一、Ribbon簡介
? Ribbon是Netflix發布的負載均衡器,有助于控制Http和Tcp的客戶端行為,配置Ribbon服務提供者地址后,Ribbon就可以基于某種負載均衡演算法,自動地去幫助服務者請求,Ribbon默認提供了幾種負載均衡演算法,例如輪詢、隨機等,我們也可以自己定義自己的負載均衡演算法,
? 在SpringCloud中,當Ribbon與Eureka配合使用時,Ribbon可自動從Eureka Server獲取服務提供者地址串列,并基于負載均衡演算法,請求其中一個服務提供者實體,展示了Ribbon與Eureka配合使用時的架構,
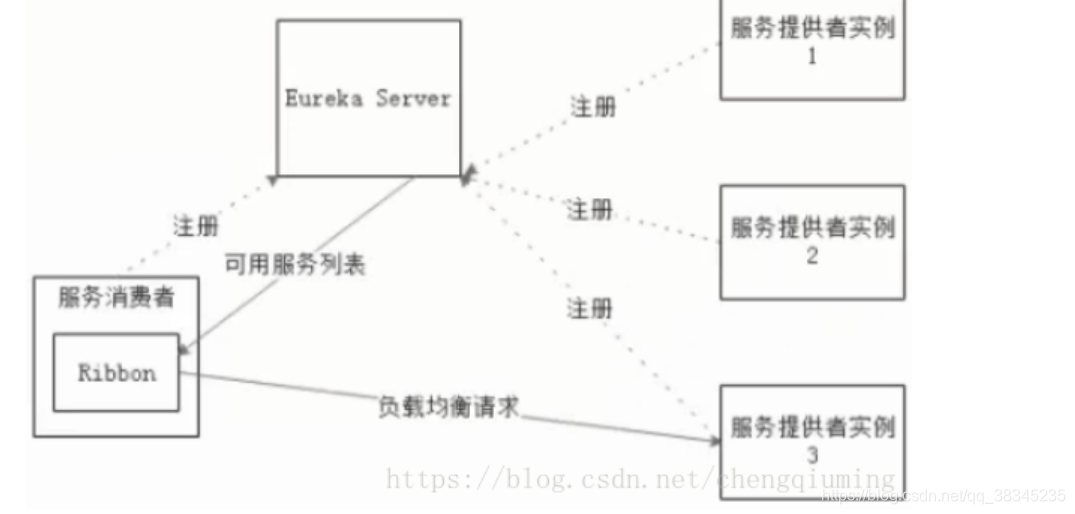
二、Ribbon的使用
首先需要去搭建一個本地的 Eureka 注冊中心具體流程省略:

其次就是去搭建兩個Eureka Client,流程省略:

讓它們注冊到本地注冊中心當中,

然后開始負載均衡的配置,因為Eureka Client包當中已經引入Ribbon的相關依賴了,所以不需要新加入Ribbon依賴
在我們服務呼叫方也就TRADE-ADMIN中,在Application.class中去添加注解@LoadBlanced,不加就是不使用負載均衡,那么它呼叫服務后,就可能默認優先在第一個埠,偶爾會切換第二個埠,
然后用@feign就可以呼叫我們的服務了,由于這里Ribbon沒有配置,Ribbon就會根據它的默認負載均衡演算法從我們的服務串列中找到合適的埠去呼叫服務了
測驗結果如下:
TRADE-ADMIN 服務利用feign去遠程呼叫 TRADE-CLIENT 服務,以埠號作為標記,發出請求:

TRADE-ADMIN 請求第一次的回傳:
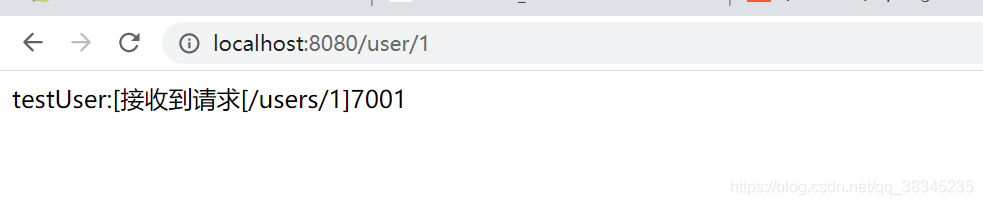
TRADE-ADMIN 請求第二次的回傳:
三、Ribbon的負債均衡的策略
什么是負載?
? 負載是linux機器的一個重要指標,直觀的反應了機器的狀態,
? 在UNIX系統當中,系統負載是對當前CPU作業量的度量,被定義為特定時間間隔內運行的佇列中的平均執行緒數,Load average表示機器一段時間內的平均Load,這個值越低越好,負載過高會導致機器無法處理其他請求及,甚至導致死機,
什么是負載均衡?
? 負載均衡是由多臺服務器以對稱的方式組成一個服務器集合,每臺服務器都具有等價的地位,都可以單獨對外供應效力而無須其他服務器的輔助,經過某種負載分管技術,將外部發送來的央求均勻分配到對稱結構中的某一臺服務器上,而接收到央求的服務器獨登時回應客戶的央求,均衡負載可以平均分配客戶央求到服務器列陣,籍此供應快速獲取重要資料,解決很多并發訪問效力問題,這種群集技術可以用最少的出資取得接近于大型主機的性能,
負載均衡的策略?
