選擇排序
定義
一種最簡單的排序演算法是這樣的:假定我們對一個陣列進行排序那么,我們可以找到陣列中最小的元素,然后與陣列的第一個經行交換,如果第一個已經是最小的,那就和自己交換,然后在剩下的元素中找到最小的和第二個進行交換,以此類推,最終得到一個升序的陣列,這種方式就叫做選擇排序,
冒泡排序的升級版本,
代碼實作
@Test
void select() {
int nums[] = new int[]{9,8,7,6,5,4,3,2,1,0};
//經行選擇排序
selectSort(nums);
for (int num : nums) {
System.out.println(num);
}
}
private void selectSort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
//這種排序需要一個變數來記錄當前最小值的位置
int min = i;
for (int j = i+1; j < nums.length; j++) {
if(nums[j] < nums[min]){
//當前元素比這個小,min指向這個小的
min = j;
}
//把最小的放在剩余元素的最前面
int tmp = nums[i];
nums[i] = nums[min];
nums [min] = tmp;
}
}
}
時間復雜度
這里只考慮最壞的情況,
對于一個長度為N的陣列,第一次就需要遍歷整個陣列,這個時候就是N次,接下來就是N-1,N-2……直到比較完成,所以最多比較次數就是把這些加起來等于N(N-1)/ 2,與就是O(N^2),
插入排序
定義
斗地主都玩過,摸起來的牌都會一張一張的插入到一個合適的位置,然后正副牌看起來就是井然有序,這種插入的方式就是插入排序,
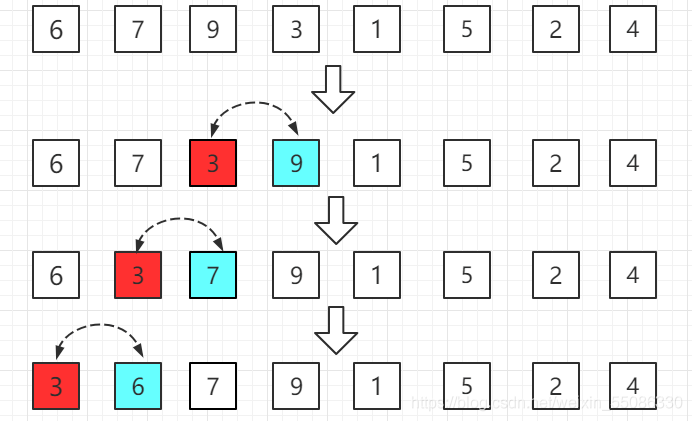
就比如這個,3比9小,于是插入到9的左邊,然后發現,3比7小,又插入到7的左邊,直到左邊沒有比這數小的,總的來說就是一趟過后,左邊的都是有序的,
代碼實作
@Test
void select() {
int nums[] = new int[]{9,8,7,6,5,4,3,2,1,0};
//經行選擇排序
insertSort(nums);
for (int num : nums) {
System.out.println(num);
}
}
private void insertSort(int[] nums){
//外層回圈
for (int i = 1; i < nums.length; i++) {
for (int j = i;j > 0;j--) {
//當前比前面的小,插入
if (nums[j] < nums[j-1]){
//交換
int tmp = nums[j];
nums[j] = nums[j-1];
nums [j-1] = tmp;
} else {
break; //沒有就后移再次進入回圈比較
}
}
}
}
時間復雜度為:N2/4,就是O(N2),比選擇排序好那么一點,
希爾排序
上面的排序每次都是相鄰的元素進行比較,導致每次都需要大量的移動,而希爾排序的特點就是,每次使陣列變得大致上有序,然后變得有序,每次使一個組有序,總體上就是大致有序,然后縮小這個組直到最后有序,
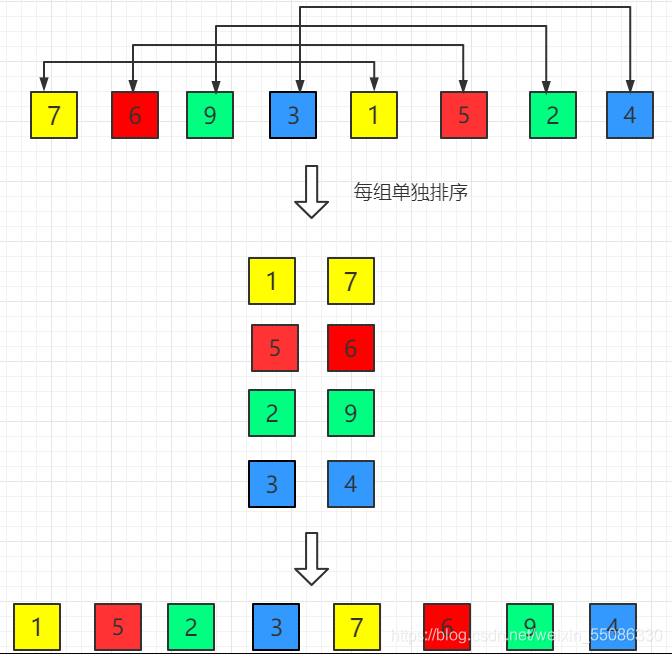
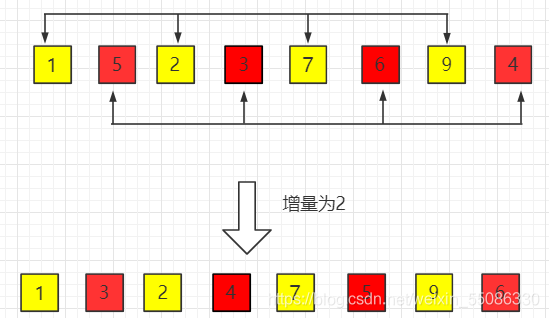
