首先是測驗前準備
整體思路:生成1000個隨機的字串,如果字串相同長度,就按字典序從小到大,否則,按照字串長度從小到大排序,對于每一種方法,都用clock()函式記錄總體時間,最后進行匯總
首先是代碼準備:
#include<iostream>
#include<string>
#include<vector>
#include<time.h>
#include<algorithm>
#include<map>
#include "排序方法大全.h"
using namespace std;
const int MAXN = 1000;
const int MAXW = 100;
//隨機給一組串長1-100的隨機小寫字母字串,先按照串長排序,如果串長相同,則按照字典序排序
#pragma once
bool cmp(String s1, String s2);
void buddle_sort(vector<String> s);
void select_sort(vector<String> s);
void insert_sort(vector<String> s);
void insert_sort(vector<String>& s, int start, int space);
void Shell_sort(vector<String> s);
void quick_sort(vector<String>& s, int start, int end, String key);
void quick(vector<String> s);
void merge(vector<String>& s, int s1, int len1, int s2, int len2);
void merge_sort(vector<String>& s, int start, int end);
void merge_sort(vector<String> s);
void heap_sort(vector<String>& s);
void bucket_sort(vector<String>& s);
void divide_bucket(vector<String> s);
int main()
{
//亂數種子替換
srand(time(0));
vector<String> s(MAXN);
//測驗冒泡排序
buddle_sort(s);
//測驗選擇排序
select_sort(s);
//測驗插入排序
insert_sort(s);
//測驗希爾排序(分治法)
Shell_sort(s);
//測驗快速排序(遞回,二分)
quick(s);
//測驗歸并排序
merge_sort(s);
//測驗堆排序
heap_sort(s);
//測驗桶排序
divide_bucket(s);
//測驗STL:sort
Sort(s);
system("pause");
}
構造String類,它是由string字串和一個int計算長度的構成,
String建構式里面隨機賦予了長度在1-100的隨機字符的字串給str
再重構3個運算子 > < ==
struct String
{
int length;
string str;
//冒泡排序
String()
{
length = rand() % 100 + 1;
for (int i = 0; i <= length - 1; i++)
{
char c = rand() % 26 + 'a';
char s[2] = { rand() % 26 + 'a' };
str.append(s);
}
}
String(int x)
{
length = 0;
str = "\0";
}
bool operator>(String str)
{
return (this->length == str.length) ? (this->str > str.str) : (this->length > str.length);
}
bool operator<(String str)
{
return !((this->length == str.length) ? (this->str > str.str) : (this->length > str.length));
}
bool operator==(String str)
{
return ((this->length == str.length) && (this->str == str.str));
}
};
1.冒泡排序
void buddle_sort(vector<String>s)
{
int len = s.size();
String temp(1);
time_t time1 = clock();
bool isswap = 0;
for (int i = 0; i < len - 1; i++)
{
//每次排好序以后,最大的項肯定是在最右邊,所以j只需要遍歷到len-i-1就可以
isswap = 0;
for (int j = 0; j < len - 1 - i; j++)
{
//先按照長度排序
if (s[j].length > s[j + 1].length)
{
isswap = 1;
temp = s[j + 1];
s[j + 1] = s[j];
s[j] = temp;
}
//再按照字典序排序
else if (s[j].length == s[j + 1].length)
{
if (s[j].str > s[j + 1].str)
{
isswap = 1;
temp = s[j + 1];
s[j + 1] = s[j];
s[j] = temp;
}
}
}
if (!isswap)//全部都排好了沒有交換
break;
}
time_t time2 = clock();
cout << "冒泡排序的時間為" << time2 - time1 << "ms" << endl;
}
2.選擇排序
void select_sort(vector<String>s)
{
int len = s.size();
time_t time1 = clock();
String temp;
for (int i = 0; i <= len - 1; i++)
{
//暫定最小值是第i個元素
String min = s[i];
for (int j = i; j <= len - 1; j++)
{
if (min.length > s[j].length)
{
temp = min;
min = s[j];
s[j] = temp;
}
else if (min.length == s[j].length)
{
if (min.str > s[j].str)
{
temp = min;
min = s[j];
s[j] = temp;
}
}
}
s[i] = min;//從i以后選出一個最小的,放到i位置上
}
time_t time2 = clock();
