目錄
- 第一章 圖
- 1.1、圖的定義
- 1.2、特殊的圖
- 1.3、圖的結構
- 1.4、圖的分類
- 第二章 無向圖
- 2.1、無向圖的術語
- 2.2、無向圖的實作
- 2.3、無向圖的搜索
- 2.3.1、深度優先搜索連通數量
- 2.3.2、廣度優先搜索連通數量
- 2.4、無向圖的路徑
- 2.4.1、深度優先搜索有效路徑
- 2.4.2、廣度優先搜索最短路徑
- 2.5、無向環的判斷
- 第三章 有向圖
- 3.1、有向圖的術語
- 3.2、有向圖的實作
- 3.3、有向圖的搜索
- 3.3.1、深度優先搜索連通數量
- 3.3.2、廣度優先搜索連通數量
- 3.4、有向圖的路徑
- 3.4.1、深度優先搜索有效路徑
- 3.4.2、廣度優先搜索最短路徑
- 3.5、有向環的判斷
- 第四章 拓撲排序
- 4.1、頂點排序
- 4.2、拓撲排序
- 第五章 加權無向圖
- 5.1、加權無向邊的實作
- 5.2、加權無向圖的實作
- 第六章 最小生成樹
- 6.1、最小生成樹的定義
- 6.2、最小生成樹的約定
- 6.3、切分定理
- 6.4、Prim演算法
- 6.4.1、演算法介紹
- 6.4.2、演算法原理
- 6.4.3、演算法實作
- 6.5、Kruskal演算法
- 6.5.1、演算法介紹
- 6.5.2、演算法原理
- 6.5.3、演算法實作
- 第七章 加權有向圖
- 7.1、加權有向邊的實作
- 7.2、加權有向圖的實作
- 第八章 最短路徑樹
- 8.1、最短路徑樹的定義
- 8.2、最短路徑樹的約定
- 8.3、松弛技術
- 8.4、Dijstra演算法
- 8.4.1、演算法介紹
- 8.4.2、演算法原理
- 8.4.3、演算法實作
專案地址:https://gitee.com/caochenlei/data-structures
第一章 圖
1.1、圖的定義
定義:圖是由一組頂點和一組能夠將兩個頂點相連的邊組成的,
1.2、特殊的圖
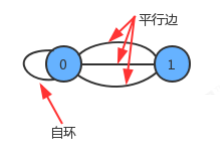
- 自環:即一條連接一個頂點和其自身的邊,
- 平行邊:連接同一對頂點的兩條邊,
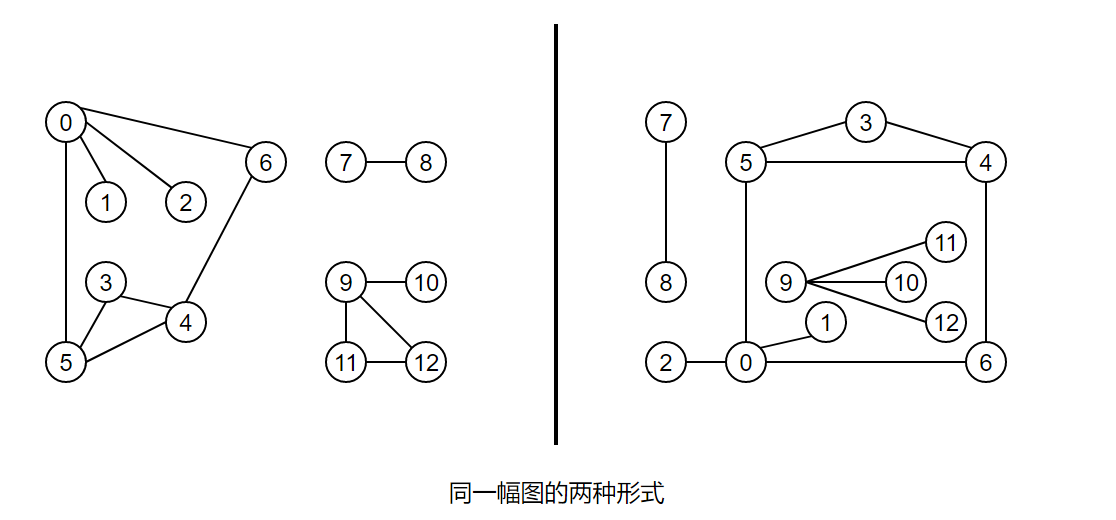
1.3、圖的結構
要表示一幅圖,只需要表示清楚以下兩部分內容即可:
- 圖中所有的頂點,
- 所有連接頂點的邊,
常見的圖的存盤結構有兩種:鄰接矩陣和鄰接表,
鄰接矩陣:
- 使用一個大小為
V*V的二維陣列int[V][V] adj,把索引的值看做是各個頂點, - 如果頂點
v和頂點w相連,我們只需要將adj[v][w]和adj[w][v]的值設定為1,否則設定為0,
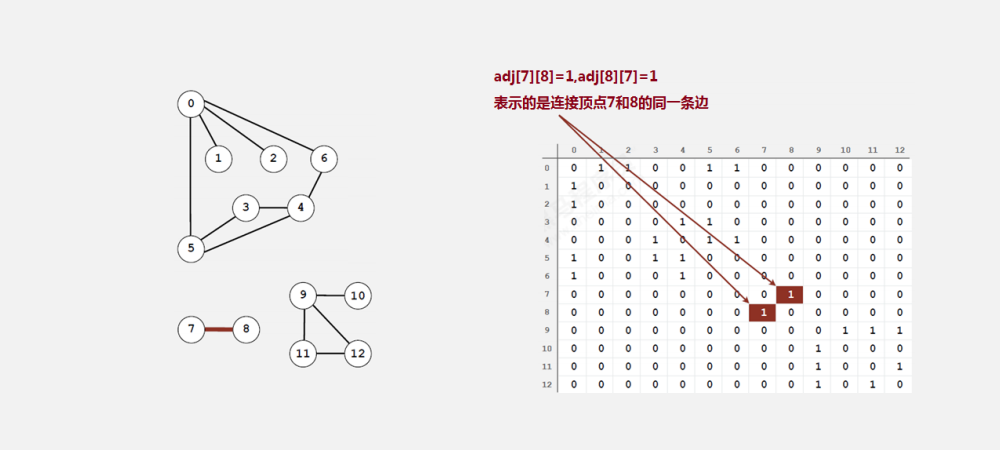
很明顯,鄰接矩陣這種存盤方式的空間復雜度是V2的,如果我們處理的問題規模比較大的話,記憶體空間極有可能 不夠用,
鄰接表:
- 使用一個大小為
V的一維陣列Queue[V] adj,把索引的值看做是各個頂點, - 每個索引處
adj[v]存盤了一個佇列,該佇列中存盤的是所有與該頂點相鄰的其他頂點,
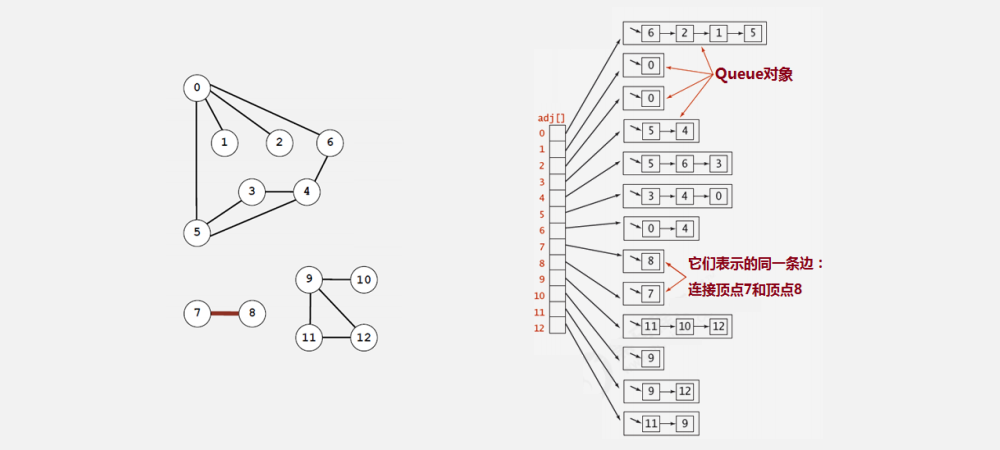
很明顯,鄰接表的空間并不是是線性級別的,所以后面我們一直采用鄰接表這種存盤形式來表示圖,
1.4、圖的分類
按照連接兩個頂點的邊的不同,可以把圖分為以下兩種:
- 無向圖:邊僅僅連接兩個頂點,沒有其他含義,
- 有向圖:邊不僅連接兩個頂點,并且具有方向,
第二章 無向圖
2.1、無向圖的術語
相鄰頂點:當兩個頂點(vertex)通過一條邊(edge)相連時,我們稱這兩個頂點是相鄰的,并且稱這條邊依附于這兩個頂點,
度:某個頂點的度就是依附于該頂點的邊的個數,
子圖:是一幅圖的所有邊的子集(包含這些邊依附的頂點)組成的圖,
路徑:是由邊順序連接的一系列的頂點組成,
環:是一條至少含有一條邊且終點和起點相同的路徑,
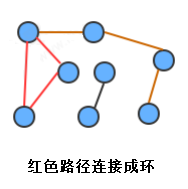
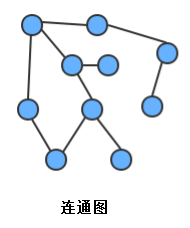
連通圖:如果圖中任意一個頂點都存在一條路徑到達另外一個頂點,那么這幅圖就稱之為連通圖,
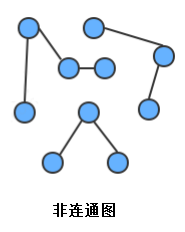
連通子圖:一個非連通圖由若干連通的部分組成,每一個連通的部分都可以稱為該圖的連通子圖,
2.2、無向圖的實作
【圖的結構】
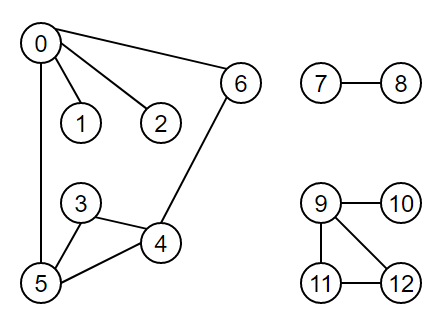
【圖的實作】
約定: N代表頂點數目,則N的取值范圍只能是0 ~ N-1,比如:N=3,則這三個頂點分別為:頂點0、頂點1、頂點2,如用其他值可能會造成adj下標越界,
public class Graph {
private int N; //表示頂點數目
private int E; //表示邊的數目
private Queue<Integer>[] adj; //表示鄰接表
public Graph(int n) {
this.N = n; //初始化頂點數目
this.E = 0; //初始化邊的數目
this.adj = new LinkedList[n]; //初始化鄰接表
for (int i = 0; i < adj.length; i++) {
adj[i] = new LinkedList<>();
}
}
//獲取頂點數目
public int size() {
return N;
}
//獲取邊的數目
public int edge() {
return E;
}
//添加一條邊
public void addEdge(int v, int w) {
adj[v].add(w); //在v的鏈表中添加w
adj[w].add(v); //在w的鏈表中添加v
E++; //圖的邊數加一
}
//洗掉一條邊
public void removeEdge(int v, int w) {
adj[v].remove(w); //在v的鏈表中洗掉w
adj[w].remove(v); //在w的鏈表中洗掉v
E--; //圖的邊數減一
}
//獲取v的鄰點
public Queue<Integer> adj(int v) {
return adj[v];
}
//獲取v的度數
public int degree(int v) {
int degree = 0;
for (Integer w : adj(v)) {
degree++;
}
return degree;
}
//獲取所有頂點的最大度數
public int maxDegree() {
int maxDegree = 0;
int curDegree;
for (int v = 0; v < N; v++) {
curDegree = degree(v);
if (curDegree > maxDegree) {
maxDegree = curDegree;
}
}
return maxDegree;
}
//獲取所有頂點的平均度數
public double avgDegree() {
return 2.0 * E / N;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(N + " vertices, ");
sb.append(E + " edges\n");
for (int v = 0; v < N; v++) {
sb.append(v + ": ");
for (Integer w : adj(v)) {
sb.append(w + " ");
}
sb.append("\n");
}
return sb.toString();
}
}
【代碼測驗】
public class GraphTest {
public static void main(String[] args) {
Graph G = new Graph(13);
G.addEdge(0, 5);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(0, 6);
G.addEdge(5, 3);
G.addEdge(5, 4);
G.addEdge(3, 4);
G.addEdge(4, 6);
G.addEdge(7, 8);
G.addEdge(9, 11);
G.addEdge(9, 12);
G.addEdge(9, 10);
G.addEdge(11, 12);
System.out.println("獲取G的大小:" + G.size());
System.out.println("獲取G的邊數:" + G.edge());
System.out.println("====================");
for (int v = 0; v < G.size(); v++) {
System.out.println("獲取" + v + "的鄰點:" + G.adj(v));
}
System.out.println("====================");
for (int v = 0; v < G.size(); v++) {
System.out.println("獲取" + v + "的度數:" + G.degree(v));
}
System.out.println("====================");
System.out.println("獲取所有頂點的最大度數:" + G.maxDegree());
System.out.println("獲取所有頂點的平均度數:" + G.avgDegree());
System.out.println("====================");
System.out.println(G);
}
}
【運行效果】
獲取G的大小:13
獲取G的邊數:13
====================
獲取0的鄰點:[5, 1, 2, 6]
獲取1的鄰點:[0]
獲取2的鄰點:[0]
獲取3的鄰點:[5, 4]
獲取4的鄰點:[5, 3, 6]
獲取5的鄰點:[0, 3, 4]
獲取6的鄰點:[0, 4]
獲取7的鄰點:[8]
獲取8的鄰點:[7]
獲取9的鄰點:[11, 12, 10]
獲取10的鄰點:[9]
獲取11的鄰點:[9, 12]
獲取12的鄰點:[9, 11]
====================
獲取0的度數:4
獲取1的度數:1
獲取2的度數:1
獲取3的度數:2
獲取4的度數:3
獲取5的度數:3
獲取6的度數:2
獲取7的度數:1
獲取8的度數:1
獲取9的度數:3
獲取10的度數:1
獲取11的度數:2
獲取12的度數:2
====================
獲取所有頂點的最大度數:4
獲取所有頂點的平均度數:2.0
====================
13 vertices, 13 edges
0: 5 1 2 6
1: 0
2: 0
3: 5 4
4: 5 3 6
5: 0 3 4
6: 0 4
7: 8
8: 7
9: 11 12 10
10: 9
11: 9 12
12: 9 11
2.3、無向圖的搜索
2.3.1、深度優先搜索連通數量
【圖的結構】
在很多情況下,我們需要遍歷圖,得到圖的一些性質,例如,找出圖中與指定的頂點相連的所有頂點,或者判定某個頂點與指定頂點是否相通,是非常常見的需求,有關圖的搜索,最經典的演算法有深度優先搜索和廣度優先搜索,接下來我們講解深度優先搜索演算法,
以下圖是查找和頂點0相通的所有頂點,紅色部分只是一次遍歷結果,不是全部,但是可以以小見大,
ps:下圖每個鏈表中的資料可能和上邊測驗的資料順序不太一樣,請不要在意,都是對的,這取決于你添加邊的順序,
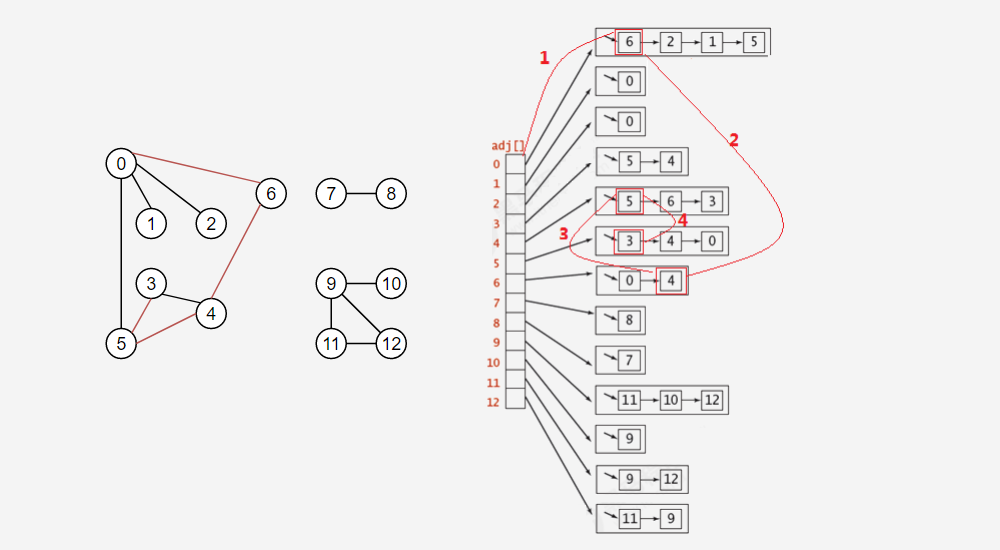
【實作代碼】
public class DepthFirstSearch {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private int count; //記錄有多少個頂點與頂點s相通
public DepthFirstSearch(Graph G, int s) { //構造深度優先搜索物件
this.marked = new boolean[G.size()]; //初始化marked陣列
this.count = 0; //初始化跟頂點s相通的頂點的數量
dfs(G, s); //使用深度優先搜索找出G圖中頂點s的所有相鄰頂點
}
private void dfs(Graph G, int v) { //使用深度優先搜索找出G圖中頂點v的所有相通頂點
marked[v] = true; //把頂點v標識為已搜索
for (Integer w : G.adj(v)) {
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
dfs(G, w); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
count++;
}
//判斷w頂點與頂點s是否相通
public boolean marked(int w) {
return marked[w];
}
//獲取與頂點s相通的所有頂點的總數
public int count() {