比如這個,1,7一組,6,5一組,然后這每一個組排個序,整個陣列就整體上變得有序很多,然后縮小這個分組,直到最后有序,
代碼實作
@Test
void select() {
int nums[] = new int[]{9,8,7,6,5,4,3,2,1,0};
//經行選擇排序
insertSort(nums);
for (int num : nums) {
System.out.println(num);
}
}
private void shellSort(int[] nums){
//選擇一個增量
int n = nums.length/2;
//增量不等于1排序,陣列只能大致有序,所以會逐步縮小到1
while (n > 0) {
for (int i = n; i < nums.length; i++) {
for (int j = i; j >= n; j -= n) {
//比較這兩個大小
if (nums[j] < nums[j-n]){
//交換
int tmp = nums[j];
nums[j] = nums[j-n];
nums [j-n] = tmp;
}
}
}
//縮小增量
n = n / 2;
}
}
對于這種排序,怎么選擇增量就是一個最復雜的問題,
歸并排序
歸并排序(Merge sort)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide and Conquer)的一個非常典型的應用,
作為一種典型的分而治之思想的演算法應用,歸并排序的實作由兩種方法:
- 自上而下的遞回(所有遞回的方法都可以用迭代重寫,所以就有了第 2 種方法);
- 自下而上的迭代;
用一張圖演示歸并的程序:

分割歸并:
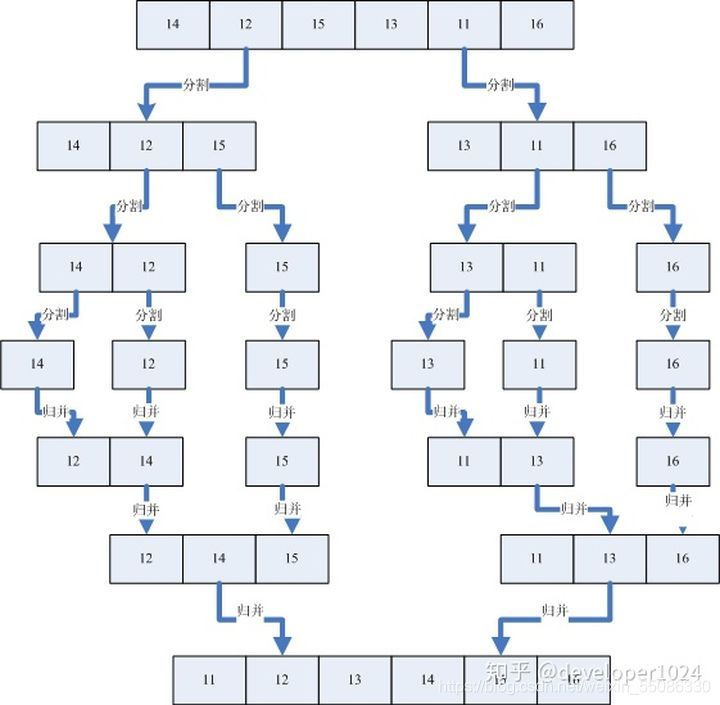
遞回
既然是一個分割合并的程序,必然需要兩個指標來對著兩邊進行歸并,
public static void main(String[] args) {
//歸并排序,定義一個陣列
int arr[] = new int[]{1,5,3,8,7,4,9,2};
//需要遞回的方法
sort(arr,0,arr.length-1);
for (int i : arr) {
System.out.print(i + " ");
}
}
//方法含義,根據陣列進行排序
public static void sort(int arr[], int left, int right){
//遞回結束條件,左指標大于或者等于右指標
if (left >= right) return;
//二分的中間值
int mid = left + (right - left) / 2;
//否則進行分割
sort(arr,left, mid);
sort(arr,mid+1,right);
//最后才是排序
merge(arr,left,mid, right);
}
private static void merge(int[] arr, int left, int mid, int right) {
//先復制這個陣列,這樣為了保證原來的陣列不被打亂
int tmp[] = new int[right-left+1];
int k=0;
int l = left;
int r = mid+1;
//左右指標
while (l <= mid && r <= right){
