
文章目錄
- 前言
- 時間戳
- 爬蟲中時間戳常見場景
- 時間戳如何轉換
- url去重
- 網頁請求的背后流程
- HTTP
- HTTP請求的一般流程:
- HTTP請求(Request):
- HTTP回應(Response):
- GET和POST:
- 再了解Cookie
- Xpath小補充
前言
本來以為第二篇沒了,就把寫了一部分的移到第一篇末尾了,所以已收藏第一篇的小伙伴可以也可以再翻翻看,是關于ts視頻拼接的,
沒想到,是我的路子窄了,
今天我打開了我的關注欄,從里面手動爬取了所有有爬蟲專欄的博客,分析他們博客中我沒見過或者不會或者需要會的知識點,整理一波走起,
時間戳
來自我的老朋友“不溫不火”的一篇博客,不知道他那篇寫時間戳干嘛,但是我覺得這個不錯,因為之前寫翻譯軟體的時候有被時間戳卡住過,當時沒太在意,因為有個大佬的教程很快幫我解決了問題,專案催的又緊,就直接交了,沒再去研究這個,
既然“冤家路窄”,這次就把它辦了,
先介紹一個時間戳轉換的網站,不知道什么是時間戳的小伙伴可以自己去玩一玩,網站上也有簡單介紹多種語言的時間戳處理辦法:
時間戳轉換網站
這里我們只講Python,
爬蟲中時間戳常見場景
時間戳作為一種簡單加密手段,你說會出現在什么場景?
js加密就不說了,我說過的,js加密能渲染我就渲染,不能渲染的我就請人來,
大多數的網站的驗證碼url地址是加上了一個時間戳的
我們可以拿到驗證碼就很簡單了, Python生成一個時間戳 + 部分url的值 = 驗證碼圖片的url地址
時間戳如何轉換
import time
time.time()
將字串的時間轉為時間戳
import time
str_time = "2021-4-01 17:16:10"
# 將時間字串轉成時間陣列
# 第一個引數就是時間字串; 第二個就是轉換的一些字串
time_array = time.strptime(str_time, "%Y-%m-%d %H:%M:%S")
# 轉換為時間戳
time_stamp = time.mktime(time_array) # 可以轉化為int型別
字串格式更改
"2021-4-01 17:16:10" 改為 "2021/4/01 17:16:10"
# 先轉換為時間陣列
import time
str_time = "2021-4-01 17:16:10"
time_array = time.strptime(str_time, "%Y-%m-%d %H:%M:%S")
other_way_time = time.strftime("%Y/%m/%d %H:%M:%S", time_array)
時間戳轉換為指定日期
time_stamp = 1861700872
# 使用localtime()轉換為時間陣列,在格式化自己想要的格式
import time
time_array = time.localtime(time_stamp)
other_way_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
import datetime
time_stamp = 1861700872
datetime_array = datetime.datetime.utcfromtimestamp(time_stamp)
other_way_time = datetime_array.strftime("%Y-%m-%d %H:%M:%S")
獲取三天前的時間
import time
import datetime
# 先獲得時間陣列格式的日期
three_day_ago = (datetime.datetime.now() - datetime.timedelta(days=3))
# 轉換為時間戳
time_stamp = int(time.mktime(three_day_ago.timetuple()))
# 轉換為其他形式的字串
other_way_time = three_day_ago.strftime("%Y-%m-%d %H:%M:%S")
毫秒級時間戳的 13位整數
int(time.time() * 1000)
就喜歡這種有經驗的博主寫的博客,一篇文章有多少內容在目錄直接一目了然,不關注他難不成來關注我?
