目錄
爬蟲之迷惑?
小白疑問?
爬蟲到底是什么?
學習爬蟲從初識爬蟲開始
初識爬蟲之概念認知篇
初識爬蟲之安裝準備篇
Python語法入門到精通
初識爬蟲之基本原理篇
初識爬蟲之爬蟲概述篇
初識爬蟲之urllib庫使用篇
初識爬蟲之requests庫使用篇
初識爬蟲之Xpath語法篇
爬蟲之案例集合
Python爬取全網文字并詞云分析(全程一鍵化!)
Python爬取微博熱搜資料之炫酷可視化
站在上帝的角度挖掘資料——Python抓取10W+社科基金專案并可視化分析
Python爬取養老資訊網案例
專案介紹
專案實作
完整原始碼點擊此處下載!親測可用!!!直接運行!!
資料集點擊此處下載!!
每文一語
爬蟲之迷惑?
小白疑問?
什么是爬蟲?爬蟲真的是蟲蟲嗎?為什么叫爬蟲呀?為什么不叫抓蟲呀?哈哈哈哈,如果你是第一次接觸爬蟲或者Python那么你一定要仔細看完前期介紹,
爬蟲顧名思義,就是爬蟲,哈哈哈,
在互聯網的汪洋大海里面,一切皆資料,前端工程師把資料和網頁完美的結合在一起,他們以為這樣是最美麗的契合,殊不知,后端的那些工程師寶寶們,一天沒事干,把他們的老窩給驚擾了,爬蟲給網站帶來的危害是比較大的,如果一個服務器一般被很多用戶訪問,可能它會宕機,也可能會崩潰,那么一個機器通過編程手段來達到這個目的,一分鐘的點擊次數,同時點擊所達到的次數,機器不會累,于是網站被他們端了,一切都要恰到好處,于是他們商量好了,禮貌的訪問,隱隱約約的訪問,悄悄咪咪的訪問,有節制的去獲取資料,慢慢的前端工程師和后端工程師關系越來也好了,最終他們誕生了幸福的結晶——大資料工程師!
哈哈哈,以上純屬娛樂,不做參考,不喜勿噴喲!
爬蟲到底是什么?
簡單來講,爬蟲就是一個探測機器,它的基本操作就是模擬人的行為去各個網站溜達,點點按鈕,查查資料,或者把看到的資訊背回來,就像一只蟲子在一幢樓里不知疲倦地爬來爬去,
你可以簡單地想象:每個爬蟲都是你的「分身」,就像孫悟空拔了一撮汗毛,吹出一堆猴子一樣,
你每天使用的百度,其實就是利用了這種爬蟲技術:每天放出無數爬蟲到各個網站,把他們的資訊抓回來,然后化好淡妝排著小隊等你來檢索,
搶票軟體,就相當于撒出去無數個分身,每一個分身都幫助你不斷重繪 12306 網站的火車余票,一旦發現有票,就馬上拍下來,然后對你喊:土豪快來付款,
爬蟲的那些操作
爬蟲也分善惡,
像谷歌這樣的搜索引擎爬蟲,每隔幾天對全網的網頁掃一遍,供大家查閱,各個被掃的網站大都很開心,這種就被定義為「善意爬蟲」,
但是,像搶票軟體這樣的爬蟲,對著 12306 每秒鐘恨不得擼幾萬次,鐵總并不覺得很開心,這種就被定義為「惡意爬蟲」,(注意,搶票的你覺得開心沒用,被掃描的網站覺得不開心,它就是惡意的,)
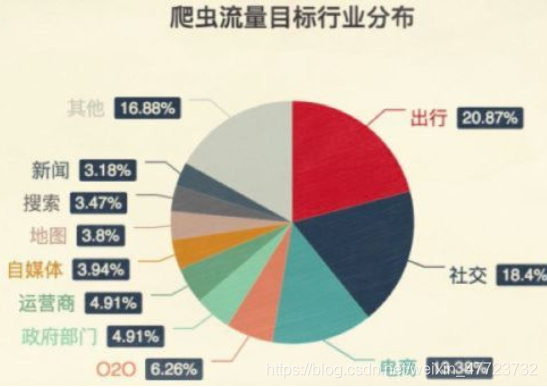
我們都是善意爬蟲,因為我們有禮貌的去獲取資料
學習爬蟲從初識爬蟲開始
之前我們寫過很多關于爬蟲的案例和語法合集,這里可以點擊查看!逐漸更新中...........