if(arr[l] < arr[r]){
//左邊陣列小于右邊,把左邊的放在臨時陣列中
tmp[k] = arr[l];
l++;
} else {
tmp[k] = arr[r];
r++;
}
k++;
}
//然后把上面沒排完的全部放在這個新陣列里面
while (l <= mid) tmp[k++] = arr[l++];
while (r <= right) tmp[k++] = arr[r++];
//最后把陣列賦值給原來的陣列
for (int i = 0; i < tmp.length; i++) {
arr[left+i] = tmp[i];
}
}
其實這是有一點像樹的后續遍歷,先找到葉子節點(這里先分割成最小單位),然后在做一個排序處理,
快速排序
快排的性能在所有排序演算法里面是最好的,資料規模越大快速排序的性能越優,快排在極端情況下會退化成O(n^2)的演算法,因此假如在提前得知處理資料可能會出現極端情況的前提下,可以選擇使用較為穩定的歸并排序,
一張圖解釋快排:
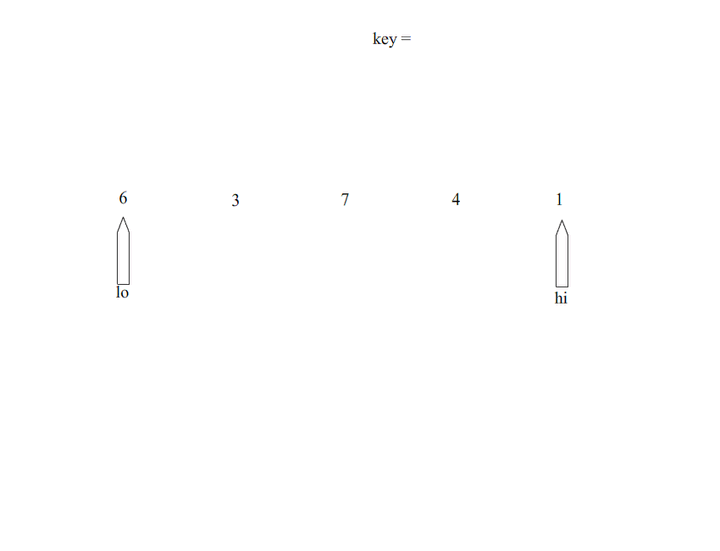
仔細看,發現這個程序跟歸并排序貌似是一個相反的程序,歸并是先分割成最小兩個單位,在逐步向上,而快排是先排序成兩個分割好的再遞進下去,
總結規律:
- 選擇待排序(A)中的任意一個元素pivot,該元素作為基準
- 將小于基準的元素移到左邊,大于基準的元素移到右邊(磁區操作)
- A被pivot分為兩部分,繼續對剩下的兩部分做同樣的處理
- 直到所有子集元素不再需要進行上述步驟
public static void main(String[] args) {
//歸并排序,定義一個陣列
int arr[] = new int[]{1,5,3,8,7,4,9,2};
//需要遞回的方法
sort(arr,0,arr.length-1);
for (int i : arr) {
System.out.print(i + " ");
}
}
//方法含義,根據陣列進行排序
public static void sort(int arr[], int left, int right){
int index = 0;
//遞回結束條件,左指標大于或者等于右指標
if (left < right) {
//將第一趟排序后的地址拿到
index = merge(arr, left, right);
//然后根據這個下標分割這個陣列
sort(arr, left, index - 1);
sort(arr, index + 1, right);
}
}
private static int merge(int[] arr, int left, int right) {
//主要的邏輯代碼,雙指標左右前進
int tmp = arr[left]; //保存中軸
while (left < right) {
while (left < right && arr[right] >= tmp) {
//比中軸小,則需要交換到低端,否則直接這個下標后移
right--;
}
//進行交換
arr[left] = arr[right];
while (left < right && arr[left] <= tmp) {
//比中軸大就交換到高端,否則就這個下標前移
left++;
}
arr[right] = arr[left];
}
//最后更新這個中軸
arr[left] = tmp;
return left;
}
堆排序
