分布式事務
- 一. 什么是分布式事務
- 二. 分布式事務理論
- 1. CAP 理論
- 2. CAP為什么不能同時滿足
- 3. CP,AP還是CA
- 3.1 舍棄A,保留CP
- 3.2. 舍棄C,保留AP
- 3.3 舍棄P,保留CA
- 4. BASE 理論
- 三. 分布式事務實作方式
- 1. 2PC(兩階段提交協議)
- 1.1 兩階段提交的基本思想
- 1.2 兩階段提交的基本流程
- 1.3 兩階段提交出現的問題
- 1.3.1 如果協調者掛了
- 1.3.2 如果協調者在發送準備命令之前掛了,事務未開始狀態
- 1.3.3 如果第一階段有參與者回傳失敗
- 1.3.4 如果第二階段提交失敗
- 1.3.5 如果協調者出現故障或者網路故障
- 1.3.6 如果協調者在第二階段發送提交請求之后掛掉
- 1.4 兩階段提交總結
- 2. 3PC(三階段提交協議)
- 2.1 三階段提交的三個階段:
- 2.1.1 詢問階段 CanCommit
- 2.1.2 準備階段 PreCommit
- 2.1.3 提交階段 DoCommit
- 2.2 解決二階段提交時的問題
- 2.3 三階段提交的問題
- 3. 最大努力通知
- 4. 補償事務TCC
- 4.1 TCC的三階段:
- 5. 本地訊息表+MQ
- 5.1 處理流程
- 5.2 一致性的容錯處理
- 5.3 總結
- 6. 基于 MQ 的最終一致性
- 6.1 原理
- 6.2 處理流程
- 6. 出現的問題
一. 什么是分布式事務
首先,事務指的是一系列資料庫操作,它是保證資料庫正確性的基本邏輯單元,擁有ACID四個特性:原子性、一致性、隔離性與持久性
- 原子性(Atomicity),可以理解為一個事務內的所有操作要么都執行成功,要么就不執行,不存在中間狀態,即一部分操作成功,一部分操作失敗的狀態
- 一致性(Consistency),可以理解為資料是滿足完整性約束的,也就是不會存在中間狀態的資料,比如你賬上有400,我賬上有100,你給我打200塊,此時你賬上的錢應該是200,我賬上的錢應該是300,不會存在我賬上錢加了,你賬上錢沒扣的中間狀態
- 隔離性(Isolation),指的是多個事務并發執行的時候不會互相干擾,即一個事務內部的資料對于其他事務來說是隔離的
- 持久性(Durability),指的是一個事務完成了之后資料就被永遠保存下來,之后的其他操作或故障都不會對事務的結果產生影響,
事務的定義
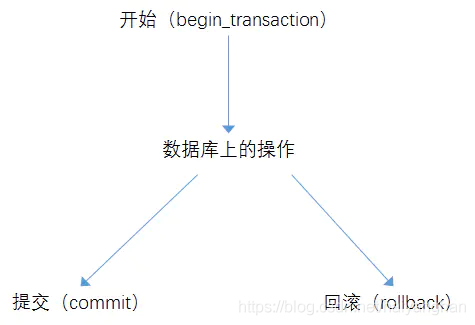
一個事務由開始標識(begin_transaction)、資料庫操作和結束標識(commit或rollback)三部分組成,如下圖所示:
-
事務開始:begin_transaction,說明事務的開始;
-
資料庫上的操作:表現為一潭訓多條SQL陳述句;
-
- 事務提交:commit_transaction,提交事務操作,操作生效;
- 事務回滾:rollback_transaction,事務取消,操作廢棄,
分布式事務就是一次操作由每個不同的事務組成,這些事務分布在不同的服務器上,且屬于不同的應用,分布式事務需要保證每個事務要么全部成功,要么全部失敗,本質上來說,分布式事務就是為了保證不同資料庫的資料一致性
二. 分布式事務理論
1. CAP 理論
