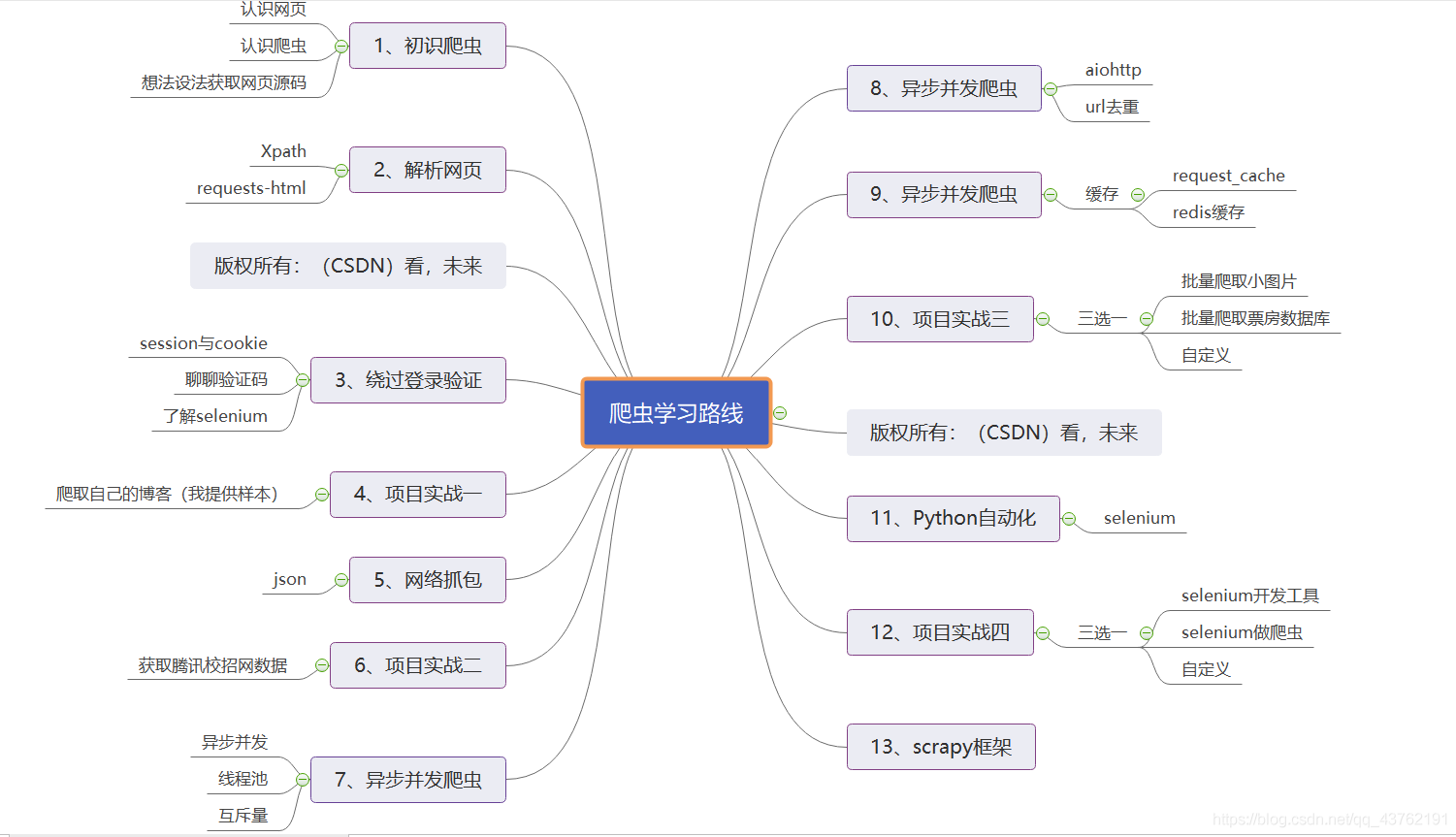
文章目錄
- 系列導讀
- 這個系列是什么?
- 本系列配套資源
- 已加入CSDN“蓄力計劃”,打造精品系列
- 系列適用人群
- 初識爬蟲
- 卸下心理包袱
- 記住我們是為什么學習爬蟲
- 網路爬蟲作業方式
- 入門心法:法
- 認識HTML網頁
- 打開網頁原始碼
- 獲取網頁原始碼
- 注一
- 從自己的電腦上獲取請求頭
- 注二:
上圖已魔法反爬,哈哈哈,想爬就爬唄,不攔著,
系列導讀
這個系列是什么?
