CPU的cache作業原理
博主微信:flm13724054952,不懂的有疑惑的也可以加微信咨詢,歡迎大家前來指教共同探討,謝謝!博主最近的作業是CPU集成設計,所以接下來的篇章將以CPU的學習講解為主,最后再打個小廣告,歡迎各位對數字IC設計感興趣的博友來我們公司“眾星微”,可以內推哦,
1 about Cache
在思考CPU的架構為什么需要cache之前,我們首先來了解一下:CPU是如何運行軟體程式的,
我們應該知道程式是運行在 RAM之中,RAM 就是我們常說的DDR(L3: DDR、Flash等),我們稱之為main memory(主存),當我們需要運行一個行程的時候,首先會從磁盤設備(L4,CF card、UFS、SSD等)中將可執行程式load到主存中,然后開始執行,在CPU內部存在一堆的通用暫存器(register), 如果CPU需要將一個變數(假設地址是A)加1,一般分為以下3個步驟:(在沒有cache的情況下)
(1) CPU 從主存中讀取地址A的資料到內部通用暫存器 R0;(一個cycle)
(2) 通用暫存器 R0 加1;(一個cycle)
(3) CPU 將通用暫存器 x0 的值寫入主存,(幾十個cycle)
CPU系統里面cache與memory的層次結構流程圖會如下圖所示, 如果有cache作為主存與CPU之間的快取資料地帶,一方面變數不需要頻繁寫到主存先快取在cache里面,那么指令的執行時間將大大加快,另一方面CPU可以不用長時間占用總線的訪問,Cache是存在于主存與CPU之間的一級存盤器, 由靜態存盤芯片(SRAM)組成,容量比較小但速度比主存高得多, 接近于CPU的速度, Cache的功能是用來存放那些近期需要運行的指令與資料,目的是提高CPU對存盤器的訪問速度, 當CPU試圖從主存中load/store資料的時候, CPU會首先從cache中查找對應地址的資料是否快取在cache 中,如果其資料快取在cache中,直接從cache中拿到資料并回傳給CPU,
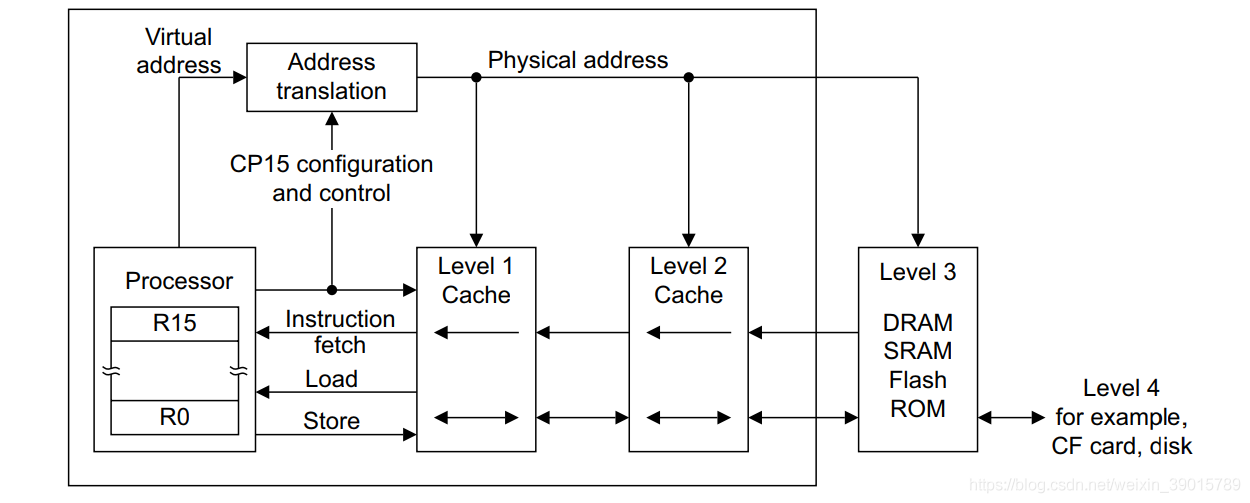
2 cache architecture
在傳統的CPU計算機架構里面,cache架構目前分為兩大架構諾依曼架構跟哈維架構,在諾依曼架構里面,一個cache同時用于指令與資料,是統一的一個Cache,在哈維架構里面,指令與資料總線是分開的,所以同時出現兩個Cache,I-Cache跟D-Cache,在arm的CPU系統里面,會有不同的指令與資料一級快取,由統一的L2-Cache支持,
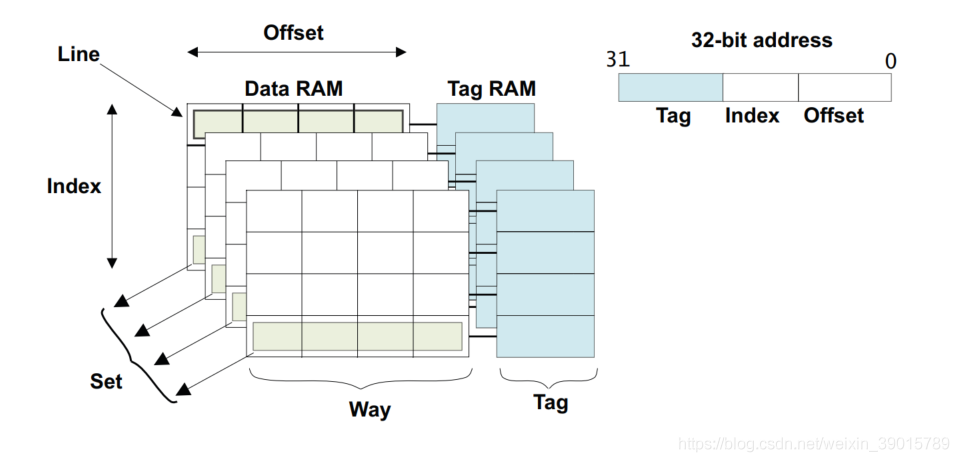
如下圖所示,在Cache的架構里面,I-Cache由data_ram跟tag_ram組成;D-Cache由data_ram,tag_ram,dirty_ram組成,
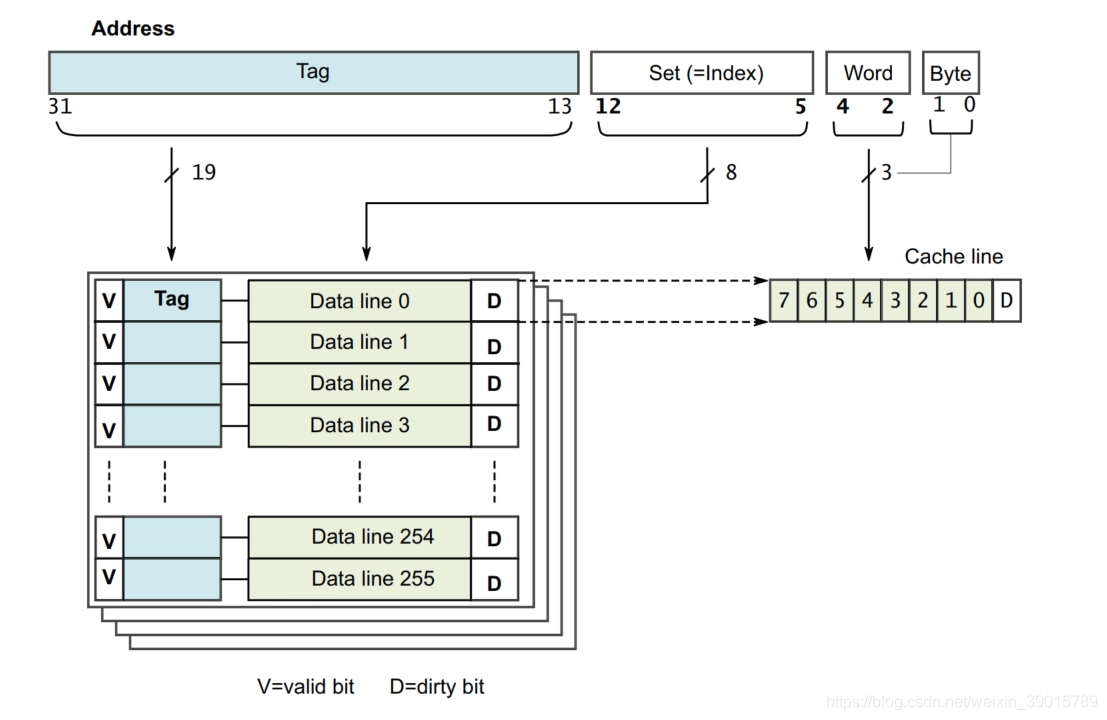
Cache line:CPU一次性從主快取搬移資料位寬的能力,如R5的cache line為32byte;