1.輪詢
每個請求按時間順序逐一分配到不同的后端服務器,如果后端服務器down掉,能自動剔除,
2.指定權重
指定輪詢幾率,weight和訪問比率成正比,用于后端服務器性能不均的情況,
3.IP系結 (ip hash)
每個請求按訪問ip的hash結果分配,這樣每個訪客固定訪問一個后端服務器,可以解決session的問題,
4.fair(第三方)
按后端服務器的回應時間來分配請求,回應時間短的優先分配,
5.url_hash(第三方)
按訪問url的hash結果來分配請求,使每個url定向到同一個后端服務器,后端服務器為快取時比較有效,
Ribbon負載均衡策略
? 1.RandomRule 隨機策略 :隨機選擇server
? 原理:通過Random類,隨機從可用服務器串列取一個
? 優勢:適用于集群中各個節點提供服務能力等同且無狀態的場景,
? 缺點:不關心服務端負載,服務端處理能力的波動可能造成堵塞
? 測驗使用改策略效果圖:
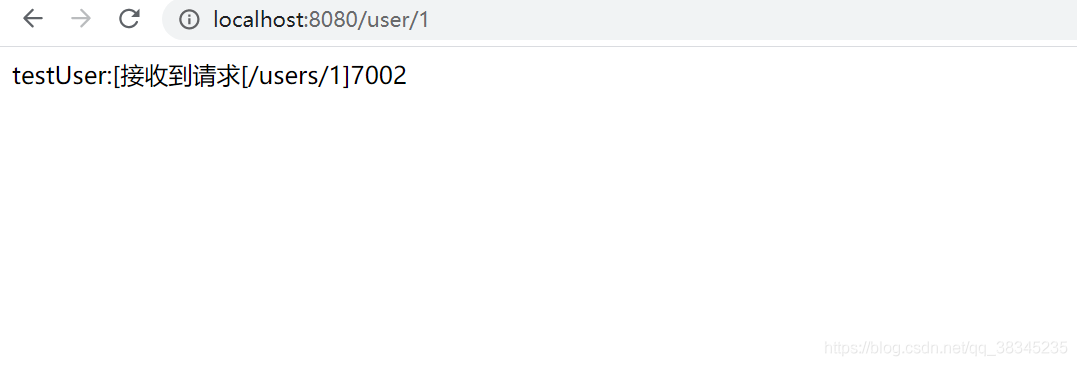
? 測驗準備了注冊了三個同名服務,以埠號不同作為標識依據,
? 組態檔修改 RandomRule策略模式
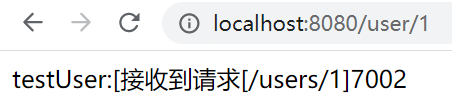
? 第一次呼叫:
? 
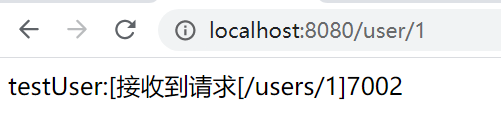
? 第二次呼叫:
? 
? 第三次呼叫:
? 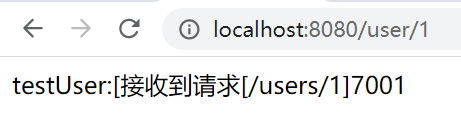
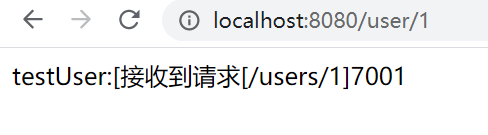
? 從測驗結果可以看出,7002埠的服務被讀取了兩次,而且分配的三個埠當前只被讀取了7001,7002,7003埠沒有被讀到,隨機策略模式是隨機去讀取一個可用服務,可能讀取程序中會讀取到重復的埠,可能會有一個埠讀不到,
? 2.RoundRobinRule 輪詢策略: 從服務端串列里面回圈獲取
? 原理:維護一個AtomicInteger變數,和服務器總數求余得到index,取 服務器串列第index的值
? 優勢:適用于集群中各個節點提供服務能力等同且無狀態的場景,
? 缺點:不關心服務端負載,服務端處理能力的波動可能造成堵塞,
? 測驗使用改策略效果圖:
? 測驗準備了注冊了三個同名提供方服務,以埠號不同作為標識依據,
? 組態檔修改 RoundRobinRule 策略模式
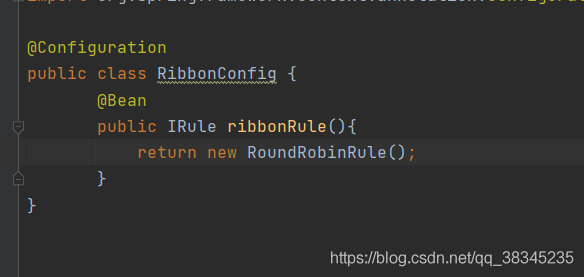
第一次呼叫:
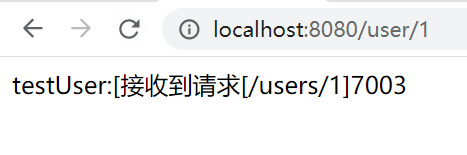
第二次呼叫:
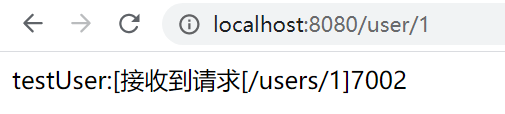
第三次呼叫:
?
