一、分布式和微服務架構的定義
分布式應用場景涵蓋的面非常廣,我理解的部分:
- 不同行程之間的互相通信,
- 不同主機的分布式物件之間呼叫,
- 用于大資料存盤的分布式檔案系統,
- 用于網路之間相互識別的命名服務,
- 集群中計算或存盤的無中心對等模型,
- 分布式事務,
- 資料副本在分布式環境中的復制,
- 云計算服務,
- 音視頻在網路中的點播和傳輸
- ....
微服務架構的目的是對原來過于大而重的云應用服務進行解耦,手段是進行比較合理的業務模塊拆解,拆解的粒度往往由架構師掌握,實作細粒度的服務,服務在云端形成分布式狀態,
那么微服務就具有了分布式的一些應用場景,比如:不同主機的分布式物件之間呼叫,以前EJB用RMI(遠程方法呼叫),現在微服務常用RPC(遠程程序呼叫);再比如:用于網路之間相互識別的命名服務,以前EJB是JNDI命名服務,現在SpringCloud的Euraka用于微服務的注冊和發現,也是分布式是命名服務,
如何通俗地理解「分布式系統」,它解決了哪些問題,有什么優缺點?
理解「分布式系統」曾經發生的事情
上面是我另外一個回答,里面比較詳細地描述了歷史上過去EJB和Spring的比較,也是分布式與單體應用的比較,那時候EJB代表分布式服務,而spring代表單體服務,
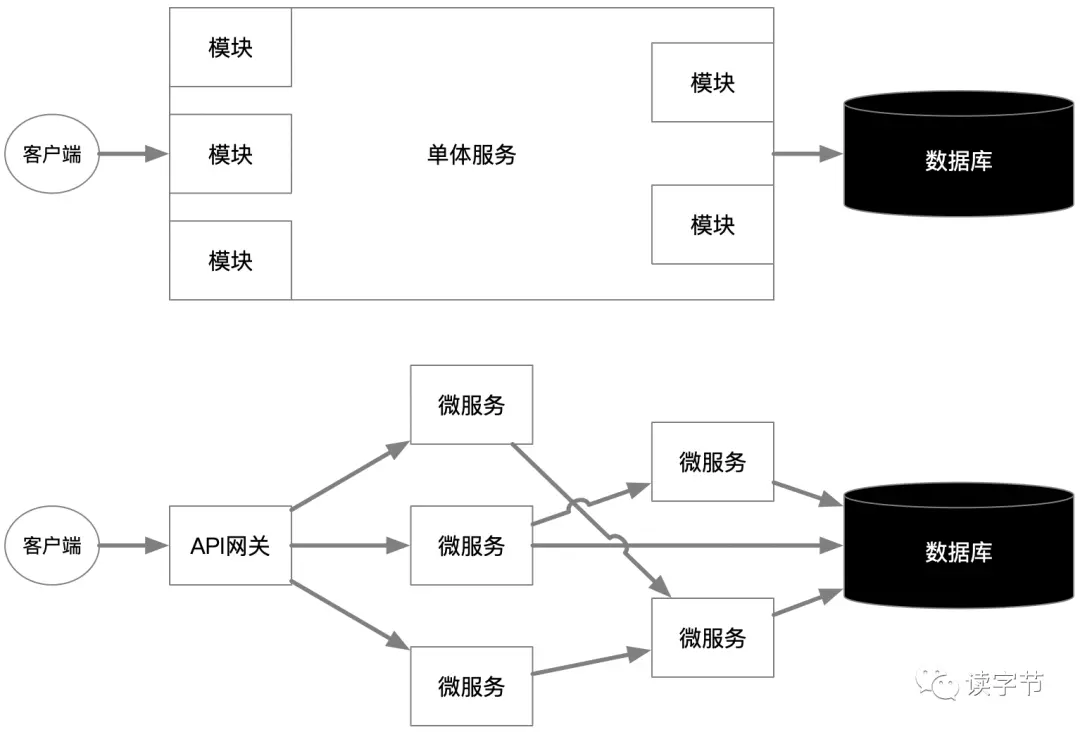
上面的圖簡單的描繪了一種最簡單的單體服務向微服務拆解的程序,當然微服務面臨的挑戰不僅僅這么簡單,這只是微服務的一種比較初始的狀態,
二、分布式和微服務這兩者解決了什么問題
分布式是計算、服務、存盤在網路中互相交流與協作的形式和狀態
分布式到底解決了什么?