初識爬蟲之概念認知篇
帶你認識什么是爬蟲,如何用語文閱讀的方式去理解編程,去感受爬蟲的快樂!曾經有人說過,爬蟲可以給他帶來美感,我認為爬蟲確實可以滴,不只是美感,而且還可以是快樂的美感喲!
初識爬蟲之安裝準備篇
爬蟲必然要用到第三方庫,這也是爬蟲選擇Python的原因之一,因為Python是一個富含維生素C的水果,哈哈哈,搞錯了,是不是最近養成了吃VC的小習慣,被鍵盤知道了,哈哈哈,大家要記得多吃水果和蔬菜,補充微量元素喲!身體是你們賺錢的本錢,帶你走向致富的道路!(#^.^#)
因為Python是一個擁有大量的第三方庫的編程語言,之所以它被大資料和人工智能所青睞,那就是它的快速便捷,同比其他語言來說,它的優點就是簡單但不失高級,晦澀但又不難理解,說的我們都快心動了,哈哈,如果你也想要學Python,快去看看這個專欄吧!帶你從0到1,走向高薪職業喲!
Python語法入門到精通

初識爬蟲之基本原理篇
爬蟲的基本原理就像是我們小時候學習拼音那樣,認識音節,知道如何去讀,然后再去教你如何去寫,爬蟲也是這樣,俗話說:知己知彼百戰百勝
初識爬蟲之爬蟲概述篇
我們可以把互聯網比作一張大網,而爬蟲(即網路爬蟲)便是在網上爬行的蜘蛛, 把網的節點比作一個個網頁,爬蟲爬到這就相當于訪問了該頁面,獲取了其資訊 , 可以把節點間的連線比作網頁與網頁之間的鏈接關系,這樣蜘蛛通過一個節點后,可以順著節點連線繼續爬行到達下一個節點,即通過一個網頁繼續獲取后續的網頁,這樣整個網的節點便可以被蜘蛛全部爬行到,網站的資料就可以被抓取下來了 ,
初識爬蟲之urllib庫使用篇
初識爬蟲之requests庫使用篇
爬蟲的基本思維就是,獲取資料,存盤資料,當然獲取資料:就包括請求資料,然后決議資料,最后有選擇性的去存盤資料,這里兩篇的技術文章,詳細的介紹了爬蟲的請求資料語法案例
初識爬蟲之Xpath語法篇
之后就是決議資料了,最常的就是Xpath,beautifulsoup,正則運算式等,當然看你個人喜好和掌握程度,如果你喜歡簡單快速的推薦使用Xpath和beautifulsoup,但是你必須要有足夠的知識儲備,這樣才不會被一些坑坑過,要不然就去使用正則運算式,雖然繁瑣,但是屢試不爽,哈哈哈!
爬蟲之案例集合
我推薦兩篇我個人覺得參考價值和娛樂性相對于比較高的三篇技術文章!
Python爬取全網文字并詞云分析(全程一鍵化!)
一鍵化的操作,還是比較的舒服!

Python爬取微博熱搜資料之炫酷可視化
文章里面有一個演示視頻,還有bjm喲,哈哈哈,微博熱搜,當時也是讓這篇文章上了熱搜了!
站在上帝的角度挖掘資料——Python抓取10W+社科基金專案并可視化分析
絕不是標題黨,內容更真實!只要你點擊去,或者關注喲!
在我看來,爬蟲絕對不是簡單獲取資料那樣,如果學習爬蟲不是為了幫助減輕作業或者學習的煩惱,那就沒有靈魂了!