? 3.WeightedResponseTimeRule 回應時間加權重策略**:根據每個服務的回應時間設定權重,回應時間越長,所占權重越少,
? **原理:**維護一個volatile List型別的權重串列,里面保存了根據當前服務回應時間計算出的權重值,該串列默認每30秒重繪一次,采用輪詢來獲取服務,
? **優勢:**允許各節點服務能力不相等并且允許波動,
? 測驗使用改策略效果圖:
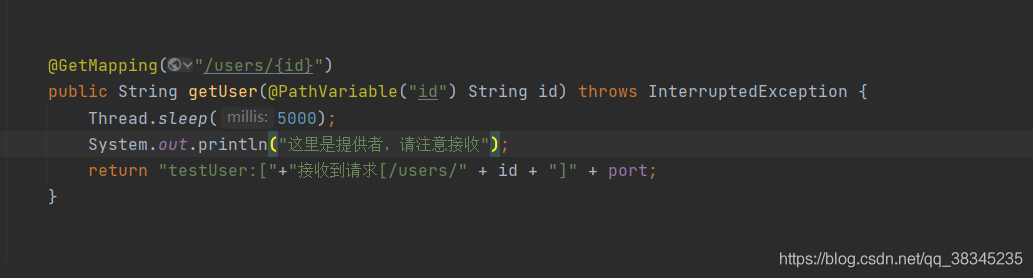
? 在 服務二 和 服務三 中設定Thread.sleep模擬介面回應時間,
TRADE-CLIENT2
TRADE-CLENT3
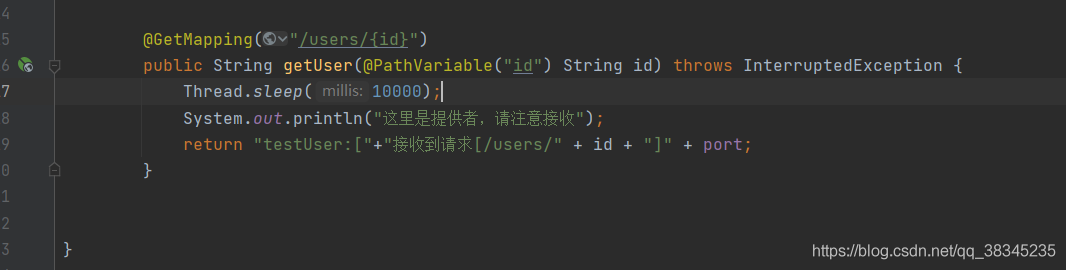
TRADE-CLENT1不設定執行緒延時,可以查出每個埠的權重,按逆序排列,可見會多次讀取7001埠,但是其實,隨著時間權重的疊加,讀取的概率也會疊加,效果不是很明顯,
? 4.RetryRule 重試策略: 鑒于IRule可以級聯,此RetryRule類允許向現有規則添加重試邏輯,(和負載均衡無關)
? **原理:**在指定時間(默認500ms)內不斷的呼叫指定路由策略(默認值:RoundRobinRule)獲取服務,直到獲取成功,
? **優勢:**具體適用場景同指定的路由策略,只是添加了重試功能
? 測驗使用改策略效果圖:
? 測驗準備了注冊了三個同名提供方服務,以埠號不同作為標識依據,
