Springcloud概念
說在前面:
? springcloud初級知識適合剛剛接觸springcloud的人閱讀和學習,如果您已經了解了不少springcloud知識,請移步springcloud中級\springcloud中級
為什么要學習springcloud?
我們從很多地方聽說或者了解到了springcloud,分布式,微服務,等等等等當下互聯網最火熱的名詞,但是為什么要學習springcloud呢?
什么是微服務架構
微服務架構就是將單體的應用程式分成多個應用程式,這多個應用程式就成為微服務,每個微服務運行在自己的行程中,并使用輕量級的機制通信,
這些服務圍繞業務能力來劃分,并通過自動化部署機制來獨立部署,這些服務可以使用不同的編程語言,不同資料庫,以保證最低限度的集中式管理,
說人話就是,微服務架構把一個很大的東西細分為很小很小的東西,就和一輛車需要很多零件和螺絲一樣!但是汽車的目的是為了方便四級在現實世界出行,而微服務是為了方便程式員在架構中實作需求!
微服務微服務微服務,分布式分布式分布式,重要的事情說三遍,你學習springcloud就是為了分布式,springcloud是集成者而不是開創者,
什么是springcloud
-
Spring Cloud是一系列Java框架的有序集合,
它利用Spring Boot的開發便利性巧妙地簡化了分布式系統基礎設施的開發,如服務發現注冊、配置中心、智能路由、訊息總線、負載均衡、斷路器、資料監控等,都可以用Spring Boot的開發風格做到一鍵啟動和部署,
-
Spring Cloud是服務框架的組合
Spring Cloud并沒有重復制造輪子,它只是將各家公司開發的比較成熟、經得起實際考驗的服務框架組合起來,通過Spring Boot風格進行再封裝屏蔽掉了復雜的配置和實作原理,最終給開發者留出了一套簡單易懂、易部署和易維護的分布式系統開發工具包,
綜上所述,springcloud即為服務框架的整合,通過springboot風格進行再封裝屏蔽掉了復雜的配置和實作原理
SpringCloud的優缺點
優點
- 1.耦合度比較低,不影響其他模塊的開發
- 2.減輕團隊的成本,可以并行開發,不用關注其他人怎么開發,先關注自己的開發,
- 3.配置比較簡單,基本用注解就能實作,不用使用過多的組態檔,
- 4.微服務跨平臺的,可以用任何一種語言開發,
- 5.每個微服務可以有自己的獨立的資料庫也有用公共的資料庫,
- 6.直接寫后端的代碼,不用關注前端怎么開發,直接寫自己的后端代碼即可,然后暴露介面,通過組件進行服務通信,
缺點
- 1.部署比較麻煩,給運維工程師帶來一定的麻煩,
- 2.針對資料的管理比麻煩,因為微服務可以每個微服務使用一個資料庫,
- 3.系統集成測驗比較麻煩
- 4.性能的監控比較麻煩,【最好開發一個大屏監控系統】
總的來說優點大過于缺點,目前看來Spring Cloud是一套非常完善的分布式框架,目前很多企業開始用微服務、Spring Cloud的優勢是顯而易見的,因此對于想研究微服務架構的同學來說,學習Spring Cloud是一個不錯的選擇,
SpringBoot和SpringCloud的區別
- SpringBoot專注于快速方便的開發單個個體微服務,
- SpringCloud是關注全域的微服務協調整理治理框架,它將SpringBoot開發的一個個單體微服務整合并管理起來,
- 為各個微服務之間提供,配置管理、服務發現、斷路器、路由、微代理、事件總線、全域鎖、決策競選、分布式會話等等集成服務
- SpringBoot可以離開SpringCloud獨立使用開發專案, 但是SpringCloud離不開SpringBoot ,屬于依賴的關系
- SpringBoot專注于快速、方便的開發單個微服務個體,SpringCloud關注全域的服務治理框架,
Spring Cloud和SpringBoot版本對應關系
| Spring Cloud Version | SpringBoot Version |
|---|---|
| 2020.0.x aka Ilford | 2.4.x |
| Hoxton | 2.2.x, 2.3.x (Starting with SR5) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
SpringCloud由什么組成
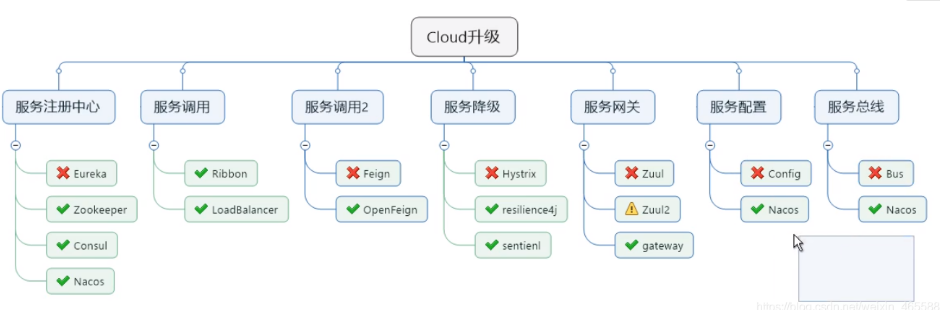
-
Spring Cloud Eureka(現在閉源了):服務注冊與發現
-
Spring Cloud Zuul(gateway):服務網關
-
Spring Cloud Ribbon:客戶端負載均衡
-
Spring Cloud Feign:宣告性的Web服務客戶端
-
Spring Cloud Hystrix:斷路器
-
Spring Cloud Config:分布式統一配置管理
-
等20幾個框架,開源一直在更新
使用 Spring Boot 開發分布式微服務時,我們面臨什么問題
- 1.與分布式系統相關的復雜性-這種開銷包括網路問題,延遲開銷,帶寬問題,安全問題,
- 2.服務發現-服務發現工具管理群集中的流程和服務如何查找和互相交談,它涉及一個服務目錄,在該目錄中注冊服務,然后能夠查找并連接到該目錄中的服務,
- 3.冗余-分布式系統中的冗余問題,
- 4.負載平衡 --負載平衡改善跨多個計算資源的作業負荷,諸如計算機,計算機集群,網路鏈路,中央處理單元,或磁盤驅動器的分布,
- 5.性能-問題 由于各種運營開銷導致的性能問題,
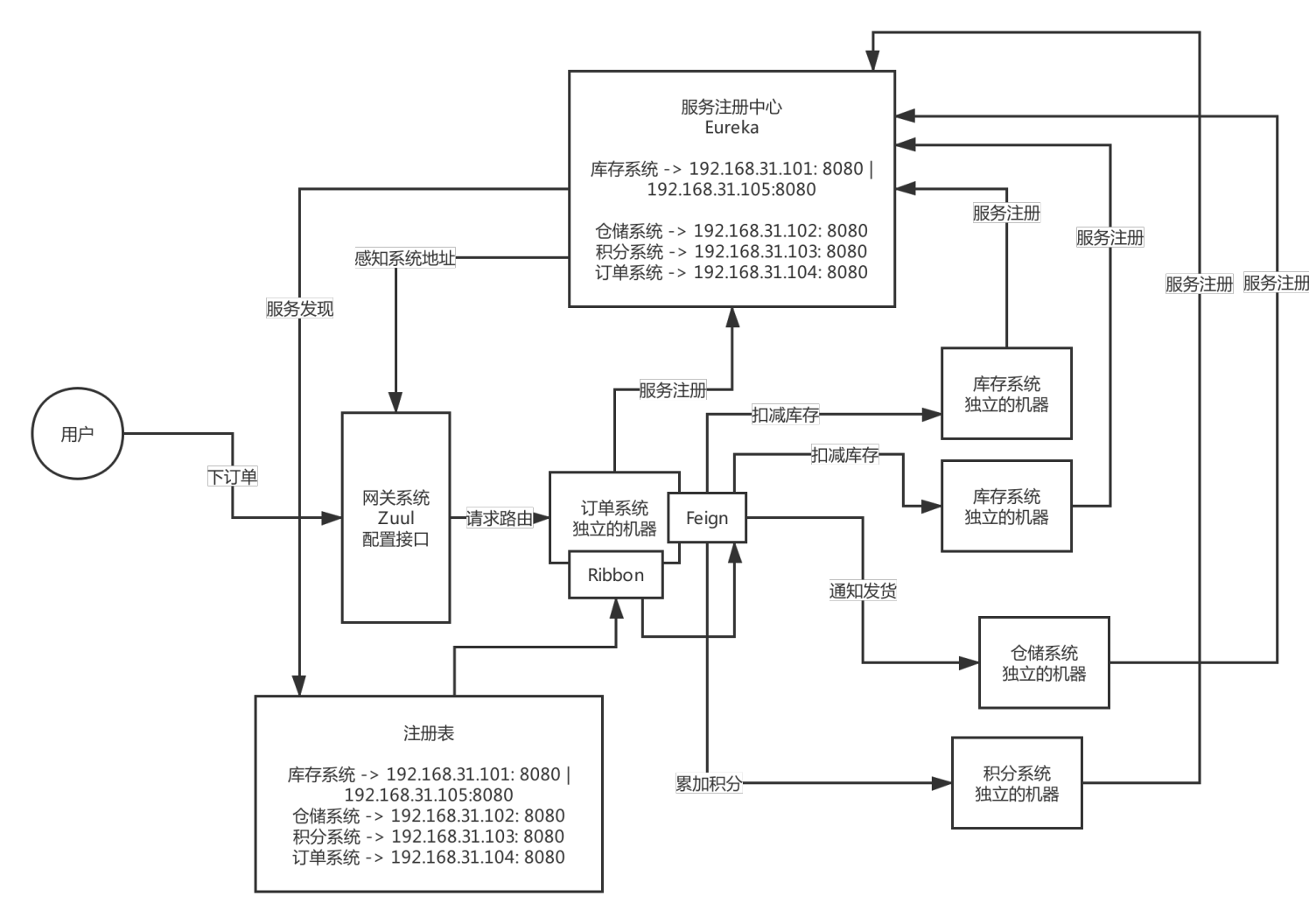
服務注冊和發現是什么意思?Spring Cloud 如何實作?