return count;
}
}
【測驗代碼】
public class DepthFirstSearchTest {
public static void main(String[] args) {
Graph G = new Graph(13);
G.addEdge(0, 5);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(0, 6);
G.addEdge(5, 3);
G.addEdge(5, 4);
G.addEdge(3, 4);
G.addEdge(4, 6);
G.addEdge(7, 8);
G.addEdge(9, 11);
G.addEdge(9, 12);
G.addEdge(9, 10);
G.addEdge(11, 12);
DepthFirstSearch search = new DepthFirstSearch(G, 0);
//測驗與某個頂點相通的頂點數量
int count = search.count();
System.out.println("與起點0相通的頂點的數量為:" + count);
//測驗某個頂點與起點是否相同
boolean marked1 = search.marked(5);
System.out.println("頂點5和頂點0是否相通:" + marked1);
boolean marked2 = search.marked(7);
System.out.println("頂點7和頂點0是否相通:" + marked2);
}
}
【運行效果】
與起點0相通的頂點的數量為:7
頂點5和頂點0是否相通:true
頂點7和頂點0是否相通:false
2.3.2、廣度優先搜索連通數量
【圖的結構】
在很多情況下,我們需要遍歷圖,得到圖的一些性質,例如,找出圖中與指定的頂點相連的所有頂點,或者判定某個頂點與指定頂點是否相通,是非常常見的需求,有關圖的搜索,最經典的演算法有深度優先搜索和廣度優先搜索,接下來我們講解廣度優先搜索演算法,
以下圖是查找和頂點0相通的所有頂點,紅色部分只是一次遍歷結果,不是全部,但是可以以小見大,
ps:下圖每個鏈表中的資料可能和上邊測驗的資料順序不太一樣,請不要在意,都是對的,這取決于你添加邊的順序,
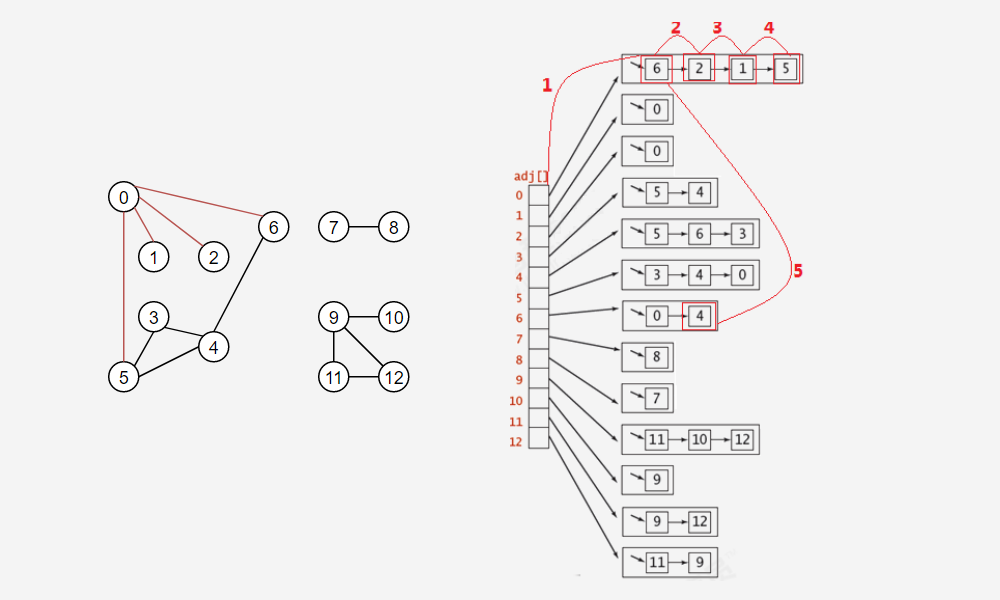
【實作代碼】
public class BreadthFirstSearch {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private int count; //記錄有多少個頂點與頂點s相通
public BreadthFirstSearch(Graph G, int s) { //構造廣度優先搜索物件
this.marked = new boolean[G.size()]; //初始化marked陣列
this.count = 0; //初始化跟頂點s相通的頂點的數量
bfs(G, s); //使用廣度優先搜索找出G圖中頂點s的所有相鄰頂點
}
private void bfs(Graph G, int v) { //使用廣度優先搜索找出G圖中頂點v的所有相通頂點
Queue<Integer> queue = new LinkedList<>(); //用來存盤待搜索鄰接表的點
marked[v] = true; //把頂點v標識為已搜索
count++; //頂點v和頂點v自己是相通的,所以加一
queue.add(v); //讓頂點v進入佇列,待搜索
while (!queue.isEmpty()) { //如果佇列不為空,則從佇列中彈出一個待搜索的頂點進行搜索
Integer wait = queue.poll(); //彈出一個待搜索的頂點
for (Integer w : G.adj(wait)) { //遍歷wait頂點的鄰接表
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
marked[w] = true; //把w頂點標識為已搜索
count++; //頂點v和頂點w自己是相通的,所以加一
queue.add(w); //讓頂點w進入佇列,待搜索
}
}
}
}
//判斷w頂點與頂點s是否相通
public boolean marked(int w) {
return marked[w];
}
//獲取與頂點s相通的所有頂點的總數
public int count() {
return count;
}
}
【測驗代碼】
public class BreadthFirstSearchTest {
public static void main(String[] args) {
Graph G = new Graph(13);
G.addEdge(0, 5);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(0, 6);
G.addEdge(5, 3);
G.addEdge(5, 4);
G.addEdge(3, 4);
G.addEdge(4, 6);
G.addEdge(7, 8);
G.addEdge(9, 11);
G.addEdge(9, 12);
G.addEdge(9, 10);
G.addEdge(11, 12);
BreadthFirstSearch search = new BreadthFirstSearch(G, 0);
//測驗與某個頂點相通的頂點數量
int count = search.count();
System.out.println("與起點0相通的頂點的數量為:" + count);
//測驗某個頂點與起點是否相同
boolean marked1 = search.marked(5);
System.out.println("頂點5和頂點0是否相通:" + marked1);
boolean marked2 = search.marked(7);
System.out.println("頂點7和頂點0是否相通:" + marked2);
}
}
【運行效果】
與起點0相通的頂點的數量為:7
頂點5和頂點0是否相通:true
頂點7和頂點0是否相通:false
2.4、無向圖的路徑
2.4.1、深度優先搜索有效路徑
【圖的結構】
在實際生活中,地圖是我們經常使用的一種工具,通常我們會用他進行導航,輸入一個出發城市,輸入一個目的地城市,就可以把路線規劃好,而在規劃好的這個路線上,會路過很多中間的城市,這類問題翻譯成專業問題就是: 從s頂點到v頂點是否存在一條路徑?如果存在,請找出這條路徑,
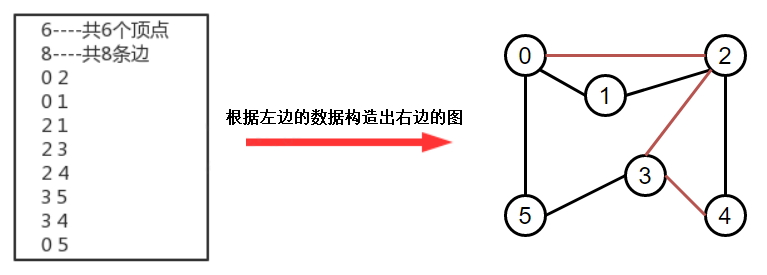
【實作代碼】
public class DepthFirstPaths {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private int[] edgeTo; //索引代表頂點,值代表從起點s到當前頂點路徑上的最后一個頂點
private int s; //記錄有多少個頂點與頂點s相通
public DepthFirstPaths(Graph G, int s) { //構造深度優先搜索物件
this.marked = new boolean[G.size()]; //初始化marked陣列
this.edgeTo = new int[G.size()]; //初始化edgeTo陣列
this.s = s; //初始化起點
dfs(G, s); //使用深度優先搜索找出G圖中起點為s的所有路徑
}
private void dfs(Graph G, int v) { //使用深度優先搜索找出G圖中起點為s的所有路徑
marked[v] = true; //把v頂點標識為已搜索
for (Integer w : G.adj(v)) {
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
edgeTo[w] = v; //到達頂點w的路徑上的最后一個頂點是v
dfs(G, w); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
}
//判斷v頂點與頂點s是否存在路徑
public boolean hasPathTo(int v) {
return marked[v];
}
//找出從起點s到頂點v的路徑
public Stack<Integer> pathTo(int v) {
if (!hasPathTo(v)) {
return null;
}
Stack<Integer> path = new Stack<>();
for (int x = v; x != s; x = edgeTo[x]) {
path.push(x);
}
path.push(s);
return path;
}
}
【測驗代碼】
public class DepthFirstPathsTest {
public static void main(String[] args) {
int s = 0;//從s點開始走
int n = 6;//圖g的頂點數
Graph G = new Graph(n);
G.addEdge(0, 2);
G.addEdge(0, 1);
G.addEdge(2, 1);
G.addEdge(2, 3);
G.addEdge(2, 4);
G.addEdge(3, 5);
G.addEdge(3, 4);
G.addEdge(0, 5);
DepthFirstPaths paths = new DepthFirstPaths(G, s);
for (int v = s; v < n; v++) {
if (paths.hasPathTo(v)) {
Stack<Integer> stack = paths.pathTo(v);
System.out.print(s + " to " + v + ": ");
while (!stack.isEmpty()) {
if (stack.size() == 1) {
System.out.print(stack.pop() + "\n");
} else {
System.out.print(stack.pop() + "->");
}
}
}
}
}
}
【運行效果】
0 to 0: 0
0 to 1: 0->2->1
0 to 2: 0->2
0 to 3: 0->2->3
0 to 4: 0->2->3->4
0 to 5: 0->2->3->5
2.4.2、廣度優先搜索最短路徑
【圖的結構】
在實際生活中,地圖是我們經常使用的一種工具,通常我們會用他進行導航,輸入一個出發城市,輸入一個目的地城市,就可以把路線規劃好,而在規劃好的這個路線上,會路過很多中間的城市,如何走路程才是最近的,這類問題翻譯成專業問題就是: 從s頂點到v頂點是否存在一條路徑?廣度優先搜索都能找到一條從s到v的最短路徑,沒有其他從s到v的路徑所含的邊比這條路徑更少,如果存在,請找出這條路徑,
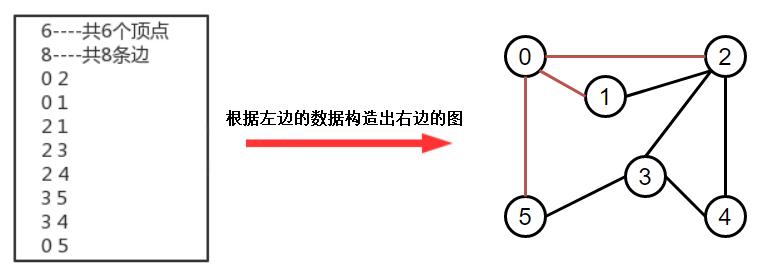
【實作代碼】
public class BreadFirstPaths {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private int[] edgeTo; //索引代表頂點,值代表從起點s到當前頂點路徑上的最后一個頂點
private int s; //記錄有多少個頂點與頂點s相通
public BreadFirstPaths(Graph G, int s) { //構造廣度優先搜索物件
this.marked = new boolean[G.size()]; //初始化marked陣列
this.edgeTo = new int[G.size()]; //初始化edgeTo陣列
this.s = s; //初始化起點
bfs(G, s); //使用廣度優先搜索找出G圖中起點為s的所有路徑
}
private void bfs(Graph G, int v) { //使用廣度優先搜索找出G圖中v頂點的所有相通頂點
Queue<Integer> queue = new LinkedList<>(); //用來存盤待搜索鄰接表的點
marked[v] = true; //把v頂點標識為已搜索
queue.add(v); //讓頂點v進入佇列,待搜索
while (!queue.isEmpty()) { //如果佇列不為空,則從佇列中彈出一個待搜索的頂點進行搜索
Integer wait = queue.poll(); //彈出一個待搜索的頂點
for (Integer w : G.adj(wait)) { //遍歷wait頂點的鄰接表
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
edgeTo[w] = wait; //到達頂點w的路徑上的最后一個頂點是wait
marked[w] = true; //把w頂點標識為已搜索
queue.add(w); //讓頂點w進入佇列,待搜索
}
}
}
}
//判斷v頂點與頂點s是否存在路徑
public boolean hasPathTo(int v) {