? 組態檔修改 RetryRule 策略模式
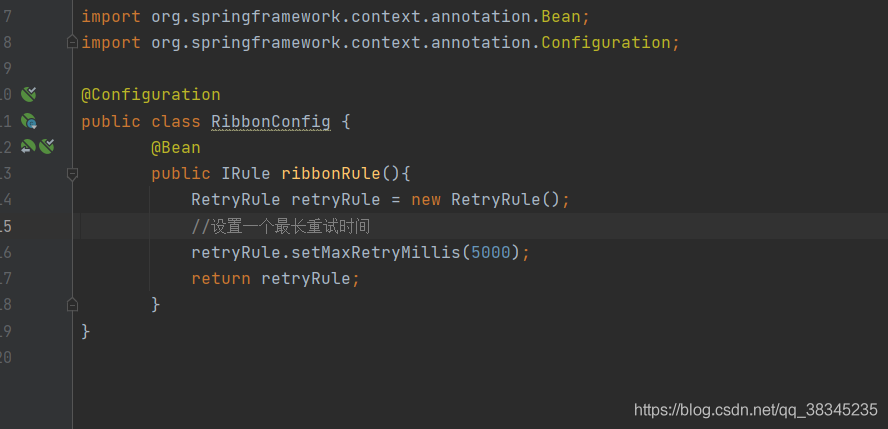
測驗結果:
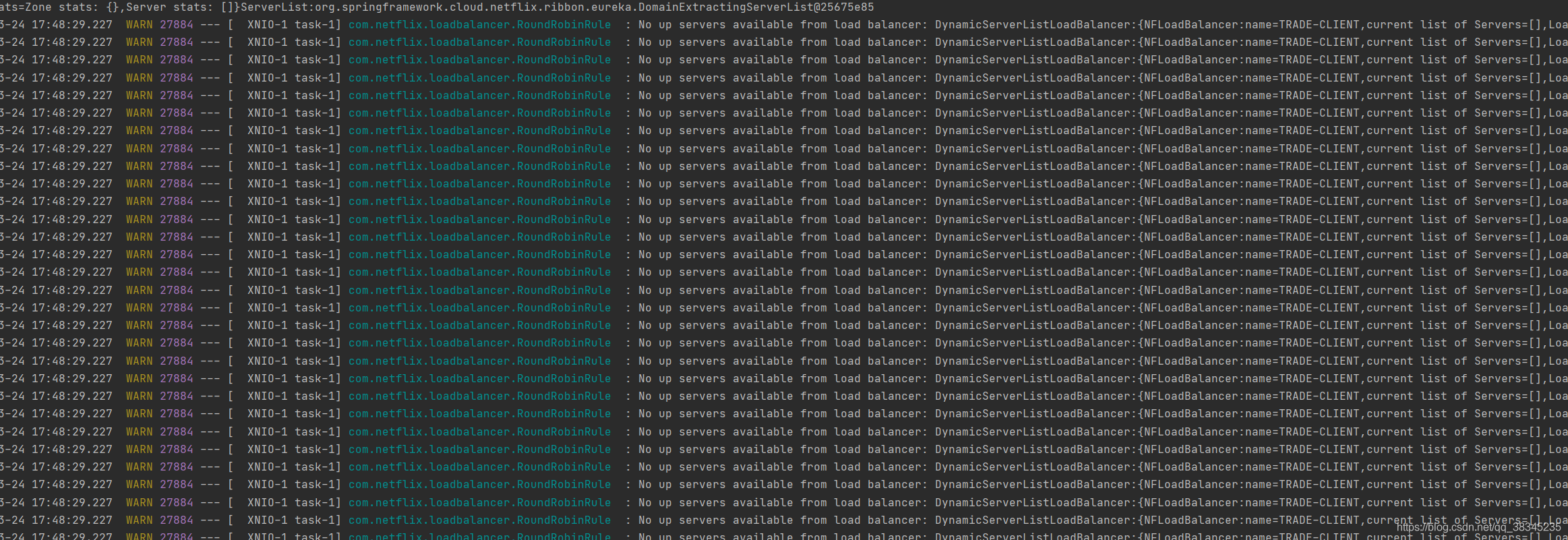
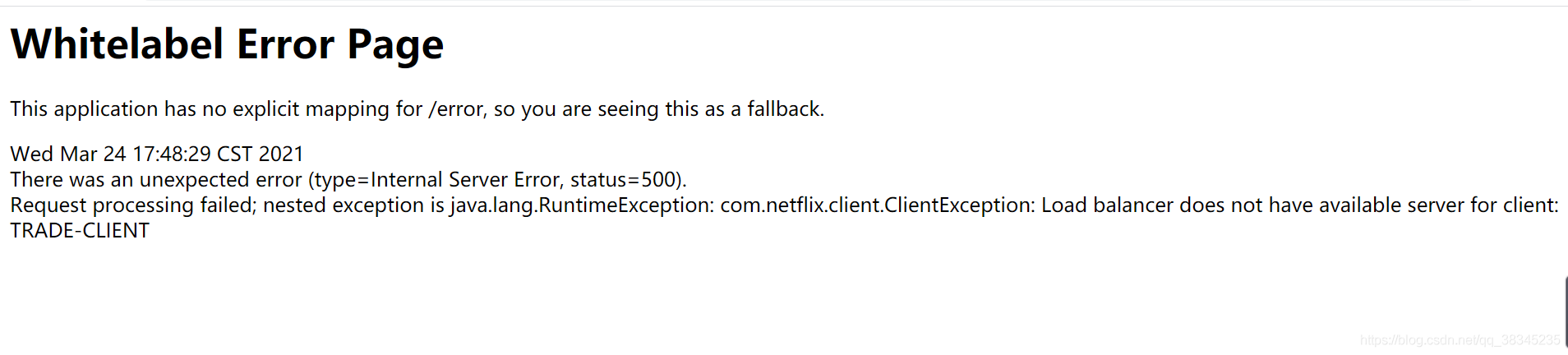
可以看到這個請求會被重試5秒之后,再回傳一個錯誤頁面,然后依據輪詢的方式依次訪問下一個埠,
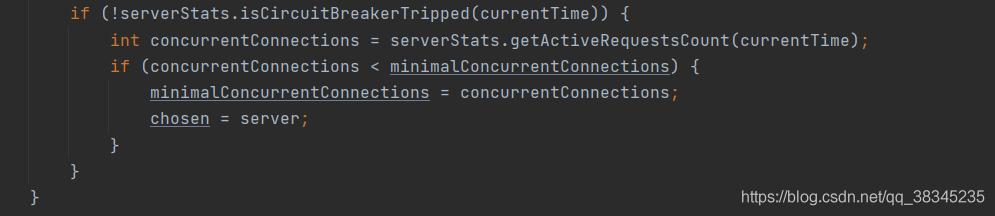
? 5.BestAvailableRule 最低并發策略: 跳過具有“跳閘”斷路器的服務器的規則,并選擇具有最低并發請求的服務器,
? **優勢:**此規則通常應與ServerListSubsetFilter一起使用,后者對規則可見的服務器設定限制, 這確保了它只需要在少量服務器中找到最小的并發請求, 此外,每個客戶端將獲得一個隨機的服務器串列,避免了大量客戶端選擇一個具有最低并發請求的服務器并立即被淹沒的問題,
? 沒條件測驗家里窮,核心CORE:
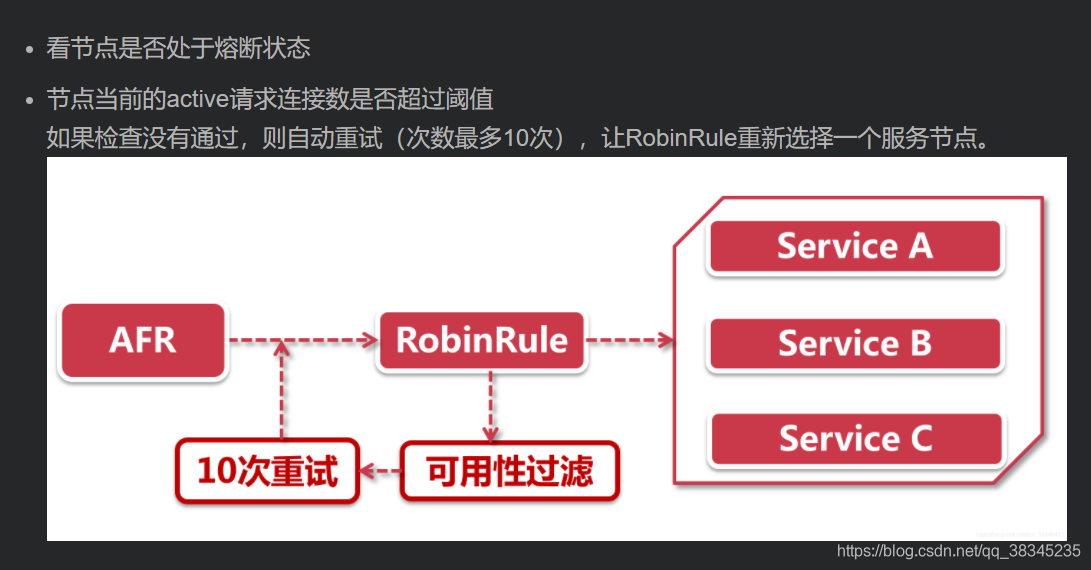
? 6.AvailabilityFilteringRule 可用過濾策略:過濾掉那些因為一直連接失敗的被標記為circuit tripped的后端server,并過濾掉那些高并發的的后端server(active connections 超過配置的閾值)