CAP:Consistency Acailability Partition tolerance的縮寫
-
C (一致性)
一致性指的是多個資料副本是否能夠保持一致的特性,在一致性的條件下,系統在執行資料更新操作之后能夠從一致性狀態轉移到另一個一致性狀態
對系統的一個資料更新成功之后,如果所有用戶都能夠讀取到最新的值,該系統就被認為具有強一致性 -
A (可用性)
可用性指分布式系統在面對各種例外時可以提供正常的服務能力,可以用系統可用時間占總時間的比值來衡量,4 個 9 的可用性表示系統 99.99%的時間是可用的,
在可用性的條件下,要求系統提供的服務一直處于可用的狀態,對于用戶的每一個操作請求總是能夠在有限的時間內回傳結果 -
P (磁區容忍性)
網路磁區指分布式系統中的節點被劃分了多個區域,每個區域內部都可以通信,但是區域之間無法通信,
在磁區容忍性條件下,分布式系統在遇到任何網路磁區故障的時候,仍然需要能對外提供一致性的可用服務,除非整個網路都出現了故障
CAP理論認為:一個 分布式系統最多只能同時滿足,一致性,可用性,磁區容錯性的三項中的兩項,由于磁區容錯性是必然存在的,所以大部分分布式軟體系統都在CP和AP中做取舍,比如:
- Zookeeper 采用CP一致性,強調一致性,榷訓可用性,
- Eureka 采用AP可用性,強調可用性,榷訓一致性,
2. CAP為什么不能同時滿足
假設有兩臺服務器N1和N2,它們各自有一個應用程式AB和資料庫,兩臺服務器資料庫里面的資料是一樣的
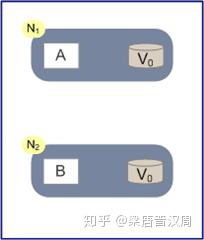
- 在滿足一致性的時候,N1和N2資料庫中的資料保持一致
- 在滿足可用性的時候,用戶不管是請求N1或者N2,都會得到立即回應
- 在滿足磁區容錯性的情況下,N1和N2有任何一方宕機,或者網路不通的時候,都不會影響N1和N2彼此之間的正常運作
問題來了:
假設某個時刻N1和N2之間的網路通信突然中斷了,如果系統滿足磁區容錯性,那么顯然可以支持這種例外,問題是在此前提下,一致性和可用性是否可以做到不受影響呢
如下圖,突然某一時刻N1和N2之間的關聯斷開:
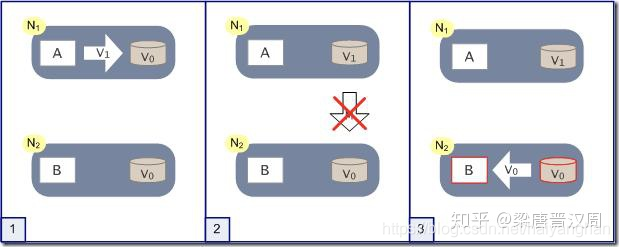
用戶向N1發送了請求更改了資料,將資料庫從V0更新成了V1,由于網路斷開,所以N2資料庫依然是V0,如果這個時候有一個請求發給了N2,但是N2并沒有辦法可以直接給出最新的結果V1,這個時候該怎么辦呢?
這個時候一致性 和 可用性就無法同時滿足,這里必須做出取舍:
- 第一種是滿足可用性,將錯就錯,將錯誤的V0資料回傳給用戶
- 第二種是滿足一致性,阻塞等待,等待網路通信恢復,N2中的資料更新之后再回傳給用戶
- 為了保證一致性(CP):就需要讓所有節點下線成為不可用狀態,等待同步完成,
- 為了保證可用性(AP):在同步程序中允許讀取所有節點的資料,但是資料可能不一致,
3. CP,AP還是CA
3.1 舍棄A,保留CP
一個系統保證了一致性和磁區容錯性,舍棄可用性,也就是說在極端情況下,允許出現系統無法訪問的情況出現,這個時候往往會犧牲用戶體驗,讓用戶保持等待,一直到系統資料一致了之后,再恢復服務
對于一些應用而言,一致性是必須要滿足的,比如Hbase、Redis這種分布式存盤,資料一致性是最基本的要求,不滿足一致性的存盤顯然不會有用戶愿意使用