return marked[v];
}
//找出從起點s到頂點v的路徑
public Stack<Integer> pathTo(int v) {
if (!hasPathTo(v)) {
return null;
}
Stack<Integer> path = new Stack<>();
for (int x = v; x != s; x = edgeTo[x]) {
path.push(x);
}
path.push(s);
return path;
}
}
【測驗代碼】
public class BreadFirstPathsTest {
public static void main(String[] args) {
int s = 0;//從s點開始走
int n = 6;//圖g的頂點數
Graph G = new Graph(n);
G.addEdge(0, 2);
G.addEdge(0, 1);
G.addEdge(2, 1);
G.addEdge(2, 3);
G.addEdge(2, 4);
G.addEdge(3, 5);
G.addEdge(3, 4);
G.addEdge(0, 5);
BreadFirstPaths paths = new BreadFirstPaths(G, s);
for (int v = s; v < n; v++) {
if (paths.hasPathTo(v)) {
Stack<Integer> stack = paths.pathTo(v);
System.out.print(s + " to " + v + ": ");
while (!stack.isEmpty()) {
if (stack.size() == 1) {
System.out.print(stack.pop() + "\n");
} else {
System.out.print(stack.pop() + "->");
}
}
}
}
}
}
【運行效果】
0 to 0: 0
0 to 1: 0->1
0 to 2: 0->2
0 to 3: 0->2->3
0 to 4: 0->2->4
0 to 5: 0->5
2.5、無向環的判斷
【圖的結構】
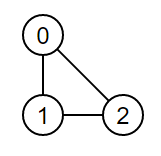
【實作代碼】
public class Cycle {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private boolean hasCycle; //記錄圖中是否有環
public Cycle(Graph G) {
this.marked = new boolean[G.size()]; //初始化marked陣列
this.hasCycle = false; //初始化hasCycle變數
for (int v = 0; v < G.size(); v++) {
if (!marked[v]) { //判斷當前v頂點有沒有被搜索過
dfs(G, v, v); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
}
private void dfs(Graph G, int v, int u) { //v代表當前頂點,u代表當前頂點的父頂點(這里的父頂點表示dfs遍歷順序中的父頂點)
marked[v] = true; //把v頂點標識為已搜索
for (Integer w : G.adj(v)) {
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
dfs(G, w, v); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
} else if (w != u) { //如果存在某個鄰接的頂點已被標記為訪問狀態,且這個頂點不是當前頂點的父頂點
hasCycle = true; //那么這個圖就是存在回路的
}
}
}
//判斷當前無向圖G中是否有環
public boolean hasCycle() {
return hasCycle;
}
}
【測驗代碼】
public class CycleTest {
public static void main(String[] args) {
Graph G = new Graph(3);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(1, 2);
Cycle cycle = new Cycle(G);
System.out.println("是否有環:" + cycle.hasCycle());
System.out.println("====================");
System.out.println(G);
}
}
【運行效果】
是否有環:true
====================
3 vertices, 3 edges
0: 1 2
1: 0 2
2: 0 1
第三章 有向圖
3.1、有向圖的術語
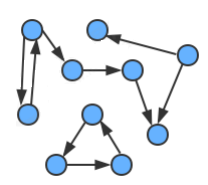
出度:由某個頂點指出的邊的個數稱為該頂點的出度,
入度:指向某個頂點的邊的個數稱為該頂點的入度,
有向路徑:由一系列頂點組成,對于其中的每個頂點都存在一條有向邊,從他指向序列中的下一個頂點,
有向環:一條至少含有一條邊,且起點和終點相同的有向路徑,
3.2、有向圖的實作
【圖的結構】
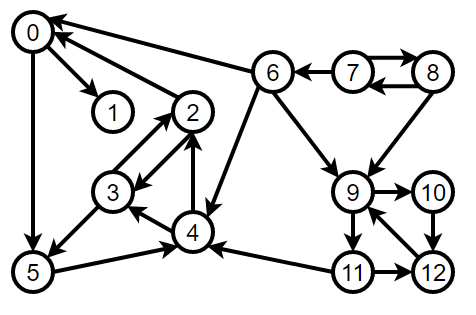
【實作代碼】
約定: N代表頂點數目,則N的取值范圍只能是0 ~ N-1,比如:N=3,則這三個頂點分別為:頂點0、頂點1、頂點2,如用其他值可能會造成adj下標越界,
public class Digraph {
private int N; //表示頂點數目
private int E; //表示邊的數目
private Queue<Integer>[] adj; //表示鄰接表
public Digraph(int n) {
this.N = n; //初始化頂點數目
this.E = 0; //初始化邊的數目
this.adj = new LinkedList[n]; //初始化鄰接表
for (int i = 0; i < adj.length; i++) {
adj[i] = new LinkedList<>();
}
}
//獲取頂點數目
public int size() {
return N;
}
//獲取邊的數目
public int edge() {
return E;
}
//添加一條邊
public void addEdge(int v, int w) {
adj[v].add(w); //在v的鏈表中添加w
E++; //圖的邊數加一
}
//洗掉一條邊
public void removeEdge(int v, int w) {
adj[v].remove(w); //在v的鏈表中洗掉w
E--; //圖的邊數減一
}
//獲取v的鄰點
public Queue<Integer> adj(int v) {
return adj[v];
}
//獲取反向圖
public Digraph reverse() {
Digraph r = new Digraph(N);
for (int v = 0; v < N; v++) {
for (Integer w : adj[v]) {
r.addEdge(w, v);
}
}
return r;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(N + " vertices, ");
sb.append(E + " edges\n");
for (int v = 0; v < N; v++) {
sb.append(v + ": ");
for (Integer w : adj(v)) {
sb.append(w + " ");
}
sb.append("\n");
}
return sb.toString();
}
}
【測驗代碼】
public class DigraphTest {
public static void main(String[] args) {
Digraph D = new Digraph(13);
D.addEdge(4, 2);
D.addEdge(2, 3);
D.addEdge(3, 2);
D.addEdge(6, 0);
D.addEdge(0, 1);
D.addEdge(2, 0);
D.addEdge(11, 12);
D.addEdge(12, 9);
D.addEdge(9, 10);
D.addEdge(9, 11);
D.addEdge(8, 9);
D.addEdge(10, 12);
D.addEdge(11, 4);
D.addEdge(4, 3);
D.addEdge(3, 5);
D.addEdge(7, 8);
D.addEdge(8, 7);
D.addEdge(5, 4);
D.addEdge(0, 5);
D.addEdge(6, 4);
D.addEdge(6, 9);
D.addEdge(7, 6);
System.out.println("獲取D的大小:" + D.size());
System.out.println("獲取D的邊數:" + D.edge());
System.out.println("====================");
for (int v = 0; v < D.size(); v++) {
System.out.println("獲取D中" + v + "的鄰點:" + D.adj(v));
}
System.out.println("====================");
System.out.println(D);
Digraph R = D.reverse();
System.out.println("獲取R的大小:" + R.size());
System.out.println("獲取R的邊數:" + R.edge());
System.out.println("====================");
for (int v = 0; v < R.size(); v++) {
System.out.println("獲取R中" + v + "的鄰點:" + R.adj(v));
}
System.out.println("====================");
System.out.println(R);
}
}
【運行效果】
獲取D的大小:13
獲取D的邊數:22
====================
獲取D中0的鄰點:[1, 5]
獲取D中1的鄰點:[]
獲取D中2的鄰點:[3, 0]
獲取D中3的鄰點:[2, 5]
獲取D中4的鄰點:[2, 3]
獲取D中5的鄰點:[4]
獲取D中6的鄰點:[0, 4, 9]
獲取D中7的鄰點:[8, 6]
獲取D中8的鄰點:[9, 7]
獲取D中9的鄰點:[10, 11]
獲取D中10的鄰點:[12]
獲取D中11的鄰點:[12, 4]
獲取D中12的鄰點:[9]
====================
13 vertices, 22 edges
0: 1 5
1:
2: 3 0
3: 2 5
4: 2 3
5: 4
6: 0 4 9
7: 8 6
8: 9 7
9: 10 11
10: 12
11: 12 4
12: 9
獲取R的大小:13
獲取R的邊數:22
====================
獲取R中0的鄰點:[2, 6]
獲取R中1的鄰點:[0]
獲取R中2的鄰點:[3, 4]
獲取R中3的鄰點:[2, 4]
獲取R中4的鄰點:[5, 6, 11]
獲取R中5的鄰點:[0, 3]
獲取R中6的鄰點:[7]
獲取R中7的鄰點:[8]
獲取R中8的鄰點:[7]
獲取R中9的鄰點:[6, 8, 12]
獲取R中10的鄰點:[9]
獲取R中11的鄰點:[9]
獲取R中12的鄰點:[10, 11]
====================
13 vertices, 22 edges
0: 2 6
1: 0
2: 3 4
3: 2 4
4: 5 6 11
5: 0 3
6: 7
7: 8
8: 7
9: 6 8 12
10: 9
11: 9
12: 10 11
3.3、有向圖的搜索
3.3.1、深度優先搜索連通數量
DepthFirstSearch也是有向圖中的重要處理演算法,因此之前單獨抽成了一個工具類,同樣的API和代碼,只需要把Graph替換成Digraph即可,
3.3.2、廣度優先搜索連通數量
BreadthFirstSearch也是有向圖中的重要處理演算法,因此之前單獨抽成了一個工具類,同樣的API和代碼,只需要把Graph替換成Digraph即可,
3.4、有向圖的路徑
3.4.1、深度優先搜索有效路徑
DepthFirstPaths也是有向圖中的重要處理演算法,因此之前單獨抽成了一個工具類,同樣的API和代碼,只需要把Graph替換成Digraph即可,
3.4.2、廣度優先搜索最短路徑
BreadFirstPaths也是有向圖中的重要處理演算法,因此之前單獨抽成了一個工具類,同樣的API和代碼,只需要把Graph替換成Digraph即可,
3.5、有向環的判斷