當我們開始一個專案時,我們通常在屬性檔案中進行所有的配置,隨著越來越多的服務開發和部署,添加和修改這些屬性變得更加復雜,
有些服務可能會下降,而某些位置可能會發生變化,手動更改屬性可能會產生問題, Eureka 服務注冊和發現可以在這種情況下提供幫助,由于所有服務都在 Eureka 服務器上注冊并通過呼叫 Eureka 服務器完成查找,因此無需處理服務地點的任何更改和處理,
Eureka
Eureka的基礎概念
什么是Eureka?
Eureka作為SpringCloud的服務注冊功能服務器,他是服務注冊中心,系統中的其他服務使用Eureka的客戶端將其連接到Eureka Service中,并且保持心跳,這樣作業人員可以通過Eureka Service來監控各個微服務是否運行正常,
Eureka服務注冊與發現
什么是服務治理?
SpringCloud封裝了Netflix公司開發的Eureka模塊來實作服務治理
在傳統的RPC遠程呼叫框架中,管理每個服務與服務之間的依賴關系比較復雜,管理比較麻煩,所以需要使用服務治理,管理服務于服務之間的依賴關系,可以實作服務呼叫,負載均衡,容錯等,實作服務發現與注冊,
什么是服務注冊與發現
Eureka采用了CS的設計架構,Eureka Server作為服務注冊功能的服務器,他是服務注冊中心,而系統中的其他微服務,使用Eureka 的客戶端連接到Eureka Server并維持心跳連接,這樣系統的維護人員就可以通過Eureka Server來監控系統中各個微服務是否正常運行,
在服務注冊與發現中,有一個注冊中心,當服務器啟動的時候,會把當前自己服務器的資訊:比如 服務地址通訊地址等以別名的方式注冊到注冊中心上,另一方面(消費者|服務提供者),會以該別名的方式去注冊中心上獲取到實際的服務服務通訊地址,然后再實作本低RPC呼叫RPC遠程呼叫框架核心設計思想:在于注冊中心,因為注冊中心管理每個服務與服務之間的一個依賴關系(服務治理概念),在任何RPC遠程框架中,都會有一個注冊中心(存放服務地址相關資訊(如:介面地址))
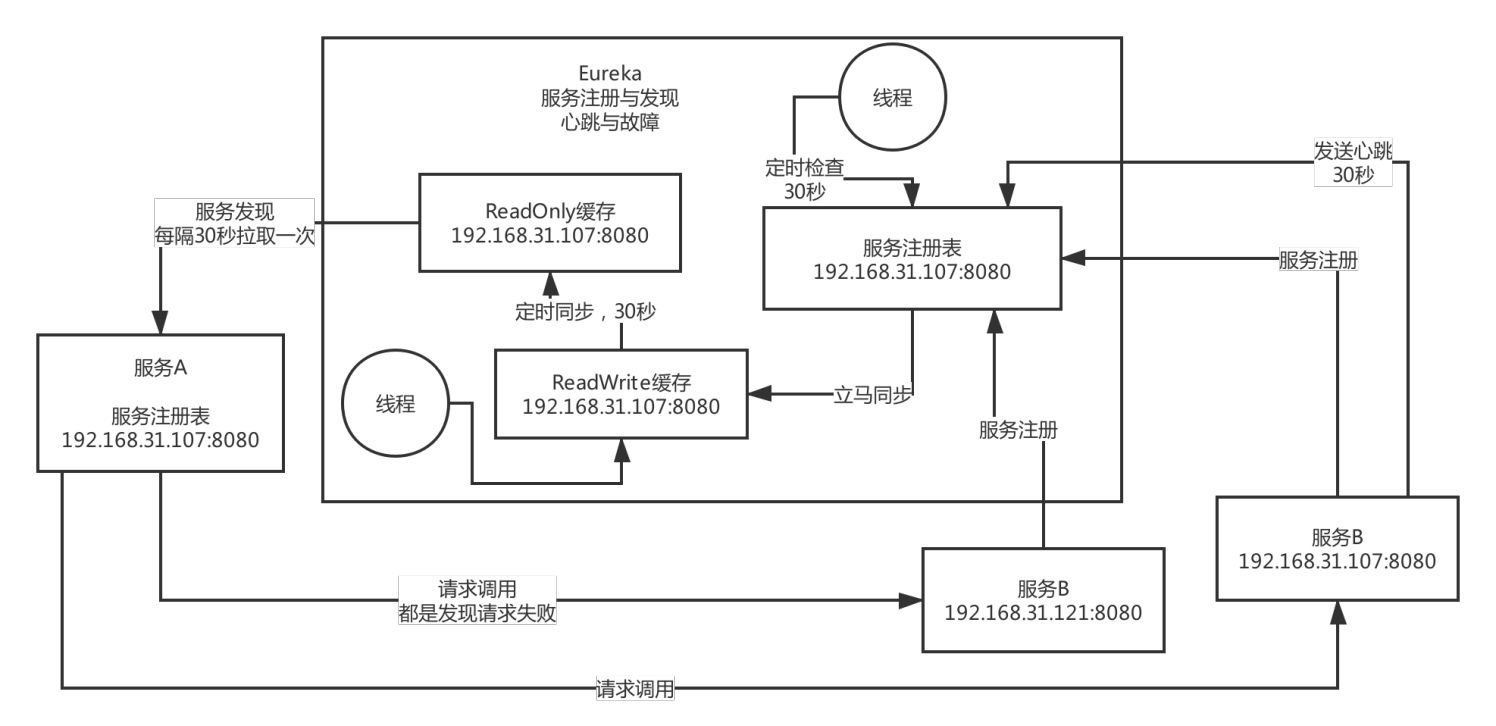
Eureka的使用規范
Eureka兩個組件
-
1.Eureka Server 提供服務注冊 服務
各個微服務節點通過配置啟動之后,會在Eureka Server中進行注冊,這樣Eureka Server中的服務注冊表將會存盤所有可用服務節點的資訊,服務節點的資訊可以在界面中直觀看到,
-
2.Eureka Client通過注冊中心進行訪問
本質是一個java客戶端,用于簡化Eureka Server 的互動,客戶端同時也具備一個內置的,使用輪詢(round-robin)負載演算法的負載均衡器,在應用啟動后,將會向Eureka Server發送心跳(默認周期為30s),如果Eureka Server在多個心跳周期內沒有接收到某個節點的心跳,Eureka Server將會從注冊服務表中把這個服務節點移除(默認90s),
Eureka怎么實作高可用(搭建集群)
Eureka 的集群搭建方法很簡單:每一臺 Eureka 只需要在配置中指定另外多個 Eureka 的地址就可以實作一個集群的搭建了,
什么是Eureka的自我保護模式
默認情況下,如果Eureka Service在一定時間內沒有接收到某個微服務的心跳,Eureka Service會進入自我保護模式,在該模式下Eureka Service會保護服務注冊表中的資訊,不在洗掉注冊表中的資料,當網路故障恢復后,Eureka Servic 節點會自動退出自我保護模式(好死不如賴活著)
在測驗環境中不建議開啟這個引數,生產環境中建議開啟
測驗用例
我是跟著尚硅谷周陽老師學習的,這里附上視頻地址
具體架構如下:
配置Eureka只需要實作一個springboot的主啟動類就可以了,我寫了兩個是因為需要搭建集群,你也可以寫三個或者更多,
eureka-server-7001服務模塊
server:
port: 7001
eureka:
instance:
hostname: eureka7001.com # eureka服務端的實體名稱
client:
register-with-eureka: false # false表示不向注冊中心注冊自己
fetch-registry: false # false表示自己端就是注冊中心,職責就是維護實體,并不需要去檢索服務
service-url:
# 設定與Eureka Server互動的地址查詢服務和注冊服務都需要依賴這個地址
defaultZone: http://eureka7002.com:7002/eureka/
server:
enable-self-preservation: true # eureka默認的保護機制,默認開啟true 在此保護機制下,eureka不會因為微服務的突然停止而終止服務
eviction-interval-timer-in-ms: 0 # eureka默認的保護機制踢除時間
@SpringBootApplication
@EnableEurekaServer// 開啟Eureka注冊服務中心