ZooKeeper也是一樣,任何時候訪問ZK都可以獲得一致性的結果,它的職責就是保證管轄下的服務保持同步和一致,顯然不可能放棄一致性,但是在極端情況下,ZK可能會丟棄調一些請求,消費者需要重新請求才能獲得結果
3.2. 舍棄C,保留AP
這種是大部分的分布式系統的設計,舉個例子,我們在12306買票的時候就經常會遇到,在我們點擊購買的時候,系統并沒有提示沒票,等我們輸入了驗證碼,付款的時候才會告知,已經沒有票了,這就是因為我們在點擊購買的時候,資料沒有達成一致性,在付款校驗的時候才檢驗出余票不足,這種設計會犧牲一些用戶體驗,但是可以保證高可用,讓用戶不至于無法訪問或者是長時間等待,也算是一種取舍吧
3.3 舍棄P,保留CA
這種情況幾乎不存在,
首先,在分布式系統中,網路磁區是必然的,P(磁區容忍性)必不可少, 如果要舍棄P,那么就是要舍棄分布式系統,CAP也就無從談起了,可以說P是分布式系統的前提,因為需要總是假設網路是不可靠的,因此,CAP 理論實際上是要在一致性和可用性之間做權衡
4. BASE 理論
BASE理論是對CAP中CA,一致性和可用性進行一個權衡的結果,理論的核心思想就是:我們無法做到強一致,但每個應用都可以根據自身的業務特點,采用適當的方式來使系統達到最終一致性(Eventual consistency)
- Basically Available(基本可用) 不追求強可用性,而且強調系統基本能夠一直運行對外提供服務,當分布式系統遇到不可預估的故障時,允許一定程度上的不可用,比如:對請求進行限流排隊,使得部分用戶回應時間變長,或對非核心服務進行降級
- Soft state(軟狀態) 對于資料庫中事務的原子性:要么全部成功,要不全部不成功,軟狀態允許系統中的資料存在中間狀態
- Eventually consistent(最終一致性) 資料不可能一直都是軟狀態,必須在一個時間期限之后達到各個節點的一致性,在此之后,所有的節點的資料都是一致的,系統達到最終一致性
三. 分布式事務實作方式
1. 2PC(兩階段提交協議)
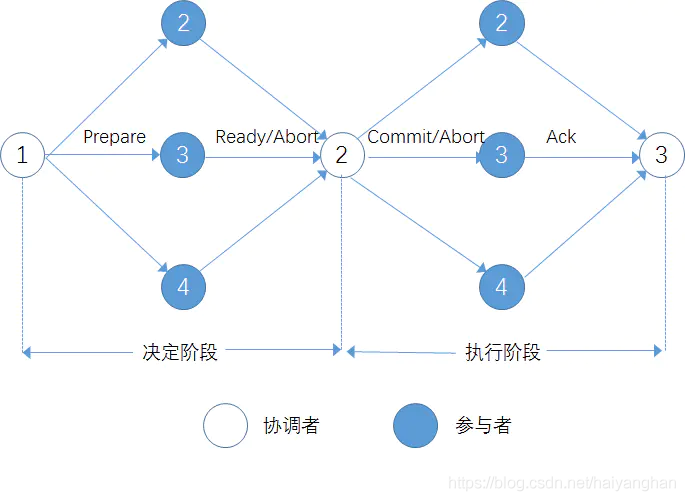
分布式事務在執行時會被分解為多個服務器或多個應用上的子事務來執行,為協調各個服務器(應用)上的子事務的執行,我們需要一個協調者,而各個子事務的具體執行,需要本地的參與者來完成,為進一步理解兩階段提交協議,我們先了解下協調者與參與者這兩個概念:
- 協調者:協調各個子事務的執行,負責決定所有子事務的提交或回滾;
- 參與者:負責各個子事務的提交與回滾,并向協調者提出子事務的提交或回滾意向
協調者與參與者的關系如下圖所示:
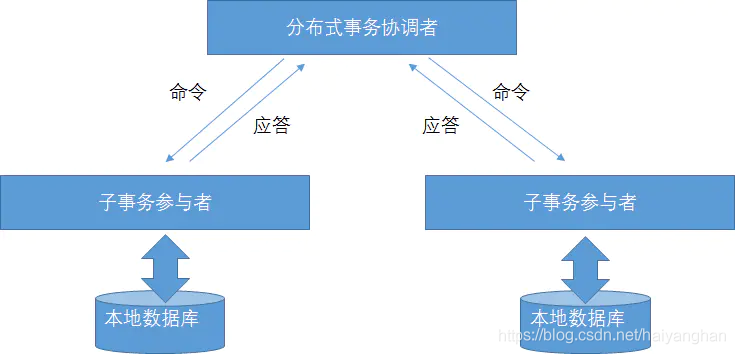
協調者和每個參與者均擁有一個本地日志檔案,用來記錄各自的執行程序,無論是協調者還是參與者,他們在進行操作前都必須將該操作記錄到相應的日志檔案中,以用來進行事務故障恢復,
協調者可以向各個參與者發送命令,使各個參與者在協調者的領導下執行命令,各個參與者也可以將自身的命令執行狀態以應答的形式反饋給協調者,由協調者收集并分析這些應答以決定下一步的操作
1.1 兩階段提交的基本思想
兩階段提交是為了實作分布式事務提交而采用的協議,
其基本思想是把全域事務的提交分為如下兩個階段:
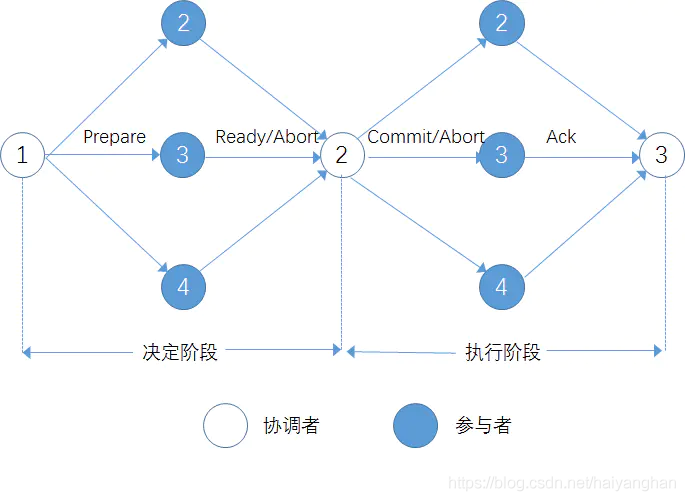
1.2 兩階段提交的基本流程
-