? **原理:**使用一個AvailabilityPredicate來包含過濾server的邏輯,其實就就是檢查status里記錄的各個server的運行狀態 ,
? 沒條件測驗家里窮,核心程序:
? 
? 7.ZoneAvoidanceRule 區域權重策略: 使用CompositePredicate根據區域和可用性過濾服務器的規則
? **原理:**通過Predicate鏈進行判斷,最后在所用通過判斷的服務器串列中采用輪詢策略選擇服務器
? **優勢:**服務器分布范圍很廣,呼叫方分布范圍也很廣,可使呼叫方請求路由到最近的服務器集群
? 沒條件測驗家里窮:
? 
? 8.自定義:一致性hash策略:對關鍵值進行hash運算,每次計算的結果一致,再加上其他的條件,使某種請求路由到同一個服務上,
? **優勢:**服務存在大量本地快取,例如根據token進行hash一致性運算,同一個token每次路由到同一個服務,這個服務可以做一些關于用戶權限相關的本地快取,
? 實際上,在負載均衡策略的選擇上,為了保證我們的服務的穩定性和平衡性等問題,我們會使用隨機策略使得每個用戶每次訪問都會均攤到不同的生產者服務上,使得單個服務器的壓力減小,但對于快取服務器來說,隨機取樣是一種方式,但是隨機取樣影響查找的性能,隨機獲取一臺服務器然后將Object存入,應用程式中通過id從快取服務器查找Object,這種方式是無法第一時間確定其所在的服務器的,需要遍歷集群中的所有服務器,然后比對查找出