一、背景
隨著分布式應用的崛起,單臺應用服務器很難支撐起業務,真實場景中往往一個應用要部署多次來解決高并發的問題,相信很多人對虛擬機都不陌生,
最早的做法就是通過在物理機上創建多個虛擬機(程式運行空間),虛擬機再運行相關應用,
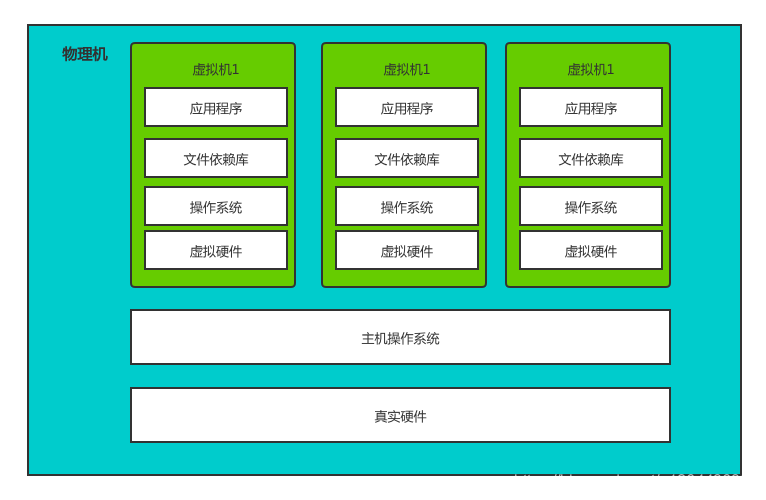
這種做法可以在同一臺機器上啟動多個應用實體,但每個虛擬機都創建都會將計算機結構一起打包,對于用戶來說創建、維護成本也太高了,每個虛擬機都會有作業系統、虛擬硬體也顯得這種方式比較重,那有沒有更輕的方式呢,答案是有的,
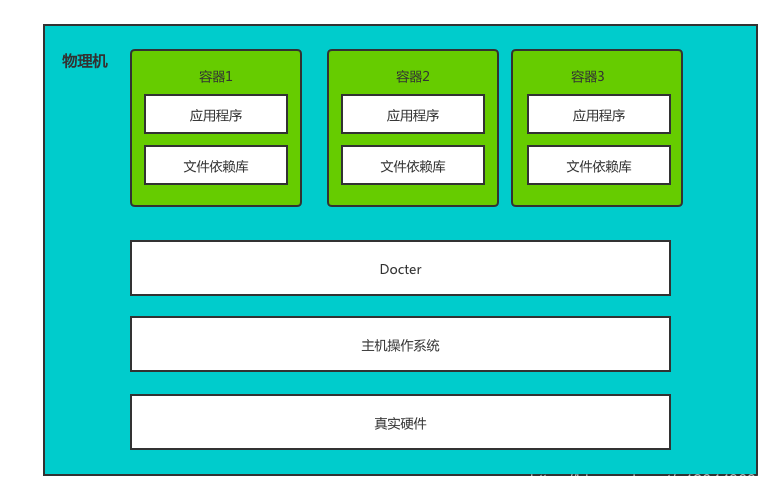
Docker技術就橫空出世了,Docker相比與虛擬機的主要優勢就是在于它輕,輕在哪些方面呢?它是直接運行在作業系統層面的,共享物理機的作業系統和硬體,用戶創建只需關注docker內的應用程式和檔案依賴庫,
二、Docker生命周期
介紹完虛擬機和Docker,有的小伙伴可能還不太熟悉他們之前的優缺點
| 特性 | 虛擬機 | 容器 |
| 啟動 | 分鐘級 | 秒級 |
| 硬碟使用 | GB級別 | Mb級別 |
| 性能 | 若于原生 | 接近原生 |
| 系統支持量 | 一般幾十個 | 單機支持幾千個 |
1、docker的生命周期
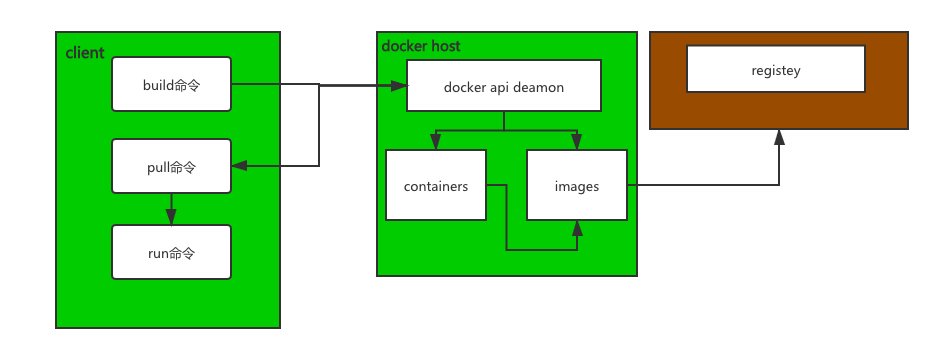
主要流程如下:
1、client發送命令到docker host被deamon行程所監控,