協調者在征求各參與者的意見之前,首先要在它的日志檔案中寫入一條“開始提交”(Begin_commit)的記錄,然后,協調者向所有參與者發送“預提交”(Prepare)命令,此時協調者進入等待狀態,等待收集各參與者的應答
-
各個參與者接收到“預提交”(Prepare)命令后,根據情況判斷其是否已經準備好提交子事務,若可以提交,則在參與者日志檔案中寫入一條“準備提交”(Ready)的記錄,并將“準備提交”(Ready)的應答發送給協調者,否則,在參與者的日志檔案中寫入一條“準備廢棄”(Abort)的記錄,并將“準備廢棄”(Abort)的應答發送給協調者,發送應答后,參與者將進入等待狀態,等待協調者所做出的最終決定
-
協調者收集各參與者發來的應答,判斷是否存在某個參與者發來“準備廢棄”的應答,若存在,則采取兩階段提交協議的“一票否決制”,在其日志檔案中寫入一條“決定廢棄”(Abort)的記錄,并發送“全域廢棄”(Abort)命令給各個參與者,否則,在其日志中寫入一條“決定提交”(Commit)的記錄,向所有參與者發送“全域提交”(Commit)命令,此時,協調者再次進入等待狀態,等待收集各參與者的確認資訊
-
各個參與者接收到協調者發來的命令后,判斷該命令型別,若為“全域提交”命令,則在其日志檔案中寫入一條“提交”(Commit)的記錄,并對子事務實施提交,否則,參與者在其日志檔案中寫入一條“廢棄”(Abort)的記錄,并對子事務實施廢棄,實施完畢后,各個參與者要向協調者發送確認資訊(Ack)
-
當協調者接收到所有參與者發送的確認資訊后,在其日志檔案中寫入“事務結束”(End_transaction)記錄,全域事務終止
基本流程圖:
1.3 兩階段提交出現的問題
1.3.1 如果協調者掛了
如果協調者故障,可以通過選舉得到新協調者
1.3.2 如果協調者在發送準備命令之前掛了,事務未開始狀態
如果處于第一階段,其實影響不大都回滾好了,在第一階段事務肯定還沒提交
1.3.3 如果第一階段有參與者回傳失敗
協調者就會向所有參與者發送回滾事務的請求,即分布式事務執行失敗
1.3.4 如果第二階段提交失敗
這里有兩種情況
- 第一種是第二階段執行的是回滾事務操作,那么答案是不斷重試,直到所有參與者都回滾了,不然那些在第一階段準備成功的參與者會一直阻塞著
- 第二種是第二階段執行的是提交事務操作,那么答案也是不斷重試,因為有可能一些參與者的事務已經提交成功了,這個時候只有一條路,就是頭鐵往前沖,不斷的重試,直到提交成功,到最后真的不行只能人工介入處理
1.3.5 如果協調者出現故障或者網路故障
如果協調者故障或者網路故障,導致參與者不能及時收到協調者發送的“提交”命令時,那么參與者將處于等待狀態,直到獲得所需要的資訊后才可以做出決定,在故障恢復前,參與者的行為將始終停留不前,子事務所占用的系統資源也不能被釋放,這時我們稱事務進入了阻塞狀態,阻塞狀態會降低系統的可靠性與可用性
1.3.6 如果協調者在第二階段發送提交請求之后掛掉
如果協調者在第二階段發送提交請求之后掛掉,而唯一接受到這條訊息的參與者執行之后也掛掉了,即使協調者通過選舉協議產生了新的協調者并通知其他參與者進行提交或回滾操作的話,都可能會與這個已經執行的參與者執行的操作不一樣,當這個掛掉的參與者恢復之后,就會產生資料不一致的問題
1.4 兩階段提交總結
兩階段提交優點:盡量保證了資料的強一致,但不是100%一致
兩階段提交的缺點:
- 單點故障,由于協調者的重要性,一旦協調者發生故障,參與者會一直阻塞,尤其時在第二階段,協調者發生故障,那么所有的參與者都處于鎖定事務資源的狀態中,而無法繼續完成事務操作
- 同步阻塞,由于所有節點在執行操作時都是同步阻塞的,當參與者占有公共資源時,其他第三方節點訪問公共資源不得不處于阻塞狀態
- 資料不一致,在第二階段中,當協調者想參與者發送提交事務請求之后,發生了區域網路例外或者在發送提交事務請求程序中協調者發生了故障,這會導致只有一部分參與者接收到了提交事務請求,而在這部分參與者接到提交事務請求之后就會執行提交事務操作,但是其他部分未接收到提交事務請求的參與者則無法提交事務,從而導致分布式系統中的資料不一致
2. 3PC(三階段提交協議)
三階段提交(Three-phase commit),三階段提交是為解決兩階段提交 的缺點而設計的,
三階段提交協議在一定程度上解決了兩階段提交協議中的同步阻塞問題,這是因為當協調者故障或是網路故障時,參與者長時間未收到協調者的命令,參與者可以通過啟動恢復處理程序,不必進入等待狀態而可以獨立的做出決定,三階段提交協議中協調者和參與者都引入了超時機制,然后把兩階段提交協議里的第一個階段拆分為兩步:先詢問(CanCommit),再鎖資源(PreCommit),再最后提交(DoCommit)
雖然三階段提交協議雖然可以在一定程度上解決兩階段提交協議中的阻塞問題,但因為流程邏輯復雜,代碼撰寫難度太高,也很難用于實際應用
2.1 三階段提交的三個階段:
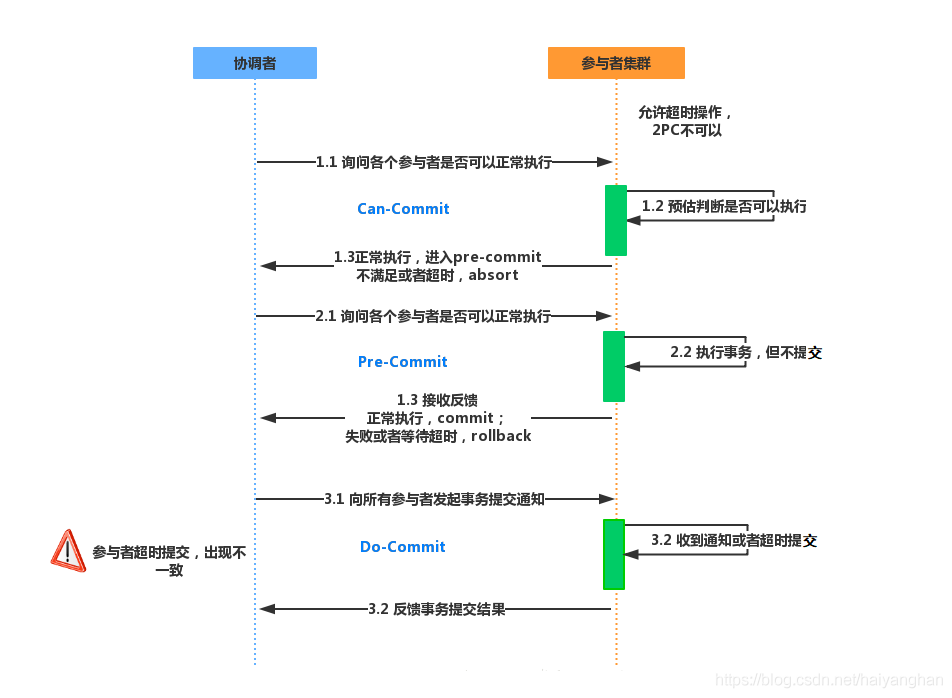
2.1.1 詢問階段 CanCommit
協調者向參與者發送commit請求,參與者如果可以提交就回傳Yes回應,否則回傳No回應,
2.1.2 準備階段 PreCommit
協調者根據參與者在詢問階段的回應判斷是否執行事務還是中斷事務:
- 如果所有參與者都回傳Yes,則執行事務
- 如果參與者有一個或多個參與者回傳No或者超時,則中斷事務
參與者執行完操作之后回傳ACK回應,同時開始等待最終指令
2.1.3 提交階段 DoCommit
協調者根據參與者在準備階段的回應判斷是否執行事務還是中斷事務:
- 如果所有參與者都回傳正確的ACK回應,則提交事務
- 如果參與者有一個或多個參與者收到錯誤的ACK回應或者超時,則中斷事務
- 如果參與者無法及時接收到來自協調者的提交或者中斷事務請求時,會在等待超時之后,會繼續進行事務提交
協調者收到所有參與者的ACK回應,完成事務
2.2 解決二階段提交時的問題
在三階段提交中,如果在第三階段協調者發送提交請求之后掛掉,并且唯一的接受的參與者執行提交操作之后也掛掉了,這時協調者通過選舉協議產生了新的協調者,在二階段提交時存在的問題就是新的協調者不確定已經執行過事務的參與者是執行的提交事務還是中斷事務,但是在三階段提交時,肯定得到了第二階段的再次確認,那么第二階段必然是已經正確的執行了事務操作,只等待提交事務了,所以新的協調者可以從第二階段中分析出應該執行的操作,進行提交或者中斷事務操作,這樣即使掛掉的參與者恢復過來,資料也是一致的
所以,三階段提交解決了二階段提交中存在的由于協調者和參與者同時掛掉可能導致的資料一致性問題和單點故障問題,并減少阻塞,因為一旦參與者無法及時收到來自協調者的資訊之后,他會默認執行提交事務,而不會一直持有事務資源并處于阻塞狀態
2.3 三階段提交的問題