不溫不火
url去重
昨天有個小伙伴問我怎么給url去重,我說用快取會自動去重,那是個辦法,今天又學到另一個辦法,后期我其比對一下哪個方法會比較好,
from pybloom_live import ScalableBloomFilter # 用于URL去重的
#使用ScalableBloomFilter模塊,對獲取的URL進行去重處理
urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
···偽代碼···
# 查重,從new中提取URL,并利用ScalableBloomFilter查重
if new["url"] not in urlbloomfilter:
urlbloomfilter.add(new["url"]) #將爬取過的URL放入urlbloomfilter中
try:
dosomething
except Exception as e:
error_url.add(new["url"]) #將未能正常爬取的URL存入到集合error_url中
看名字就知道這是一個布隆過濾器,bloomfilter:是一個通過多哈希函式映射到一張表的資料結構,能夠快速的判斷一個元素在一個集合內是否存在,具有很好的空間和時間效率,(典型例子,爬蟲url去重)
講真的,我不是很明白,布隆過濾器不是用來判斷某個元素不存在嗎?
它說存在那不一定存在,它說不存在那肯定是不存在的,
所以布隆過濾器什么時候能用來去重了?
后來,經過我多方查證,說是:很可能存在,所以就當做是存在,好的,畢竟那點誤判率在大資料面前,不重要,
網頁請求的背后流程
再怎么說,目前我還是個做后端的,所以對這個流程還是比較感興趣的,
第一步:網路瀏覽器通過本地或者遠程DNS,獲取域名對應的IP地址
第二步:根據獲取的IP地址與訪問內容封裝HTTP請求
第三步:瀏覽器發送HTTP請求
第四步:服務器接收資訊,根據HTTP內容尋找web資源
第五步:服務器創建HTTP請求并封裝
第六步:服務器將HTTP回應回傳到客戶端瀏覽器
第七步:瀏覽器決議,渲染服務器回傳得資源,顯示給用戶
HTTP
HTTP請求程序
HTTP請求
HTTP回應
HTTP方法
HTTP頭
HTTP請求的一般流程:
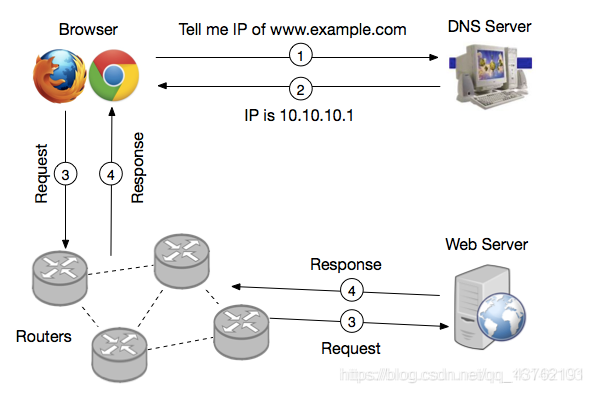
HTTP請求(Request):

HTTP回應(Response):
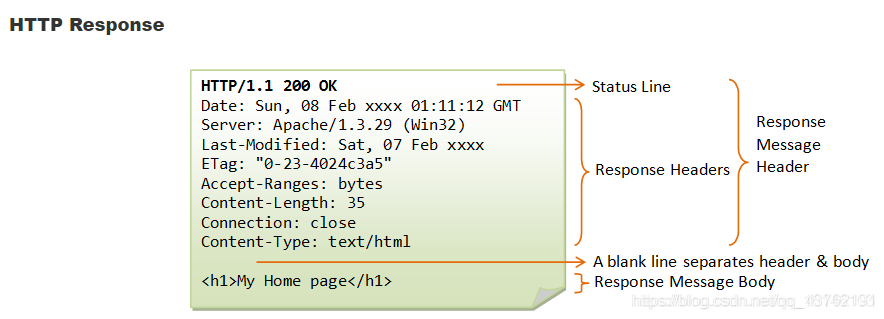
GET和POST:
GET 方法會將需要的引數附在 URL 的后面(是 URL 的一部分,即包含在 Request Line 中),以 “?” 分隔 URL和引數,多個引數之間用 “&” 連接,
豆瓣閱讀的 URL 為 https://read.douban.com/?dcn=entry&dcs=book-nav&dcm=douban ,其中包含了3個 key-value 引數,服務器會根據這些引數對用戶所請求的資源進行篩選和過濾,盡管 RFC2616 沒有對 URL 的長度進行限制,但通常服務器或瀏覽器都會限制 URL 的長度,如 Chrome 的 URL 長度不能超過 8KB,所以,如果要向服務器發送大量的資料 POST 是更好的選擇,
另外,為了保證客戶端和服務器之間的一致性,RFC2616 規定 URL 中只能使用 ASCII 中的可見字符, 所以如果 URL 中包含了中文等非 ASCII 字符, 就要對 URL 進行編碼,通常采用的編碼方式是百分號編碼,即用 ‘%’ 分隔十六進制的 UTF-8 編碼,
與 GET 方法不同,POST 方法是將資料放在訊息體中,并用 Content-Type 標明采用的是何種格式,不過,RFC2616 并沒有規定訊息體的格式,實際上,開發者完全可以開發自己的傳輸格式,只要保證客戶端和服務器之間能正確決議即可,另外,通過 POST 傳遞的資料,不會被瀏覽器快取,所以 POST 方法要比 GET 方法的安全性高一點,因為這些原因,現行的網站大多都采用 POST 方法實作注冊、登錄等互動功能,
再了解Cookie
Cookie,有時也用其復數形式Cookies,指某些網站為了辨別用戶身份、進行session跟蹤而存盤在用戶本地終端上的資料(通常經過加密),