Cache tag:指示cache的資料對應來自主快取的哪個位置,同個cache line的tag是一樣的;
Cache index:指示將主快取的資料編譯到Cache的哪一行,決定了cache的size大小;
Cache way:將Cache均分成幾塊MEM來存盤,每一塊都稱為ways;
Cache hit:CPU在cache尋找資料時,如果tag與主存tag一致那就是快取命中;
Cache miss:CPU在cache尋找資料時,如果tag與主存tag不一致那就是快取缺失;
 data ram
data ram
在Cache的架構里面,data_ram就是對軟體呈現的快取資料的地方,
tag ram
在Cache的架構里面,tag_ram是告訴cache(data_ram)的資料是來自與主快取的對應位置,tag_ram里面還有一個valid bit來指示當前對應的cache_line的資料是否是有效的,
dirty ram
在Cache的架構里面,dirty ram僅僅是D-Cache所擁有,其作用是在指示當前D-Cache的資料是否與主快取一致,一致的話dirty為1,不一致的話dirty為0,
cache的容量
cache的容量計算如下:
(1)用cache line跟ways來計算容量:例如R5的cache line為32個位元組,D-Cache有4ways,(一個ways由兩個資料位寬32bits 資料深度1024lines的bank拼接在一起);所以cache容量占據32×4×1024×2÷8=32KB;
(2)用下圖資料位寬,深度,資料塊數來計算:所以cache容量占據32×1024×8÷8=32KB;
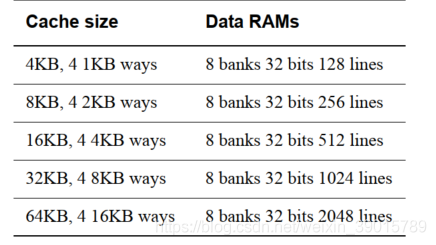 一個cache line一般還含有ag欄位和valid位,通常情況下我們都是用cache中資料部分占的空間表示cache的容量,也就是32位元組,但是實際上,它還額外多占用了tag ram跟dirty ram的存盤空間,
一個cache line一般還含有ag欄位和valid位,通常情況下我們都是用cache中資料部分占的空間表示cache的容量,也就是32位元組,但是實際上,它還額外多占用了tag ram跟dirty ram的存盤空間,
3 Cache maping
Cache的映射原則是根據cache index來定位主快取的資料應該搬移到cache的哪一行,然后把對應物理地址的tag資訊及地址對應資料放入對應的tag ram跟data ram,并把相關的valid位置1,后面當CPU要在cache尋找資料的時候就可以根據cache line的tag欄位來辨識當前的cache line資料是那個block的,
如下圖所示,Cache的映射方式有三種,直接映射(direct-mapping),組相連映射(set-associative-mapping),全相連映射(full-associative-mapping),
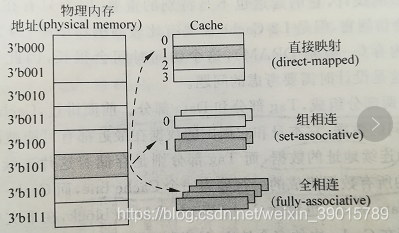
3.1 直接映射(direct-mapping)