本系列會寫一些什么內容,在開頭那張思維導圖里面寫了個大概了,至于導圖里面沒有寫出來的,就作為一些探索的內容吧,
我之前有寫過一個Python爬蟲自學系列,反響也還可以,不過那個系列里面的不少鏈接是另一個付費專欄里面的內容了,相對要閱讀就有些困難,
這個系列是在原有知識點的基礎上,加入一些新的知識點,重新寫的一個系列,不出意外,這個系列將會是我在Python爬蟲領域的最后一個教學系列,
本系列配套資源
這個系列是會有配套視頻課的,將會發布在CSDN學院上,當然,如果還是喜歡看博文的朋友可以看我的這個系列,
已加入CSDN“蓄力計劃”,打造精品系列
由于參加了CSDN的“蓄力計劃”,諸多條條框框,總結一下就是為讀者服務,所以這個系列會寫的很認真,畢竟我想上榜啊,大家多多支持,
系列適用人群
有Python基本語法基礎的人,分支回圈、函式、類、模塊、例外處理等,
不喜歡枯燥乏味的填鴨式教育的朋友,
肯動手實操為最佳,
初識爬蟲
卸下心理包袱
不知道大家對于爬蟲這項技術是怎么看的,我是猶豫了很久,才學的爬蟲(要不是學長把買好的課拍在我面前,我估計還不動手),倒不是說爬蟲有多難,但是在當時的我看來,爬蟲技術離我那是十萬八千里,爬蟲會不會很難吶,但是真的放下心里的包袱去學的時候,會發現爬蟲也就那樣,一個月入門爬蟲綽綽有余了,
記住我們是為什么學習爬蟲
為什么要專門講這個呢,因為有的年輕人,入門爬蟲之后就會比較喜歡炫技,這也無可厚非啦,我也有過一段喜歡炫技的時間,
但是呢,我們學習爬蟲技術,使用爬蟲技術,最本質的目標是什么?不就是為了獲取資料嘛,
獲取什么資料?
可以復制的資料、
可以復制的資料,但是量大、
不可以復制的資料、
不可以復制的資料,而且量還大、
多種資料糅雜
···
大概是這些吧,那我們先來簡單講一下針對這些資料,分別要如何處理吧,
對于第一種:那還費什么話,直接復制粘貼就好,我想應該沒有人會專門為了這種資料去寫個爬蟲吧?