堆排序是利用堆這種資料結構而設計的一種排序演算法,堆排序是一種**選擇排序,**它的最壞,最好,平均時間復雜度均為O(nlogn),它也是不穩定排序,首先簡單了解下堆結構,
堆是具有以下性質的完全二叉樹:每個結點的值都大于或等于其左右孩子結點的值,稱為大頂堆;或者每個結點的值都小于或等于其左右孩子結點的值,稱為小頂堆,如下圖:
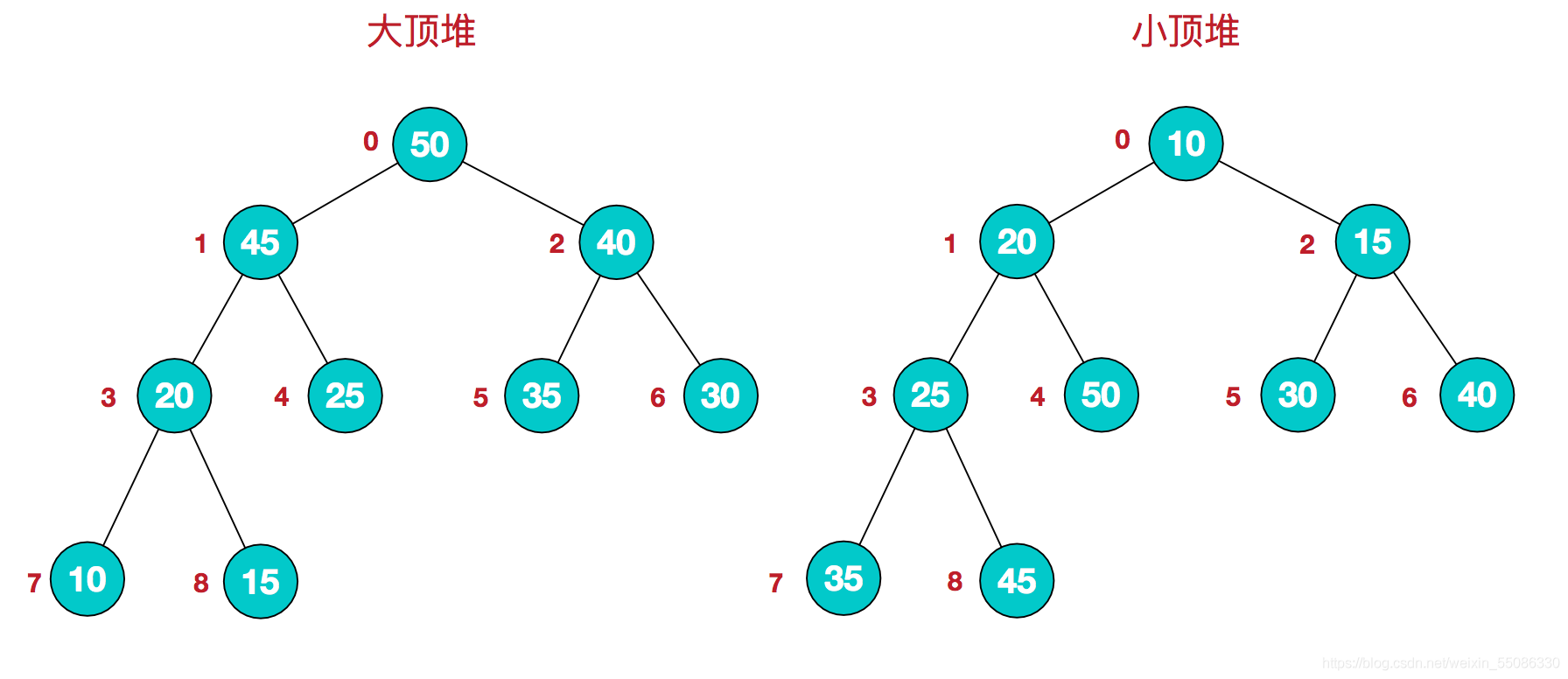
同時,我們對堆中的結點按層進行編號,將這種邏輯結構映射(層序遍歷的一種結構)到陣列中就是下面這個樣子:

這個陣列中蘊含的一個數學公式:
大頂堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小頂堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
至此就可以開始著手了解這個堆排序,
基本思想:將待排序構造成一個大頂堆(或者小堆)結構,此時,整個序列的最大值(最小值)一定是堆頂的這個節點,或者說是這個陣列的第一個元素,然后把這個值和最后的一個節點交換,這個時候最大或者最小值不久直接搞到最后了嘛,然后把除了最后一個節點的剩下節點再構造成一個堆結構,如此反復,一個有序的陣列就得到了,
public static void main(String[] args) {
int[] nums = {16,7,3,20,17,8};
headSort(nums);
for (int num : nums) {
System.out.print(num + " ");
}
}
/**
* 堆排序
*/
public static void headSort(int[] list) {
//構造初始堆,i一定是倒數第二層的一個節點,并且這個節點的右邊的節點一定沒有孩子節點,
for (int i = (list.length) / 2 - 1; i >= 0; i--) {
headAdjust(list, list.length, i);
}
//排序,將最大的節點放在堆尾,然后從根節點重新調整
for (int i = list.length - 1; i >= 1; i--) {
int temp = list[0];
list[0] = list[i];
list[i] = temp;
headAdjust(list, i, 0);
}
}
/**
* 調整這個節點與左右孩子的關系
* @param list
* @param len
* @param i
*/
private static void headAdjust(int[] list, int len, int i) {
//tem 是父節點,index是左孩子,k 父節點的位置
int k = i, temp = list[i], index = 2 * k + 1;
while (index < len) {
//index < len 表示有左孩子
if (index + 1 < len) {
//找到孩子節點中較大值的下標
if (list[index] < list[index + 1]) {
index = index + 1;
}
}
//這個較大的孩子節點比父節點大,交換,
if (list[index] > temp) {
list[k] = list[index];
k = index;
index = 2 * k + 1;
} else {
break;
}