【圖的結構】
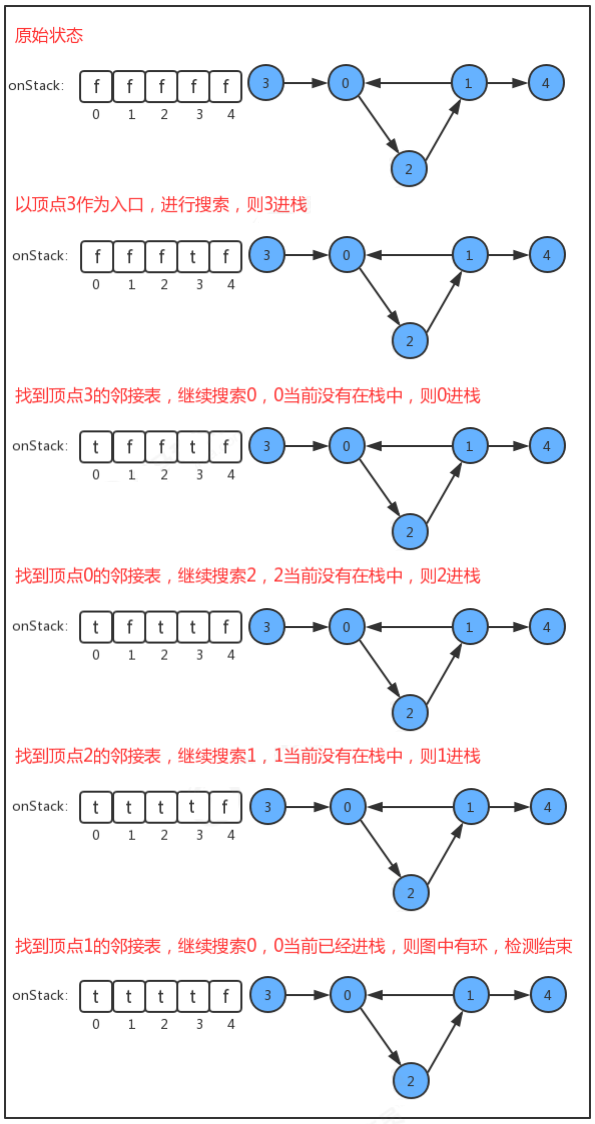
【實作代碼】
public class DirectedCycle {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private boolean hasCycle; //記錄圖中是否有環
private boolean[] onStack; //索引代表頂點,使用堆疊的思想,記錄當前頂點有沒有已經處于正在搜索的有向路徑上
public DirectedCycle(Digraph G) {
this.marked = new boolean[G.size()]; //初始化marked陣列
this.hasCycle = false; //初始化hasCycle變數
this.onStack = new boolean[G.size()]; //初始化onStack陣列
for (int v = 0; v < G.size(); v++) {
if (!marked[v]) { //判斷當前v頂點有沒有被搜索過
dfs(G, v); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
}
private void dfs(Digraph G, int v) { //使用深度優先搜索找出G圖中頂點v的所有相通頂點
marked[v] = true; //把v頂點標識為已搜索
onStack[v] = true; //讓當前頂點v進堆疊
for (Integer w : G.adj(v)) {
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
dfs(G, w); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
if (onStack[w]) { //如果頂點w已經被搜索過,則查看頂點w是否在堆疊中
hasCycle = true; //如果在,則證明圖中有環,修改hasCycle標記
return; //結束搜索
}
}
onStack[v] = false; //當前頂點已經搜索完畢,讓當前頂點出堆疊
}
//判斷當前有向圖G中是否有環
public boolean hasCycle() {
return hasCycle;
}
}
【測驗代碼】
public class DirectedCycleTest {
public static void main(String[] args) {
Digraph D = new Digraph(5);
D.addEdge(3, 0);
D.addEdge(0, 2);
D.addEdge(2, 1);
D.addEdge(1, 0);
D.addEdge(1, 4);
DirectedCycle cycle = new DirectedCycle(D);
System.out.println("是否有環:" + cycle.hasCycle());
System.out.println("====================");
System.out.println(D);
}
}
【運行效果】
是否有環:false
====================
5 vertices, 4 edges
0: 2
1: 4
2: 1
3: 0
4:
第四章 拓撲排序
4.1、頂點排序
【圖的結構】
如果要把圖中的頂點生成線性序列其實是一件非常簡單的事,我們會發現其實深度優先搜索有一個特點,那就是在一個連通子圖上,每個頂點只會被搜索一次,如果我們能在深度優先搜索的基礎上,添加一行代碼,只需要將搜索的頂點放入到線性序列的資料結構中,我們就能完成這件事,
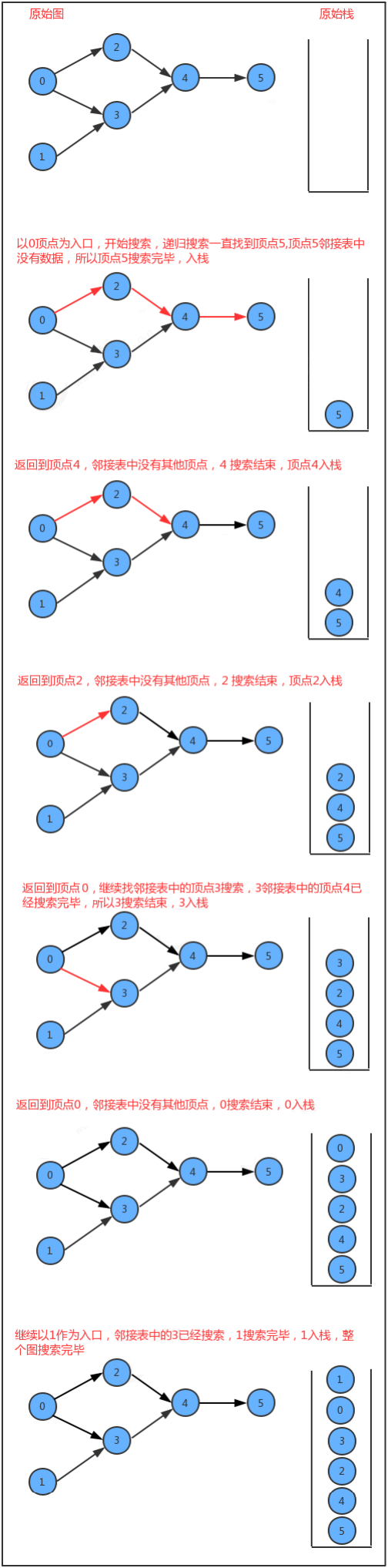
【實作代碼】
public class DepthFirstOrder {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private Stack<Integer> reversePost; //使用堆疊,存盤頂點序列
public DepthFirstOrder(Digraph G) {
this.marked = new boolean[G.size()]; //初始化marked陣列
this.reversePost = new Stack<>(); //初始化reversePost堆疊
for (int v = 0; v < G.size(); v++) {
if (!marked[v]) { //判斷當前v頂點有沒有被搜索過
dfs(G, v); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
}
private void dfs(Digraph G, int v) { //使用深度優先搜索找出G圖中頂點v的所有相通頂點
marked[v] = true; //把v頂點標識為已搜索
for (Integer w : G.adj(v)) {
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
dfs(G, w); //如果沒有被搜索過,則遞回呼叫dfs方法進行深度搜索
}
}
reversePost.push(v); //讓v頂點進堆疊
}
//獲取頂點線性序列
public Stack<Integer> reversePost() {
return reversePost;
}
}
【測驗代碼】
public class DepthFirstOrderTest {
public static void main(String[] args) {
Digraph D = new Digraph(6);
D.addEdge(0, 2);
D.addEdge(2, 4);
D.addEdge(4, 5);
D.addEdge(0, 3);
D.addEdge(3, 4);
D.addEdge(1, 3);
DepthFirstOrder order = new DepthFirstOrder(D);
Stack<Integer> stack = order.reversePost();
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
【運行效果】
1
0
3
2
4
5
4.2、拓撲排序
【圖的結構】
在現實生活中,我們經常會同一時間接到很多任務去完成,但是這些任務的完成是有先后次序的,以我們學習java學科為例,我們需要學習很多知識,但是這些知識在學習的程序中是需要按照先后次序來完成的,從java基礎,到jsp/servlet,到ssm,到springboot等是個循序漸進且有依賴的程序,在學習jsp前要首先掌握java基礎和html基礎,學習ssm框架前要掌握jsp/servlet之類才行,
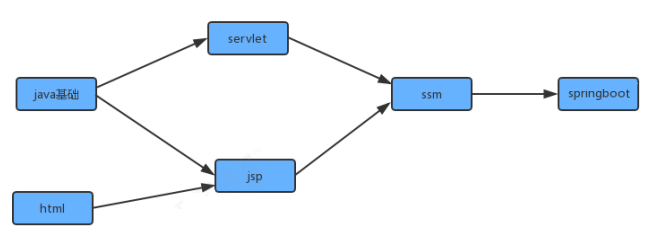
為了簡化問題,我們使用整數為頂點編號的標準模型來表示這個案例:
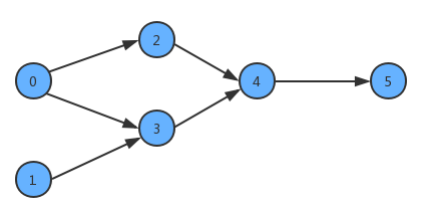
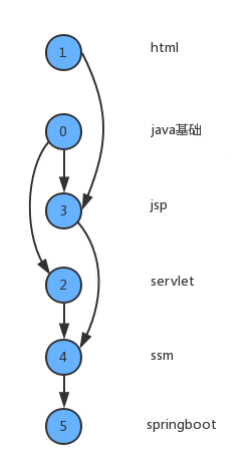
如果某個同學要學習這些課程,就需要指定出一個學習的方案,我們只需要對圖中的頂點進行排序,讓他轉換為一個線性序列,就可以解決問題,這時就需要用到一種叫 拓撲排序 的演算法,
拓撲排序: 給定一副有向圖,將所有的頂點排序,使得所有的有向邊均從排在前面的元素指向排在后面的元素,此時就可以明確的表示出每個頂點的優先級,
下圖是一副拓撲排序后的示意圖:
【實作代碼】
public class TopoLogical {
//頂點的拓撲排序
private Stack<Integer> order;
public TopoLogical(Digraph G) {
//創建一個檢測有向環的物件
DirectedCycle directedCycle = new DirectedCycle(G);
//判斷G圖中有沒有環,如果沒有環,則進行頂點排序
if (!directedCycle.hasCycle()) {
DepthFirstOrder depthFirstOrder = new DepthFirstOrder(G);
order = depthFirstOrder.reversePost();
}
}
//判斷圖G是否有環
public boolean isCycle() {
return order == null;
}
//獲取拓撲排序的所有頂點
public Stack<Integer> order() {
return order;
}
}
【測驗代碼】
public class TopoLogicalTest {
public static void main(String[] args) {
Digraph D = new Digraph(6);
D.addEdge(0, 2);
D.addEdge(2, 4);
D.addEdge(4, 5);
D.addEdge(0, 3);
D.addEdge(3, 4);
D.addEdge(1, 3);
TopoLogical topoLogical = new TopoLogical(D);
Stack<Integer> stack = topoLogical.order();
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
【運行效果】
1
0
3
2
4
5
第五章 加權無向圖
5.1、加權無向邊的實作
加權無向圖中的邊我們就不能簡單的使用v-w兩個頂點表示了,而必須要給邊關聯一個權重值,因此我們可以使用物件來描述一條邊,
public class Edge implements Comparable<Edge> {
private final int v; //頂點一
private final int w; //頂點二
private final double weight; //邊權重
public Edge(int v, int w, double weight) {
this.v = v; //初始化頂點一
this.w = w; //初始化頂點二
this.weight = weight; //初始化邊權重
}
//獲取邊的權重值
public double weight() {
return weight;
}
//獲取邊的一個點
public int either() {
return v;
}
//獲取邊的另一個點
public int other(int vertex) {
if (vertex == v) {
return w;
} else {
return v;
}
}
@Override
public int compareTo(Edge that) {
if (this.weight() > that.weight()) {
//如果當前邊的權重值比that邊的權重值大,回傳+1
return +1;
} else if (this.weight() < that.weight()) {
//如果當前邊的權重值比that邊的權重值小,回傳-1
return -1;
} else {
//如果當前邊的權重值和that邊的權重值一樣,回傳0
return 0;
}
}
@Override
public String toString() {
return String.format("%d-%d %.2f", v, w, weight);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Edge edge = (Edge) o;
return v == edge.v && w == edge.w && Double.compare(edge.weight, weight) == 0;
}
@Override
public int hashCode() {
return Objects.hash(v, w, weight);
}
}
5.2、加權無向圖的實作
【圖的結構】
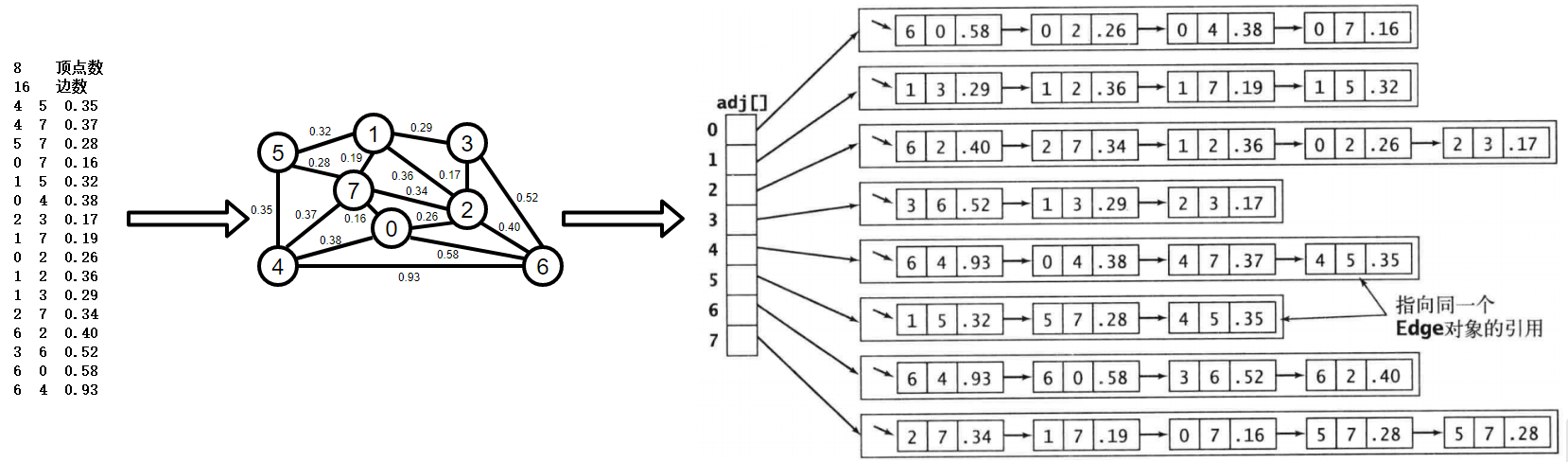
【實作代碼】
約定: N代表頂點數目,則N的取值范圍只能是0 ~ N-1,比如:N=3,則這三個頂點分別為:頂點0、頂點1、頂點2,如用其他值可能會造成adj下標越界,
public class EdgeWeightedGraph {
private int N; //表示頂點數目
private int E; //表示邊的數目
private Queue<Edge>[] adj; //表示鄰接表
public EdgeWeightedGraph(int n) {
this.N = n; //初始化頂點數目
this.E = 0; //初始化邊的數目
this.adj = new LinkedList[n]; //初始化鄰接表
for (int i = 0; i < adj.length; i++) {
adj[i] = new LinkedList<>();
}
}
//獲取頂點數目
public int size() {
return N;
}
//獲取邊的數目