對于第二種:那需要使用爬蟲了,這里的量大,怎么說也得有個幾十上百頁吧,但是這時候我們不要自己去寫爬蟲,應該使用現有代碼框架,
這里的框架指的是我們自己平時封裝好的代碼框架,不要迷戀什么scrapy框架,資料量還沒大到那個程度呢,
在本系列中,我會陸陸續續放上我自己平時使用的比較順手的封裝代碼,大家自取,
對于第三種:如果還在“提取圖中文字”的朋友可以停手了,學完這篇就可以停手了,我們直接打開它的原始碼,直接復制就好了,
對于第四種:既然不讓復制,那要直接爬取就比較麻煩了,這時候就需要根據實際情況選用合適的方法來爬取了,
對于第五種:伺機而動,爬下來之后還要做一系列資料清洗作業才行,
總之,這個系列貫穿頭尾的線索就是:怎么簡單怎么來,好不?咱不搞那些花里胡哨的
網路爬蟲作業方式
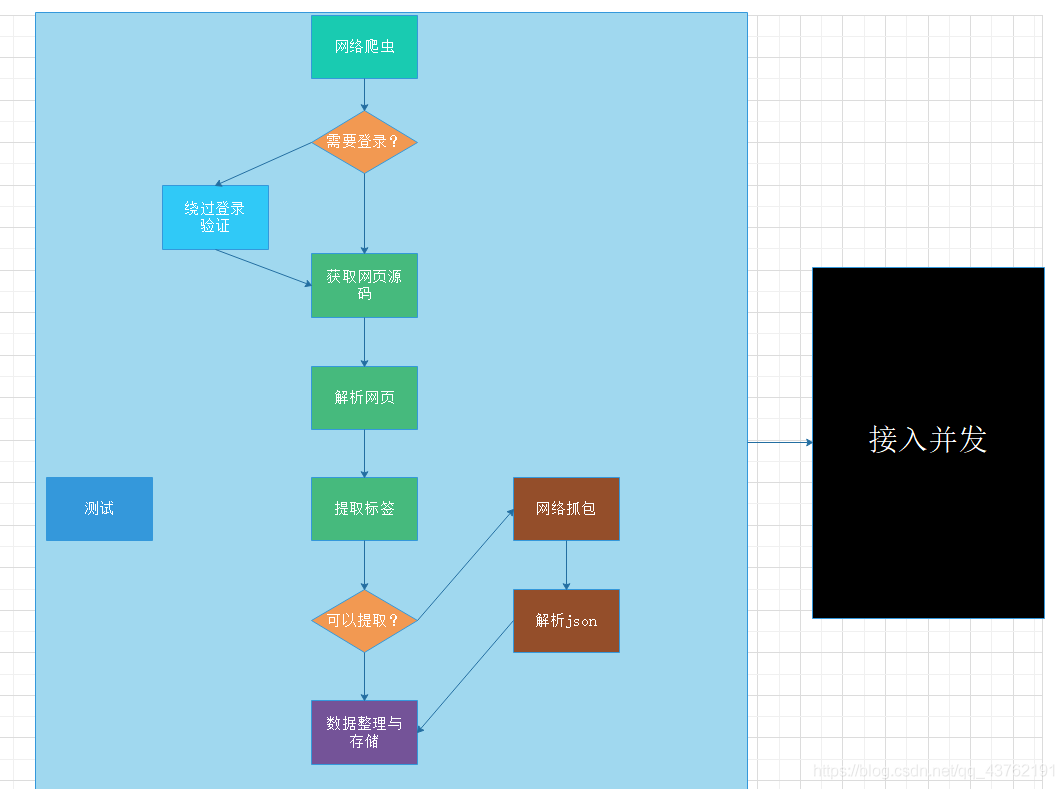
入門心法:法
玩爬蟲吶,是有可能會跟“法”打交道的,這點大家還是要了解一下的,新聞上時不時的就有報道,說某某資料團隊被一鍋端了,因為爬了不該爬的資料,并做商用,
然后呢,我昨晚苦思冥想,想到了老師上課所說的一句話:我們為了學術研究而去獲取的資料,不拿去傳播就沒有太大的問題,
懂我意思吧,不拿去傳播,
其實吧,就我這技術,能拿去賣錢的資料,我也拿不到嘛,
好了好了,言歸正傳,寫爬蟲的都知道一般網站都有robot.txt,可以看網站上的哪些目錄拒絕爬蟲,這個檔案一般在網站的根目錄后面跟上robot.txt打開,如果比較穩重的朋友建議采用這種方式,像我這種比較飄的,就直接爬了,不給爬的話,回傳的狀態量就會直接提示了,
網站地圖就先不說啦,后面批量爬取的時候再說,那個東西可真的是玩火了,
認識HTML網頁
“學爬蟲,對HTML的要求很高嗎?”很多朋友都問我這個問題,
我說我一個后端選手都能學爬蟲,你們怕什么?