}
//更新這個孩子節點的值,如果上面沒有發生交換,就保持父節點不動
list[k] = temp;
}
計數排序
現在假設一種場景,高考一般考生在幾百萬,有這么多的資料,但是這個資料值的分布呢,0到750這個資料,也就是不論哪個人,分數一定是在這個范圍,那么如何知道一個人的排名呢?這個時候就可以統計每個分數的人數,而不是非要把幾百萬個資料進行一個排序!
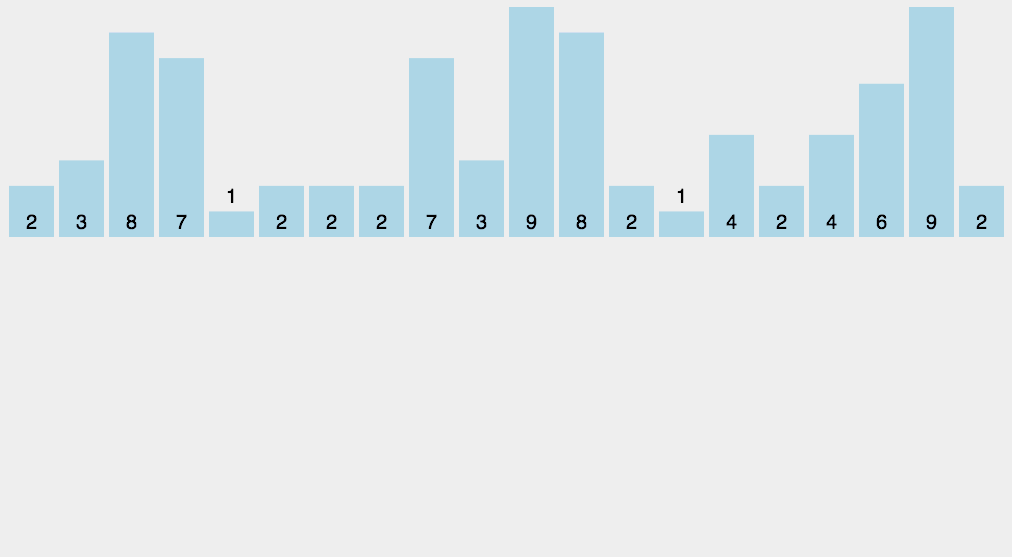
核心思想:統計每個整數在序列中出現的次數,進而推匯出每個整數在有序序列中的索引
public static void main(String[] args) {
//歸并排序,定義一個陣列
int arr[] = new int[]{1,5,3,8,7,4,0,0,9,2,4,5,1,7,8,9,7,4,4,5,1,2,3,2,6,5,6,9,8,7};
//需要遞回的方法
int[] sort = sort(arr);
for (int i : sort) {
System.out.print(i + " ");
}
System.out.println();
for (int i : arr) {
System.out.print(i+" ");
}
}
//方法含義,根據陣列進行排序
public static int[] sort(int arr[]){
//既然是計數,我們需要一個陣列來記錄每個資料出現的次數
int count[] = new int[10];
//然后遍歷這個陣列,每個資料當作下標使用
for (int i = 0; i < arr.length; i++) {
count[arr[i]]++;
}
int index = 0; //這個陣列的下標,i表示這個數值
//根據這個計數器得到資料
for (int i = 0; i < count.length; i++) {
int tmp = count[i]; //得到這個值的次數
while (tmp > 0){
arr[index++] = i;
tmp--;
}
}
return count;
}
前面的排序都是比較大小人后交換位置,這種排序算得上另辟蹊徑,直接統計數量然后重新賦值整個陣列,但是這種排序大部分只針對這種數字,
基數排序
計數排序是一種很容易理解的演算法,適用的領域也比較小,這里給出的基數排序也用到了桶這個概念,也就是統計個數,一張動圖如下:假如我們現在陣列的元素是:1221, 15, 20, 3681, 277, 5420, 71, 1522, 4793,

在上面的例子中,我們先對個位進行count排序,然后對十位進行count排序,然后是百位和千位,最后生成最終的排序結果,
public static void main(String[] args) {
int[] arr = new int[] { 23, 6, 9, 287, 56, 1, 789, 34, 65, 653 };
System.out.println(Arrays.toString(arr));
radixSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void radixSort(int[] arr) {
// 存陣列中最大的數字,為了知道回圈幾次
int max = Integer.MIN_VALUE;// (整數中的最小數)
// 遍歷陣列,找出最大值