public int edge() {
return E;
}
//添加一條邊
public void addEdge(Edge e) {
int v = e.either();
int w = e.other(v);
adj[v].add(e);
adj[w].add(e);
E++;
}
//洗掉一條邊
public void removeEdge(Edge e) {
int v = e.either();
int w = e.other(v);
adj[v].remove(e);
adj[w].remove(e);
E--;
}
//獲取和頂點v關聯的所有邊
public Queue<Edge> adj(int v) {
return adj[v];
}
//獲取加權無向圖的所有邊
public Queue<Edge> edges() {
Queue<Edge> allEdges = new LinkedList<>();
for (int v = 0; v < N; v++) {
for (Edge e : adj(v)) {
if (e.other(v) < v) {
allEdges.add(e);
}
}
}
return allEdges;
}
}
【測驗代碼】
public class EdgeWeightedGraphTest {
public static void main(String[] args) {
EdgeWeightedGraph EWG = new EdgeWeightedGraph(8);
EWG.addEdge(new Edge(4, 5, 0.35));
EWG.addEdge(new Edge(4, 7, 0.37));
EWG.addEdge(new Edge(5, 7, 0.28));
EWG.addEdge(new Edge(0, 7, 0.16));
EWG.addEdge(new Edge(1, 5, 0.32));
EWG.addEdge(new Edge(0, 4, 0.38));
EWG.addEdge(new Edge(2, 3, 0.17));
EWG.addEdge(new Edge(1, 7, 0.19));
EWG.addEdge(new Edge(0, 2, 0.26));
EWG.addEdge(new Edge(1, 2, 0.36));
EWG.addEdge(new Edge(1, 3, 0.29));
EWG.addEdge(new Edge(2, 7, 0.34));
EWG.addEdge(new Edge(6, 2, 0.40));
EWG.addEdge(new Edge(3, 6, 0.52));
EWG.addEdge(new Edge(6, 0, 0.58));
EWG.addEdge(new Edge(6, 4, 0.93));
System.out.println("獲取EWG的大小:" + EWG.size());
System.out.println("獲取EWG的邊數:" + EWG.edge());
System.out.println("====================");
for (int v = 0; v < EWG.size(); v++) {
System.out.println("獲取和頂點" + v + "關聯的所有邊:" + EWG.adj(v));
}
System.out.println("====================");
for (Edge e : EWG.edges()) {
System.out.println(e);
}
}
}
【運行效果】
獲取EWG的大小:8
獲取EWG的邊數:16
====================
獲取和頂點0關聯的所有邊:[0-7 0.16, 0-4 0.38, 0-2 0.26, 6-0 0.58]
獲取和頂點1關聯的所有邊:[1-5 0.32, 1-7 0.19, 1-2 0.36, 1-3 0.29]
獲取和頂點2關聯的所有邊:[2-3 0.17, 0-2 0.26, 1-2 0.36, 2-7 0.34, 6-2 0.40]
獲取和頂點3關聯的所有邊:[2-3 0.17, 1-3 0.29, 3-6 0.52]
獲取和頂點4關聯的所有邊:[4-5 0.35, 4-7 0.37, 0-4 0.38, 6-4 0.93]
獲取和頂點5關聯的所有邊:[4-5 0.35, 5-7 0.28, 1-5 0.32]
獲取和頂點6關聯的所有邊:[6-2 0.40, 3-6 0.52, 6-0 0.58, 6-4 0.93]
獲取和頂點7關聯的所有邊:[4-7 0.37, 5-7 0.28, 0-7 0.16, 1-7 0.19, 2-7 0.34]
====================
0-2 0.26
1-2 0.36
2-3 0.17
1-3 0.29
0-4 0.38
4-5 0.35
1-5 0.32
6-2 0.40
3-6 0.52
6-0 0.58
6-4 0.93
4-7 0.37
5-7 0.28
0-7 0.16
1-7 0.19
2-7 0.34
第六章 最小生成樹
6.1、最小生成樹的定義
圖的生成樹是他的一棵含有其所有頂點的無環連通子圖,一幅加權無向圖的最小生成樹(MST)是他的一棵權值(樹中所有邊的權重之和)最小的生成樹,
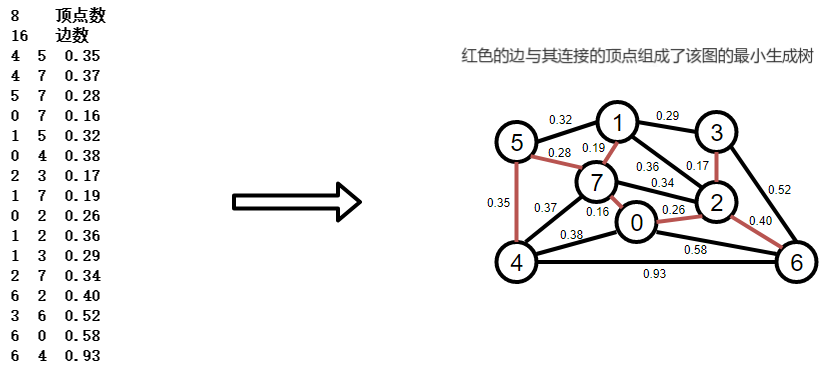
6.2、最小生成樹的約定
- 只考慮連通圖,最小生成樹的定義說明他只能存在于連通圖中,如果圖不是連通的,那么分別計算每個連通圖子圖的最小生成樹,合并到一起稱為最小生成森林,
- 所有邊的權重都各不相同,如果不同的邊權重可以相同,那么一副圖的最小生成樹就可能不唯一了,雖然我們的演算法可以處理這種情況,但為了好理解,我們約定所有邊的權重都各不相同,
6.3、切分定理
要從一幅連通圖中找出該圖的最小生成樹,需要通過切分定理完成,
切分: 將圖的所有頂點按照某些規則分為兩個非空且沒有交集的集合,
橫切邊: 連接兩個屬于不同集合的頂點的邊稱之為橫切邊,在一幅加權圖中,給定任意的切分,他橫切邊中的權重最小者必然屬于圖中的最小生成樹的一條邊,
例如,我們將圖中的頂點切分為兩個集合,灰色頂點屬于一個集合,白色頂點屬于另外一個集合,那么效果如下:
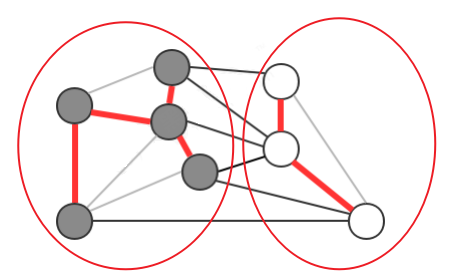
注意:一次切分產生的多個橫切邊中,權重最小的邊不一定是所有橫切邊中唯一屬于圖的最小生成樹的一條邊,
6.4、Prim演算法
6.4.1、演算法介紹
普里姆(Prim)演算法是圖論中的一種演算法,可在加權連通圖里搜索最小生成樹(英語:Minimum Spanning Tree,MST),即由此演算法搜索到的邊子集所構成的樹中,不但包括了連通圖里的所有頂點(英語:Vertex),且其所有邊的權值(英語:Weighted)之和亦為最小,該演算法于1930年由捷克數學家沃伊捷赫·亞爾尼克(英語:Vojtěch Jarník)發現;并在1957年由美國計算機科學家羅伯特·普里姆(英語:Robert C. Prim)獨立發現;1959年,艾茲格·迪科斯徹(英語:Edsger Wybe Dijkstra)再次發現了該演算法,因此,在某些場合,普里姆演算法又被稱為DJP演算法、亞爾尼克演算法或普里姆-亞爾尼克演算法,
6.4.2、演算法原理
1、將頂點0添加到最小生成樹之中,將他的鄰接表中的所有邊添加到優先佇列中,
約定:紅色代表最小生成樹;綠色代表加入優先佇列中的邊(也代表橫切邊);灰色代表失效邊;
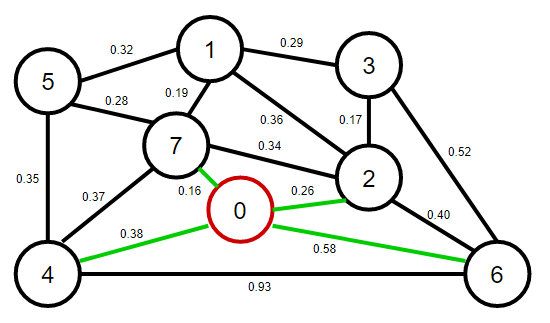
2、從優先佇列中彈出權重最小的邊0-7,將0-7這條邊和頂點7加入到最小生成樹之中,將頂點7的鄰接表中的所有邊添加到優先佇列中,
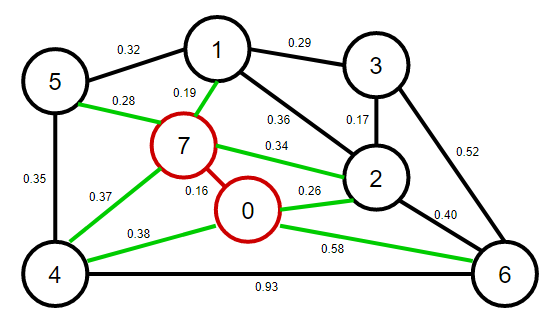
3、從優先佇列中彈出權重最小的邊1-7,將1-7這條邊和頂點1加入到最小生成樹之中,將頂點1的鄰接表中的所有邊添加到優先佇列中,
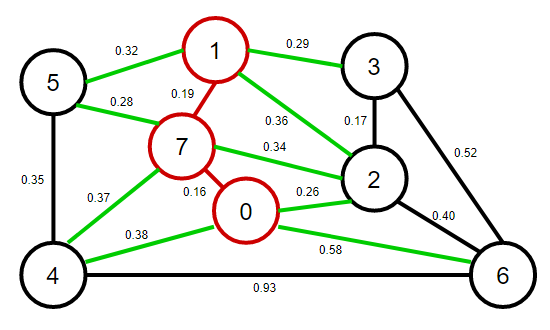
4、從優先佇列中彈出權重最小的邊0-2,將0-2這條邊和頂點2加入到最小生成樹之中,將頂點2的鄰接表中的所有邊添加到優先佇列中,
注意:此時邊1-2和邊2-7變為失效邊,原因是邊1-2和2-7這兩個邊已經形成不了橫切邊了,因為每個邊的兩個頂點都在最小生成樹中,
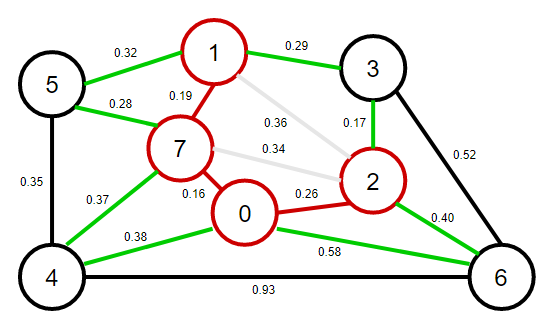
5、從優先佇列中彈出權重最小的邊2-3,將2-3這條邊和頂點3加入到最小生成樹之中,將頂點3的鄰接表中的所有邊添加到優先佇列中,
注意:此時邊1-3變為失效邊,原因是邊1-3這一個邊已經形成不了橫切邊了,因為每個邊的兩個頂點都在最小生成樹中,
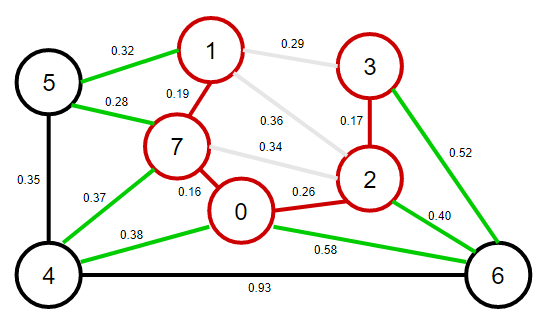
6、從優先佇列中彈出權重最小的邊5-7,將5-7這條邊和頂點5加入到最小生成樹之中,將頂點5的鄰接表中的所有邊添加到優先佇列中,
注意:此時邊1-5變為失效邊,原因是邊1-5這一個邊已經形成不了橫切邊了,因為每個邊的兩個頂點都在最小生成樹中,
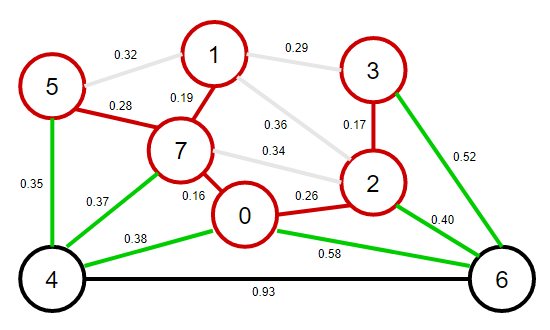
7、從優先佇列中彈出權重最小的邊4-5,將4-5這條邊和頂點4加入到最小生成樹之中,將頂點4的鄰接表中的所有邊添加到優先佇列中,
注意:此時邊4-7和邊0-4變為失效邊,原因是邊4-7和邊0-4這兩個邊已經形成不了橫切邊了,因為每個邊的兩個頂點都在最小生成樹中,
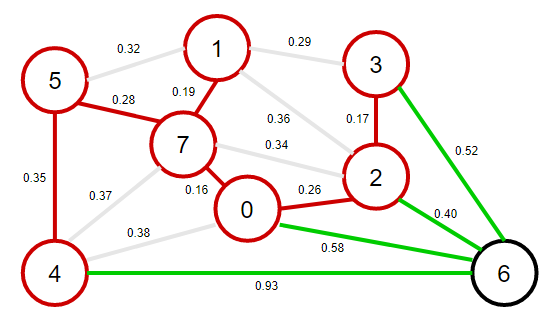
8、從優先佇列中彈出權重最小的邊2-6,將2-6這條邊和頂點6加入到最小生成樹之中,將頂點6的鄰接表中的所有邊添加到優先佇列中,
注意:此時邊4-6和邊0-6和邊3-6變為失效邊,原因是邊4-6和邊0-6和邊3-6這三個邊已經形成不了橫切邊了,因為每個邊的兩個頂點都在最小生成樹中,
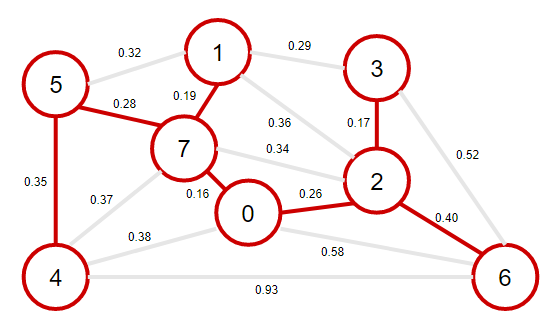
在添加了N個頂點(以及N-1條邊)之后,最小生成樹就完成了,優先佇列中余下的邊都是無效邊,不需要再去檢查他們,
該最小生成樹的權值為:0.16+0.19+0.26+0.17+0.28+0.35+0.40=1.81
6.4.3、演算法實作
【圖的結構】
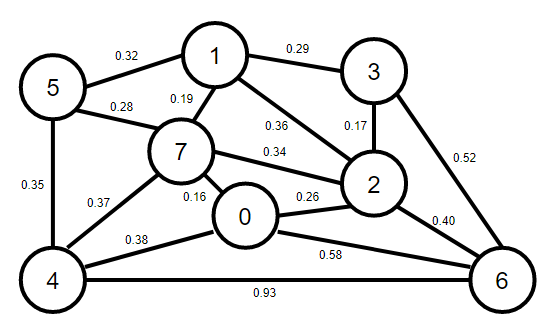
【實作代碼】
public class PrimMST {
private boolean[] marked; //索引代表頂點,值表示當前頂點是否已經被搜索
private Queue<Edge> mst; //最小生成樹的各個邊
private Queue<Edge> pq; //優先佇列用來存放橫切邊(包括失效的邊)
public PrimMST(EdgeWeightedGraph G) {
this.marked = new boolean[G.size()]; //初始化marked陣列
this.mst = new LinkedList<>(); //初始化mst最小生成樹
this.pq = new PriorityQueue<>(); //初始化pq優先佇列
visit(G, 0); //假設G是連通的
while (!pq.isEmpty() && (mst.size() < G.size() - 1)) {
Edge e = pq.poll(); //取出權重最小的那條邊
int v = e.either(); //獲取權重最小的那條邊的其中一個點
int w = e.other(v); //獲取權重最小的那條邊的另外一個點
if (marked[v] && marked[w]) { //跳過失效的邊
continue;
}
mst.add(e); //將權重最小的那條邊加入到最小生成樹中
if (!marked[v]) { //將頂點v添加到最小生成樹中
visit(G, v);
}
if (!marked[w]) { //將頂點w添加到最小生成樹中
visit(G, w);
}
}
}
private void visit(EdgeWeightedGraph G, int v) {
marked[v] = true; //把頂點v標識為已搜索
for (Edge e : G.adj(v)) {
int w = e.other(v); //獲取邊e的另外一個頂點w
if (!marked[w]) { //判斷當前w頂點有沒有被搜索過
pq.add(e); //如果沒有被搜索過,就直接把頂點v和頂點w所對應的邊e加入到優先佇列pq中
}
}
}
//獲取最小生成樹的各邊
public Queue<Edge> edges() {
return mst;
}
//獲取最小生成樹的權重
public double weight() {
double s = 0.0D;
if (mst != null) {
for (Edge e : mst) {
s += e.weight();
}
}
return s;
}
}
【測驗代碼】
public class PrimMSTTest {
public static void main(String[] args) {
EdgeWeightedGraph EWG = new EdgeWeightedGraph(8);