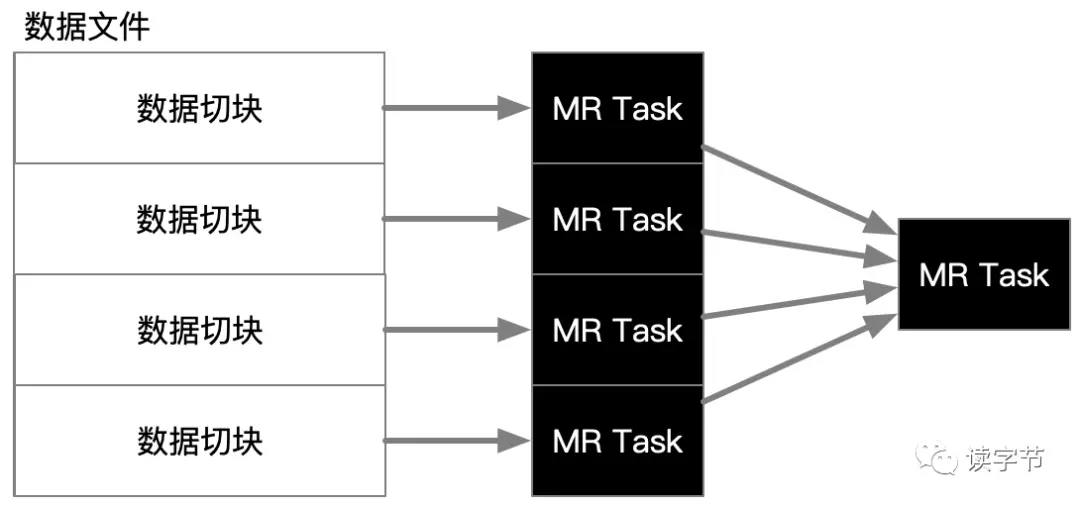
上圖就是典型的分布式計算,一個大檔案被切分成四份,MapReduce分成四個任務(行程),然后在同一主機不同行程,或不同主機上進行資料處理,最終再通過網路匯聚到一個合并任務,那么這個時候到分布式就是任務并行,解決了單任務的效率問題,
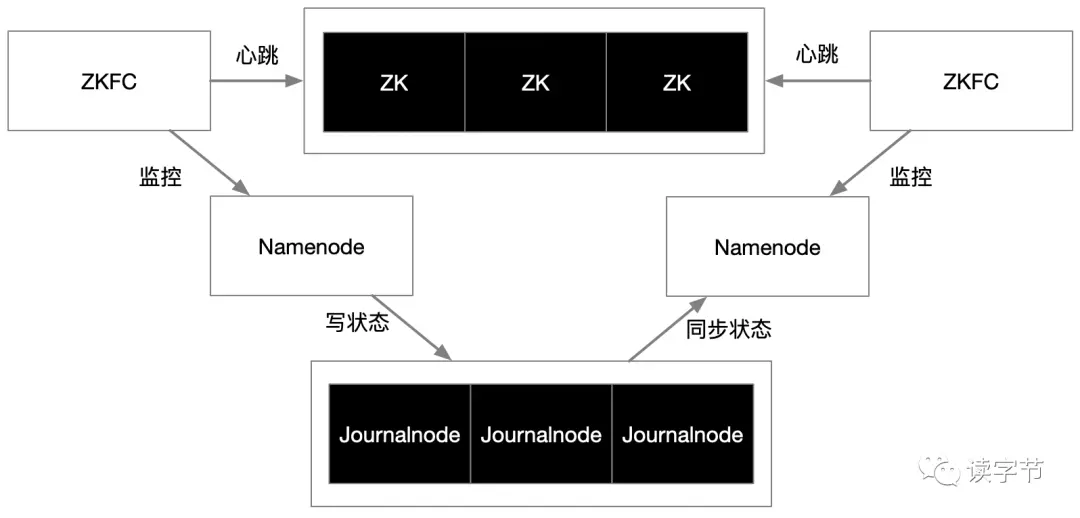
上圖是個典型的分布式狀態協調管理圖,是Hadoop HDFS集群的HA高可用架構,主副兩個Namonode節點,必須活著一個,當判斷主的掛了,必須讓副的頂上去,這個時候,三個ZK(zookeeper)組成的集群就是作為主副節點的協調者,通過ZKFC行程實作對Namoenode節點的心跳監控和切換命令下發,
另外三個Journalnode節點形成的集群又是namonode分布式狀態資料保存的地方,當主namonode掛了,所有的狀態必須快速的恢復到副namenode的上面,所以Journalnode必須持續同步狀態,滿足hdfs集群狀態的快速恢復
那么分布式中非常關鍵的一個應用場景——集群,上述的Hadoop hdfs集群,就需要有一個或幾個角色(zookeeper,Journalnode),作為集群狀態的協調者和管理者,有時候這種狀態管理是對等的(GlusterFS),有時候這種狀態管理是集中的(Hadoop就是這樣),
微服務又解決了什么問題呢?