for (int i = 0; i < arr.length; i++) {
if (max < arr[i]) {
max = arr[i];
}
}
// 計算最大數是幾位數,,此方法計較絕妙
int maxLength = (max + "").length();
// 用于臨時存盤資料的陣列
int[][] temp = new int[10][arr.length];
// 用于存盤桶內的元素位置
int[] counts = new int[arr.length];
// 第一輪個位數較易得到余數,第二輪就得先除以十再去取余,之后百位除以一百
// 可以看出,還有一個變數隨回圈次數變化,為了取余
// 回圈的次數
for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {
// 每一輪取余
for (int j = 0; j < arr.length; j++) {
// 計算余數
int ys = (arr[j] / n) % 10;
// 把資料放在指定陣列中,有兩個資訊,放在第幾個桶+資料應該放在第幾位
temp[ys][counts[ys]] = arr[j];
// 記錄數量
counts[ys]++;
}
// 記錄取的數字應該放到位置
int index = 0;
// 每一輪回圈之后把數字取出來
for (int k = 0; k < counts.length; k++) {
// 記錄數量的陣列中當前余數記錄不為零
if (counts[k] != 0) {
for (int l = 0; l < counts[k]; l++) {
// 取出元素
arr[index] = temp[k][l];
index++;
}
// 取出后把數量置為零
counts[k] = 0;
}
}
}
}
桶排序
一句話總結:劃分多個范圍相同的區間,每個子區間自排序,最后合并,
桶排序是計數排序的擴展版本,計數排序可以看成每個桶只存盤相同元素,而桶排序每個桶存盤一定范圍的元素,通過映射函式,將待排序陣列中的元素映射到各個對應的桶中,對每個桶中的元素進行排序,最后將非空桶中的元素逐個放入原序列中,

public static void bucketSort(int[] arr){
// 計算最大值與最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
// 計算桶的數量
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 將每個元素放入桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
// 對每個桶進行排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
// 將桶中的元素賦值到原序列
int index = 0;
for(int i = 0; i < bucketArr.size(); i++){
for(int j = 0; j < bucketArr.get(i).size(); j++){
arr[index++] = bucketArr.get(i).get(j);
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/272278.html
標籤:其他
上一篇:C語言檔案操作
下一篇:idea常用快捷鍵!(開發必備)