EWG.addEdge(new Edge(4, 5, 0.35));
EWG.addEdge(new Edge(4, 7, 0.37));
EWG.addEdge(new Edge(5, 7, 0.28));
EWG.addEdge(new Edge(0, 7, 0.16));
EWG.addEdge(new Edge(1, 5, 0.32));
EWG.addEdge(new Edge(0, 4, 0.38));
EWG.addEdge(new Edge(2, 3, 0.17));
EWG.addEdge(new Edge(1, 7, 0.19));
EWG.addEdge(new Edge(0, 2, 0.26));
EWG.addEdge(new Edge(1, 2, 0.36));
EWG.addEdge(new Edge(1, 3, 0.29));
EWG.addEdge(new Edge(2, 7, 0.34));
EWG.addEdge(new Edge(6, 2, 0.40));
EWG.addEdge(new Edge(3, 6, 0.52));
EWG.addEdge(new Edge(6, 0, 0.58));
EWG.addEdge(new Edge(6, 4, 0.93));
PrimMST mst = new PrimMST(EWG);
System.out.println("最小生成樹的各邊:");
for (Edge e : mst.edges()) {
System.out.println(e);
}
System.out.println("====================");
System.out.println("最小生成樹的權重:" + mst.weight());
}
}
【運行效果】
最小生成樹的各邊:
0-7 0.16
1-7 0.19
0-2 0.26
2-3 0.17
5-7 0.28
4-5 0.35
6-2 0.40
====================
最小生成樹的權重:1.81
6.5、Kruskal演算法
6.5.1、演算法介紹
克魯斯卡爾(Kruskal)演算法是求連通圖的最小生成樹的另一種方法,與普里姆演算法不同,他的時間復雜度為O(ElogE)(E為圖中的邊數),所以適合于求邊稀疏的圖的最小生成樹,克魯斯卡爾(Kruskal)演算法從另一途徑求圖的最小生成樹,其基本思想是:假設連通圖G=(N,E),令最小生成樹的初始狀態為只有n個頂點而無邊的非連通圖T=(N,{}),圖中每個頂點自成一個連通分量,在E中選擇代價最小的邊,若該邊依附的頂點分別在T中不同的連通分量上,則將此邊加入到T中;否則,舍去此邊而選擇下一條代價最小的邊,依此類推,直至T中所有頂點構成一個連通分量為止,
簡單的來說:按照邊的權重順序(從小到大)處理他們,將邊加入最小生成樹中,加入的邊不會與已經加入的邊構成環,直到樹中含有N-1條邊為止,
6.5.2、演算法原理
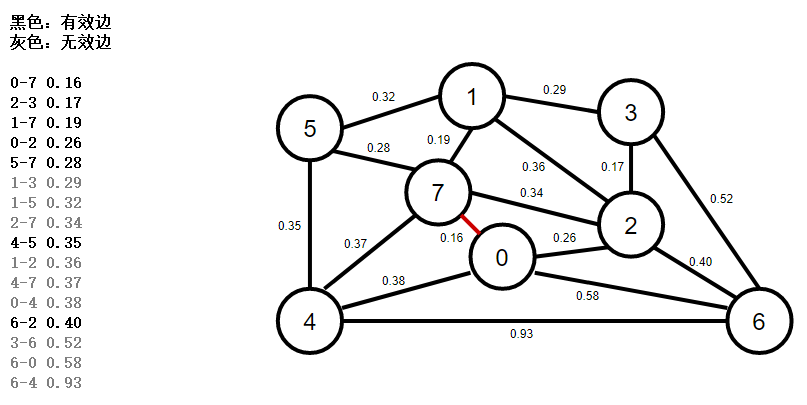
1、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊0-7,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
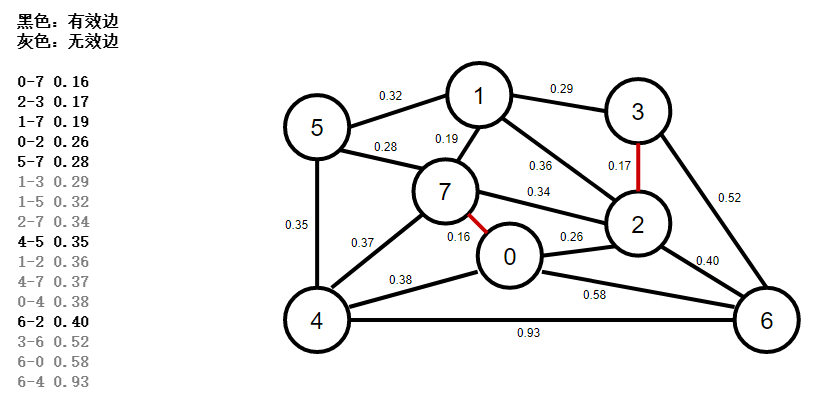
2、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊2-3,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
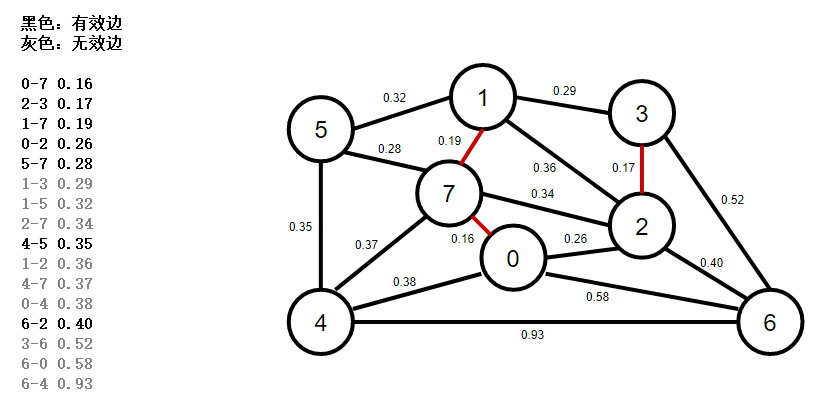
3、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊1-7,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
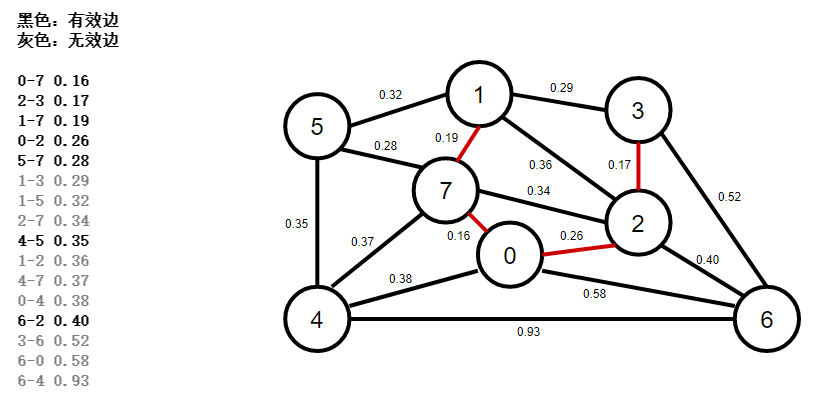
4、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊0-2,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
5、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊5-7,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
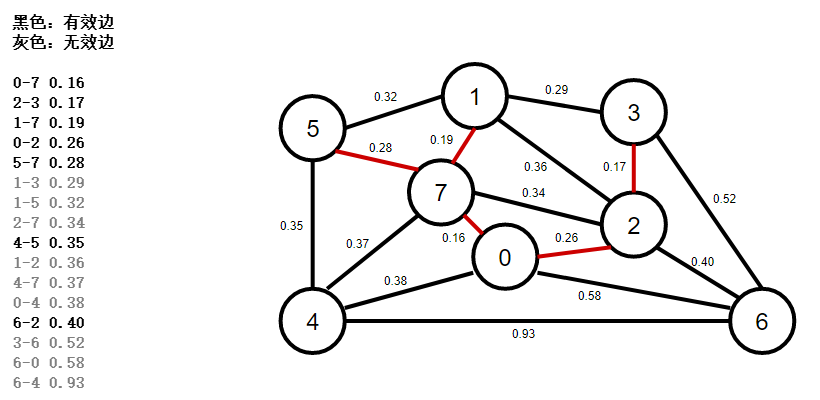
6、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊1-3,此時邊1-3如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
7、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊1-5,此時邊1-5如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
8、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊2-7,此時邊2-7如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
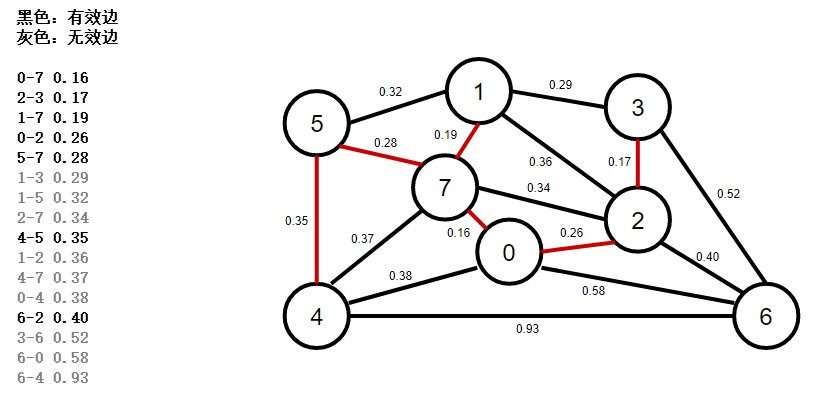
9、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊4-5,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
10、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊1-2,此時邊1-2如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
11、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊4-7,此時邊4-7如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
12、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊0-4,此時邊0-4如果連接起來,mst最小生成樹會構成環路,所以是無效邊,忽略掉,
13、使用優先佇列按權重排序所有邊,彈出權重最小的一條邊6-2,判斷是否是有效邊,如果是,加入mst最小生成樹佇列,
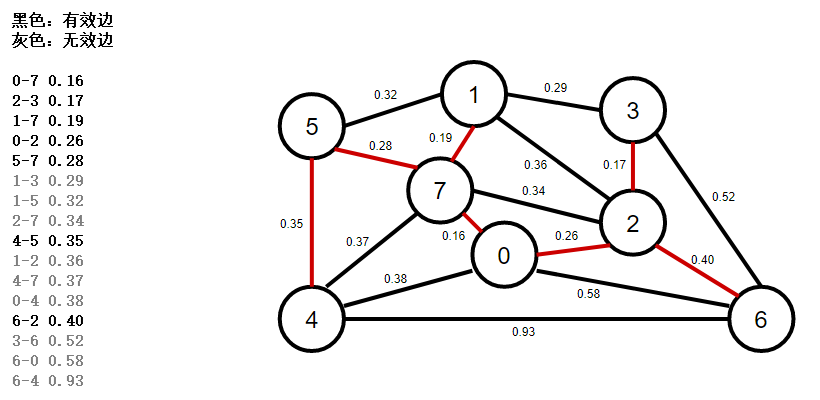
在添加了N個頂點(以及N-1條邊)之后,最小生成樹就完成了,優先佇列中余下的邊都是無效邊,不需要再去檢查他們,
該最小生成樹的權值為:0.16+0.19+0.26+0.17+0.28+0.35+0.40=1.81
6.5.3、演算法實作
【圖的結構】
【實作代碼】
public class KruskalMST {
private Queue<Edge> mst; //用于存盤最小生成樹的各個邊
private Queue<Edge> pq; //用于存盤對圖各邊按權重排序
private int[] eleAndGroup; //下標代表頂點,值代表哪個組
public KruskalMST(EdgeWeightedGraph G) {
this.mst = new LinkedList<>(); //初始化mst佇列
this.pq = new PriorityQueue<>(); //初始化pq佇列
this.eleAndGroup = new int[G.size()]; //初始化eleInGroup
//使用優先佇列pq按照權重值排序所有的邊
for (Edge e : G.edges()) {
pq.add(e);
}
//將G.size()個頂點分為G.size()個組
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i;
}
//從優先佇列中不停彈出最小邊,然后判斷
while (!pq.isEmpty() && (mst.size() < G.size() - 1)) {
Edge e = pq.poll(); //取出權重最小的那條邊
int v = e.either(); //獲取權重最小的那條邊的其中一個點
int w = e.other(v); //獲取權重最小的那條邊的另外一個點
int vGroup = eleAndGroup[v]; //獲取頂點v所在的分組,下標v代表頂點v,值代表頂點v所在的組號
int wGroup = eleAndGroup[w]; //獲取頂點w所在的分組,下標w代表頂點w,值代表頂點w所在的組號
if (vGroup == wGroup) { //如果頂點v和頂點w在同一分組中
continue; //如果在同一個組中,說明是無效邊,則應該直接跳過
}
//如果頂點v和頂點w不在同一分組中,說明這是一條有效的權重最小的邊
//為了方便接下來對無效邊的判斷,我們應該把頂點v和頂點w放到同一組
for (int i = 0; i < eleAndGroup.length; i++) {
if (eleAndGroup[i] == vGroup) {
eleAndGroup[i] = wGroup;
}
}
mst.add(e); //將權重最小的那條邊加入到最小生成樹中
}
}
//獲取最小生成樹的各邊
public Queue<Edge> edges() {
return mst;
}
//獲取最小生成樹的權重
public double weight() {
double s = 0.0D;
if (mst != null) {
for (Edge e : mst) {
s += e.weight();
}
}
return s;
}
}
【測驗代碼】
public class KruskalMSTTest {
public static void main(String[] args) {
EdgeWeightedGraph EWG = new EdgeWeightedGraph(8);
EWG.addEdge(new Edge(4, 5, 0.35));
EWG.addEdge(new Edge(4, 7, 0.37));
EWG.addEdge(new Edge(5, 7, 0.28));
EWG.addEdge(new Edge(0, 7, 0.16));
EWG.addEdge(new Edge(1, 5, 0.32));
EWG.addEdge(new Edge(0, 4, 0.38));
EWG.addEdge(new Edge(2, 3, 0.17));
EWG.addEdge(new Edge(1, 7, 0.19));
EWG.addEdge(new Edge(0, 2, 0.26));
EWG.addEdge(new Edge(1, 2, 0.36));
EWG.addEdge(new Edge(1, 3, 0.29));
EWG.addEdge(new Edge(2, 7, 0.34));
EWG.addEdge(new Edge(6, 2, 0.40));
EWG.addEdge(new Edge(3, 6, 0.52));
EWG.addEdge(new Edge(6, 0, 0.58));
EWG.addEdge(new Edge(6, 4, 0.93));
KruskalMST mst = new KruskalMST(EWG);
System.out.println("最小生成樹的各邊:");
for (Edge e : mst.edges()) {
System.out.println(e);
}
System.out.println("====================");
System.out.println("最小生成樹的權重:" + mst.weight());
}
}
【運行效果】
最小生成樹的各邊:
0-7 0.16
2-3 0.17
1-7 0.19
0-2 0.26
5-7 0.28
4-5 0.35
6-2 0.40
====================
最小生成樹的權重:1.81
第七章 加權有向圖
7.1、加權有向邊的實作
加權無向圖中的邊我們就不能簡單的使用v-w兩個頂點表示了,而必須要給邊關聯一個權重值,因此我們可以使用物件來描述一條邊,
public class DirectedEdge implements Comparable<DirectedEdge> {
private final int v; //當前邊的起點
private final int w; //當前邊的終點
private final double weight; //當前邊的權重
public DirectedEdge(int v, int w, double weight) {
this.v = v; //初始化起點