public class EurekaMain7001 {
public static void main(String[] args) {
SpringApplication.run(EurekaMain7001.class,args);
}
}
cloud-provider-payment-8001生產者模塊
server:
port: 8001
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
# defaultZone: http://localhost:7001/eureka 單機版
defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka # 集群版
instance:
instance-id: payment8001
prefer-ip-address: true # 訪問路徑可以顯示IP地址
# eureka客戶端向服務端發送心跳的時間間隔,單位為秒(默認30s)
lease-renewal-interval-in-seconds: 1
# eureka服務端在收到最后一次心跳后的等待時間上限,單位為秒(默認90s),超時將剔除服務
lease-expiration-duration-in-seconds: 2
#配置mybatis
mybatis:
#設定別名
mapperLocations: classpath:mapper/*.xml
type-aliases-package: com.simple.springcloud.entities
configuration:
map-underscore-to-camel-case: true #開啟這個的作用是可以讓資料庫中的p_Addr與pojo中的pAddr對應
@SpringBootApplication
@EnableEurekaClient // 通過注冊中心進行訪問
@EnableDiscoveryClient
@MapperScan("com.simple.springcloud.dao")
public class PaymentMain8001 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain8001.class,args);
}
}
Zookeeper
Zookeeper的基礎概念
什么是Zookeeper?
ZooKeeper是一個經典的分布式資料一致性解決方案,致力于為分布式應用提供一個高性能、高可用,且具有嚴格順序訪問控制能力的分布式協調服務,
分布式應用程式可以基于ZooKeeper實作資料發布與訂閱、負載均衡、命名服務、分布式協調與通知、集群管理、Leader選舉、分布式鎖、分布式佇列等功能,
總結:zookeeper是一個分布式協調工具,可以實作注冊中心功能
Zookeeper目標
ZooKeeper致力于為分布式應用提供一個高性能、高可用,且具有嚴格順序訪問控制能力的分布式協調服務
- 高性能
ZooKeeper將全量資料存盤在記憶體中,并直接服務于客戶端的所有非事務請求,尤其適用于以讀為主的應用場景
- 高可用
ZooKeeper一般以集群的方式對外提供服務,一般3 ~ 5臺機器就可以組成一個可用的Zookeeper集群了,每臺機器都會在記憶體中維護當前的服務器狀態,并且每臺機器之間都相互保持著通信,只要集群中超過一般的機器都能夠正常作業,那么整個集群就能夠正常對外服務
- 嚴格順序訪問
對于來自客戶端的每個更新請求,ZooKeeper都會分配一個全域唯一的遞增編號,這個編號反映了所有事務操作的先后順序
ZooKeeper五大特性
- 順序一致性
從同一個客戶端發起的請求,最終將會嚴格按照其發送順序進入ZooKeeper中
- 原子性
所有請求的回應結果在整個分布式集群環境中具備原子性,即要么整個集群中所有機器都成功的處理了某個請求,要么就都沒有處理,絕對不會出現集群中一部分機器處理了某一個請求,而另一部分機器卻沒有處理的情況
- 單一性
無論客戶端連接到ZooKeeper集群中哪個服務器,每個客戶端所看到的服務端模型都是一致的,不可能出現兩種不同的資料狀態,因為ZooKeeper集群中每臺服務器之間會進行資料同步
- 可靠性
一旦服務端資料的狀態發送了變化,就會立即存盤起來,除非此時有另一個請求對其進行了變更,否則資料一定是可靠的
- 實時性
當某個請求被成功處理后,ZooKeeper僅僅保證在一定的時間段內,客戶端最終一定能從服務端上讀取到最新的資料狀態,即ZooKeeper保證資料的最終一致性
Zookeeper集群角色
在分布式系統中,集群中每臺機器都有自己的角色,ZooKeeper沒有沿用傳統的Master/Slave模式(主備模式),而是引入了Leader、Follower和Observer三種角色
-
Leader
集群通過一個Leader選舉程序從所有的機器中選舉一臺機器作為”Leader”,Leader能為客戶端提供讀和寫服務
Leader服務器是整個集群作業機制的核心,主要作業:
- 事務請求的唯一調度者和處理者,保證集群事務處理的順序性
- 集群內部各服務器的調度者