來的物件的id,才能獲得查找的Object,資料結構中的哈希表可以解決查找的問題,S集合使用線性串列方式存盤,這樣每臺服務器相對應的都有個編號,對于上面的4臺服務器來說,A的編號為0,其余的服務器編號依此類推,這樣的話確定了編號,就可以確定選擇的服務器,這個線性串列就是一張哈希表,通過公式hash(id)%N(N代表服務器個數)來確定我們的Object注冊到哪個服務器,以保證我們每次都可以訪問到之前快取服務器上,但是這個時候問題就來了,通過公式我們可以看出,當我們的服務器數量增加或者減少的話,我們的N就會發生變動,那么我們的計算出來的hash值就會發生變化,導致我們找不到原來的服務器,那么這樣他就會重新去請求資料庫,假設有大量的請求進來,我們資料庫可能承受不住壓力而導致崩潰,造成快取雪崩現象,
? 為此我們引入了一致性hash的策略,為了解決我們的hash函式計算出來的值受到服務器數量的影響,我們對hash函式進行了改進->hash(id),通過這個哈希函式計算出來的值,通常都是4個位元組,也就是32位,所以取值范圍就是0~2^32-1,所有的哈希值都會在這個區間內,將這個區間抽象成一個環
那么我們先將這4個物件映射到我們的換上面
h1 = hash(id);
h2 = hash(id);
h3 = hash(id);
h4 = hash(id);
然后對服務器也進行標識:
c1 = hash(cache1);
c2 = hash(cache2);