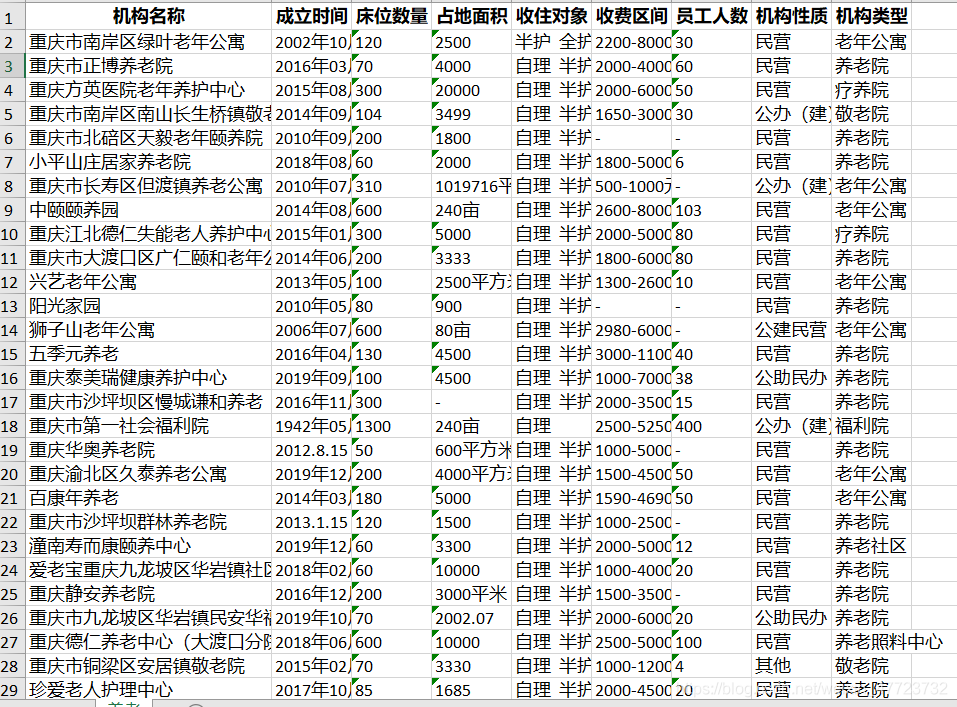
Python爬取養老資訊網案例
說了這么多的,當然絕對不是廢話哈,磨刀不誤砍柴工,如果你了解了這些基本的東西,學習起來也不會感到枯燥的!
專案介紹
有這樣一個網站,它包含了中國的養老機構的資訊,里面的資料可以作為科研人的資源,但是他們就是覺得有點麻煩,如果手動去找資料的話,于是我又踏上了幫助人的道路了
哈哈哈哈,加油!
專案實作
完整原始碼點擊此處下載!親測可用!!!直接運行!!
資料集點擊此處下載!!
匯入第三方庫
import requests
from lxml import etree
from fake_useragent import UserAgent
import pandas as pd
import time請求資料部分原始碼
b = 0
a += 1