在提交階段如果發送的是中斷事務請求,但是由于網路問題,導致部分參與者沒有接到請求,那么參與者會在等待超時之后執行提交事務操作,這樣這些由于網路問題導致提交事務的參與者的資料就與接受到中斷事務請求的參與者存在資料不一致的問題
所以無論是2PC還是3PC都不能保證分布式系統中的資料100%一致
3. 最大努力通知
最大努力通知主要用于對于事務的一致性不是特別敏感的事務,實作事務的弱一致性,適用于一些最終一致性要求較低的業務,比如支付通知,短信通知這種業務,可以通過訊息中間件實作,與前面異步確保型操作不同的一點是, 在訊息由MQ Server投遞到消費者之后, 允許在達到最大重試次數之后正常結束事務
基本流程:
- 主業務完成后,通過mq通知被動業務(允許訊息丟失)
- 通知失敗后主動方 按照一定的時間階梯進行訊息發送重試,直到超過最大重試次數為止
- 主動方提供業務查詢介面,以便被動方后續進行通知失敗后的補償,恢復丟失訊息
最大努力通知其實只是表明了一種柔性事務的思想:我已經盡力我最大的努力想達成事務的最終一致了
4. 補償事務TCC
TCC Try-Confirm-Cancel的簡稱,針對每個操作,都需要有一個其對應的確認和取消操作,當操作成功時呼叫確認操作,當操作失敗時呼叫取消操作,類似于二階段提交,只不過是這里的提交和回滾是針對業務上的,所以基于TCC實作的分布式事務也可以看做是對業務的一種補償機制
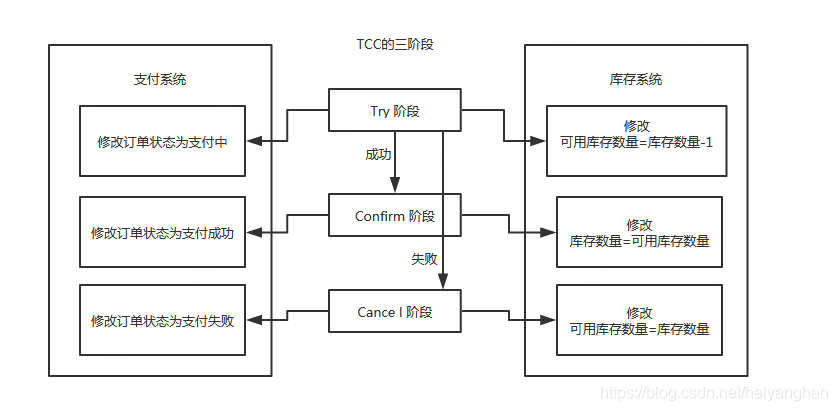
4.1 TCC的三階段:
- Try階段:對業務系統做檢測及資源預留
- Confirm階段:對業務系統做確認提交,Try階段執行成功并開始執行 Confirm階段時,默認Confirm階段是不會出錯的,即:只要Try成功,Confirm一定成功
- Cancel階段:在業務執行錯誤,需要回滾的狀態下執行的業務取消,預留資源釋放
比如訂單和存盤操作,需要檢查庫存剩余數量是否夠用,并進行預留,預留操作的話就是新建一個可用庫存數量欄位,Try階段操作是對這個可用庫存數量進行操作
執行流程:
- Try階段:訂單系統將當前訂單狀態設定為支付中,庫存系統校驗當前剩余庫存數量是否大于1,然后將可用庫存數量設定為庫存剩余數量-1,
- 如果Try階段執行成功,執行Confirm階段,將訂單狀態修改為支付成功,庫存剩余數量修改為可用庫存數量
- 如果Try階段執行失敗,執行Cancel階段,將訂單狀態修改為支付失敗,可用庫存數量修改為庫存剩余數量
5. 本地訊息表+MQ
本地訊息表方案最初是ebay提出的,其實也是BASE理論的應用,屬于可靠訊息最終一致性的范疇,其基本的設計思想是將遠程分布式事務拆分成一系列的本地事務,如果不考慮性能及設計優雅,借助關系型資料庫中的表即可實作,
方案通過在事務主動發起方額外新建事務訊息表,事務發起方處理業務和記錄事務訊息在本地事務中完成,輪詢事務訊息表的資料發送事務訊息,事務被動方基于訊息中間件消費事務訊息表中的事務,這樣設計可以避免”業務處理成功 + 事務訊息發送失敗",或"業務處理失敗 + 事務訊息發送成功"的棘手情況出現,保證 2 個系統事務的資料一致性
5.1 處理流程
下面把分布式事務最先開始處理的事務方稱為事務主動方,在事務主動方之后處理的業務內的其他事務稱為事務被動方
為了方便理解,下面繼續以 電商下單為例進行方案決議,這里把整個程序簡單分為扣減庫存,訂單創建 2 個步驟,庫存服務和訂單服務分別在不同的服務器節點上,其中庫存服務是事務主動方,訂單服務是事務被動方