c3 = hash(cache3);
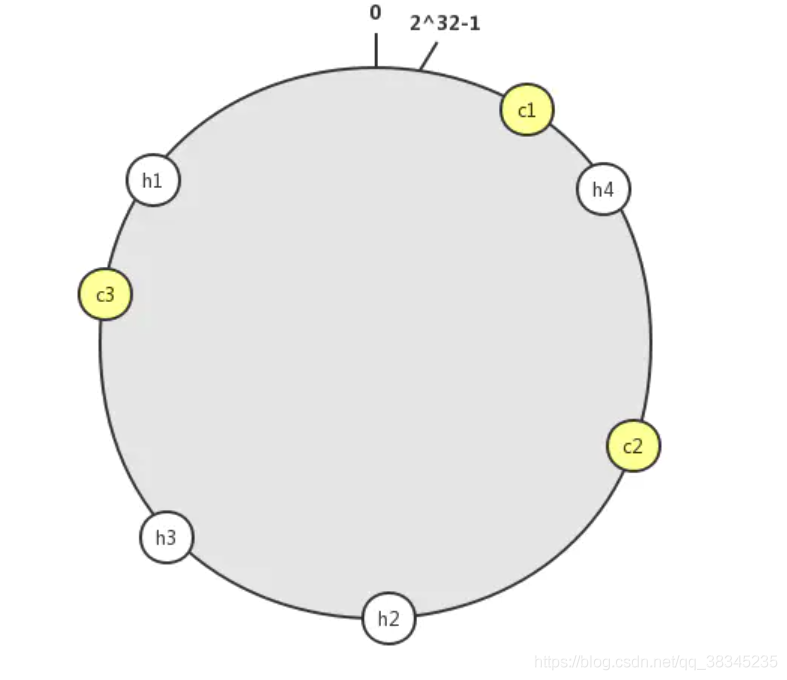
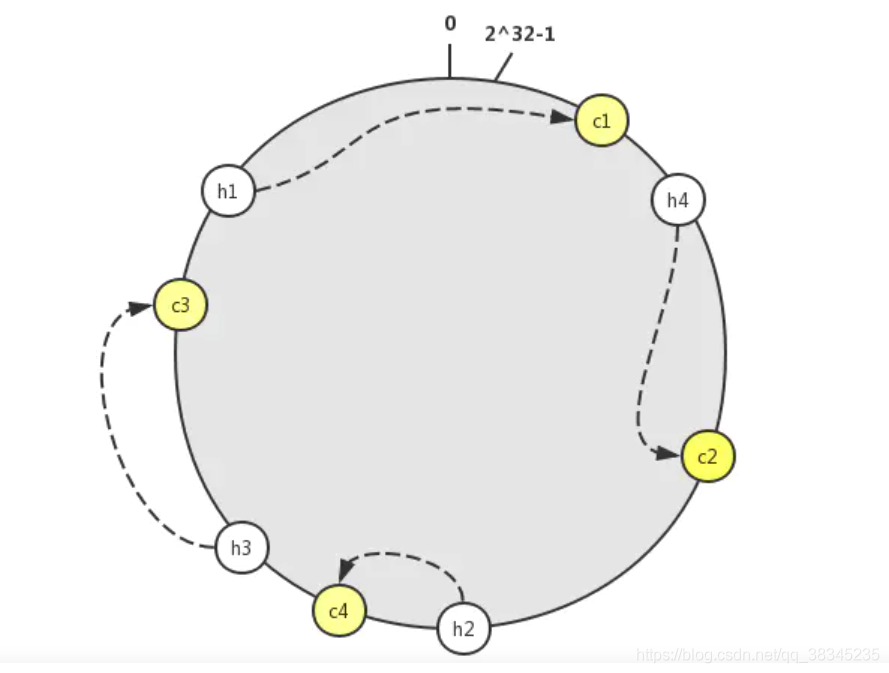
那么如何去確定h 和 c 之間的對應關系呢?我們可以想象一個人沿著環去尋找下一個地點,如果C節點的服務器掛掉,那么物件就會沿著環去尋找下一個節點,這里采用順時針的方式去尋找
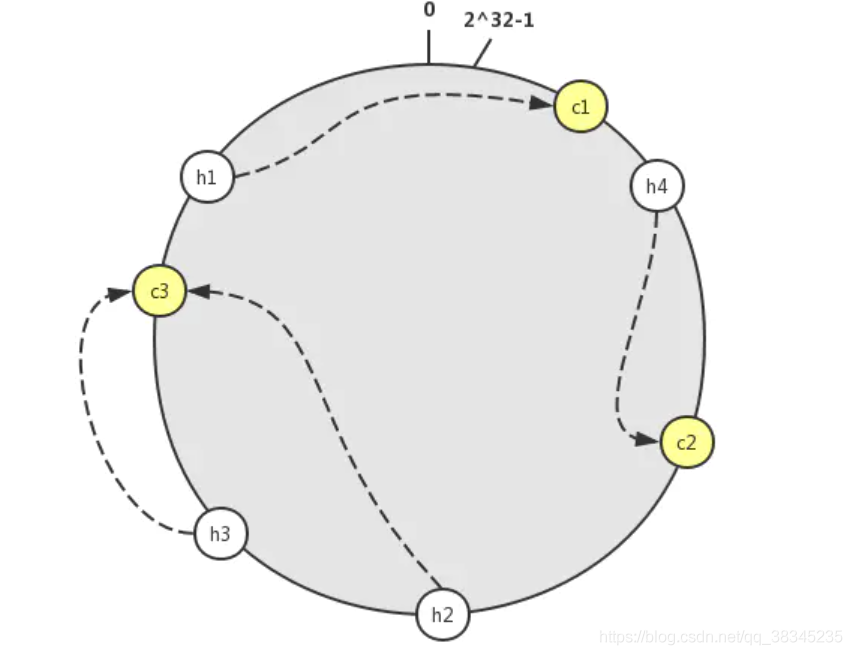
我們可以看到h1物件被分配到c1節點,h4節點被分配到了c2節點,h2,h3被分配到了c3節點,那么當c2節點崩潰的時候,那么h4就會被分配到c3節點,
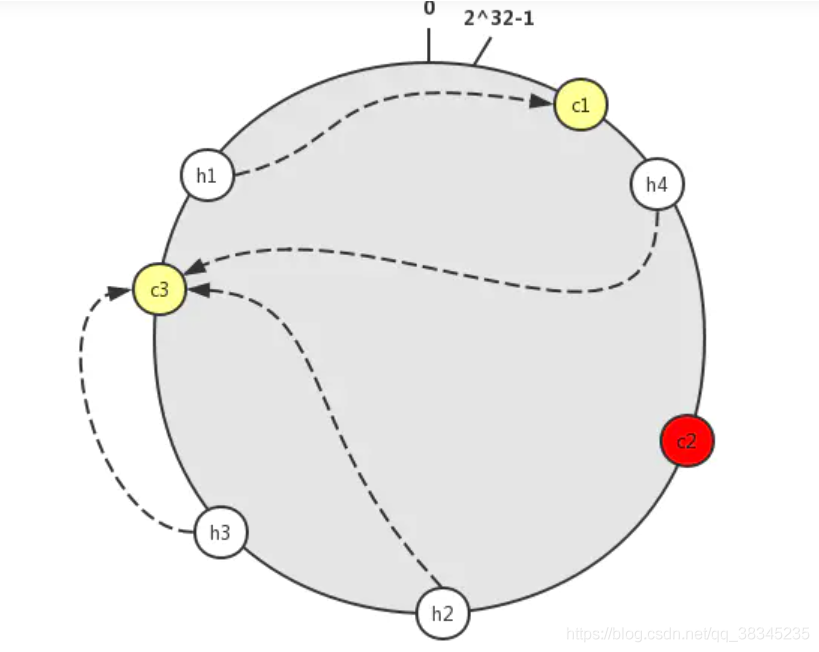
可以看到,c2服務下線,h4服務器就會去重新查詢資料庫,然后快取在下一個服務器上面,如圖就會尋找下一個節點c3,只會影響c3 服務器 ,并不會對其他服務器造成影響,這和普通的hash演算法的表現是不同的,普通hash演算法會影響其他快取服務器上的資料,
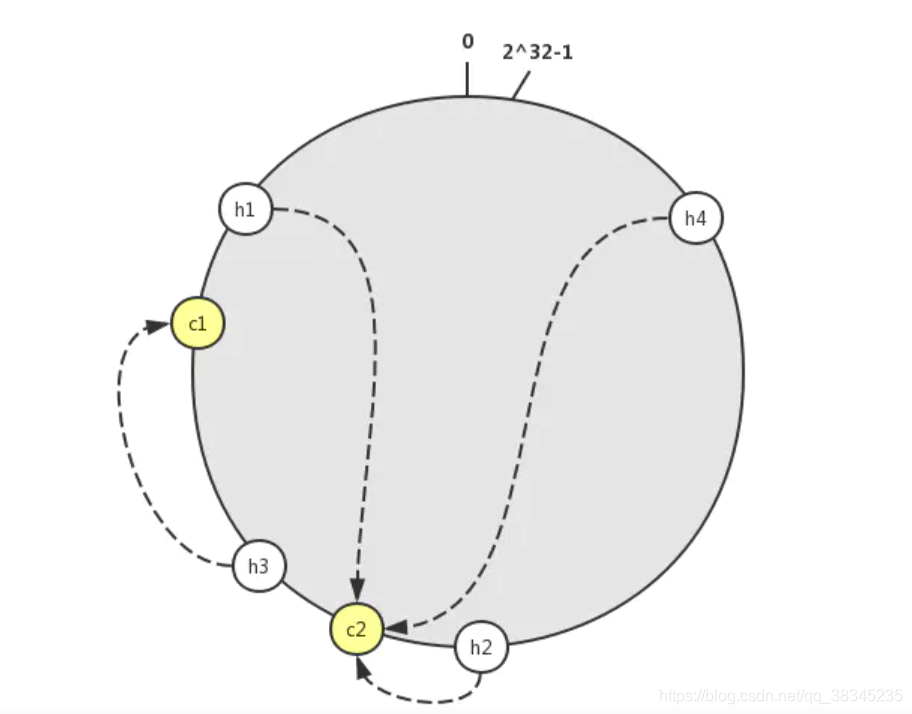
那么我們來看增加快取服務器看看:
增加Cache4,c4節點落在h2和h3之間,此時根據id2進行查找,定位到h2節點,從h2出發尋找對應的c節點,未增加之前找到的是c3節點,增加之后找到的是c4節點,c4節點代表的快取服務器Cache4并沒有Object2資料,那么應用