cout << "選擇排序的時間為" << time2 - time1 << "ms" << endl;
}
3 插入排序
void insert_sort(vector<String>s)
{
int len = s.size();
time_t time1 = clock();
int j;
for (int i = 1; i <= len - 1; i++)
{
String temp = s[i];//空出第i個位置
for (j = i - 1; (s[j].length == temp.length) ? (s[j].str > temp.str) : (s[j].length > temp.length) && j - 1 >= 0; j--)//往左邊找,直到找到一個元素它小于或者等于該元素
{
s[j + 1] = s[j];
if (j - 1 < 0)
break;
}
//停下的位置的后一個是插入的位置,當前的j位置有一個元素
s[j + 1] = temp;
}
time_t time2 = clock();
cout << "插入排序的時間為" << time2 - time1 << "ms" << endl;//時間主要節省在不用交換元素上
}
4.希爾排序
這里重構了插入排序,以傳入步長和起始位置
//插入排序重構,start代表分組的位置,space代表步長(間距)
void insert_sort(vector<String>& s, int start, int space)
{
int len = s.size();
for (int i = start + space; i <= len - 1; i += space)
{
String temp = s[i];
int j = i - space;
for (j = i - space; (s[j].length == temp.length) ? (s[j].str > temp.str) : (s[j].length > temp.length); j -= space)
{
s[j + space] = s[j];
if (j - space < 0)
break;
}
s[j + space] = temp;
}
}
void Shell_sort(vector<String>s)
{
int len = s.size();
int space = len / 2;
//分組,最開始的分組為陣列長度的一半,每次
time_t time1 = clock();
for (; space >= 1; space /= 2)
{
//一共有space組,每一組的起始編號為i
for (int i = 0; i <= space - 1; i++)
{
insert_sort(s, i, space);//將分好的組進行插入排序
}
}
time_t time2 = clock();
cout << "希爾排序的時間為" << time2 - time1 << "ms" << endl;
}
5.快速排序
因為有遞回,所以選擇了quick函式作為介面,方便計算時間(這里兩個-2代表第一次初始化,但其實可以在quick函式里面初始化的,不想改了o(╥﹏╥)o)
void quick_sort(vector<String>& s, int start = -2, int end = -2, String key = 0)
{
start = (start == -2) ? (0) : (start);
end = (end == -2) ? (s.size() - 1) : (end);
int start0 = start, end0 = end;
if (start >= end)
{
return;
}
key = s[start];
while (start < end)
{
while (start < end && (s[end].length == key.length) ? (s[end].str > key.str) : (s[end].length > key.length))//end邏輯上要比key大
end--;
s[start] = s[end];
while (start < end && ((s[start].length == key.length) ? (s[start].str <= key.str) : (s[start].length <= key.length)))//start邏輯上要比key小
start++;
s[end] = s[start];
}
s[start] = key;
quick_sort(s, start0, start - 1);
quick_sort(s, start + 1, end0);
}
void quick(vector<String>s)
{
time_t time1 = clock();
quick_sort(s);
time_t time2 = clock();
cout << "快速排序的時間為" << time2 - time1 << "ms" << endl;
}
6.歸并排序(真的好難)
首先定義了一個介面(因為要用到遞回嘛),然后在merge_sort函式里面先分割陣列,最后在歸并,歸并卸載了merge里面了,總體思路就這樣吧
void merge(vector<String>& s, int s1, int len1, int s2, int len2)
{
//分割陣列
int mid1 = s1 + len1 / 2;
int mid2 = s2 + len2 / 2;
int i1 = s1, i2 = s2, i = s1;
int flag1 = 1, flag2 = 1;
vector<String>temp;
for (; i <= s1 + len1 + len2 - 1; i++)
{
//如果左邊那個有序陣列的第i1個小于等于右邊有序陣列的第i2個
if ((((s[i1].length == s[i2].length) ? (s[i1].str <= s[i2].str) : (s[i1].length <= s[i2].length)) && flag1) || (flag2 == 0 && flag1 != 0))
{
//歸并i1
temp.push_back(s[i1]);
if (i1 + 1 <= s1 + len1 - 1) i1++;
else { flag1 = 0; }
}
else if ((((s[i1].length == s[i2].length) ? (s[i1].str > s[i2].str) : (s[i1].length > s[i2].length)) && flag2) || (flag1 == 0 && flag2))
{
//歸并i2
temp.push_back(s[i2]);
if (i2 + 1 <= s2 + len2 - 1) i2++;
else { flag2 = 0; }
}
}