res = requests.get(url='http://www.yanglaocn.com/yanglaoyuan/yly/?RgSelect=02301&page={}'.format(j),
headers=headers)
res.encoding = 'UTF-8'
html = res.text
html_ = etree.HTML(html)
text_1 = html_.xpath('//div[@class="jiadiantulist"]/ul[1]/a/@href')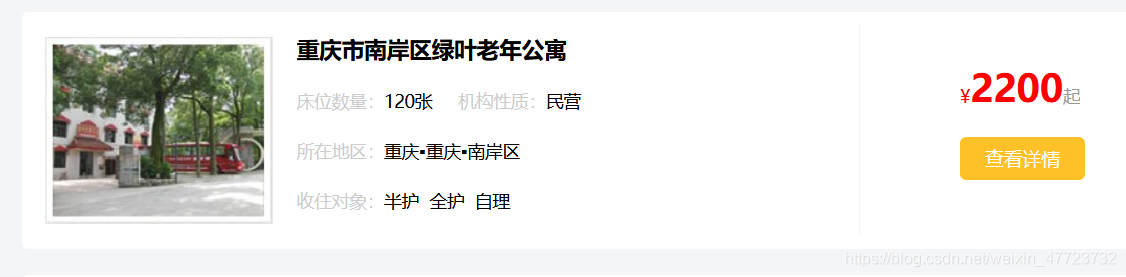
這個主頁的資訊太少了,我們需要點擊去,要這里面的全部資料
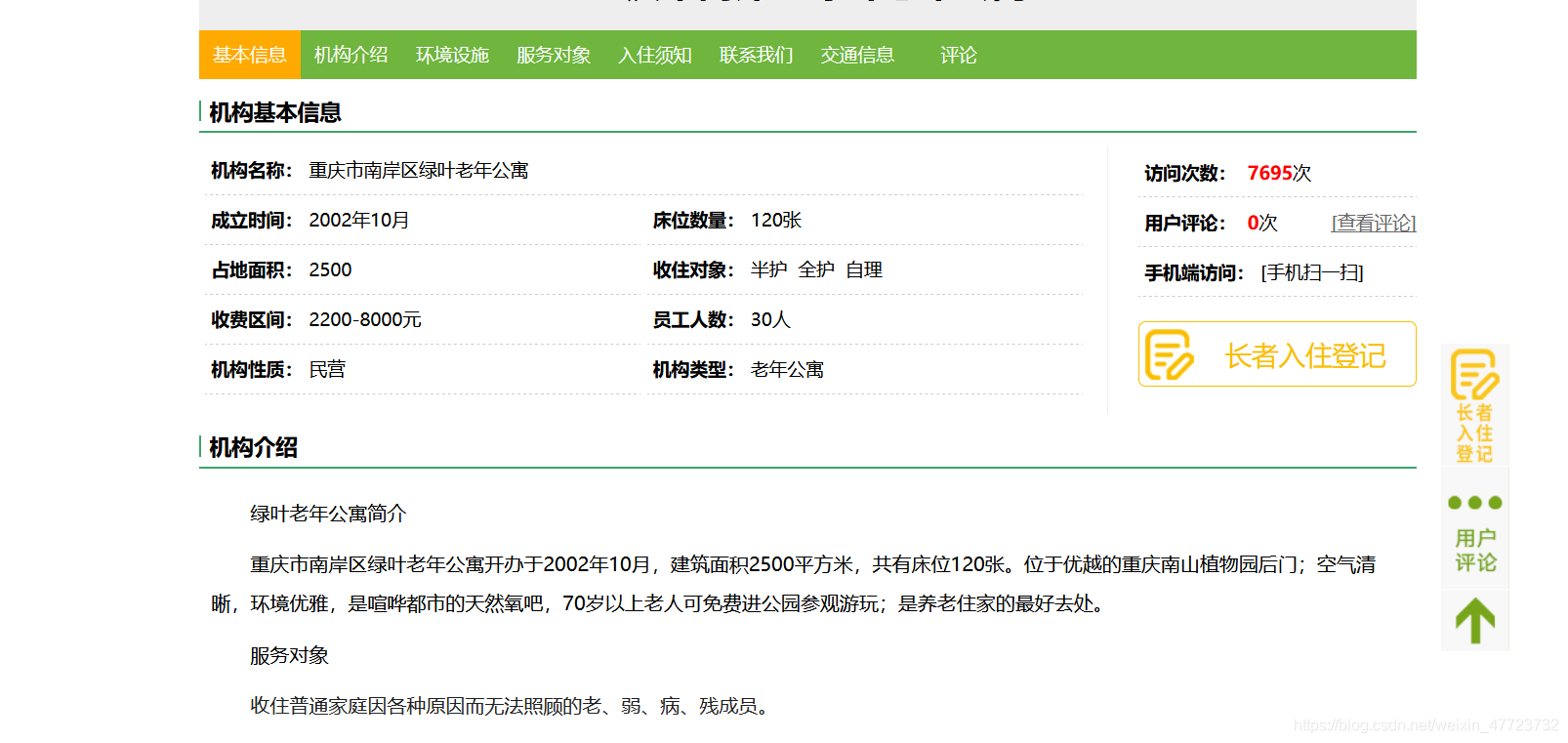
有小伙伴想到了模擬點擊,但是我也去試過,但是發現速度非常的慢,我們如果是要獲取少量的資料還好,如果很多的資料,那就完蛋了,太慢了!