2、deamon根據命令執行相關操作,如pull操作,會檢測本地是否有相關鏡像、容器,
3、如本地未有則去registey倉庫里獲取相關鏡像,
4、最后把相關鏡像、容器回傳給client,client完成鏡像、容器的啟動,
三、kubernetes
對于多個容器,如果采用人為的方式去管理顯然是不科學的,此時就急于需要一款能代替人為去管理這些容器的工具,此時k8s就出現了,
k8s是一個開源平臺,能夠有效簡化應用管理、應用部署和應用擴展環節的手動操作流程,讓用戶更加靈活地部署管理云端應用,架構如下:
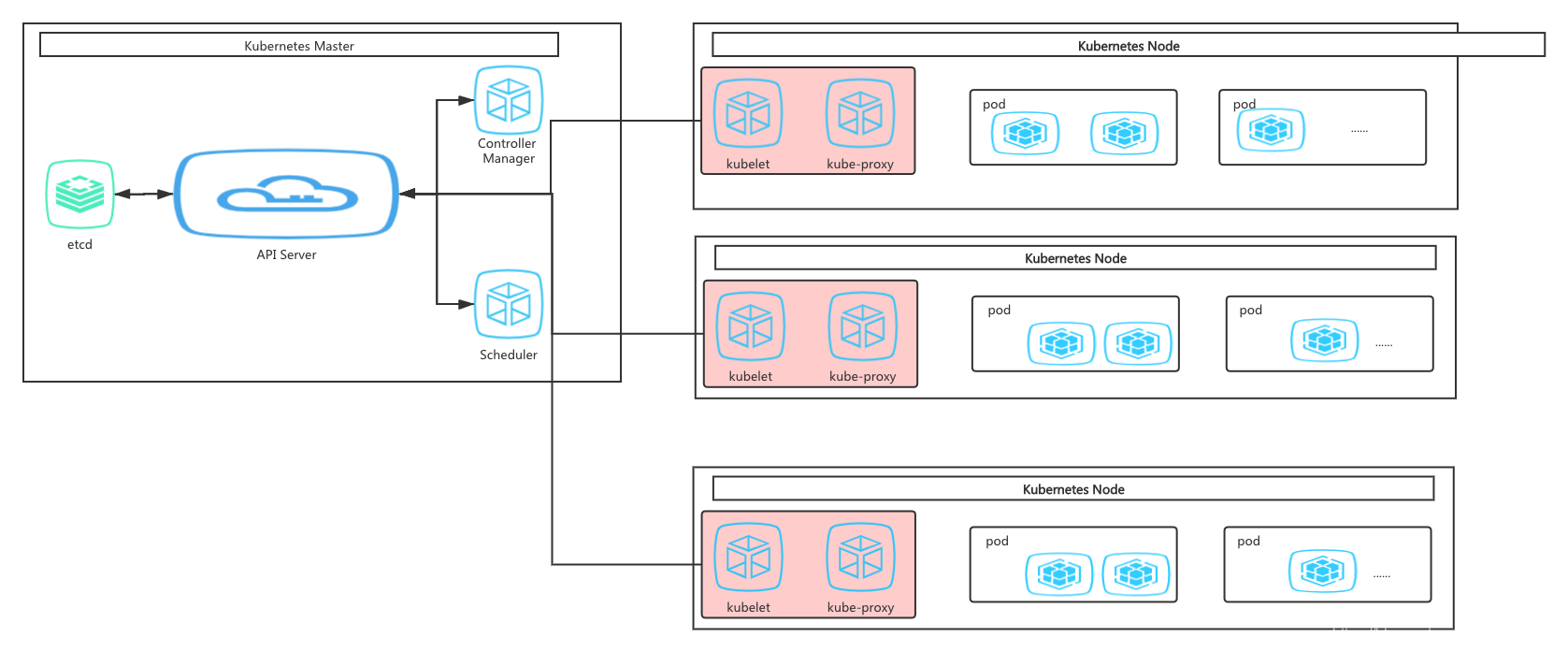
1、kubernetes Master
Master 是 Cluster 的大腦,它的主要職責是調度,即決定將應用放在哪里運行,Master 運行 Linux 作業系統,可以是物理機或者虛擬機,為了實作高可用,可以運行多個 Master,主從架構,
(1)Etcd:保存了整個集群的狀態(存盤狀態資料庫,存盤pod、service、rc等資訊),只為ApiServer提供操作、訪問權限;
(2)Apiserver:提供了資源操作的唯一入口,并提供認證、授權、訪問控制、API注冊和發現等機制;
(3)Controller manager:負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等;
(4)Scheduler:負責資源的調度,按照預定的調度策略將Pod調度到相應的機器上;