打開網頁原始碼
推薦使用瀏覽器:谷歌瀏覽器
隨便打開一個網頁,或者你們就對著這篇博客,我們來打開網頁源代碼看一下:
方法一:網頁空白處右擊,檢查
方法二:F12
如果遇上那種不讓右擊,又不讓F12的網頁的話,這種網頁比較少見,但是碰到的時候還是很懵逼的,
方法三:Ctrl+Shift+i
方法四:滑鼠點擊網址欄,然后再按F12,目前不清楚這是個例還是通用的,因為我就遇到了一個這種網頁,
方法五:自定義及控制->更多工具->開發者工具,
作為一個爬蟲選手,如果連審查頁面元素的能力都沒有,那也就不要干了嘛,
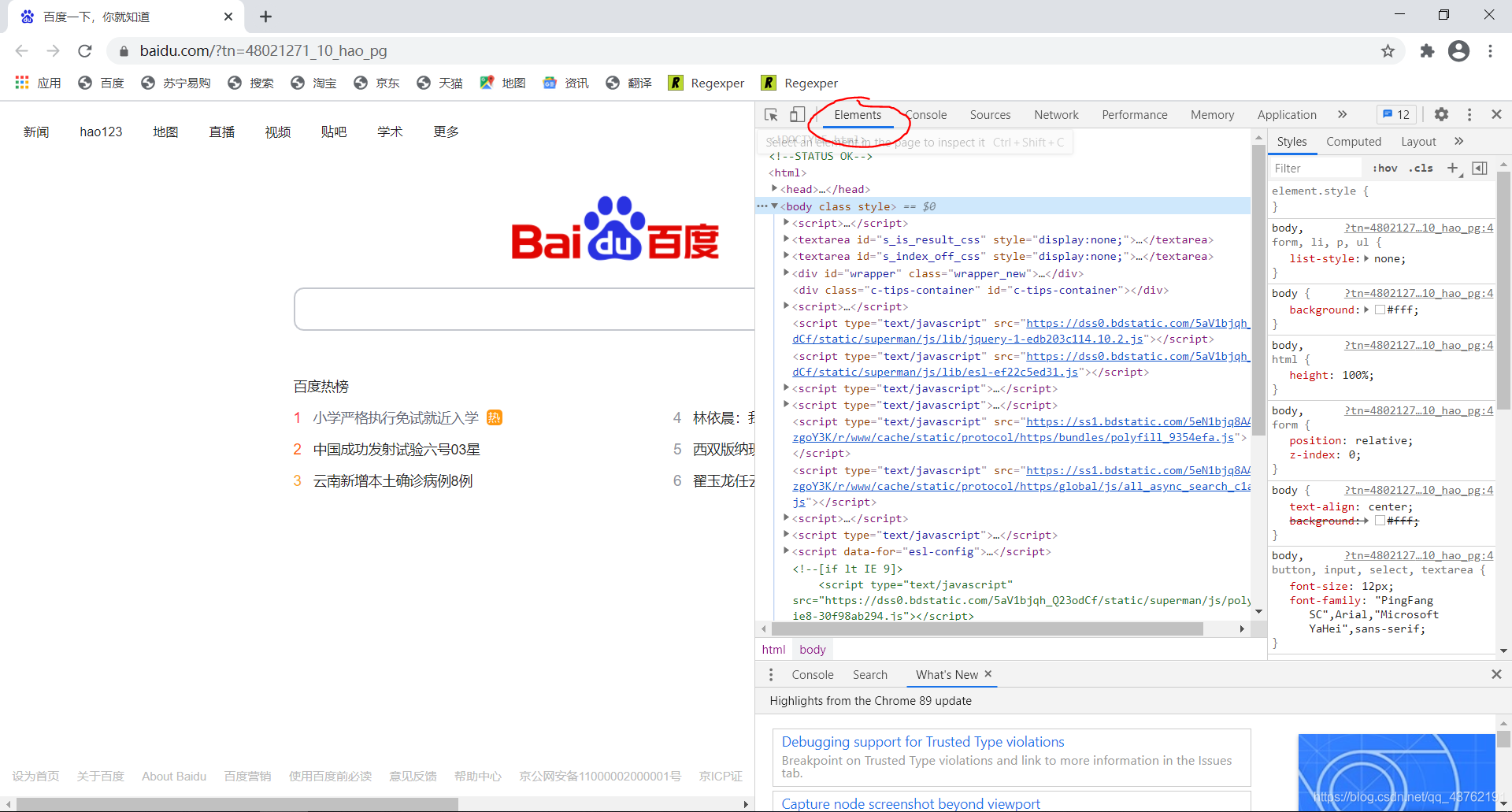
左邊這一塊兒,就是網頁原始碼,
而我們今天的任務也很明確,獲取它的原始碼,
獲取網頁原始碼
這一塊兒,有一個比較出名且常用的模塊兒來專門負責:requests,
import requests
獲取網頁原始碼也只需要一行簡單的代碼:
res = resquests(url,headers = headers)
有時候需要帶上個頭,有時候不需要,不過大部分時候需要,那就帶上吧,
先看代碼,然后我們對著代碼里面還沒說的點進行補充,
目前的封裝代碼如下:
def get_html(url,times):
'''
這是一個用戶獲取網頁源資料的函式
:param url: 目標網址
:param times: 遞回執行次數
:return: 如果有,就回傳網頁資料,如果沒有,回傳None
'''
try:
res = requests.get(url = url,headers = {
"User-Agent":random.choice(user_agent_list) # 注一
}) #帶上請求頭,獲取資料
if res.status_code>=200 and res.status_code<=300: # 注二