-
Follower
顧名思義,Follower是追隨者,主要作業:
- 參與Leader選舉投票
- 處理客戶端非事務請求 - 即讀服務
- 轉發事務請求給Leader服務器
- 參與事務請求Proposal的投票
-
Observer
Observer是ZooKeeper自3.3.0版本開始引入的一個全新的服務器角色,充當一個觀察者角色,作業原理和Follower基本是一致的,和Follower唯一的區別是Observer不參與任何形式的投票
處理客戶端非事務請求 - 即讀服務
轉發事務請求給Leader服務器
不參與Leader選舉投票
參與事務請求Proposal的投票
所以Observer可以在不影響寫性能的情況下提升集群的讀性能
測驗用例
cloud-provider-payment-8004
server:
port: 8004
spring:
application:
name: cloud-provider-payment
cloud:
zookeeper:
connect-string: 192.168.136.140:2181
@SpringBootApplication
@EnableDiscoveryClient // 服務發現組件
public class PaymentMain8004 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain8004.class,args);
}
}
@RestController
@Slf4j
public class PaymentController {
@Value("${server.port}")
private String serverPort;
@GetMapping(value = "/payment/zk")
public String paymentzk(){
return "springcloud with zookeeper:"+serverPort+"\t"+ UUID.randomUUID().toString();
}
}
此時的服務節點為臨時節點
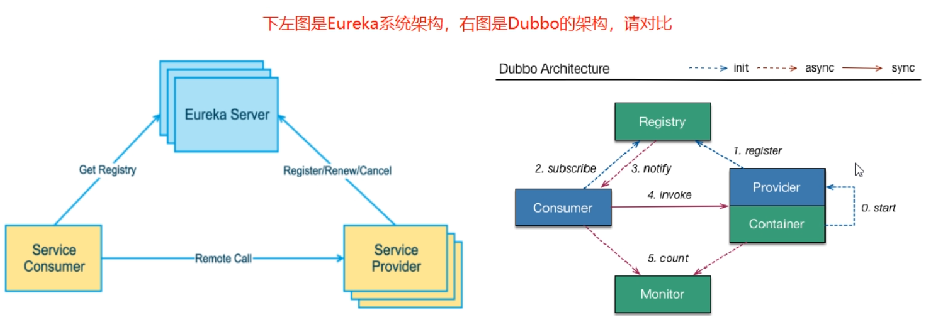
Eureka和ZooKeeper的區別
Eureka和ZooKeeper都可以提供服務注冊與發現的功能,那么區別是什么呢
Dubbo作為服務框架的,一般注冊中心會選擇Zookeeper
Spring Cloud作為服務框架的,一般服務注冊中心會選擇Eureka
DiscoveryClient的作用
- 可以從注冊中心中根據服務別名獲取注冊的服務器資訊,
服務注冊發現的原理
Eureka的集群架構
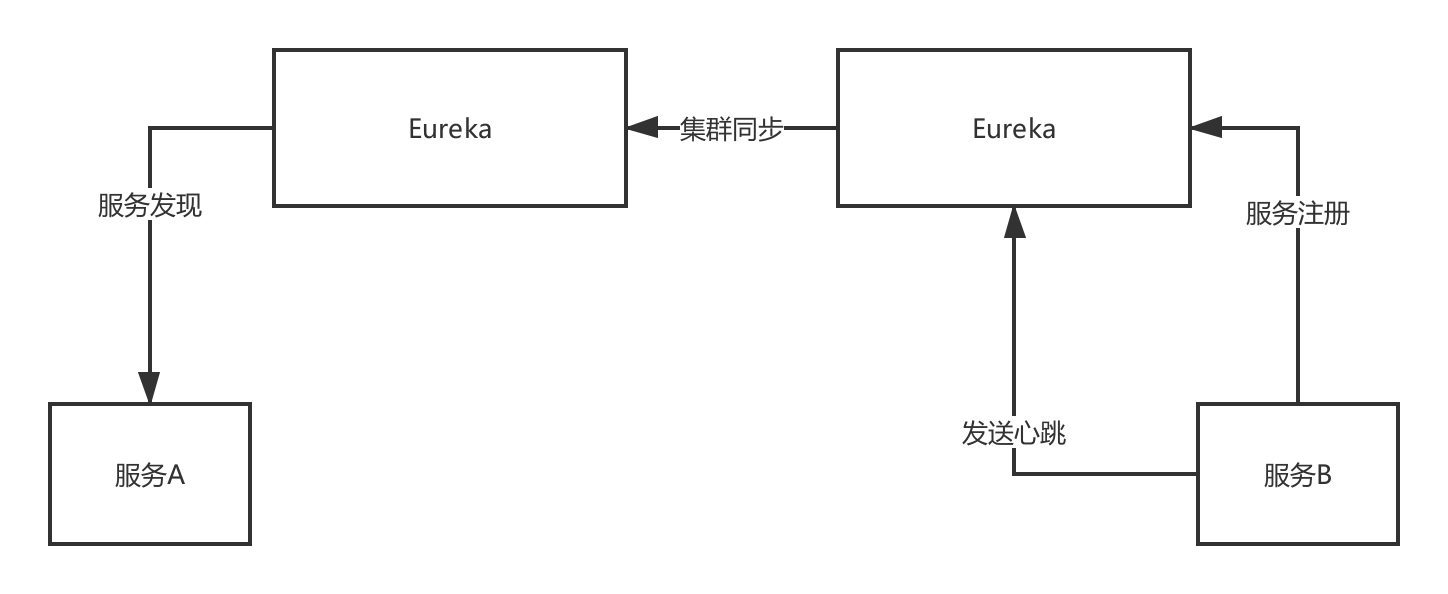
Eureka,peer-to-peer,部署一個集群,但是集群里每個機器的地位是對等的,各個服務可以向任何一個Eureka實體服務注冊和服務發現,集群里任何一個Euerka實體接收到寫請求之后,會自動同步給其他所有的Eureka實體
Zookeeper的集群架構
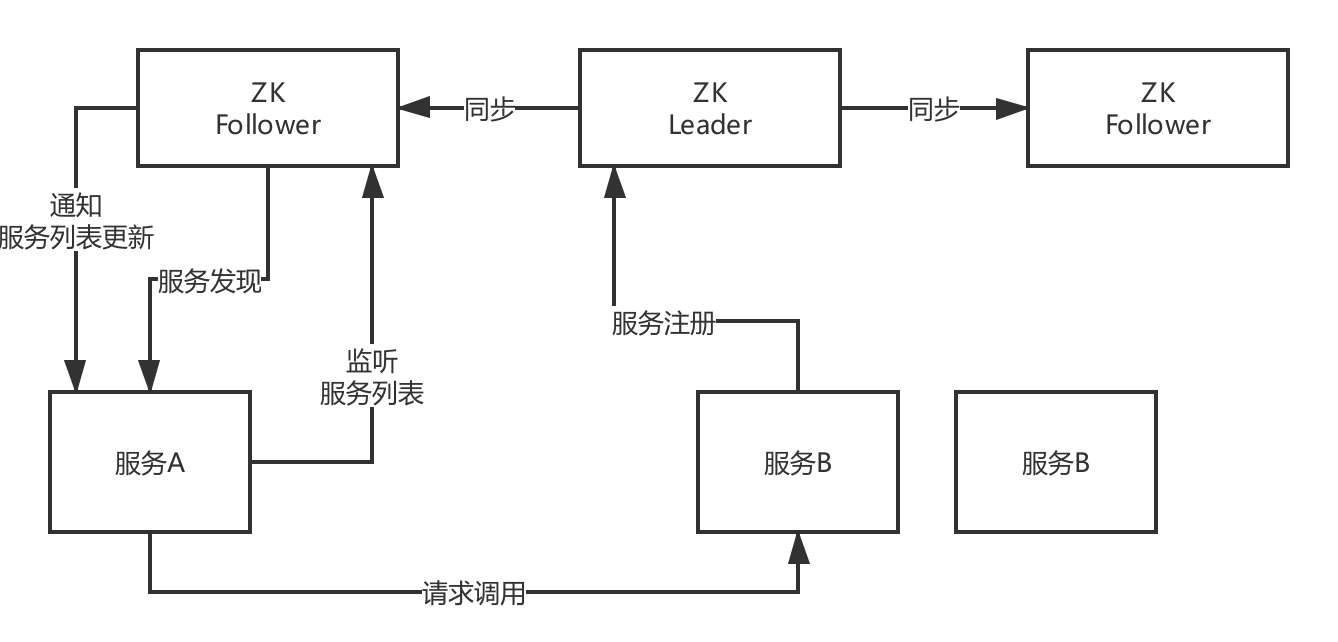
ZooKeeper,服務注冊和發現的原理,Leader + Follower兩種角色,只有Leader可以負責寫也就是服務注冊,他可以把資料同步給Follower,讀的時候leader/follower都可以讀
Eureka和Zookeeper的區別
- ZooKeeper中的節點服務掛了就要選舉
在選舉期間注冊服務癱瘓,雖然服務最侄訓恢復,但是選舉期間不可用的,
選舉就是改微服務做了集群,必須有一臺主其他的都是從 - Eureka各個節點是平等關系,服務器掛了沒關系,只要有一臺Eureka就可以保證服務可用,資料都是最新的,
如果查詢到的資料并不是最新的,就是因為Eureka的自我保護模式導致的 - Eureka本質上是一個工程,而ZooKeeper只是一個行程
- Eureka可以很好的應對因網路故障導致部分節點失去聯系的情況,而不會像ZooKeeper 一樣使得整個注冊系統癱瘓
- ZooKeeper保證的是CP,Eureka保證的是AP
服務的一致性保障(CAP)
CAP理論關注粒度是資料,而不是整體系統設計的策略
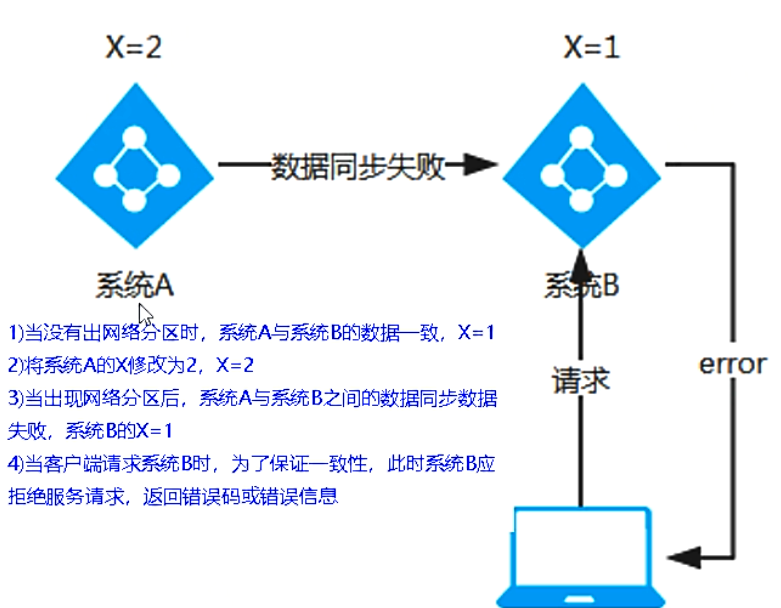
AP架構(Eureka)
當網路磁區出現后,為了保證可用性,系統B可以回傳舊值,保證系統的可用性
結論:違背了一致性C的要求,只滿足可用性和磁區容錯,即AP
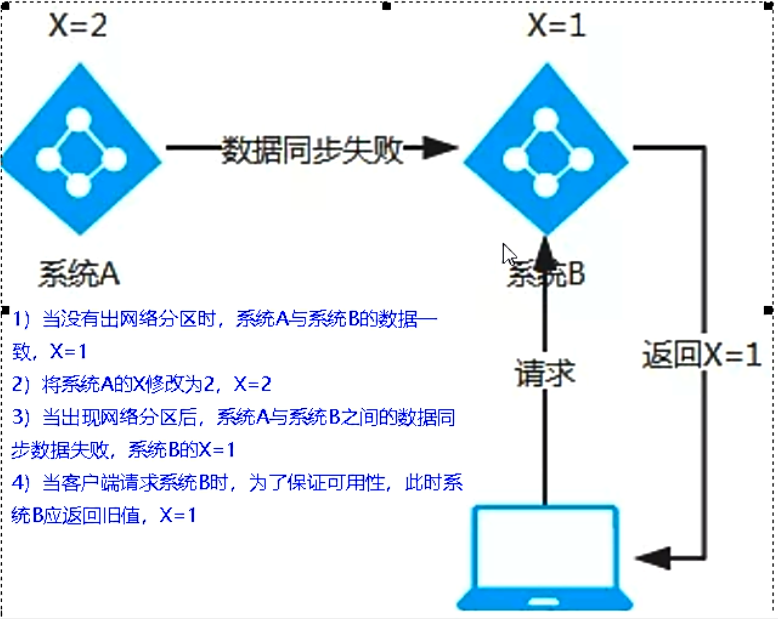
CP架構(Zookeeper/Consul)
當網路磁區出現后,為了保證一致性,就必須拒絕請求,否則無法保證一致性
結論:違背了可用性A的要求,只滿足一致性和磁區容錯,即CP
CAP理論的核心是:一個分布式系統不可能很好的滿足一致性,可用性和磁區容錯性這三個需求,因此,根據CAP原理將NoSQL分成了滿足CA原則,滿足CP原則,和滿足AP原則三大類
CA:單點集群,滿足一致性,可用性的系統,通常在可拓展性上不太強大