2、kubernetes Note
Node 的職責是運行容器應用,Node 由 Master 管理,Node 負責監控并匯報容器的狀態,并根據 Master 的要求管理容器的生命周期,Node 運行在 Linux 作業系統,可以是物理機或者是虛擬機,
(1)kubelet:負責維護容器的生命周期,同時也負責Volume(CSI)和網路(CNI)的管理;
(2)kube-proxy:負責為Service提供集群內部的服務發現和負載均衡;
(3)pod:K8S管理的最小單位級,它是一個或多個容器的組合,在Pod中,所有容器都被同一安排和調度,并運行在共享的背景關系中,對于具體應用而言,Pod是它們的邏輯主機,Pod包含業務相關的多個應用容器,
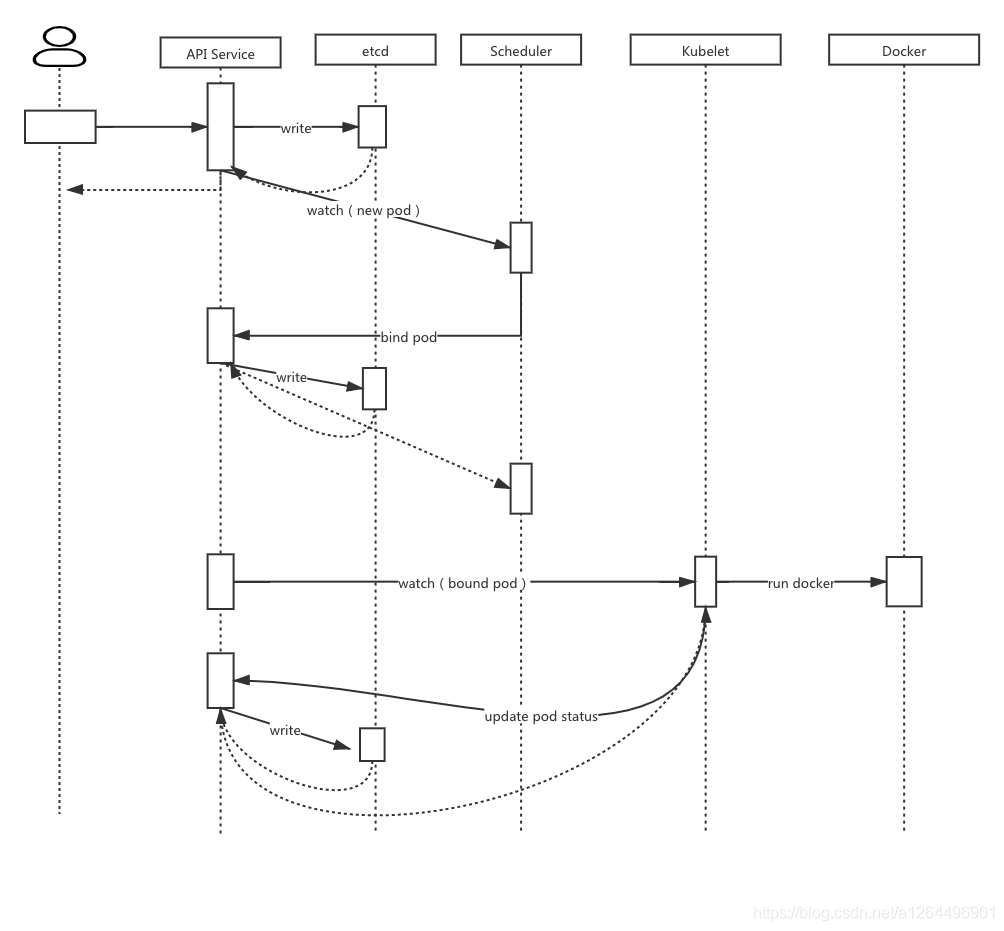
3、創建pod流程
(1)用戶提交創建Pod的請求,可以通過API Server的REST API ,也可用Kubectl命令列工具;
(2)API Server處理用戶請求,存盤Pod資料到etcd;
(3)Schedule通過和API Server的watch機制,查看到新的Pod,嘗試為Pod系結Node;
(4)過濾主機:調度器用一組規則過濾掉不符合要求的主機,比如Pod指定了所需要的資源,那么就要過濾掉資源不夠的主機;
(5)主機打分:對第一步篩選出的符合要求的主機進行打分,在主機打分階段,調度器會考慮一些整體優化策略,比如把一個Replication Controller的副本分布到不同的主機上,使用最低負載的主機等;