程式從資料庫或其他地方獲取Object2資料然后重新放入到Cache2中,Cache3中的Object2此時就是無效的,可以看出增加Cache4服務器,只會影響到Cache2和Cache4之間的h節點代表的資料,
增加Cache4服務器后,最終的查找效果如下:
虛擬節點:
假設當前只有兩臺快取服務器,那么我們現在總共有4個物件,那么假設如圖分布
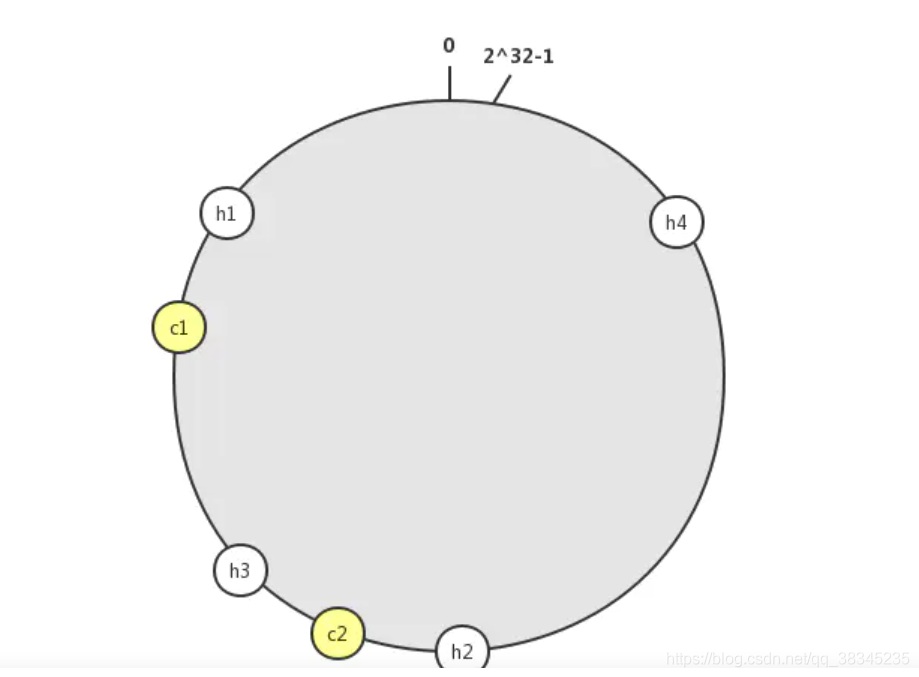
按照邏輯,我們h4,h2,h1都會集中分配在c2服務器上面,只有h3被分配到c1服務器上面,那么這樣就會導致我們的服務器分配不均衡,
如圖可見我們c2服務器就會承受很大滴壓力,如何解決這種問題呢?
可以采用虛擬節點的方式,給每個c服務器再分配多個虛擬節點,虛擬節點也是隨機分配在此區間環上面,那么每個c服務器的虛擬節點都是其本身的克隆節點,但是也是散列分布在這個哈希環當中,目的就是為了將部分節點的壓力均分,
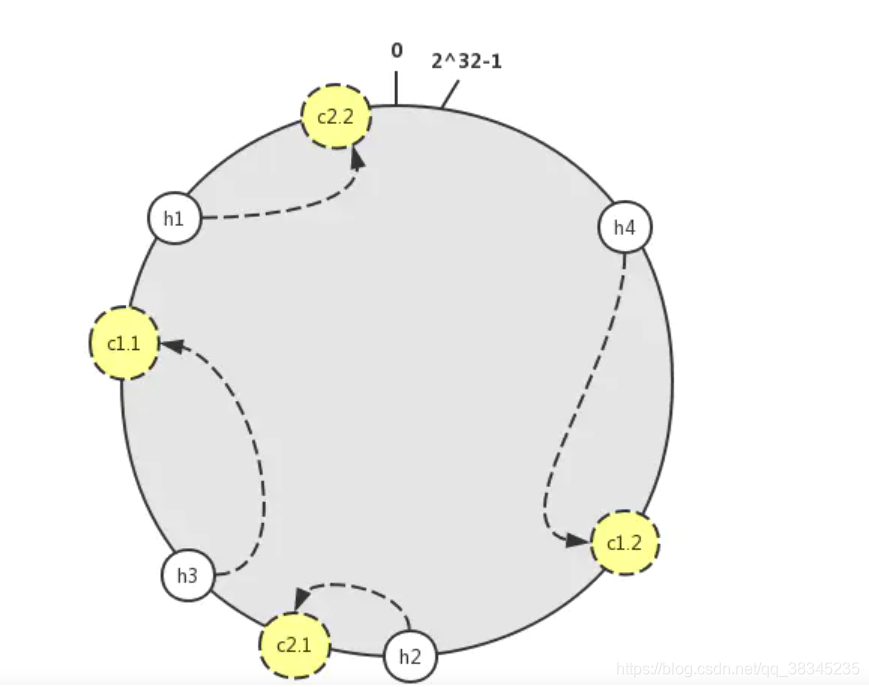
如圖可見
h2被分配到c2.1節點,h4被分配到c1.2節點,h1被分配到c2.2節點,h3被分配到c1.1節點,節點的分配變得均衡,當然這不是絕對的,一致性hash只能解區域分不重連資料庫的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271557.html
標籤:其他
下一篇:記:2020.3.31