CP:滿足一致性,磁區容忍性的分析,通常性能不是很好
AP:滿足可用性,磁區容忍性的系統,通常可能對一致性要求低一些
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-A3at4vSn-1617551613997)(…/…/AppData/Local/Temp/mindmaster/9252b142206/001/24828D79-251B-488C-A71A-4332FD60E754.png)]
C:一致性,Consistency;
取舍:(強一致性、單調一致性、會話一致性、最終一致性、弱一致性)
A:可用性,Availability;
P:磁區容錯性,Partition tolerance;
ZooKeeper是有一個leader節點會接收資料, 然后同步寫其他節點,一旦leader掛了,要重新選舉leader,這個程序里為了保證C,就犧牲了A,不可用一段時間,但是一個leader選舉好了,那么就可以繼續寫資料了,保證一致性
Eureka是peer模式,可能還沒同步資料過去,結果自己就死了,此時還是可以繼續從別的機器上拉取注冊表,但是看到的就不是最新的資料了,但是保證了可用性,強一致,最終一致性
服務注冊發現的時效性
Zookeeper,時效性更好,注冊或者是掛了,一般秒級就能感知到
Eureka,默認配置非常糟糕,服務發現感知要到幾十秒,甚至分鐘級別,上線一個新的服務實體,到其他人可以發現他,極端情況下,可能要1分鐘的時間,ribbon去獲取每個服務上快取的eureka的注冊表進行負載均衡
服務故障,隔60秒才去檢查心跳,發現這個服務上一次心跳是在60秒之前,隔60秒去檢查心跳,超過90秒沒有心跳,才會認為他死了,2分鐘都過去
30秒,才會更新快取,30秒,其他服務才會來拉取最新的注冊表
三分鐘都過去了,如果你的服務實體掛掉了,此時別人感知到,可能要兩三分鐘的時間,一兩分鐘的時間,很漫長
容量
ZooKeeper,不適合大規模的服務實體,因為服務上下線的時候,需要瞬間推送資料通知到所有的其他服務實體,所以一旦服務規模太大,到了幾千個服務實體的時候,會導致網路帶寬被大量占用
Eureka,也很難支撐大規模的服務實體,因為每個Eureka實體都要接受所有的請求,實體多了壓力太大,扛不住,也很難到幾千服務實體
之前dubbo技術體系都是用Zookeeper當注冊中心,spring cloud技術體系都是用Eureka當注冊中心這兩種是運用最廣泛的,但是現在很多中小型公司以spring cloud居多,所以后面基于Eureka說一下服務注冊中心的生產優化
服務過慢的優化方法
Zookeeper,一般來說還好,服務注冊和發現,都是很快的
Eureka,必須優化引數
- 服務器到注冊中心心跳時間設定
- 注冊中心定時檢測心跳時間設定
- 心跳失效時間設定
- readWrite快取定更新到readOnly時間設定
- 客戶端定時拉取readWrite快取時間設定
Consul
Consul的基礎概念
Consul 是 HashiCorp 公司推出的開源工具,用于實作分布式系統的服務發現與配置,與其它分布式服務注冊與發現的方案,Consul 的方案更“一站式”,內置了服務注冊與發現框架、分布一致性協議實作、健康檢查、Key/Value 存盤、多資料中心方案,不再需要依賴其它工具(比如 ZooKeeper 等),使用起來也較為簡單,
Consul 使用 Go 語言撰寫,因此具有天然可移植性(支持Linux、windows和Mac OS X);安裝包僅包含一個可執行檔案,方便部署,與 Docker 等輕量級容器可無縫配合,
什么是Consul
Consul是一個基于CP的輕量級分布式高可用的系統,提供服務發現、健康檢查、K-V存盤、多資料中心等功能,不需要再依賴其他組件(Zookeeper、Eureka、Etcd等),
-
服務發現:提供HTTP和DNS兩種發現方式
Consul可以提供一個服務,比如api或者MySQL之類的,其他客戶端可以使用Consul發現一個指定的服務提供者,并通過DNS和HTTP應用程式可以很容易的找到所依賴的服務,
-
健康檢查:支持多種協議,HTTP、TCP、Docker、Shell腳本定制化
Consul客戶端提供相應的健康檢查介面,Consul服務端通過呼叫健康檢查介面檢測客戶端是否正常
-
K-V存盤:
客戶端可以使用Consul層級的Key/Value存盤,比如動態配置,功能標記,協調,領袖選舉等等
-
多資料中心:
Consul支持開箱即用的多資料中心
Consul的使用場景
docker 實體的注冊與配置共享
coreos 實體的注冊與配置共享
vitess 集群
SaaS 應用的配置共享
與 confd 服務集成,動態生成 nginx 和 haproxy 組態檔
Consul的作用
client: 客戶端, 無狀態, 將 HTTP 和 DNS 介面請求轉發給局域網內的服務端集群.server: 服務端, 保存配置資訊, 高可用集群, 在局域網內與本地客戶端通訊, 通過廣域網與其他資料中心通訊. 每個資料中心的 server 數量推薦為 3 個或是 5 個.