(6)選擇主機:選擇打分最高的主機,進行binding操作,結果存盤到etcd中;
(7)Kubelet根據調度結果執行Pod創建操作: 系結成功后,會啟動container,docker run,scheduler會呼叫API在資料庫etcd中創建一個bound pod物件,描述在一個作業節點上系結運行的所有pod資訊,運行在每個作業節點上的Kubelet也會定期與etcd同步bound pod資訊,一旦發現應該在該作業節點上運行的bound pod物件沒有更新,則呼叫Docker API創建并啟動pod內的容器;
4、用戶請求程序
在Kubernetes平臺上,Pod是有生命周期,為了可以給客戶端一個固定的訪問端點,因此需要在客戶端和Pod之間添加一個中間層,這個中間層稱之為Service,
kube-proxy通過kubernetes中固有的watch請求方法持續監聽apiserver,一旦有service資源發生變動(增刪改查)kube-proxy可以及時轉化為能夠調度到后端Pod節點上的規則,這個規則可以是iptables也可以是ipvs,取決于service實作方式,
service有如下四種實作:
(1)ClusterIp
默認型別,自動分配一個僅Cluster內部可以訪問的虛擬IP
(2)NodePort
在ClusterIP基礎上為Service在每臺機器上系結一個埠,這樣就可以通過: NodePort來訪問該服務,
(3) LoadBalancer