事務的主動方需要額外新建事務訊息表,用于記錄分布式事務的訊息的發生、處理狀態
整個業務處理流程如下:
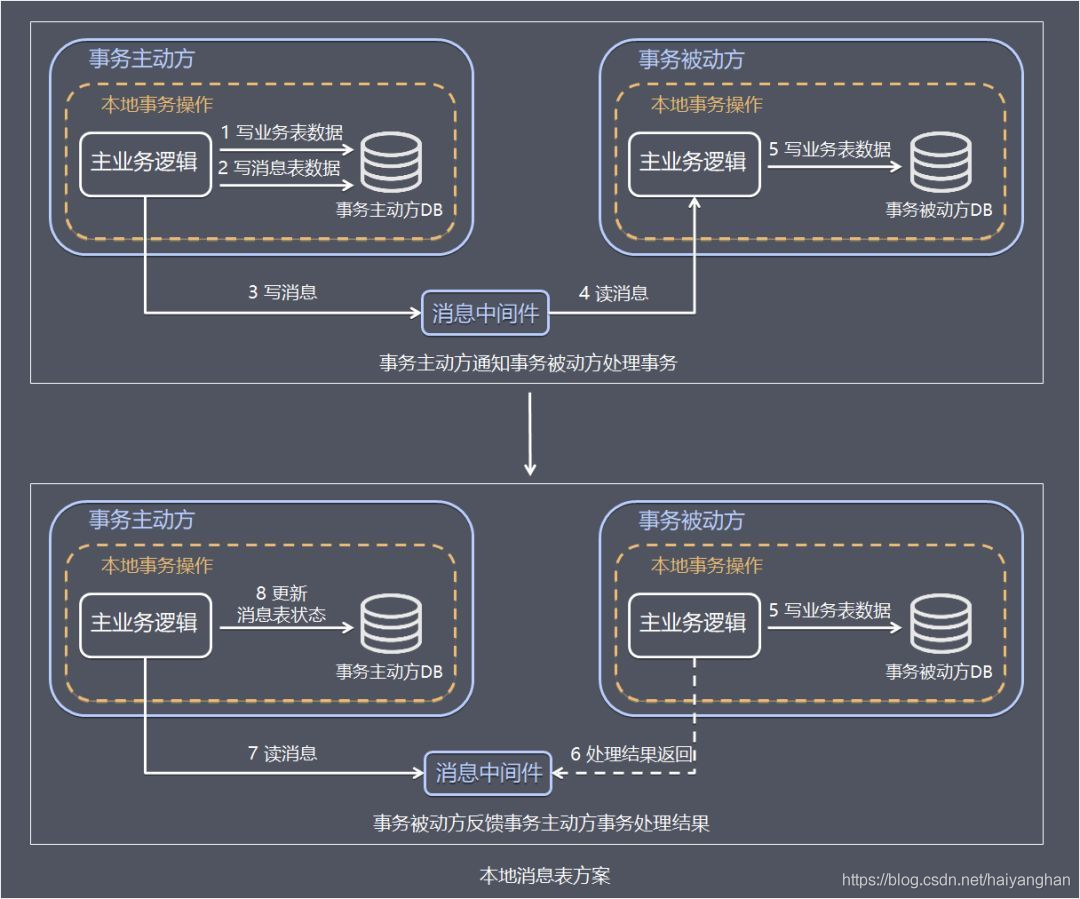
- 事務主動方處理本地事務
事務主動方在本地事務中處理業務更新操作和寫訊息表操作,上面例子中庫存服務階段在本地事務中完成扣減庫存和寫訊息表(圖中 1、2) - 事務主動方通過訊息中間件,通知事務被動方處理事務通知事務待訊息
訊息中間件可以基于 Kafka、RocketMQ 訊息佇列,事務主動方主動寫訊息到訊息佇列,事務消費方消費并處理訊息佇列中的訊息
前兩步,庫存服務把事務待處理訊息寫到訊息中間件,訂單服務消費訊息中間件的訊息,完成新增訂單(圖中 3 - 5)
- 事務被動方通過訊息中間件,通知事務主動方事務已處理的訊息
訂單服務把事務已處理訊息寫到訊息中間件,庫存服務消費中間件的訊息,并將事務訊息的狀態更新為已完成(圖中 6 - 8)
為了資料的一致性,當處理錯誤需要重試,事務發送方和事務接收方相關業務處理需要支持冪等
5.2 一致性的容錯處理
- 當步驟 1 處理出錯,事務回滾,相當于什么都沒發生,
- 當步驟 2、步驟 3 處理出錯,由于未處理的事務訊息還是保存在事務發送方,事務發送方可以定時輪詢為超時訊息資料,再次發送到訊息中間件進行處理,事務被動方消費事務訊息重試處理,
- 如果是業務上的失敗,事務被動方可以發訊息給事務主動方進行回滾,
- 如果多個事務被動方已經消費訊息,事務主動方需要回滾事務時需要通知事務被動方回滾,
5.3 總結
優點:
- 從應用設計開發的角度實作了訊息資料的可靠性,訊息資料的可靠性不依賴于訊息中間件,榷訓了對 MQ 中間件特性的依賴
- 方案輕量,容易實作
缺點:
- 與具體的業務場景系結,耦合性強,不可公用,
- 訊息資料與業務資料同庫,占用業務系統資源,
- 業務系統在使用關系型資料庫的情況下,訊息服務性能會受到關系型資料庫并發性能的局限
6. 基于 MQ 的最終一致性
利用訊息中間件來異步完成事務的后一半更新,實作系統的最終一致性,它采用的不是強一致性,而是最終一致性,這也就是 BASE 理論,并且我們直到 MQ 是異步的,所以性能也比較快,可以說完美的解決了上面兩種方式帶來的問題
主要是基于 MQ 訊息投遞的可靠性,將分布式事務發送給 MQ 中間件之后,中間件將事務持久化,這一點非常重要,保證訊息不丟失,消費者端異步消費,如果遇到失敗情況,由于我們的訊息是持久化的,所以可以根據業務規則不斷重試,有必要的話,人工補償,保證資料最終一致性
6.1 原理
- MQ的確認機制 確保生產者一定將增加積分的訊息投遞到MQ中
- 手動ack應答形式 確保消費者消費訊息一定成功,如果沒有例外情況下通知MQ洗掉該訊息,否則情況下不斷重試消費 (需要保證冪等性問題)
- 補償佇列 如果MQ異步代碼執行之后,代碼出現例外的情況下,可以保證分布式事務問題
6.2 處理流程
以轉賬業務為例,有兩步操作,一個是操作用戶A扣錢,一個是操作用戶B加錢
- A 扣款成功后,發送“扣款成功訊息”到訊息中間件
- 加錢業務訂閱“扣款成功訊息”,再對用戶B加錢
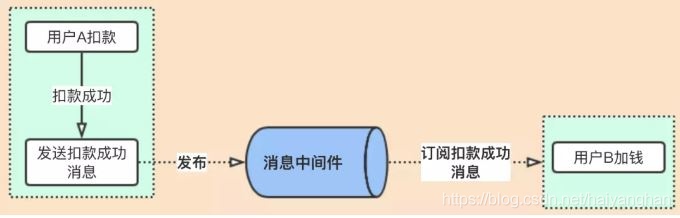
如何用戶A扣款失敗,可加錢業務訂閱到了訊息,用戶B加了錢的場景?