如果這時候在提微服務的分布式優勢,就不是目的,而是手段了,微服務只是借助了分布式架構,達到了自己的目的,所以微服務不是基礎技術架構的問題,而是上層應用的架構問題,
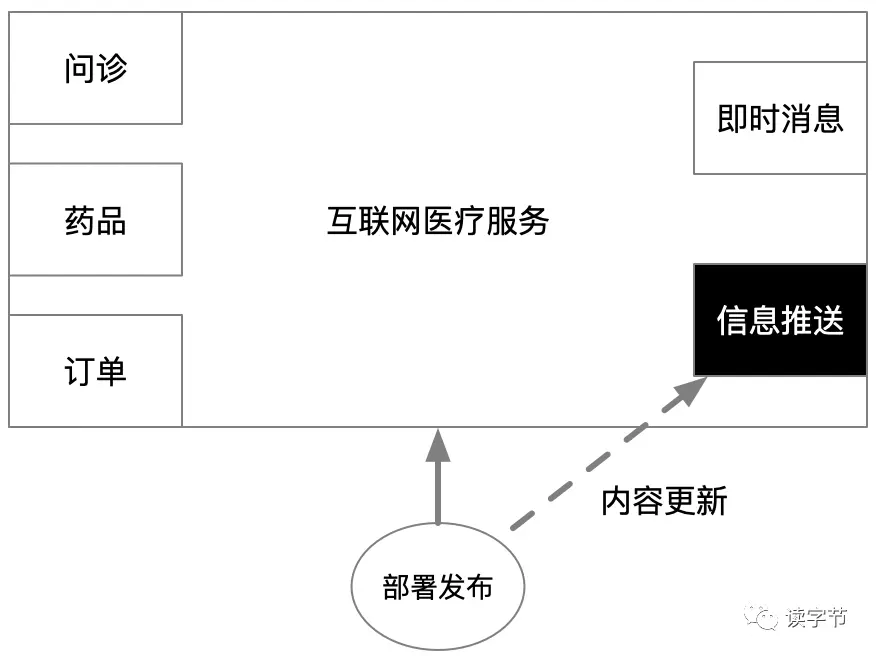
上面的例子是個簡單的互聯網醫療服務單體應用,這時候問診、藥品、訂單、即時訊息都是互聯網醫療最核心的業務,資訊推送目的是將互聯網醫療平臺的各類資訊進行互聯網資訊服務平臺的推送、發布和交流,達到自我推廣的目的,
可恰恰資訊推送服務的更新程度很高,因為需要對外連接的互聯網服務平臺情況復雜,也會有新的服務平臺納入到模塊范圍,那么作為單體應用就存在這樣一個部署問題,每次更新一個新的資訊推送功能,就要整體服務重新部署一次,那么這種影響對于核心服務就造成了很大的困擾,這時候的患者、醫生、醫院的業務影響都是大規模的,
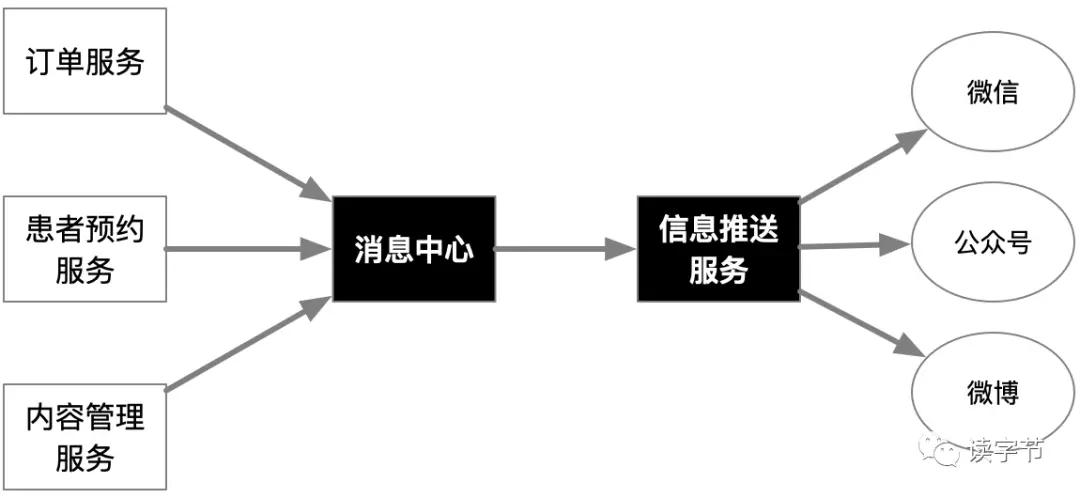
再看看微服務架構,如果將資訊推送服務作為單獨的微服務存在,其他微服務只是將需要推送到互聯網服務平臺的內容進行遠程呼叫即可,甚至用訊息中心的方式,打包成訊息,實作訊息事件驅動,讓對外發布服務的部署不會干預到其他核心服務,使得整體平臺因為部署發布而造成的影響降到最低,這種方式是不是看起來就舒服多了,非常利于部署、發布,甚至增強了整體系統的魯棒性,
當然微服務解決的問題還有很多,團隊分工的細粒度、迭代速度的提升、更易于小范圍重構,利于持續化集成(devops)等等,就不一一具體描述了,只把它很有特點的部分拿出來理解一下,
三、這些架構帶來的利弊
分布式對應的是就是單機,其優點上節描述了一些,就不贅述了,缺點也很大
部署不簡單,運維不簡單
網路瓶頸和故障會有重要的影響,
節點若失效,就要有察覺和熱替換機制,
一致性問題,例如分布式事務一直是世界性難題,
不僅要考慮均衡負載,更要考慮均衡負載的效果,
資料進行分布式存盤,在有些對等模式下還要考慮資料傾斜問題,
微服務除了分布式存盤缺點6之外,上述前5個缺點基本上都完美的繼承了,
四、利用不當所帶來的技術債務
說說微服務設計不當的麻煩問題吧
(1)微服務解耦后,會將一些業務程式從原來資料庫查詢的方式,轉變成遠程物件呼叫,這個程序我在原來的回答中提過,這是反人性的,形成復雜度和需要約定的介面都帶來了比SQL查詢更大的作業量,而且更反人性的方式就是資料庫也跟著微服務進行分庫,到底哪些資料需要冗余,哪些資料還能保持資料庫范式,基本都能把高程們煩死,
