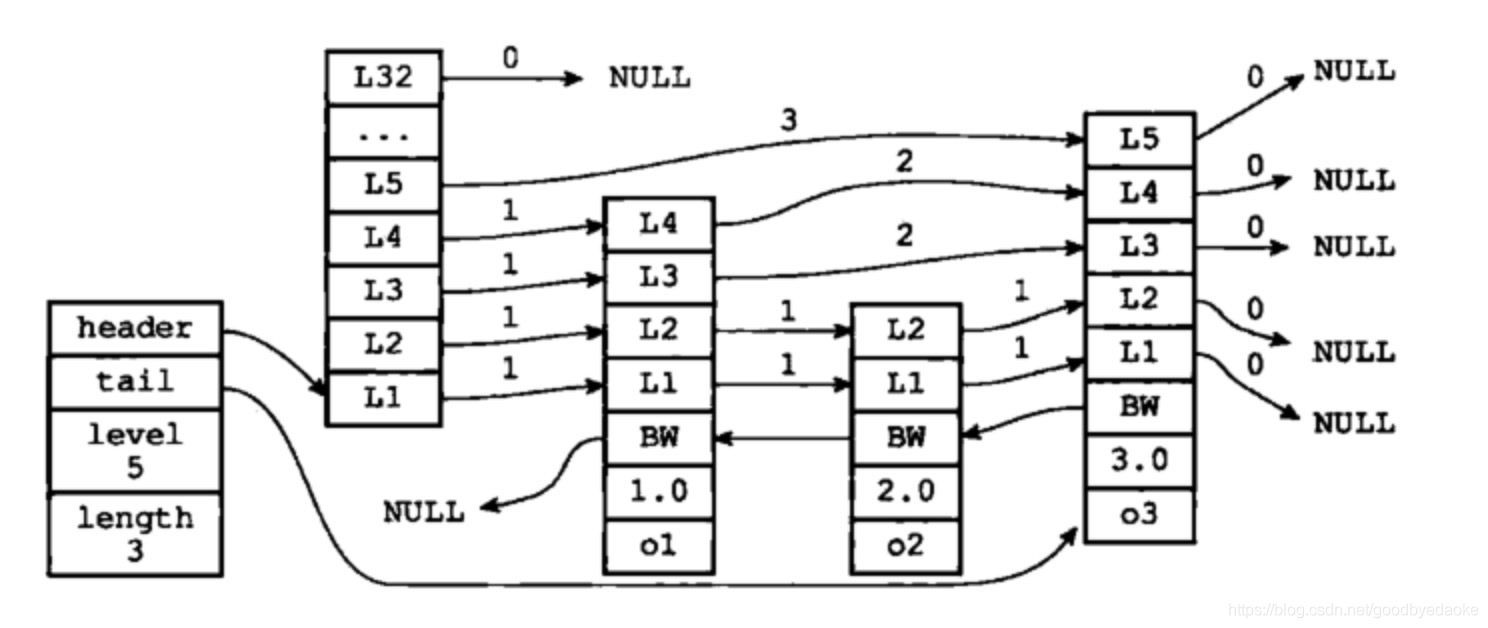
ziplist 壓縮表作為 list,hash,zset的底層結構

intset 整數集合作為set的底層結構之一

2,快取擊穿,穿透,雪崩
2.1,穿透:快取里沒有,資料庫里有,解決:資料的合法性、安全性進行校驗;布隆過濾器
擊穿:快取里沒有,資料庫里也沒有,解決:熱點Key永不失效;互斥鎖
雪崩:快取里的key大面積失效,解決:隨機過期時間;主動更新資料
3,快取過期策略
3.1 定時洗掉:redis每隔100ms隨機檢查是否有過期Key
3.2 惰性洗掉:在訪問到這個Key時檢查
3.3 淘汰機制:lru(最近最少使用)
noeviction:不足時報錯,無法寫入
allkeys-lru: 不足時,在所有Key中最近最少使用的洗掉
allkeys-ramdom:不足時,在所有Key中隨機洗掉
volatile-lru: 不足時,在過期Key中最近最少使用洗掉
volatile-ramdom:不足時,在過期Key中隨機洗掉
volatile-ttl:不足時,在過期Key中洗掉更早的
4,快取主從+哨兵
4.1,主從
概念:一般來講redis的服務器搭建分為主從,分布式,而哨兵單獨存在是沒有意義的
原理及實作:
1,先在從節點redis.conf中配置:slaveof 主資料庫ip 主資料庫port
先啟動主節點,再啟動從節點即可-------準備階段
2,從節點發送sync(psync)命令,主節點收到后無條件觸發RDB持久化并保存在此期間新的寫命令
3,當快照完成后,主節點將RDB檔案和命令一起發送給從節點
4,從節點會加載快照檔案和命令進行同步
核心機制:
1,offset 偏移量
2,backlog 1M用來做增量復制留存記錄頁
3,run id :主從都會寫
4,psync:同步命令
5,heatbeat機制:主節點10s一次,從節點1s一次
4.2,哨兵
作用:
1.監控主資料庫和從資料庫是否能夠正常運行
2.主資料庫出現故障時自動將從資料庫轉換為主資料庫,
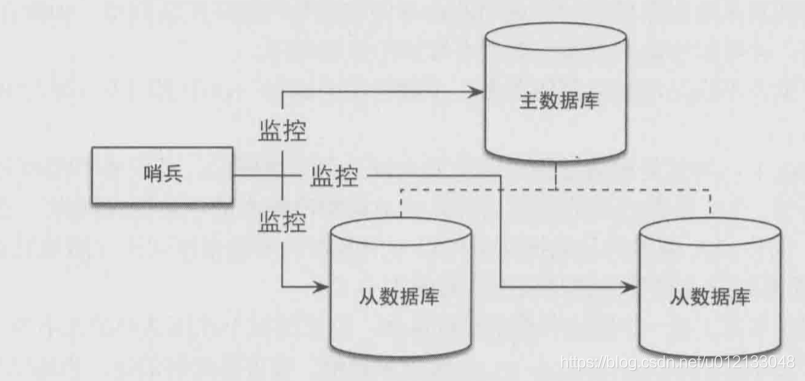
實作:由三個定時腳本
- 每隔10s向主資料庫和從資料庫發送info命令,檢查節點資訊
- 每隔2s向主資料里和從資料庫的_sentinel_:hello頻道發送自己的資訊,
- 每隔1s向所有資料庫節點和所有哨兵節點發送ping命令
選舉:兩個選舉,一個是對節點故障的選舉;另一個是哨兵自己本身的故障選舉,哨兵為奇數方便投票
主節點下線:
- 選出領頭哨兵
- 領頭哨兵從在線的從資料庫中,選擇優先級最高的從資料庫,優先級可以通過slave-priority選項設定,
- 如果優先級相同,則從復制的命令偏移量越大(即復同步資料越多,資料越新),越優先,
- 如果以上條件都一樣,則選擇run ID較小的從資料庫
哨兵自我選舉
- 發送主資料庫客觀下線的哨兵向每個哨兵命令,要求對方選擇自己為領頭,
- 如果沒有選擇過其他哨兵,則會同意請求
- 如果發現有超過半數,且超過quorum的哨兵同意自己的請求,則自己就是哨兵領頭,
4.3,分布式系統資料一致性
四,PHP&Go
五,資料結構
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/267503.html
標籤:其他
下一篇:Dubbo進階(十四)—— dubbo+zookeeper與提供者provider、消費者consumer通信原理講解