于是我又重新找到了另外一個方法,在爬蟲里面嵌套一個爬蟲獲取頁面當單個的網址,這樣就可以實作速度和資料并存運行了,果然效果還不錯!
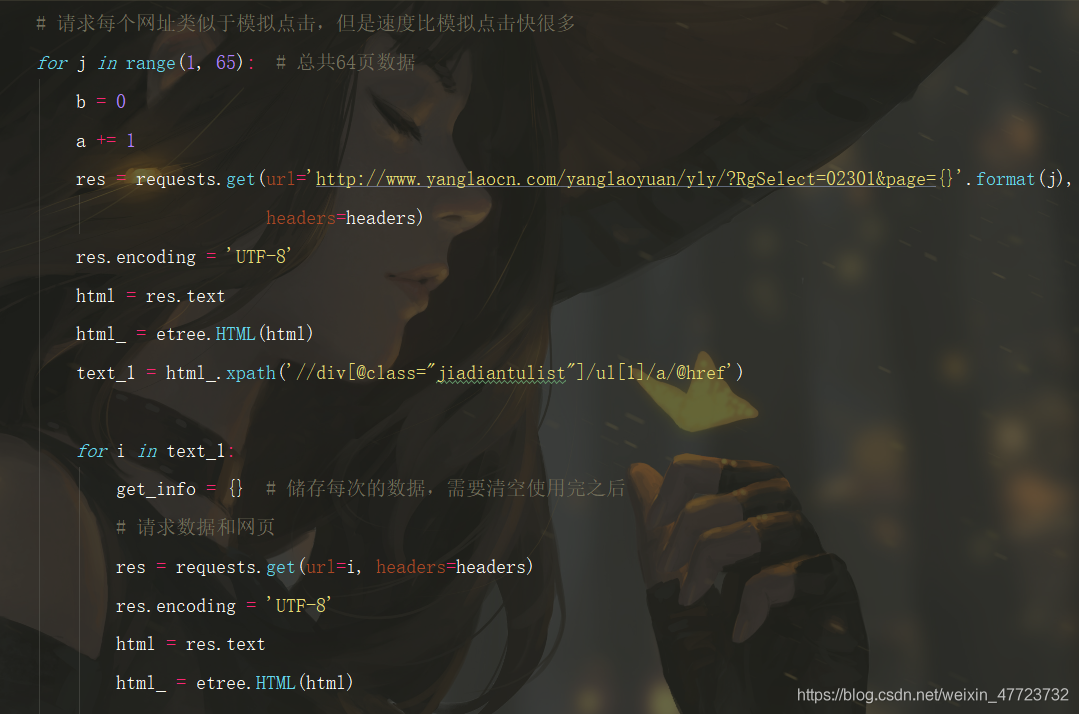
雙層回圈,遞回操作,完美結合!
決議資料
# 決議資料
name = html_.xpath('//div[@class="leftcontext_left"]/div[1]/label/text()')
for text in name:
get_info['機構名稱'] = text
time.sleep(1)儲存資料部分原始碼
df.to_csv('養老.csv', mode='a+', index=False, encoding='utf-8')
count += 1
get_info_list.clear()
texts = html_.xpath('//div[@class="leftcontext"]//text()')
aa = list(texts)
index = aa.index("養老資訊網提示您:")
v = list(texts)[:index]
c = []
for x in v: # 遍歷b這個,去除里面的特殊字符
if x in "●\r\n":
continue
else: # 分別分出有意義的詞組,因為對于一個詞的,分析沒有太大的意義
c.append(x) # 存盤1詞組變數
with open(r"文本.txt", 'a+', encoding="utf-8") as file:
file.write("\t\t\t\t" + text)
for i in c:
file.write('\n'.join(i.split()) + '\n')
print("第1頁第1條資料寫入!!!") # 寫入第一行表頭加資料,表頭默認主函式
if __name__ == '__main__':
# 定義一些變數
ua = UserAgent() # 解決了我們平時自己設定偽裝頭的繁瑣,此庫自動為我們彈出一個可用的模擬瀏覽器
headers = {"User-Agent": ua.random}
Data()
print("感謝你使用本程式!")資料獲取完畢!