(2)經驗欠缺的微服務架構師,容易將微服務切得太細,假如一個單體若被切分成一千個微服務,而且微服務之間用到了遠程物件序列化和反序列化,那么這就成了死穴!因為一旦一個微服務的物體物件進行了調整,那么有多少個關聯的微服務被污染了,就要不斷定位其他微服務的依賴關系并重新發布,這種作業量已經超出了本該解決業務問題的作業量,
因此微服務的劃分一定要注意,而且RPC之間的物件傳遞盡量用簡單、松散的結構來做,微服務劃分的程度根據業務不同而粒度不同,有種約定是一個微服務進行大的重構,需要一周的時間,做為微服務粒度標準,
五、專案直接使用微服務架構, 是基于對未來的考慮?
微服務架構的考慮,不應該是對未來的考慮,而是對過去單體式應用出現問題后的一種架構重構,從第一節中的圖可以看到其重構程序,在互聯網醫療的例子中微服務的重構進一步趨向于訊息驅動、事件驅動,
從以往實施微服務的經驗教訓中,我總結出來的經驗,如果是新專案的架構師,可以先選擇單體應用,然后根據業務發展一點點迭代重構到微服務上來,即便程序中微服務的架構不那么純粹,甚至單體應用和微服務很長一段時間共存,也要慎重從新的專案上直接去設計微服務,
因為誰也不是算命先生,能估算到自己業務系統會在哪一天,哪個層面,哪個范圍就一定需要微服務化解耦,只有系統運行快到那個階段了,才能讓架構師更容易做到合理的微服務化決策,當然了,也有人會有疑惑,系統設計成單體,誰還有心思繼續重構微服務,不如直接做成微服務架構多省事,而我想說的是,若無重構之力行,切勿有微服務之念想,
六、K8s和Spring Cloud有什么區別和聯系?
Spring Cloud是貫徹微服務架構的一種具體實作框架,包括了springboot作為微服務的獨立運行容器,Euraka作為微服務的注冊和發現,zuul服務網關,其他的沒怎么用,就不提,其實網關我更喜歡用Openresty,
k8s只是容器的一種編排框架,管理者大量的docker容器,但是現在k8s又不集成docker了,暈得很!
docker作為微服務的容器,為每一個微服務都提供了單獨的網路、檔案系統、行程管理等基礎設施,這樣每個微服務的狀態、運行日志可以更好的被監控和管理,另外容器讓部署程序變得簡單,促進了現在流行的devops開發、發布、部署一體的管理模式,微服務的容器化其實是天生一對,
七、結尾
當我們理解清楚分布式下的各種場景是什么的一種存在形式的時候,當我們理解微服務又是一種什么分布式場景的時候,我們就更能清楚的去做好微服務的設計決策,
前往讀位元組的知乎——了解更多關于大資料的知識
公眾號 "讀位元組" 大資料(技術、架構、應用)的深度,專業解讀

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/270926.html
標籤:架構設計
上一篇:多執行緒
下一篇:Java資料持久層