在NodePort的基礎上,借助Cloud Provider創建一個外部負載均衡器,并將請求轉發到NodePort
(4)ExternalName
把集群外部的服務引入到集群內部來,在集群內部直接使用,沒有任何型別代理被創建,這只有 Kubernetes 1.7或更高版本的kube-dns才支持,
用戶訪問具體應用流程
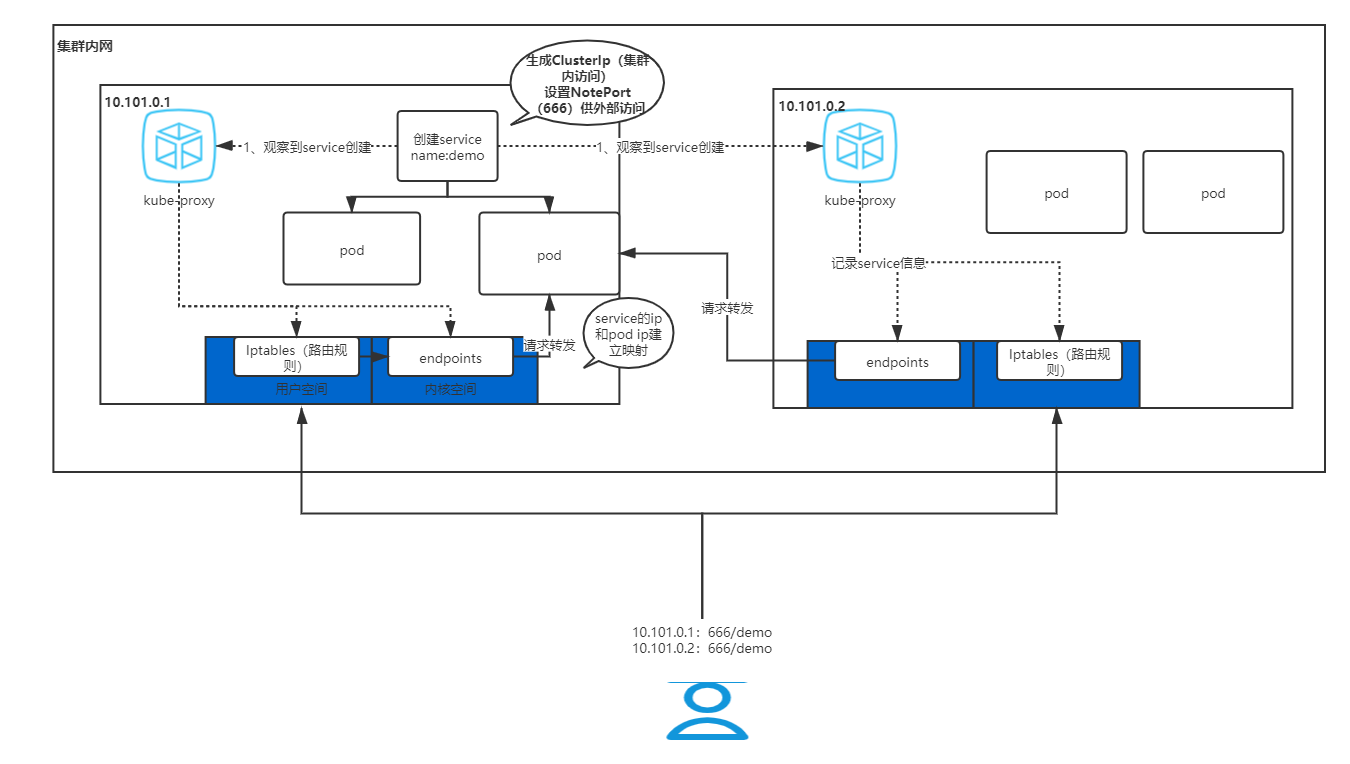
如上圖是通過NotePort方式供外部呼叫,此方案不能對請求進行過濾、負載均衡,此時可以引入請求轉發組件,如Ingress或LoadBalancer
a、LoadBalancer
服務是暴露服務到 Internet 的標準方式,所有通往你指定的埠的流量都會被轉發到對應的服務,它沒有過濾條件,沒有路由等,這意味著你幾乎可以發送任何種類的流量到該服務,像 HTTP,TCP,UDP,WebSocket,gRPC 或其它任意種類,
b、Ingress
可以給 Service 提供集群外部訪問的 URL、負載均衡、SSL 終止、HTTP 路由等,為了配置這些 Ingress 規則,集群管理員需要部署一個 Ingress Controller,它監聽 Ingress 和 Service 的變化,并根據規則配置負載均衡并提供訪問入口,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/273215.html
標籤:其他
上一篇:硬體設計——外圍電路(電源電路)
下一篇:web服務器簡介