return res
else:
return None
except Exception as e:
print(e) # 顯示報錯原因(可以考慮這里寫入日志)
if times>0:
get_html(url,times-1) # 遞回執行
注一
這里是一個請求頭的串列,
倒不是我小氣,IP池分兩種,一種是私用的,一種是公有的,公有的IP池有現成的包,from fake_useragent import UserAgent,但是公有的IP都不穩定啊,畢竟大家都在用,用多了就讓人封了唄,封了你還不知道,傻乎乎的去用,就爬不到資料了唄,
user_agent_list = [
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
]
從自己的電腦上獲取請求頭
還是上面那個圖,在“Element”右邊,找到一個“network”,點進去,什么都沒有,是吧,
在左邊的網頁上,右擊,重新加載,
如果網頁是無法右擊狀態的話,可以在電腦左上角,重繪網頁,這時候,右側就會出現一些包,
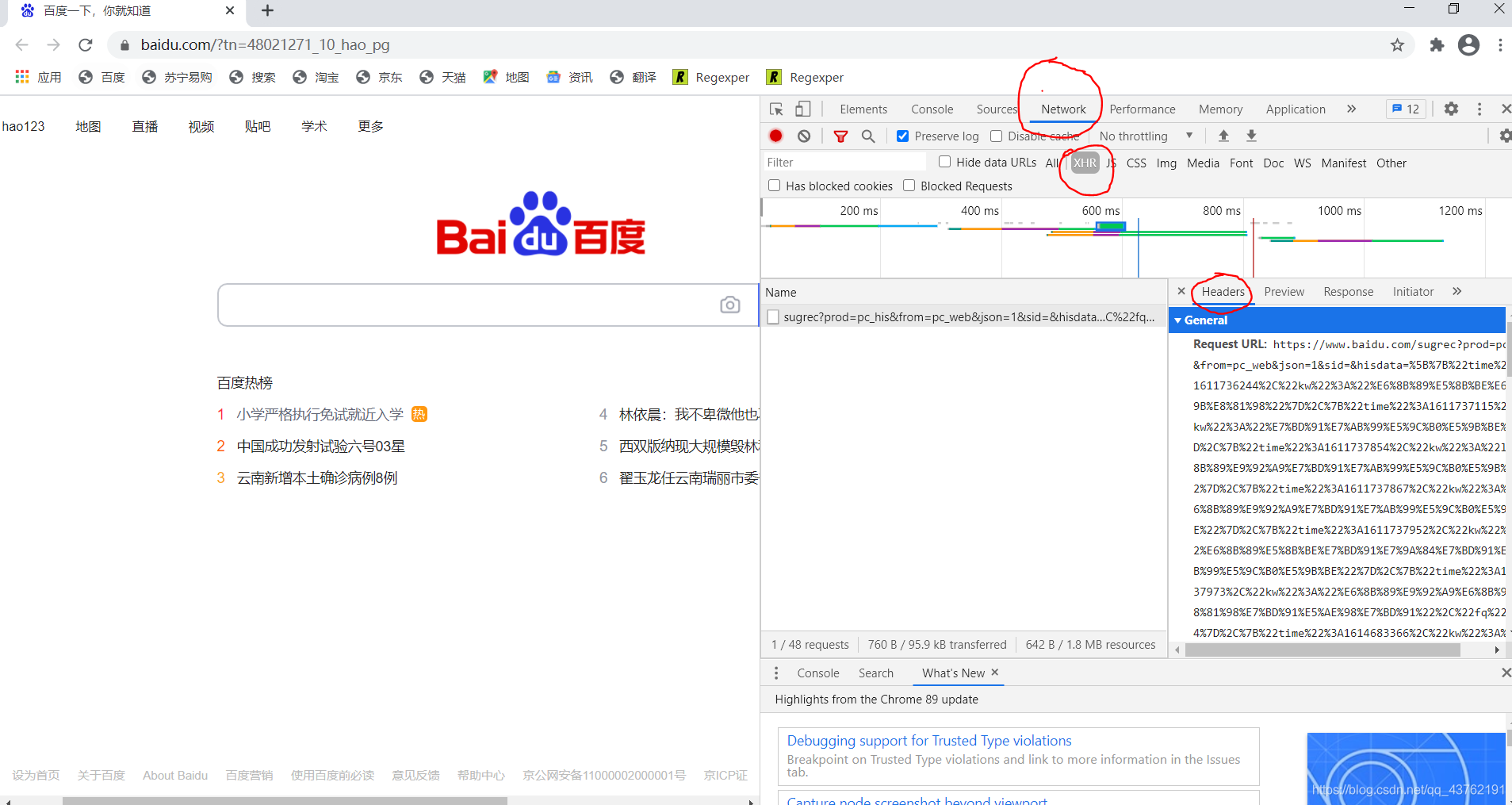
看到沒,我圈起來的那三個圈,從上往下依次點擊兩個,然后會發現包少了一些,隨便點一個,再點我圈出來那第三個圈,然后往下劃,找到一個“User-Agent”打頭的,把后面那個復制下來,
如果沒有就再找一個包,
注二:
那個是網頁校驗碼,當校驗碼在以2XX的形式存在的時候,說明這個網頁可以被爬取,否則就不要想太多啦,
今天就先到這里,下篇見咯,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/274779.html
標籤:其他
上一篇:位元組Android開發崗首戰演算法被慘虐,復盤兩個月再戰拿下2-2
下一篇:雙向回圈鏈表講解及實作