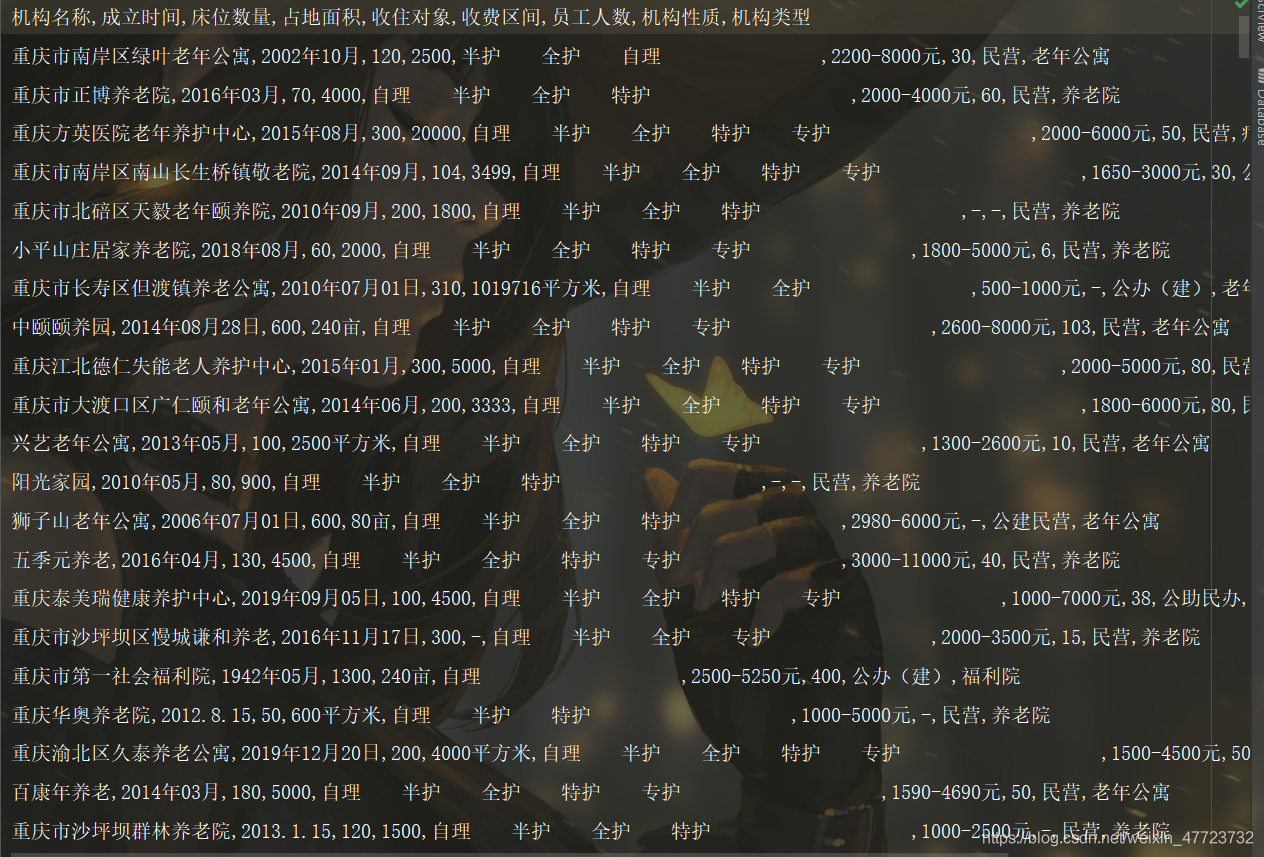
知識是不是需要付費?讓我想起了一個博主,他說:“知識不付費,永遠學不會”
本期的文章就更新到這里喲,關注我!學習Python和大資料,帶你一起快樂代碼!
每文一語
為你寫詩,為你寫時,為你做最浪漫的事!遇見才是美好,沒有問號?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/274449.html
標籤:其他