直接映射快取是cache只有一個ways,搬移資料直接就在同一塊上快取;所以在硬體設計上會更加簡單,因此成本上也會較低,但是也會引入其他問題,如下圖所示,根據直接映射快取的作業方式,我們可以看到,地址0x00-0x3f地址處對應的資料可以覆寫整個cache,0x40-0x7f地址的資料也同樣是覆寫整個cache,
 我們現在思考一個問題,如果一個程式試圖依次訪問地址0x00、0x40、0x80,cache中的資料會發生什么呢?首先我們應該明白0x00、0x40、0x80地址中index部分是一樣的,因此,這3個地址對應的cache line是同一個,所以,當我們訪問0x00地址時,cache會缺失,然后資料會從主存中加載到cache中第0行cache line,當我們訪問0x40地址時,依然索引到cache中第0行cache line,由于此時cache line中存盤的是地址0x00地址對應的資料,所以此時依然會cache缺失,然后從主存中加載0x40地址資料到第一行cache line中,同理,繼續訪問0x80地址,依然會cache缺失,這就相當于每次訪問資料都要從主存中讀取,所以cache的存在并沒有對性能有什么提升,訪問0x40地址時,就會把0x00地址快取的資料替換,這種現象叫做cache顛簸(cache thrashing),針對這個問題,我們引入多路組相連快取,我們首先研究下最簡單的兩路組相連快取的作業原理,
我們現在思考一個問題,如果一個程式試圖依次訪問地址0x00、0x40、0x80,cache中的資料會發生什么呢?首先我們應該明白0x00、0x40、0x80地址中index部分是一樣的,因此,這3個地址對應的cache line是同一個,所以,當我們訪問0x00地址時,cache會缺失,然后資料會從主存中加載到cache中第0行cache line,當我們訪問0x40地址時,依然索引到cache中第0行cache line,由于此時cache line中存盤的是地址0x00地址對應的資料,所以此時依然會cache缺失,然后從主存中加載0x40地址資料到第一行cache line中,同理,繼續訪問0x80地址,依然會cache缺失,這就相當于每次訪問資料都要從主存中讀取,所以cache的存在并沒有對性能有什么提升,訪問0x40地址時,就會把0x00地址快取的資料替換,這種現象叫做cache顛簸(cache thrashing),針對這個問題,我們引入多路組相連快取,我們首先研究下最簡單的兩路組相連快取的作業原理,
3.2 組相連映射(set-associative-mapping)
兩路組相連快取的硬體成本相對于直接映射快取更高,因為其每次比較tag的時候需要比較多個cache line對應的tag(某些硬體可能還會做并行比較,增加比較速度,這就增加了硬體設計復雜度),為什么我們還需要兩路組相連快取呢?因為其可以有助于降低cache顛簸可能性,那么是如何降低的呢?
如下圖所示:根據兩路組相連快取的作業方式,兩路組相連快取較直接映射快取最大的差異就是:第一個地址對應的資料可以對應2個cache line,而直接映射快取一個地址只對應一個cache line,那么這究竟有什么好處呢?