基于RocketMQ事務方案
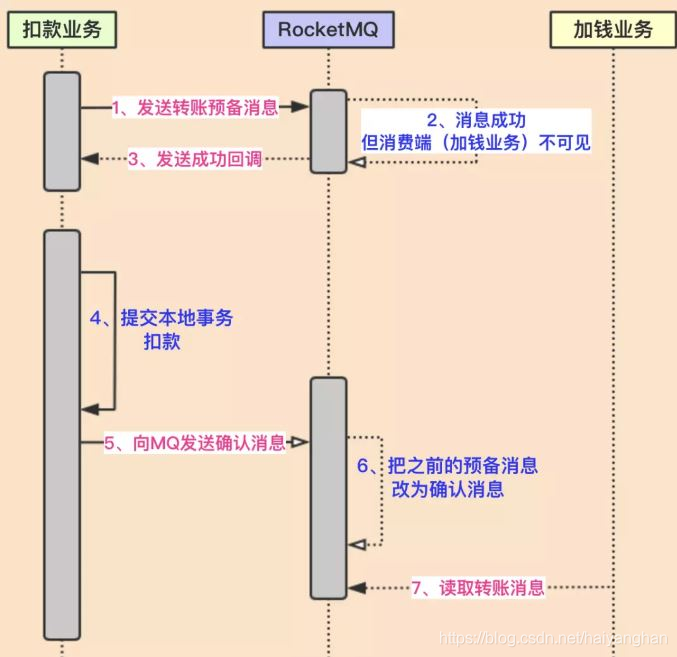
因為上面的問題,RocketMq訊息中間件把訊息分為兩個階段:
- Prepared階段(預備階段) 該階段主要發一個訊息到rocketmq,但該訊息只儲存在commitlog中,但consumeQueue中不可見,也就是消費端(訂閱端)無法看到此訊息
- Commit/rollback階段(確認階段) 該階段主要是把prepared訊息保存到consumeQueue中,即讓消費端可以看到此訊息,也就是可以消費此訊息
整個流程:
- 在扣款之前,先發送預備訊息
- 發送預備訊息成功后,執行本地扣款事務
- 扣款成功后,再發送確認訊息
- 訊息端(加錢業務)可以看到確認訊息,消費此訊息,進行加錢
確認訊息說明
注意:上面的確認訊息可以為commit訊息,可以被訂閱者消費;也可以是Rollback訊息,即執行本地扣款事務失敗后,提交rollback訊息,即洗掉那個預備訊息,訂閱者無法消費
6. 出現的問題
- 問題1:如果發送預備訊息失敗,下面的流程不會走下去;這個是正常的
- 問題2:如果發送預備訊息成功,但執行本地事務失敗;這個也沒有問題,因為此預備訊息不會被消費端訂閱到,消費端不會執行業務,
- 問題3:如果發送預備訊息成功,執行本地事務成功,但發送確認訊息失敗;這個就有問題了,因為用戶A扣款成功了,但加錢業務沒有訂閱到確認訊息,無法加錢,這里出現了資料不一致,
那RocketMq是怎么解決的呢?
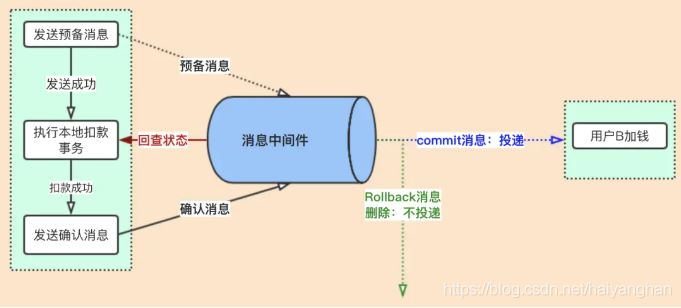
RocketMQ回查
RocketMq如何解決上面的問題,核心思路就是【狀態回查】,也就是RocketMq會定時遍歷commitlog中的預備訊息,因為預備訊息最終肯定會變為commit訊息或Rollback訊息,所以遍歷預備訊息去回查本地業務的執行狀態,如果發現本地業務沒有執行成功就rollBack,如果執行成功就發送commit訊息
問題3解決方案:發送預備訊息成功,本地扣款事務成功,但發送確認訊息失敗;因為RocketMq會進行回查預備訊息,在回查后發現業務已經扣款成功了,就補發“發送commit確認訊息”;這樣加錢業務就可以訂閱此訊息了,這個思路其實把問題2也解決了,因為本地事務沒有執行成功,RocketMQ回查業務,發現沒有執行成功,就會發送RollBack確認訊息,把訊息進行洗掉,
回查判斷業務是否成功
在回查業務中,如何判斷本地事務是否執行成功?其實這個跟具體的業務場景有關,比如訂單的話,我們可以查詢訂單表中是否有記錄,有記錄則表明成功,如果本地事務執行了很多張表,那是不是我們要把那些表都要進行判斷是否執行成功呢?這樣是不是太麻煩了,而且和業務很耦合,
有沒有更好的方式呢? 就是設計一張Transaction表,將業務表和Transaction系結在同一個本地事務中,如果扣款本地事務成功時,Transaction中應當已經記錄該TransactionId的狀態為「已完成」,當RocketMq回查時,只需要檢查對應的TransactionId的狀態是否是「已完成」就好,而不用關心具體的業務資料,這就是上面的第五條 本地訊息表+MQ
如果消費端消費失敗了怎么辦?
如果有訊息消費失敗了,則將失敗的訊息回傳給broker,即重新寫入commitLog檔案,消費者將重新消費;如果訊息回傳的時候,consumer和broker之間網路斷開,則consumer會呼叫submitConsumeRequestLater()方法,在consumer端進行重新消費,如果仍然消費失敗,會不斷重試直到達到默認的16次,你可以使用msg.getReconsumeTimes()方法來獲取當前重試次數,如果重試次數足夠多之后仍然無法消費成功,必須通過工單、日志等方式進行人工干預以讓producer事務進行回退處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271305.html
標籤:其他
上一篇:一長路漫漫.編程C語言啟航..