由于Spring Cloud Consul專案的實作,我們可以輕松的將基于Spring Boot的微服務應用注冊到Consul上,并通過此實作微服務架構中的服務治理,
Consul常用命令
| 命令 | 解釋 | 示例 |
|---|---|---|
| agent | 運行一個consul agent | consul agent -dev |
| join | 將agent加入到consul集群 | consul join IP |
| members | 列出consul cluster的members | consul members |
| leave | 將節點移除所在集群 | consul leave |
Consul agent命令的常用選項
-data-dir
作用:指定agent儲存狀態的資料目錄
這是所有agent都必須的
對于server尤其重要,因為他們必須持久化集群的狀態
-config-dir
作用:指定service的組態檔和檢查定義所在的位置
通常會指定為”某一個路徑/consul.d”(通常情況下,.d表示一系列組態檔存放的目錄)
-config-file
作用:指定一個要裝載的組態檔
該選項可以配置多次,進而配置多個組態檔(后邊的會合并前邊的,相同的值覆寫)
-dev
作用:創建一個開發環境下的server節點
該引數配置下,不會有任何持久化操作,即不會有任何資料寫入到磁盤
這種模式不能用于生產環境(因為第二條)
-bootstrap-expect
- 作用:該命令通知consul server我們現在準備加入的server節點個數,該引數是為了延遲日志復制的啟動直到我們指定數量的server節點成功的加入后啟動,
-node
作用:指定節點在集群中的名稱
該名稱在集群中必須是唯一的(默認采用機器的host)
推薦:直接采用機器的IP
-bind
作用:指明節點的IP地址
有時候不指定系結IP,會報Failed to get advertise address: Multiple private IPs found. Please configure one. 的例外
-server
作用:指定節點為server
每個資料中心(DC)的server數推薦至少為1,至多為5
所有的server都采用raft一致性演算法來確保事務的一致性和線性化,事務修改了集群的狀態,且集群的狀態保存在每一臺server上保證可用性
server也是與其他DC互動的門面(gateway)
-client
作用:指定節點為client,指定客戶端介面的系結地址,包括:HTTP、DNS、RPC
默認是127.0.0.1,只允許回環介面訪問
若不指定為-server,其實就是-client
-join
作用:將節點加入到集群
-datacenter(老版本叫-dc,-dc已經失效)
作用:指定機器加入到哪一個資料中心中
下載與啟動
直接去官方網站下載,下載完成之后只有一個consul檔案
在consul的相應路徑下啟動cmd
使用開發模式啟動: consul agent -dev
測驗用例
cloud-providerconsul-payment-8006
server:
port: 8006
spring:
application:
name: consul-provider-payment
###consul注冊中心地址
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
@SpringBootApplication
@EnableDiscoveryClient
public class PaymentMain8006 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain8006.class,args);
}
}
@RestController
@Slf4j
public class PaymentController {
@Value("${server.port}")
private String serverPort;
@RequestMapping(value = "/payment/consul")
public String paymentConsul(){
//后面這個是流水號,會一直變的
return "springcloud with consul:"+serverPort + "\t"+ UUID.randomUUID().toString();
}
}
Ribbon負載均衡
Ribbon的基礎概念
Ribbon是什么
- Ribbon是Netflix發布的開源專案,主要功能是提供客戶端的軟體負載均衡演算法
- Ribbon客戶端組件提供一系列完善的配置項,如連接超時,重試等,簡單的說,就是在組態檔中列出后面所有的機器,Ribbon會自動的幫助你基于某種規則(如簡單輪詢,隨即連接等)去連接這些機器,我們也很容易使用Ribbon實作自定義的負載均衡演算法,(有點類似Nginx)
LB負載均衡的分類
集中式LB
即在服務的消費方和提供方之間使用獨立的LB設施(可以是硬體,F5,也可以是軟體,nginx)由該設施負責把訪問請求通過某種策略轉發至服務的提供方
行程內LB
將LB邏輯集成到消費方,消費方從服務之策中心獲知有那些地址可用,然后自己再從這些地址中選擇出一個合適的服務器,
Ribbon就屬于行程內LB,他只是一個類別庫,集成于消費方行程,消費方通過它來獲取到服務提供方的地址,
LB是什么?
簡單的說法就是將用戶的請求平攤的分配到多個服務上,從而達到系統的HA(高可用),
常見的負載均衡有軟體nginx,LVS,硬體F5等,
Nginx與Ribbon的區別
Nginx是服務器負載均衡,客戶端的所有請求都會交給nginx,然后由nginx實作轉發請求,即負載均衡是由服務端處理,
Nginx是反向代理同時可以實作負載均衡,nginx攔截客戶端請求采用負載均衡策略根據upstream配置進行轉發,相當于請求通過nginx服務器進行轉發,
Ribbon是客戶端負載均衡,又稱本地負載均衡,在呼叫微服務介面時,會在注冊中心上獲取注冊資訊服務串列之后快取到JVM本地,
從注冊中心讀取目標服務器資訊,然后客戶端采用輪詢策略對服務直接訪問,全程在客戶端操作,
總結:Ribbon其實就是一個軟負載均衡的客戶端組件,他可以和其他所需請求的客戶端結合使用,和eureka結合只是其中的一個實體,
Ribbon的作業步驟
Ribbon在作業時分成兩步
- 1.先選擇Eureka Server ,他優先選擇在同一個區域內負載較少的server
- 2.再根據用戶指定的策略,在從server取到的服務注冊串列中選擇一個地址,其中Ribbon提供了多種策略,比如輪詢,隨機和根據回應時間加權,
使用@LoadBalanced注解開啟客戶端負載均衡
RestTemplate的使用
RestTemplate的官網
RestTemplate的簡介
RestTemplate 是從 Spring3.0 開始支持的一個 HTTP 請求工具,它提供了常見的REST請求方案的模版,例如 GET 請求、POST 請求、PUT 請求、DELETE 請求以及一些通用的請求執行方法 exchange 以及 execute,RestTemplate 繼承自 InterceptingHttpAccessor 并且實作了 RestOperations 介面,其中 RestOperations 介面定義了基本的 RESTful 操作,這些操作在 RestTemplate 中都得到了實作,接下來我們就來看看這些操作方法的使用,
GET請求
在 RestTemplate 中,和 GET 請求相關的方法有如下幾個:

這里的方法一共有兩類,getForEntity 和 getForObject,每一類有三個多載方法,下面我們分別予以介紹,
getForEntity