this.w = w; //初始化終點
this.weight = weight; //初始化權重
}
//獲取有向邊的起點
public int from() {
return v;
}
//獲取有向邊的終點
public int to() {
return w;
}
//獲取有向邊的權重
public double weight() {
return weight;
}
@Override
public int compareTo(DirectedEdge that) {
if (this.weight() > that.weight()) {
//如果當前邊的權重值比that邊的權重值大,回傳+1
return +1;
} else if (this.weight() < that.weight()) {
//如果當前邊的權重值比that邊的權重值小,回傳-1
return -1;
} else {
//如果當前邊的權重值和that邊的權重值一樣,回傳0
return 0;
}
}
@Override
public String toString() {
return String.format("%d->%d %.2f", v, w, weight);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
DirectedEdge that = (DirectedEdge) o;
return v == that.v && w == that.w && Double.compare(that.weight, weight) == 0;
}
@Override
public int hashCode() {
return Objects.hash(v, w, weight);
}
}
7.2、加權有向圖的實作
【圖的結構】
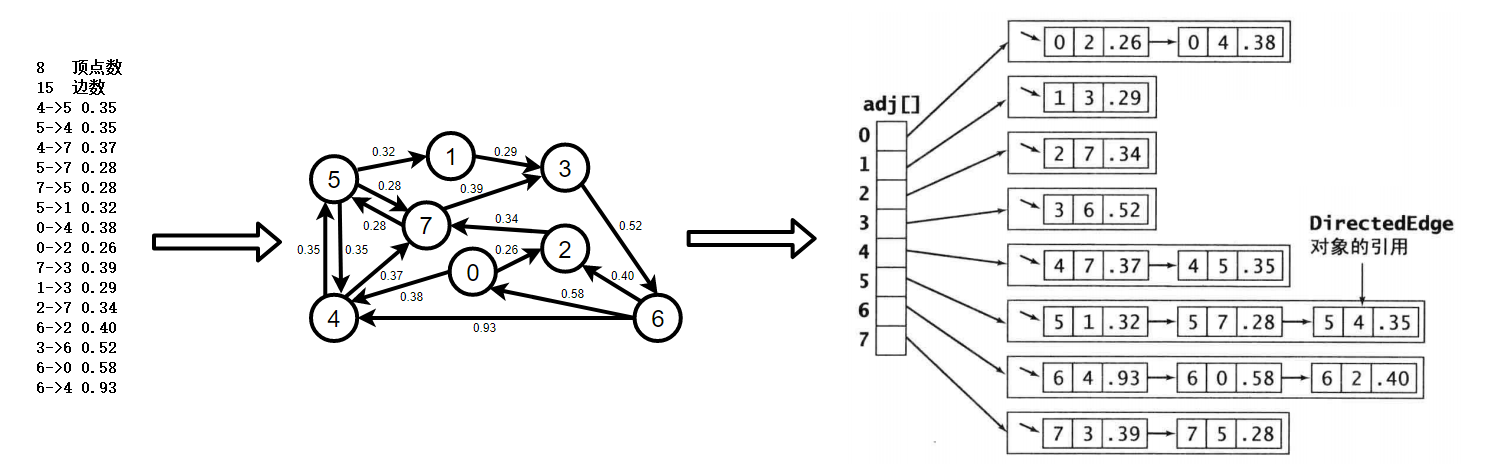
【實作代碼】
約定: N代表頂點數目,則N的取值范圍只能是0 ~ N-1,比如:N=3,則這三個頂點分別為:頂點0、頂點1、頂點2,如用其他值可能會造成adj下標越界,
public class EdgeWeightedDigraph {
private int N; //表示頂點數目
private int E; //表示邊的數目
private Queue<DirectedEdge>[] adj; //表示鄰接表
public EdgeWeightedDigraph(int n) {
this.N = n; //初始化頂點數目
this.E = 0; //初始化邊的數目
this.adj = new LinkedList[n]; //初始化鄰接表
for (int i = 0; i < adj.length; i++) {
adj[i] = new LinkedList<>();
}
}
//獲取頂點數目
public int size() {
return N;
}
//獲取邊的數目
public int edge() {
return E;
}
//添加一條邊
public void addEdge(DirectedEdge e) {
int v = e.from();
adj[v].add(e);
E++;
}
//洗掉一條邊
public void removeEdge(DirectedEdge e) {
int v = e.from();
adj[v].remove(e);
E--;
}
//獲取頂點v指出的所有的邊
public Queue<DirectedEdge> adj(int v) {
return adj[v];
}
//獲取加權有向圖的所有邊
public Queue<DirectedEdge> edges() {
Queue<DirectedEdge> allEdges = new LinkedList<>();
for (int v = 0; v < N; v++) {
for (DirectedEdge e : adj[v]) {
allEdges.add(e);
}
}
return allEdges;
}
}
【測驗代碼】
public class EdgeWeightedDigraphTest {
public static void main(String[] args) {
EdgeWeightedDigraph EWD = new EdgeWeightedDigraph(8);
EWD.addEdge(new DirectedEdge(4, 5, 0.35));
EWD.addEdge(new DirectedEdge(5, 4, 0.35));
EWD.addEdge(new DirectedEdge(4, 7, 0.37));
EWD.addEdge(new DirectedEdge(5, 7, 0.28));
EWD.addEdge(new DirectedEdge(7, 5, 0.28));
EWD.addEdge(new DirectedEdge(5, 1, 0.32));
EWD.addEdge(new DirectedEdge(0, 4, 0.38));
EWD.addEdge(new DirectedEdge(0, 2, 0.26));
EWD.addEdge(new DirectedEdge(7, 3, 0.39));
EWD.addEdge(new DirectedEdge(1, 3, 0.29));
EWD.addEdge(new DirectedEdge(2, 7, 0.34));
EWD.addEdge(new DirectedEdge(6, 2, 0.40));
EWD.addEdge(new DirectedEdge(3, 6, 0.52));
EWD.addEdge(new DirectedEdge(6, 0, 0.58));
EWD.addEdge(new DirectedEdge(6, 4, 0.93));
System.out.println("獲取EWD的大小:" + EWD.size());
System.out.println("獲取EWD的邊數:" + EWD.edge());
System.out.println("====================");
for (int v = 0; v < EWD.size(); v++) {
System.out.println("獲取和頂點" + v + "關聯的所有邊:" + EWD.adj(v));
}
System.out.println("====================");
for (DirectedEdge e : EWD.edges()) {
System.out.println(e);
}
}
}
【運行效果】
獲取EWD的大小:8
獲取EWD的邊數:15
====================
獲取和頂點0關聯的所有邊:[0->4 0.38, 0->2 0.26]
獲取和頂點1關聯的所有邊:[1->3 0.29]
獲取和頂點2關聯的所有邊:[2->7 0.34]
獲取和頂點3關聯的所有邊:[3->6 0.52]
獲取和頂點4關聯的所有邊:[4->5 0.35, 4->7 0.37]
獲取和頂點5關聯的所有邊:[5->4 0.35, 5->7 0.28, 5->1 0.32]
獲取和頂點6關聯的所有邊:[6->2 0.40, 6->0 0.58, 6->4 0.93]
獲取和頂點7關聯的所有邊:[7->5 0.28, 7->3 0.39]
====================
0->4 0.38
0->2 0.26
1->3 0.29
2->7 0.34
3->6 0.52
4->5 0.35
4->7 0.37
5->4 0.35
5->7 0.28
5->1 0.32
6->2 0.40
6->0 0.58
6->4 0.93
7->5 0.28
7->3 0.39
第八章 最短路徑樹
8.1、最短路徑樹的定義
有了加權有向圖之后,我們立刻就能聯想到實際生活中的使用場景,在一副地圖中,找到地點a與地點b之間的路徑,這條路徑可以是距離最短,也可以是時間最短,還也可以是費用最小等,如果我們把 距離/時間/費用 看做是成本,那么就需要找到地點a和地點b之間成本最小的路徑,這就是我們接下來要解決的問題,
最短路徑(Shortest Path,SP): 在一幅加權有向圖中,從頂點s到頂點t的最短路徑是所有從頂點s到頂點t的路徑中總權重最小的那條路徑,
最短路徑樹(Shortest Path Tree,SPT): 給定一幅加權有向圖和一個頂點s,以s為起點的一棵最短路徑樹是圖的一幅子圖,他包含頂點s以及從s可達的所有頂點,這棵有向樹的根結點為s,樹的每條路徑都是有向圖中的一條最短路徑,
8.2、最短路徑樹的約定
- 路徑具有方向性,最短路徑需要考慮到各條邊的方向,
- 權重不一定等價于距離,權重可以是距離、時間、花費等內容,權重最小指的是成本最低,
- 只考慮連通圖,一幅圖中并不是所有的頂點都是可達的,如果s和t不可達,那么他們之間也就不存在最短路徑, 為了簡化問題,這里只考慮連通圖,
- 最短路徑不一定是唯一的,從一個頂點到達另外一個頂點的權重最小的路徑可能會有很多條,這里只需要找出一條即可,
- 圖中不會出現負權重,負權重會使問題變得更加復雜,我們暫時假設邊的權重都是正的或零,
- 不存在平行邊和自環,為了避免歧義,我們假設圖中不存在平行邊和自環,
8.3、松弛技術
松弛(Relaxation)這個詞來源于生活,一條橡皮筋沿著兩個頂點的某條路徑緊緊展開,如果這兩個頂點之間的路徑不止一條,還有存在更短的路徑,那么把橡皮筋轉移到更短的路徑上,從而緩解了橡皮筋的壓力,橡皮筋就可以放松了,

松弛這種簡單的原理剛好可以用來計算最短路徑樹,在我們的API中,需要用到兩個成員變數edgeTo和distTo,分別存盤邊和權重,一開始給定一幅圖G和頂點s,我們只知道圖的邊以及這些邊的權重,其他的一無所知,此時初始化頂點s到頂點s的最短路徑的總權重disto[s]=0;頂點s到其他頂點的總權重默認為無窮大,隨著演算法的執行,不斷的使用松弛技術處理圖的邊和頂點,并按一定的條件更新edgeTo和distTo中的資料,最終就可以得到最短路徑樹,
邊的松弛:
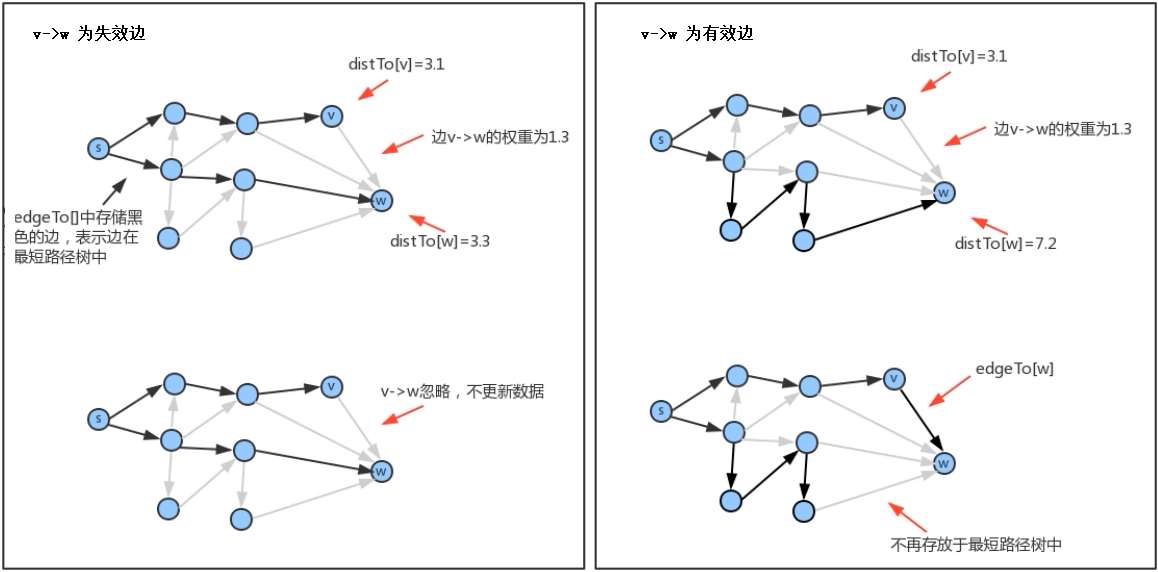
放松邊v->w意味著檢查從s到w的最短路徑是否先從s到v,然后再從v到w? 如果是,則v-w這條邊需要加入到最短路徑樹中,更新edgeTo和distTo中的內容:edgeTo[w]=表示v->w這條邊的DirectedEdge物件,distTo[w]=distTo[v]+v->w這條邊的權重; 如果不是,則忽略v->w這條邊,
邊的放松之后可能出現的兩種情況:一種情況是失效邊(下圖左邊的例子),不更新任何資料;另一種情況就是v->w就是到達w的最短路徑(下圖右邊的例子),
//邊的松弛
private void relax(DirectedEdge e) {
int v = e.from();
int w = e.to();
if (distTo(w) > distTo(v) + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
}
}
頂點的松弛:
頂點的松弛是基于邊的松弛完成的,只需要把某個頂點指出的所有邊松弛,那么該頂點就松弛完畢,例如要松弛頂點v,只需要遍歷v的鄰接表,把每一條邊都松弛,那么頂點v就松弛了,
//頂點的松弛
private void relax(EdgeWeightedDigraph G, int v) {
for (DirectedEdge e : G.adj(v)) {
relax(e);
}
}
拓展的資料:
以下資料是選讀資料,如果看不懂,則直接忽略,接著往下讀,并不影響你對程式的理解,如果能看懂,則能加深對程式的理解,

8.4、Dijstra演算法
8.4.1、演算法介紹
迪杰斯特拉(Dijkstra)演算法是由荷蘭計算機科學家狄克斯特拉于1959 年提出的,因此又叫狄克斯特拉演算法,是從一個頂點到其余各頂點的最短路徑演算法,解決的是有權圖中最短路徑問題,迪杰斯特拉演算法主要特點是從起始點開始,采用貪心演算法的策略,每次遍歷到始點距離最近且未訪問過的頂點的鄰接節點,直到擴展到終點為止,
8.4.2、演算法原理
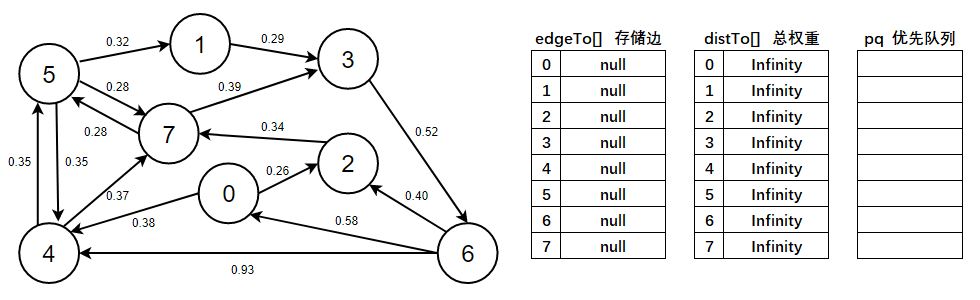
1、下圖是初始化狀態,我們只知道所有頂點和邊,現在定義以下變數:
- edgeTo[]陣列,索引代表頂點,值表示從頂點s到當前頂點的最短路徑上的最后一條邊,
- distTo[]陣列,索引代表頂點,值從頂點s到當前頂點的最短路徑的總權重,
- pq優先佇列,用于存放需要松弛的邊,并且會按照權重由小到大排序,每次彈出權重值最小的那條邊,
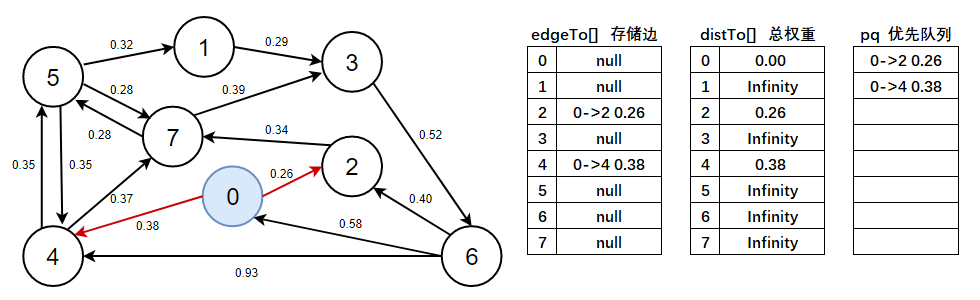
2、首先需要進行初始化,頂點0的初始化權重為0.00,然后再以頂點0開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(2) > distTo(0) + e.weight()=Infinity > 0.00 + 0.26,成立,說明0->2 0.26是有效邊,標為紅色, - 注意此處需看上圖資料:
distTo(4) > distTo(0) + e.weight()=Infinity > 0.00 + 0.38,成立,說明0->4 0.38是有效邊,標為紅色,
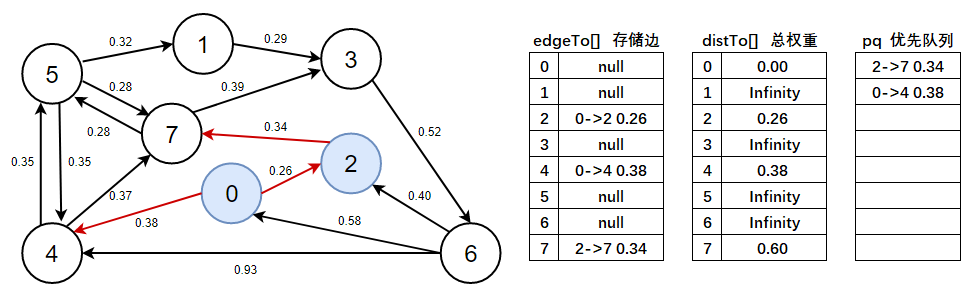
3、判斷優先佇列是否為空,不為空,彈出0->2 0.26這條邊,以頂點2開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(7) > distTo(2) + e.weight()=Infinity > 0.26 + 0.34,成立,說明2->7 0.34是有效邊,標為紅色,
4、判斷優先佇列是否為空,不為空,彈出2->7 0.34這條邊,以頂點7開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(5) > distTo(7) + e.weight()=Infinity > 0.60 + 0.28,成立,說明7->5 0.28是有效邊,標為紅色, - 注意此處需看上圖資料:
distTo(3) > distTo(7) + e.weight()=Infinity > 0.60 + 0.39,成立,說明7->3 0.39是有效邊,標為紅色,
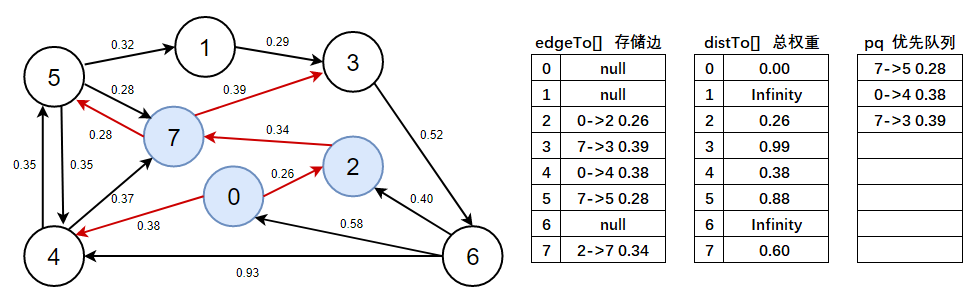
5、判斷優先佇列是否為空,不為空,彈出7->5 0.28這條邊,以頂點5開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(4) > distTo(5) + e.weight()=0.38 > 0.88 + 0.35,不成立,說明5->4 0.35是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(7) > distTo(5) + e.weight()=0.60 > 0.88 + 0.28,不成立,說明5->7 0.28是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(1) > distTo(5) + e.weight()=Infinity > 0.88 + 0.32,成立,說明5->1 0.32是有效邊,標為紅色,
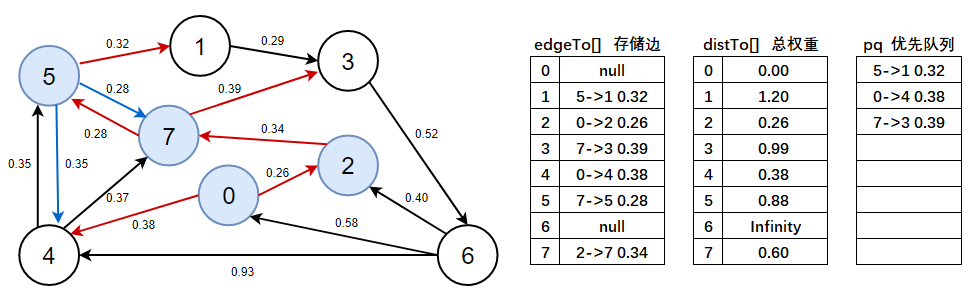
6、判斷優先佇列是否為空,不為空,彈出5->1 0.32這條邊,以頂點1開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(3) > distTo(1) + e.weight()=0.99 > 1.20 + 0.29,不成立,說明1->3 0.29是無效邊,標為藍色,
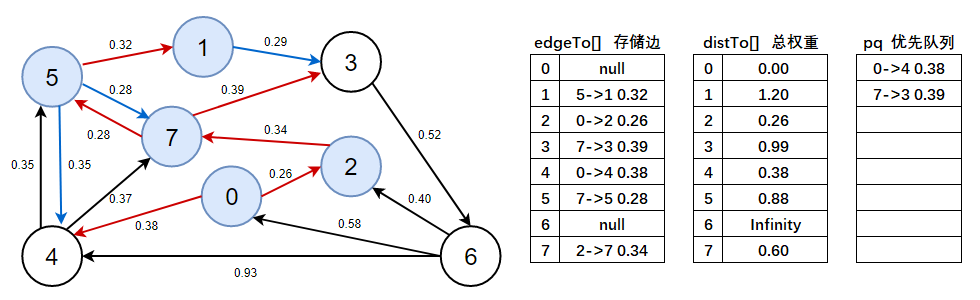
7、判斷優先佇列是否為空,不為空,彈出0->4 0.38這條邊,以頂點4開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
-
注意此處需看上圖資料:
distTo(5) > distTo(4) + e.weight()=0.88 > 0.38 + 0.35,成立,說明4->5 0.35是有效邊,7->5 0.28是無效邊, -
注意此處需看上圖資料:
distTo(7) > distTo(4) + e.weight()=0.60 > 0.38 + 0.37,不成立,說明4->7 0.37是無效邊,標為藍色,
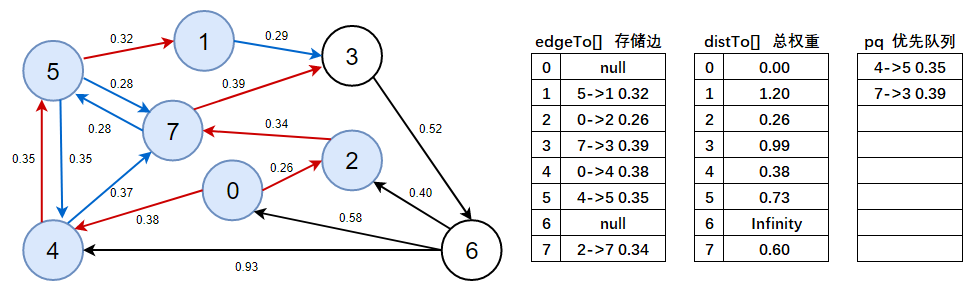
8、判斷優先佇列是否為空,不為空,彈出4->5 0.35這條邊,以頂點5開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(4) > distTo(5) + e.weight()=0.38 > 0.73 + 0.35,不成立,說明5->4 0.35是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(7) > distTo(5) + e.weight()=0.60 > 0.73 + 0.28,不成立,說明5->7 0.28是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(1) > distTo(5) + e.weight()=1.20 > 0.73 + 0.32,成立,說明5->1 0.32是有效邊,標為紅色,
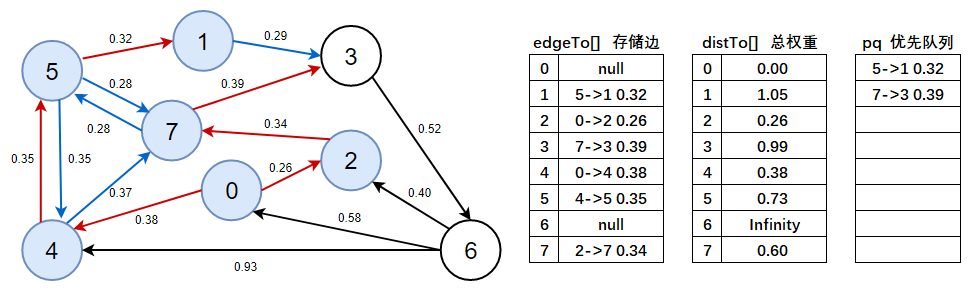
9、判斷優先佇列是否為空,不為空,彈出5->1 0.32這條邊,以頂點1開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(3) > distTo(1) + e.weight()=0.99 > 1.05 + 0.29,不成立,說明1->3 0.29是無效邊,標為藍色,
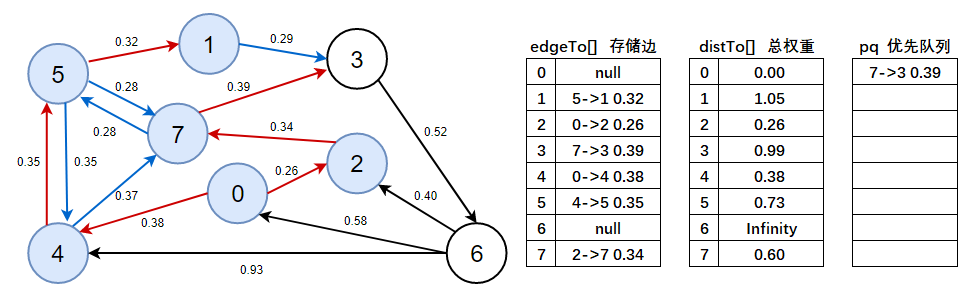
9、判斷優先佇列是否為空,不為空,彈出7->3 0.39這條邊,以頂點3開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(6) > distTo(3) + e.weight()=Infinity > 0.99 + 0.52,成立,說明3->6 0.52是有效邊,標為紅色,
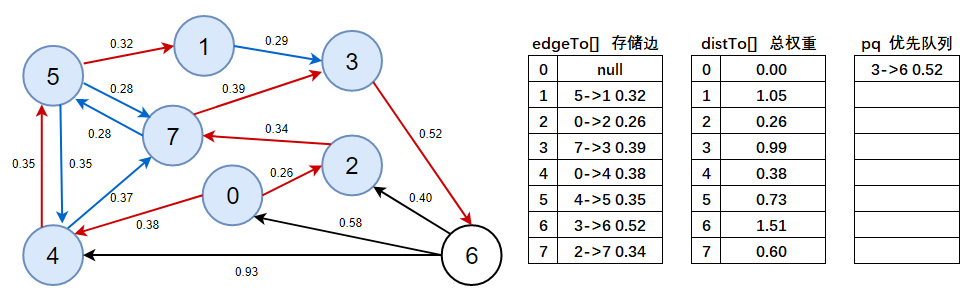
10、判斷優先佇列是否為空,不為空,彈出3->6 0.52這條邊,以頂點6開始進行頂點松弛,松弛后將有效邊加入到優先佇列中,
- 注意此處需看上圖資料:
distTo(2) > distTo(6) + e.weight()=0.26 > 1.51 + 0.40,不成立,說明6->0 0.40是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(0) > distTo(6) + e.weight()=0.00 > 1.51 + 0.58,不成立,說明6->2 0.58是無效邊,標為藍色, - 注意此處需看上圖資料:
distTo(4) > distTo(6) + e.weight()=0.38 > 1.51 + 0.93,不成立,說明6->4 0.93是無效邊,標為藍色,
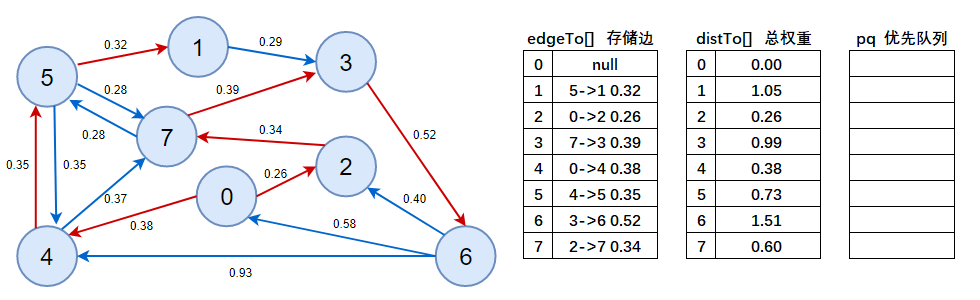
11、判斷優先佇列是否為空,此時為空,說明演算法結束,
8.4.3、演算法實作
【圖的結構】
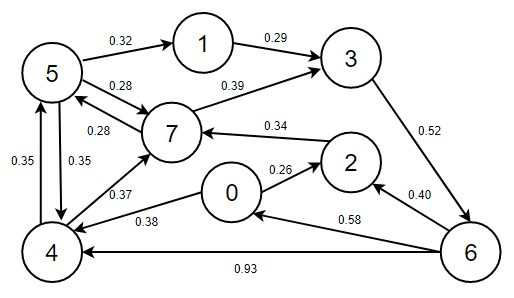
【實作代碼】
public class DijkstraSP {
private DirectedEdge[] edgeTo; //索引代表頂點,值表示從頂點s到當前頂點的最短路徑上的最后一條邊
private double[] distTo; //索引代表頂點,值從頂點s到當前頂點的最短路徑的總權重
private Queue<DirectedEdge> pq; //優先佇列用于存放有效邊
public DijkstraSP(EdgeWeightedDigraph G, int s) {
//初始化edgeTo
this.edgeTo = new DirectedEdge[G.size()];
//初始化distTo
this.distTo = new double[G.size()];
for (int i = 0; i < distTo.length; i++) {
distTo[i] = Double.POSITIVE_INFINITY;
}
//初始化pq
this.pq = new PriorityQueue<>();
//默認讓頂點s進入到最短路徑樹中
distTo[s] = 0.0D;
relax(G, s);
//遍歷pq
while (!pq.isEmpty()) {
relax(G, pq.poll().to());
}
}
//頂點的松弛
private void relax(EdgeWeightedDigraph G, int v) {
for (DirectedEdge e : G.adj(v)) {
int w = e.to();
if (distTo(w) > distTo(v) + e.weight()) {
distTo[w] = distTo[v] + e.weight();
edgeTo[w] = e;
pq.add(e);
}
}
}
//獲取從頂點s到頂點v的最短路徑的總權重
public double distTo(int v) {
return distTo[v];
}
//判斷從頂點s到頂點v是否可達
public boolean hasPathTo(int v) {
return distTo[v] < Double.POSITIVE_INFINITY;
}
//找出從起點s到頂點v的路徑
public Stack<DirectedEdge> pathTo(int v) {
if (!hasPathTo(v)) {
return null;
}
Stack<DirectedEdge> path = new Stack<>();
for (DirectedEdge e = edgeTo[v]; e != null; e = edgeTo[e.from()]) {
path.push(e);
}
return path;
}
}
【測驗代碼】
public class DijkstraSPTest {
public static void main(String[] args) {
int s = 0;
int n = 8;
EdgeWeightedDigraph EWD = new EdgeWeightedDigraph(n);
EWD.addEdge(new DirectedEdge(4, 5, 0.35));
EWD.addEdge(new DirectedEdge(5, 4, 0.35));
EWD.addEdge(new DirectedEdge(4, 7, 0.37));
EWD.addEdge(new DirectedEdge(5, 7, 0.28));
EWD.addEdge(new DirectedEdge(7, 5, 0.28));
EWD.addEdge(new DirectedEdge(5, 1, 0.32));
EWD.addEdge(new DirectedEdge(0, 4, 0.38));
EWD.addEdge(new DirectedEdge(0, 2, 0.26));
EWD.addEdge(new DirectedEdge(7, 3, 0.39));
EWD.addEdge(new DirectedEdge(1, 3, 0.29));
EWD.addEdge(new DirectedEdge(2, 7, 0.34));
EWD.addEdge(new DirectedEdge(6, 2, 0.40));
EWD.addEdge(new DirectedEdge(3, 6, 0.52));
EWD.addEdge(new DirectedEdge(6, 0, 0.58));
EWD.addEdge(new DirectedEdge(6, 4, 0.93));
DijkstraSP sp = new DijkstraSP(EWD, s);
for (int v = 0; v < n; v++) {
if (sp.hasPathTo(v)) {
String distTo = String.format("%.2f", sp.distTo(v));
System.out.println("頂點" + s + "到頂點" + v + "的最短路徑樹如下,最短路徑的總權重為:" + distTo);
Stack<DirectedEdge> stack = sp.pathTo(v);
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
System.out.println();
}
}
}
}
【運行效果】
頂點0到頂點0的最短路徑樹如下,最短路徑的總權重為:0.00
頂點0到頂點1的最短路徑樹如下,最短路徑的總權重為:1.05
0->4 0.38
4->5 0.35
5->1 0.32
頂點0到頂點2的最短路徑樹如下,最短路徑的總權重為:0.26
0->2 0.26
頂點0到頂點3的最短路徑樹如下,最短路徑的總權重為:0.99
0->2 0.26
2->7 0.34
7->3 0.39
頂點0到頂點4的最短路徑樹如下,最短路徑的總權重為:0.38
0->4 0.38
頂點0到頂點5的最短路徑樹如下,最短路徑的總權重為:0.73
0->4 0.38
4->5 0.35
頂點0到頂點6的最短路徑樹如下,最短路徑的總權重為:1.51
0->2 0.26
2->7 0.34
7->3 0.39
3->6 0.52
頂點0到頂點7的最短路徑樹如下,最短路徑的總權重為:0.60
0->2 0.26
2->7 0.34
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271405.html
標籤:其他
上一篇:Oracle 實驗:建立和配置Oracle資料庫服務器
下一篇:模板初識