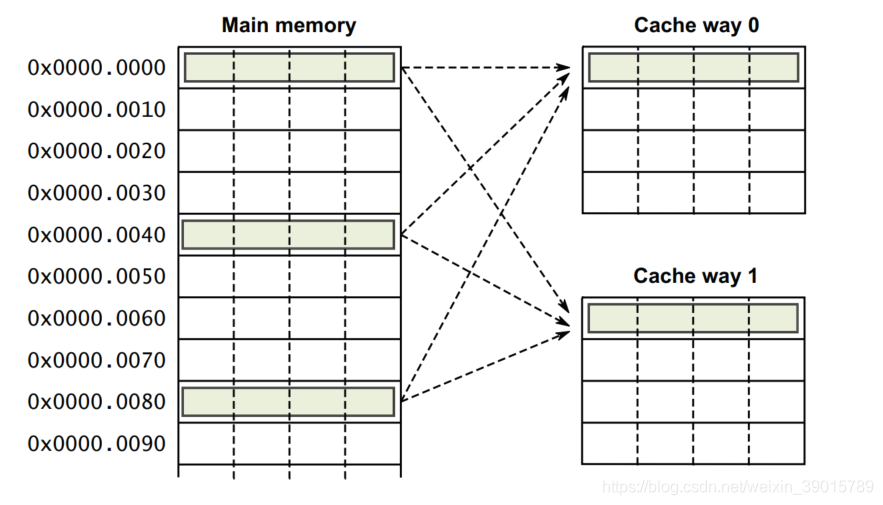 我們依然考慮直接映射快取一節的問題“如果一個程式試圖依次訪問地址0x00、0x40、0x80,cache中的資料會發生什么呢?”,現在0x00地址的資料可以被加載到way 1,0x40可以被加載到way 0,這樣是不是就在一定程度上避免了直接映射快取的尷尬境地呢?在兩路組相連快取的情況下,0x00和0x40地址的資料都快取在cache中,試想一下,如果我們是4路組相連快取,后面繼續訪問0x80,也可能被被快取,
我們依然考慮直接映射快取一節的問題“如果一個程式試圖依次訪問地址0x00、0x40、0x80,cache中的資料會發生什么呢?”,現在0x00地址的資料可以被加載到way 1,0x40可以被加載到way 0,這樣是不是就在一定程度上避免了直接映射快取的尷尬境地呢?在兩路組相連快取的情況下,0x00和0x40地址的資料都快取在cache中,試想一下,如果我們是4路組相連快取,后面繼續訪問0x80,也可能被被快取,
因此,當cache size一定的情況下,組相連快取對性能的提升最差情況下也和直接映射快取一樣,在大部分情況下組相連快取效果比直接映射快取好,同時,其降低了cache顛簸的頻率,從某種程度上來說,直接映射快取是組相連快取的一種特殊情況,每個組只有一個cache line而已,因此,直接映射快取也可以稱作單路組相連快取,
3.3 全相連映射(full-associative-mapping)
既然組相連快取那么好,如果所有的cache line都在一個組內,豈不是性能更好,其實并沒有完美的cache-mapping,例如全相連快取是將所有的cache line都放置在一個組內,主快取的任何資料可以放在任何一個cache line里面,雖然這可以最大程度的降低cache顛簸的頻率,但是硬體(設計的復雜性)成本上也是更高,所以設計這樣子的一個全相連的Cache是不切合實際的,除非這個cache非常之小,實際在應用上來說對于L1 Cache來說當超過4 ways以上的性能的提升已經是最小的了,
如下圖所示CPU最常用的組相連映射方案:對于一個4ways 32KB的D-Cache,cache line是8字,那么1 ways就會有256 lines,當cache line=256時,那么cache index=8;另外還需要3bit去指示cache line中哪一個字是有效的,
4 Cache controller
快取控制器是一個管理維護cache的硬體邏輯電路,對軟體程式而言是不可見的,他可以自動把資料從主快取寫到cache里面,還可以回應來自CPU core的讀寫請求并執行相應的操作去Cache或者主快取,
當CPU core發起讀請求的時候,他會檢測這個地址是否在cache里面,這個行為叫做查表(cache look-up),然后通過檢驗cache line的tag是否與查找地址tag一致來決定cache是否命中,當cache hit而且cache line是有效的,那么讀操作將在cache發生,