既然 RestTemplate 發送的是 HTTP 請求,那么在回應的資料中必然也有回應頭,如果開發者需要獲取回應頭的話,那么就需要使用 getForEntity 來發送 HTTP 請求,此時回傳的物件是一個 ResponseEntity 的實體,這個實體中包含了回應資料以及回應頭,例如,在 provider 中提供一個 HelloController 介面,HelloController 介面中定義一個 sayHello 的方法,如下:
@RestController
public class UseHelloController {
@Autowired
DiscoveryClient discoveryClient;
@Autowired
RestTemplate restTemplate;
@GetMapping("/hello")
public String hello(String name) {
List<ServiceInstance> list = discoveryClient.getInstances("provider");
ServiceInstance instance = list.get(0);
String host = instance.getHost();
int port = instance.getPort();
String url = "http://" + host + ":" + port + "/hello?name={1}";
ResponseEntity<String> responseEntity = restTemplate.getForEntity(url, String.class, name);
StringBuffer sb = new StringBuffer();
HttpStatus statusCode = responseEntity.getStatusCode();
String body = responseEntity.getBody();
sb.append("statusCode:")
.append(statusCode)
.append("</br>")
.append("body:")
.append(body)
.append("</br>");
HttpHeaders headers = responseEntity.getHeaders();
Set<String> keySet = headers.keySet();
for (String s : keySet) {
sb.append(s)
.append(":")
.append(headers.get(s))
.append("</br>");
}
return sb.toString();
}
}
getForObject
getForObject 方法和 getForEntity 方法類似,getForObject 方法也有三個多載的方法,引數和 getForEntity 一樣,因此這里我就不重復介紹引數了,這里主要說下 getForObject 和 getForEntity 的差異,這兩個的差異主要體現在回傳值的差異上, getForObject 的回傳值就是服務提供者回傳的資料,使用 getForObject 無法獲取到回應頭,例如,還是上面的請求,利用 getForObject 來發送 HTTP 請求,結果如下:
String url = "http://" + host + ":" + port + "/hello?name=" + URLEncoder.encode(name, "UTF-8");
URI uri = URI.create(url);
String s = restTemplate.getForObject(uri, String.class);
POST請求
和 GET 請求相比,RestTemplate 中的 POST 請求多了一個型別的方法,如下:

可以看到,post 請求的方法型別除了 postForEntity 和 postForObject 之外,還有一個 postForLocation,這里的方法型別雖然有三種,但是這三種方法多載的引數基本是一樣的,因此這里我還是以 postForEntity 方法為例,來剖析三個多載方法的用法,最后再重點說下 postForLocation 方法,
postForEntity
在 POST 請求中,引數的傳遞可以是 key/value 的形式,也可以是 JSON 資料,分別來看:
- 傳遞 key/value 形式的引數
首先在 provider 的 HelloController 類中再添加一個 POST 請求的介面,如下:
@GetMapping("/hello5")
public String hello5(String name) {
List<ServiceInstance> list = discoveryClient.getInstances("provider");
ServiceInstance instance = list.get(0);
String host = instance.getHost();
int port = instance.getPort();
String url = "http://" + host + ":" + port + "/hello2";
MultiValueMap map = new LinkedMultiValueMap();
map.add("name", name);
ResponseEntity<String> responseEntity = restTemplate.postForEntity(url, map, String.class);
return responseEntity.getBody();
}
在這里, postForEntity 方法第一個引數是請求地址,第二個引數 map 物件中存放著請求引數 key/value,第三個引數則是回傳的資料型別,當然這里的第一個引數 url 地址也可以換成一個 Uri 物件,效果是一樣的,這種方式傳遞的引數是以 key/value 形式傳遞的,在 post 請求中,也可以按照 get 請求的方式去傳遞 key/value 形式的引數,傳遞方式和 get 請求的傳參方式基本一致,例如下面這樣:
@GetMapping("/hello6")
public String hello6(String name) {
List<ServiceInstance> list = discoveryClient.getInstances("provider");
ServiceInstance instance = list.get(0);
String host = instance.getHost();
int port = instance.getPort();
String url = "http://" + host + ":" + port + "/hello2?name={1}";
ResponseEntity<String> responseEntity = restTemplate.postForEntity(url, null, String.class,name);
return responseEntity.getBody();
}
postForObject
postForObject 和 postForEntity 基本一致,就是回傳型別不同而已,這里不再贅述,
Object
回傳物件為回應體中資料轉化成的物件,基本上可以理解為JSON
Entity
回傳物件為ResponseEntity物件,抱涵了回應中一些重要資訊,比如回應頭,回應狀態碼,回應體等
Ribbon負載均衡的演算法
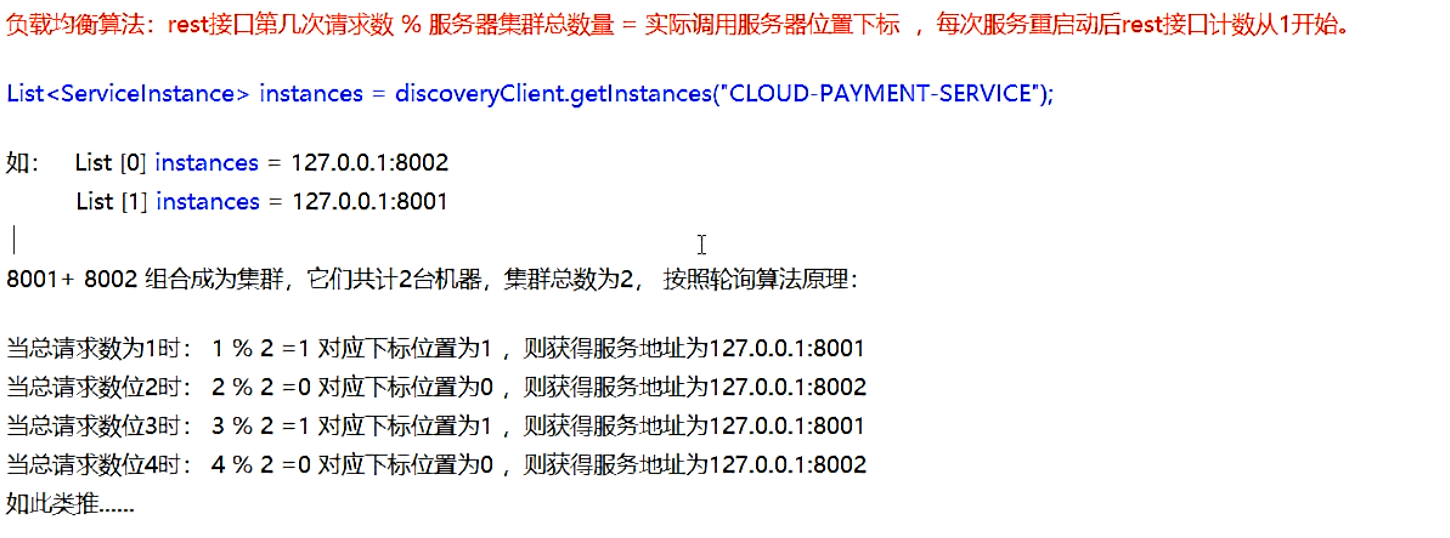
原理!
如果想要自己替換負載均衡演算法!需要注意規則
官方檔案明確給出了警告:
這個自定義配置類不能放在@ComponentScan所掃描的當前包下,否則我們自定義的這個配置類就會被所有Ribbon客戶端所共享,就達不到特殊化定制的目的了!