for (i = s1; i <= s1 + len1 + len2 - 1; i++)
s[i] = temp[i - s1];
}
void merge_sort(vector<String>& s, int start, int end)
{
int len = s.size();
start = (start == -2) ? (0) : (start);
end = (end == -2) ? (s.size() - 1) : (end);
if (start < end)
{
int mid = (start + end) / 2;
merge_sort(s, start, mid);
merge_sort(s, mid + 1, end);
merge(s, start, (mid - start + 1), mid + 1, (end - mid));
}
else
{
return;
}
}
void merge_sort(vector<String>s)
{
time_t time1 = clock();
merge_sort(s, -2, -2);
time_t time2 = clock();
cout << "歸并排序的時間為" << time2 - time1 << "ms" << endl;
}
7.堆排序
首先定義了一個最小堆Heap類,實作最小堆的構造和取最頂點
struct Heap
{
//將vector陣列建立成最小堆
Heap(vector<String>& s)
{
int len = s.size();
for (int i = 0; i <= len - 1; i++)
{
data[size + 1] = s[i];
int index = ++size;
for (; index > 1; index /= 2)
{
if ((data[index / 2].length == data[index].length) ? (data[index / 2].str > data[index].str) : (data[index / 2].length > data[index].length))
{
String temp = data[index / 2];
data[index / 2] = data[index];
data[index] = temp;
}
}
}
}
String pop()
{
if (size)
{
String return_x = data[1];
data[1] = data[size--];
int index = 1;
for (; index * 2 <= size;)
{
if (index * 2 == size)//只有左兒子
{
if (data[index] > data[index * 2])
{
swap(data[index], data[index * 2]);
index = index * 2;
break;
}
else
{
break;
}
}
else if (data[index] > data[index * 2] || data[index] > data[index * 2 + 1])
{
if (data[index * 2] > data[index * 2 + 1])
{
swap(data[index], data[index * 2 + 1]);
index = index * 2 + 1;
}
else
{
swap(data[index], data[index * 2]);
index = index * 2;
}
}
else
break;
}
return return_x;
}
else
{
return 0;
}
}
String data[MAXN + 1] = { 0 };
int size = 0;
};
然后借助Heap類進行堆排序
void heap_sort(vector<String>& s)
{
time_t time1 = clock();
Heap* heap = new Heap(s);
for (int i = 0; i <= heap->size - 1; i++)
{
s[i] = heap->pop();
}
time_t time2 = clock();
cout << "堆排序的時間為" << time2 - time1 << "ms" << endl;
}
8.桶排序
設定字串長length為一個桶,每+1為一個桶,用vector動態陣列存盤節省空間
void bucket_sort(vector<String>& s)
{
if (s.size())
quick_sort(s);
}
void divide_bucket(vector<String>s)
{
time_t time1 = clock();
int len = s.size();
vector<vector<String> > bucket(s.size() + 1);
for (int i = 0; i <= len - 1; i++)
{
//把s[i]放入指定的桶里面
bucket[s[i].length].push_back(s[i]);
}
for (int i = 0; i <= len - 1; i++)
{
bucket_sort(bucket[i]);
}
int i = 1;
s.clear();
for (int i = 1; i <= len; i++)
{
for (int j = 0; j <= (int)bucket[i].size() - 1; j++)
{
s.push_back(bucket[i][j]);
}
}
time_t time2 = clock();
cout << "桶排序的時間為" << time2 - time1 << "ms" << endl;
}
附:最后是stl里面的sort(這里采用的是降序)
bool cmp(String s1, String s2)
{
if ((s1.length == s2.length) ? (s1.str > s2.str) : (s1.length > s2.length))
{
return 1;//該交換了
}
else
{
return 0;//不交換
}
}
void Sort(vector<String>s)
{
time_t time1 = clock();
sort(s.begin(), s.end(), cmp);
time_t time2 = clock();
cout << "STL: sort時間為:" << time2 - time1 <<"ms"<< endl;
}
最終結果如下:
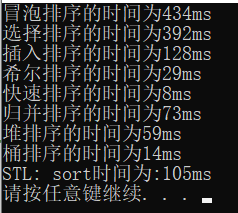
可能略微有不準確的地方,因為其中運用的運算子和函式呼叫不完全相同
僅供參考~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271412.html
標籤:其他
上一篇:聊聊Java的例外機制問題