當CPU core請求的指令或者資料來自一個特殊的地址(對應的tag不在cache里面),那么就會發生快取丟失(cache miss),當發生了cache miss那么這個請求將會出去外面的主快取回應(要么L2 Cache要么external memory),他也會導致發生了cache linefill,及在請求主快取的相應資料到CPU core去時,也復制一份到cache里面來,但是這些行為對于你來說是不可見的,CPU core在使用資料之前不必等待行填充完成,快取控制器通常會首先訪問快取線中的關鍵字,例如,如果一個load指令在快取中缺失并觸發了一個cache linefill,那么第一次讀到外部記憶體就是load指令提供的實際地址,這些關鍵資料被提供給處理器管道,而高速快取硬體和外部總線介面然后在后臺讀取高速快取線的其余部分,
5 Cache policies
cache policies里面有三種策略allocate policy,replacement policy,write policy來影響cache的操作,
5.1 allocate policy
read allocate policy
只在讀取時分配cache線路,如果內核執行了快取中未執行的寫操作,那么快取不會受到影響,寫操作將進入層次結構的下一層,
write allocate policy
讀或寫在cache中失敗的情況分配一條cache line,因此,更準確地說,這可以稱為讀寫快取分配策略,對于快取中未執行的記憶體讀操作和快取中未執行的記憶體寫操作,都會執行快取行填充操作,這通常與當前ARM核心上的回寫策略結合使用,
5.2 replacement policy
replacement policy是在當cache發生cache miss的時候,快取控制器需要將資料從主快取搬移到cache的策略,當資料從主快取搬移到cache而選擇一個cahce line的行為叫做victim(犧牲),但是選擇cache line的某一行是不固定隨機的,如果選擇的那一行包含了有用的資料而被我們替換掉新資料的話,那么會對后續訪問造成影響,那么就需要把選中的這一行cache line資料搬移到主快取保留,這種行為就叫做逐出(eviction),
就如上面所說,replacement policy就是如何選擇cache line來做victim,大部分的處理器支持兩種替換策略Round-robin or cyclic replacement policy跟Pseudo-random replacement policy,
1、Round-robin or cyclic replacement policy
就是一個victim-counter,在一個有效的cache ways里面做周期回圈計數,當計數超過ways的最大行數就歸0,重新計數,這樣子來選擇victim cache line,
2、Pseudo-random replacement policy
