前言
在上一篇筆記《變分量子對角化》里面我們簡單介紹了一下VQSD的概念,接下來的這篇筆記才是最重要的部分,這篇文章我們的內容如下:
1. 原文代價函式是如何構造的?
2. 為什么說代價函式影響到了我們估計值的精確度?
3. 分析一下原文作者的實驗,看一下迭代次數、估計值、角度、代價函式它們之間的關系,

默默告訴自己我一定得好好寫寫,沖鴨~
1. cost function的構造
前面說到代價函式才是整個程序的核心,代價函式的構造涉及了很多的問題,因為我們要尋找一個最優的角度,角度的不斷調整,會影響近似對角化的結果,代價函式是一個評判精度的引數,從下面這個式子中可以看出我們的目的就是要尋找一個使得代價函式最小的角度,這個角度我們稱為αopt,
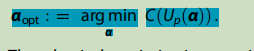
由上圖我們可以看出cost function的取值肯定也是伴隨著引數的調整而不斷變化,當α取值為α1,代價函式達到最小值的時候,α1就是我們所要尋找的αopt之一,我們的目標就是尋找p個αopt,構造出一個最優的代價函式,
上面我們提到了區域最小值α1,意思就是α目前所處的區間,只有當α=α1的時候,代價函式的取值最小,那么我們就把α1稱作區域最小值,但是如何衡量代價函式此時的取值是最小的呢,如果不是區域最小值我們接下來還要進行優化引數α,我們如果采用基于梯度的方式進行引數優化,就可以借助梯度來衡量此時的α1是不是我們所要尋找的區域最優值,
如果不太理解,就想一想導數和極值問題,思想是差不多的,梯度只是衡量當前α1是否為區域最小值的一個標準,
說到梯度,我們就要考慮噪聲、梯度消失的問題,emem,反正我是不太懂的,還需要進修這個模塊,只是先說一下本文的代價函式構造是如何解決巧妙地在梯度消失存在的情況下來訓練U(θ),來進行引數α的優化,
首先說一下本文提及的short-depth電路,看看這個電路的面貌:
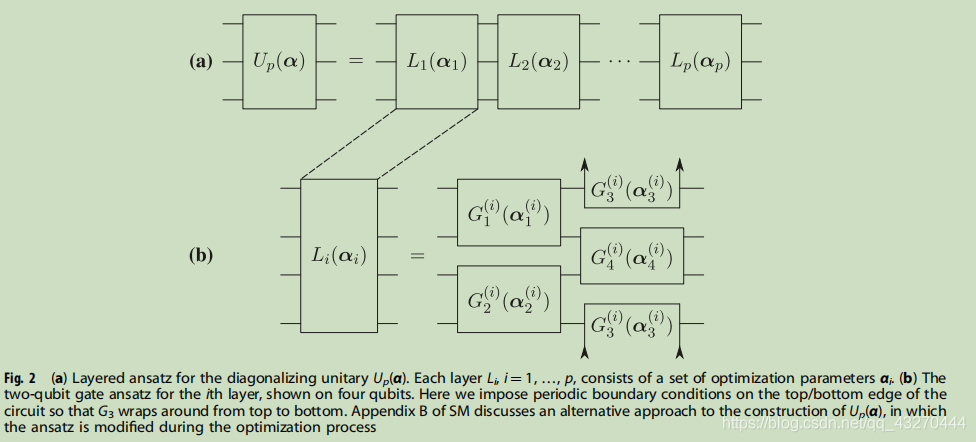
這個電路是如何緩解區域最小值的呢?將p層的優化引數作為p+1引數的起點,尋找下一個αopt.原文表達如下:

據我師兄所講,其中的barren plateaus指的是平原和高峰,指的是梯度有高有低,對于代價函式C1而言,在區域最小值附近,它的梯度變化很劇烈(后面會給出解釋),但是一旦遠離了區域最小值,它的梯度又會消失,
(PS :關于barren plateaus 我得去看看原文,后期再整理一下相關的概念~)
寫到這里我自個都搞暈了,代價函式C1仍舊存在梯度消失,梯度變化劇烈的情況,怎么敢信誓旦旦地說緩解了區域最小值問題,然后我就跑去問我賊厲害的師兄,發現果然是我理解的不夠透徹,

原文作者在進行引數優化方面是一層一層的進行的,而不是所有的層數一起蹦迪,那樣的話后期引數調整所需要的工程量太大了,所以他們提出先把眼前的利益放進口袋里,然后再打算慢慢地賺它一個億,這樣想來的話,區域最小值問題確實得到了優化,
如果還不理解的話,想想這句話“再小的問題乘以十三億,那也會是個很大的問題”,那么本文的原則就是將大問題除以十三億,轉化成小問題,一步步的解決,那么這個程序中遇到的困難就沒有那么可怕了,
再說一下原文給出的代價函式的要求:

-
faithful:代價函式為0,除非就是我們估計的和原來的資訊一模一樣,不然我們理想的代價函式就是無限趨近于0,但還是非0的一個引數;
-
efficiently computable:可以在多項式時間內完成;
-
operational meanings: 我們估計的特征值(特征向量)和實際的特征值(特征向量)之間的誤差小于代價函式的取值;
在本文中代價函式構造為:

看懂沒?肯定沒看懂吧,,,,,

別著急我們慢慢來,為了更好地理解(7)、(8)我們先跳到另一個環節,話不多說,先上圖:

在(7)式子中我們是針對全域標準基進行定義的,(7)式的后半部分代表的是去除非對角線元素所保留的密度矩陣Z(ρ),結合上圖里面對于(20)、(21)、(22)的解釋,***我們可以看出(7)式代表的意義就是ρ和ρ 之間對角線元素之間距離的平方和,(就如同我們計算的兩點之間距離的平方)***
在(8)式中,我們是針對區域標準基進行定義的,(9)式說明只有我們近似得到的對角化矩陣和實際的對角化矩陣是相同的情況下,代價函式C1,C2才為0,
(你問我啥是全域標準基,啥是區域標準基,我這樣回答你,全域標準基他們一家人,只要打掃衛生每個人都要去勞動;區域標注基他們一家打掃衛生,不要求一起勞動,單人行動模式,最后每個人的作業量取得是平均值)
由于C1,C2伴隨著n的增加,效果各異,就像一條路肯定有高有低,坡度還不一樣嘞,所以為了更好地訓練U(θ),找到αopt,我們最后構造出的代價函式要充分考慮C1,C2受n的影響,原文解釋如下:

q是一個自由引數,允許我們根據自己的實際問題來調整VQSD方法;對于小的n,q的取值近似為1;對于大的n,q的取值就可以設定的稍微小一點,下面給出了為什么不能用C1來訓練U(θ)的詳細解釋:

通過將C1,C2相結合,即使n太大,C1的梯度消失,我們也可以通過C2來進行引數優化,進行區域最小值的尋找,
2. 影響精確度的引數
在這里我們好好捋一捋在這篇論文中會影響到我們近似對角化結果的引數有哪些,
| 符號 | 意義 |
|---|---|
| p | 超引數 |
| iterative numbers | 迭代次數:大,結果精確,,復雜度高 |
| fz | 讀到特征值的次數:大,結果精確 |
| Nreadout | 讀取次數:大,結果精確 |
| εmax | 特征值的相對誤差,閾值 |
| vz~ | inferred eigenvector(eigenvalue):數值大,越精確 |
| αopt | 最優引數 |
| C | 代價函式:小,結果越精確 |
| λz~ | inferred eigenvalue:數值大,越精確 |
我們先來介紹一下特征值誤差和特征向量誤差的表示符號:
(1)特征值誤差表示:

(2) 特征向量誤差表示

內容總結:我們可以把式子(4)看作是一個加權特征向量誤差,其中大特征值對應的特征向量權重相對而言比較大,那么我們想要減少誤差,可以降低代價函式,從而迫使最大特征值對應的特征向量高度精確,
下面我們分析一下為什么我們會說代價函式C1是特征值誤差的上界:


原文中是這樣分析的:

推導程序如下:

由此看出,當代價函式C1越小,那么我們得到的特征值的誤差就越小,同時特征向量的誤差也就越小,
3. 實驗分析

實驗效果:
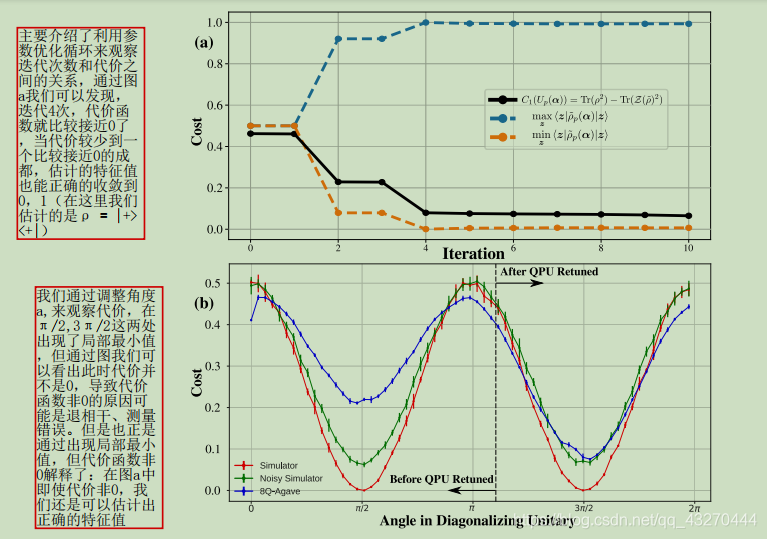
這里想要強調的是第二個圖,在第二個圖中我們發現在π/2,3π/2,代價函式出現了比較小的數值,并且在當時α所處的區間內,沒有比這令代價函式還要小的數值,所以我們可以判斷上面兩個值就是區域最小值,是我們要尋找的αopt的一員,這里的影像比較具備周期性,結果比較形象直觀,但并不是都可以找到區域最優值,就像在高等數學里面,我們的極小值可不一定是最小值,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/274436.html
標籤:其他
上一篇:輕量級網路的學習(僅供自己學習觀看)(Objection Detection Backbone系列一)
下一篇:LeetCode-旋轉陣列