@Configuration
public class MySelfRule {
@Bean
public IRule myRule(){
return new RandomRule();//定義為隨機
}
}
最后在主啟動類加入一個注解
@RibbonClient(name="",configuration = .class)
@SpringBootApplication
@EnableEurekaClient
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE",configuration = MySelfRule.class)
public class OrderMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderMain80.class,args);
}
}
手寫負載均衡演算法原理
@Component
public class MyLB implements LoadBalancer {
private AtomicInteger atomicInteger = new AtomicInteger(0);
//坐標
private final int getAndIncrement(){
int current;
int next;
do {
current = this.atomicInteger.get();
next = current >= 2147483647 ? 0 : current + 1;
}while (!this.atomicInteger.compareAndSet(current,next)); //第一個引數是期望值,第二個引數是修改值是
System.out.println("*******第幾次訪問,次數next: "+next);
return next;
}
@Override
public ServiceInstance instances(List<ServiceInstance> serviceInstances) { //得到機器的串列
int index = getAndIncrement() % serviceInstances.size(); //得到服務器的下標位置
return serviceInstances.get(index);
}
}
@GetMapping(value = "/consumer/payment/lb")
public String getPaymentLB(){
List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
if (instances == null || instances.size() <= 0){
return null;
}
ServiceInstance serviceInstance = loadBalancer.instances(instances);
URI uri = serviceInstance.getUri();
return restTemplate.getForObject(uri+"/payment/lb",String.class);
}
OpenFeign
OpenFeign的基礎概念
Feign是什么
feign是netflix開發的宣告式,模板化的HTTP客戶端,Feign可以幫助我們更加便捷,優雅的呼叫HTTP API,
Feign原理
在配置類上,加上@EnableFeginClients,那么該注解是基于@Import注解,注冊有關Fegin的決議注冊類,這個類是實作 ImportBeanDefinitionRegistrar 這個介面,重寫registryBeanDefinition 方法,
他會掃描所有加了@FeginClient 的介面,然后針對這個注解的介面生成動態代理,然后你針對fegin的動態代理去呼叫他方法的時候,此時會在底層生成http協議格式的請求,
Feign能干什么
Feign旨在使撰寫Java Http客戶端變得更加容易,
前面在使用Ribbon+RestTemplate時,利用RestTemplate對http請求的封裝處理,行程了一套模板化的呼叫方法,但是實際開發中對于服務依賴的呼叫可能不止一處,往往一個介面會被多次呼叫,所以通常都會針對每個微服務自行封裝一些客戶端來包裝這些依賴服務的呼叫,
在Feign的實作下,我們只需要創建一個介面并使用注解的方式來配置他(以前是Dao介面上面標注Mapper注解,現在是一個微服務介面上標注一個Feign注解即可)即可完成對服務提供方的介面系結,簡化了使用springcloud時,自動封裝呼叫客戶端的開發量
Feign集成了Ribbon
利用Ribbon維護了Payment的服務串列資訊,并且通過輪詢實作了客戶端的負載均衡,但是與Ribbon不同的是,通過feign只需要定義服務系結介面且以宣告式的方法,

測驗用例
cloud-consumer-feign-order-80
這里feign集成了我們的ribbon,eureka也集成了ribbon,前提都是新版本
server:
port: 80
eureka:
client:
register-with-eureka: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka, http://eureka7002.com:7002/eureka
@SpringBootApplication
@EnableFeignClients
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE")
public class OrderFeignMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderFeignMain80.class,args);
}
}
@Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")//這里就是微服務名稱
public interface PaymentFeignService {
//客戶端需要向瀏覽器回傳一個狀態值,所以需要包起來~
@GetMapping(value = "/payment/get/{id}")
public CommonResult getPaymentById(@PathVariable("id") Long id);
}
@RestController
@Slf4j
public class OrderFeignController {
@Resource
private PaymentFeignService paymentFeignService;
@GetMapping(value = "/consumer/payment/get/{id}")
public CommonResult getPaymentById(@PathVariable("id") Long id){
return paymentFeignService.getPaymentById(id);
}
}
往簡單了想,feign就是把ribbon集成了,把restTemplate方式代替成結構的方式,更加體現面向介面編程的思想,搞完收工~
OpenFeign的控制以及日志功能
OpenFeign的超時控制
因為feign里面集成了ribbon,所以這里可以這樣寫,feign默認的超時時間是1s,如果超過了時間就會報錯,所以我們需要手動的在yml里面設定超時時間:
ribbon:
//這里指的是建立連接所用的時間
ReadTimeout: 5000
//這里指的是建立連接之后讀取到資源所用的時間
ConnectTimeout: 5000
OpenFeign日志列印功能
Feign提供了日志列印功能,我們可以呼叫配置來調整日志級別,從而了解Feign中Http請求的細節,
說白了就是對Feign介面的呼叫情況進行監控和輸出
NONE:默認的,不顯示任何日志;
BASIC:僅記錄請求方法,URL,回應狀態碼及執行時間;
HEADERS:除了BASIC中定義的資訊之外,還有請求和回應的頭資訊;
FULL:除了HEADERS中定義的資訊之外,還有請求和回應的正文及資料源
配置config:
@Configuration
public class FeignConfig {
//開啟詳細日志
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
YML檔案里需要開啟日志的Feign客戶端
logging:
level:
#配置feign日志以什么級別,監控哪個介面
com.yan.springcloud.service.PaymentFeignService: debug
SpringCloud有幾種呼叫介面方式
-
Feign
-
RestTemplate
Ribbon和Feign呼叫服務的區別
- 呼叫方式同:Ribbon需要我們自己構建Http請求,模擬Http請求然后通過RestTemplate發給其他服務,步驟相當繁瑣
- 而Feign則是在Ribbon的基礎上進行了一次改進,采用介面的形式,將我們需要呼叫的服務方法定義成抽象方法保存在本地就可以了,不需要自己構建Http請求了,直接呼叫介面就行了,不過要注意,呼叫方法要和本地抽象方法的簽名完全一致,
Spring Cloud Netflix(重點,這些組件用的最多)
Netflix OSS 開源組件集成,包括Eureka、Hystrix、Ribbon、Feign、Zuul等核心組件,
-
Eureka:服務治理組件,包括服務端的注冊中心和客戶端的服務發現機制;
-
Ribbon:負載均衡的服務呼叫組件,具有多種負載均衡呼叫策略;
-
Hystrix:服務容錯組件,實作了斷路器模式,為依賴服務的出錯和延遲提供了容錯能力;
-
Feign:基于Ribbon和Hystrix的宣告式服務呼叫組件;
-
Zuul:API網關組件,對請求提供路由及過濾功能,
我覺得SpringCloud的福音是Netflix,他把人家的組件都搬來進行封裝了,使開發者能快速簡單安全的使用
:僅記錄請求方法,URL,回應狀態碼及執行時間;**
HEADERS:除了BASIC中定義的資訊之外,還有請求和回應的頭資訊;
FULL:除了HEADERS中定義的資訊之外,還有請求和回應的正文及資料源
配置config:
@Configuration
public class FeignConfig {
//開啟詳細日志
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
YML檔案里需要開啟日志的Feign客戶端
logging:
level:
#配置feign日志以什么級別,監控哪個介面
com.yan.springcloud.service.PaymentFeignService: debug
SpringCloud有幾種呼叫介面方式
-
Feign
-
RestTemplate
Ribbon和Feign呼叫服務的區別
- 呼叫方式同:Ribbon需要我們自己構建Http請求,模擬Http請求然后通過RestTemplate發給其他服務,步驟相當繁瑣
- 而Feign則是在Ribbon的基礎上進行了一次改進,采用介面的形式,將我們需要呼叫的服務方法定義成抽象方法保存在本地就可以了,不需要自己構建Http請求了,直接呼叫介面就行了,不過要注意,呼叫方法要和本地抽象方法的簽名完全一致,
Spring Cloud Netflix(重點,這些組件用的最多)
Netflix OSS 開源組件集成,包括Eureka、Hystrix、Ribbon、Feign、Zuul等核心組件,
-
Eureka:服務治理組件,包括服務端的注冊中心和客戶端的服務發現機制;
-
Ribbon:負載均衡的服務呼叫組件,具有多種負載均衡呼叫策略;
-
Hystrix:服務容錯組件,實作了斷路器模式,為依賴服務的出錯和延遲提供了容錯能力;
-
Feign:基于Ribbon和Hystrix的宣告式服務呼叫組件;
-
Zuul:API網關組件,對請求提供路由及過濾功能,
我覺得SpringCloud的福音是Netflix,他把人家的組件都搬來進行封裝了,使開發者能快速簡單安全的使用
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/272637.html
標籤:其他