就是一個偽隨機替換Pseudo-random-victim counter,通過偽隨機函式來隨機選擇cache的某一行去做victim cache line,
總的來說 回圈替代政策通常更具可預測性,但某些用例中的性能可能會受到不利影響,因此,偽隨機策略通常是首選,
5.3 write policy
write policy的策略分為了兩種策略write-through跟write-back,
1、CPU向cache寫入資料時的操作,兩者的區別:
Write-through:CPU向cache寫入資料時,同時向memory(后端存盤)也寫一份,使cache和memory的資料保持一致;
Write-back:CPU更新cache時,只是把更新的cache區標記一下,并不同步更新memory(后端存盤),只是在cache區要被新進入的資料取代時,才更新memory(后端存盤),
2、兩者相比較優勢跟缺點:
Write-through:優點是簡單,但是每次都要訪問memory,速度比較慢;
Write-back:優點是CPU執行的效率提高,缺點是實作起來技術比較復雜,
系統設計人員應評估最適合其應用程式的快取操作策略要求,如果使用了回寫策略,那么快取通常必須在在切換背景關系以保持記憶體系統的一致性之前描述的,這個切換前可能需要大量寫入CP15暫存器,或者,選擇直寫策略可以降低系統性能并增加功耗每個快取操作都保持一致性,這有時是不必要的,然而,這意味著快取正在不斷地被清理,因此快取維護通常是花更少的時間,
6 write and fetch buffer
write buffer是一個位于CPU內部的硬體邏輯塊,當CPU執行一條store指令,資料往往會先寫到writer buffer中去,然后CPU不等他真正寫到主快取就去執行下一條指令 ,但是writer buffer過一段時間會主動把資料寫到主快取之中去,
因此writer buffer的優點就是可以大大提供CPU執行指令的能力,提高整體性能,但是當CPU大量往writerbuffer寫資料且速度比write buffer寫到主快取的速度快,那么writer buffer很快就會被寫滿,那么這個時候對CPU的性能提升就不是很明顯了,而且當軟體同事需要CPU想獲取當前的資料再去執行下一條指令的時候,那么這個時候writer buffer反而也是礙事了,
一些write buffer還有一個寫合并的功能,對相連的單發寫資料會合并在一起,通過brust的方式寫到主快取去,這樣子可以提高資料流的傳輸速度,但是相反來說,當軟體想要的是單位元組操作資料不是連續一段資料,那么這個時候就是反而礙事了,
在某些系統中,稱為fetch buffer的類似組件可以用于讀取,特別是,CPU core通常包含預取緩沖區,在指令實際插入到管道之前從記憶體中讀取指令,通常,這樣的緩沖區對你來說是透明的,在研究記憶體排序規則時,我們也應該考慮與此相關的一些可能的危險,
參考文獻
<<arm-v7架構手冊>>
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/272869.html
標籤:其他
下一篇:微服務架構的那些事兒