由于HTTP是一種無狀態的協議,服務器但從網路連接上不能知道客戶身份,如果想要知道客戶身份,這是就需要一張通行證,每人一個,無論誰訪問都必須攜帶自己的通行證,這樣服務器就能通過通行證來確定客戶身份,這就是Cookie的作業原理,
客戶端發送一個http請求到服務器端,如果是登錄操作則攜帶我們的用戶名和密碼,
服務器端驗證后發送一個http回應到客戶端,其中包含Set-Cookie頭部,
客戶端發送一個http請求到服務器端,其中包含Cookie,
服務器端發送一個http回應到客戶端,
看了一個連目錄都不做的人,看著就難受,取關了,
字體加密的破解太高級了,等下次機緣吧,
Xpath小補充
今天群里有個小伙伴問我說Xpath怎么按行提取,說的意思不是很明白,我們估計是這兩種情況:
一種是這樣的:
es = el.xpath('./h1 |./h2 |./h3 |./h4 |./h5 |./h6 |./p |./p/mark |./p/span/span/span/span[2]//span/span[2]'
'|./p/strong |./p/em |./ul//li |./ol//li |./ul//li |./blockquote/p |./pre/code |./p/code '
'|./div/table/thead/tr//th |./div/table/tbody/tr//td |./hr |./p/img |./p/a')
要抓取很多種不同的標簽,但是有要保持標簽內容的原有排序,可以使用這種方式,將所有的標簽用 “|” 的方式進行并列,
另一種情況是這樣的:
(這是一個爬取票房資料庫的示例,里面采用了二次Xpath的方式)
import requests
from lxml import etree
def get_html(url,times):
'''
這是一個用戶獲取網頁源資料的函式
:param url: 目標網址
:param times: 遞回執行次數
:return: 如果有,就回傳網頁資料,如果沒有,回傳None
'''
try:
res = requests.get(url = url,headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0"
}) #帶上請求頭,獲取資料
if res.status_code>=200 and res.status_code<=300: #兩百打頭的識別符號標識網頁可以被獲取
return res
else:
return None
except Exception as e:
print(e) # 顯示報錯原因(可以考慮這里寫入日志)
if times>0:
get_html(url,times-1) # 遞回執行
def get_data(html_data, Xpath_path):
'''
這是一個從網頁源資料中抓取所需資料的函式
:param html_data:網頁源資料 (單條資料)
:param Xpath_path: Xpath尋址方法
:return: 存盤結果的串列
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") # 洗掉資料中的注釋
tree = etree.HTML(data) # 創建element物件
el_list = tree.xpath(Xpath_path)
return el_list
res = get_html('http://58921.com/alltime?page=1',2)
print(res.content)
el_list = get_data(res,'//*[@id="content"]/div[3]//tr')
for el in el_list:
e = el.xpath('.//text() | .//@href')
print(e)
哇哦,剛剛發現一個爬蟲博主有幾百篇爬蟲,,,
太多了吧,下次再說吧,,,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/271609.html
標籤:其他
上一篇:動態記憶體管理