分布式事務
前言:
最近太難了… 要學好多新技術!準備面試,簡歷…專案. 快結業了,好難!
- 天真的我居然,還想學習資料結構…
當然這個我之前看過不過又忘了,之前還準備寫一個 Ouath 認證框架的筆記…都咕咕了! - 唉,最近在搞分布式事務,又加上感冒
MD看了一天才有點眉目! 感冒好難受…😒 - 本篇學習借鑒了以下文章:
感謝大佬
https://blog.csdn.net/bjweimengshu/article/details/79607522
https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
https://www.cnblogs.com/monkeyblog/p/10449363.html
當然這里絕對不是打廣告!而且,我看的可不止這么多,這個是我看的比較好的… 為了方便我后面自己忘記了可以回顧的, - 因為是初學,不正確的地方,感謝提醒!
- 本篇,存在一些大佬的文章搬運,主要是寫的太好了,copy來了… 如果大佬不允許會及時洗掉!
什么是事務
舉個生活中的例子:
- 你去小賣鋪買東西,“一手交錢,一手交貨”就是一個事務的例子
- 交錢和交貨 必須全部成功,事務才算成功
任一個活動失敗,事務將撤銷所有已成功的活動, - 事務可以看做是一次大的活動,它由不同的小活動組成,這些活動要么全部成功,要么全部失敗,
資料庫事務的四大特性 ACID:
A(Atomic):原子性
- 構成事務的所有操作,要么都執行完成,要么全部不執行,不可能出現部分成功部分失敗的情況,
C(Consistency):一致性
- 在事務執行前后,資料庫的一致性約束沒有被破壞,
- 比如
張三100元 ,李四100元,一共200,
李四給張三50
李四50元, 張三150元,一共還是200元!
I(Isolation):隔離性
- 資料庫中的事務一般都是并發的,
- 隔離性是指并發的兩個事務的執行互不干擾,一個事務不能看到其他事務運行程序的中間狀態,
- 通過配置事務隔離級別可以避臟讀、重復讀等問題
D(Durability):持久性
- 事務完成之后,該事務對資料的更改會被持久化到資料庫,且不會被回滾
本地事務 Local Transaction
- 起初,事務僅限于對單一資料庫資源的訪問控制 架構服務化以后,事務的概念延伸到了服務中,
- 倘若將一個單一的服務操作作為一個事務,那么整個服務操作只能涉及一個單一的資料庫資源,
- 這類基于單個服務單一資料庫資源訪問的事務,被稱為
本地事務
分布式事務 | 產生的場景
- 隨著互聯網的快速發展,軟體系統由原來的
單體應用轉變 為分布式應用 - 分布式系統會把一個應用系統拆分為可獨立部署的多個服務,
不同的服務還會有不同的庫
因此需要服務與服務之間遠程協作才能完成事務操作 - 這種分布式系統環境下
由不同的服務之間通過網路遠程協作,在不同的資料庫之間,完成事務稱之為分布式事務
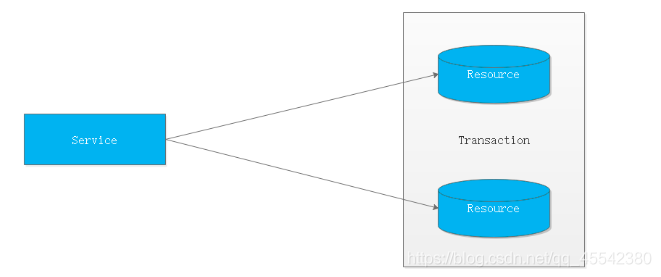
單一服務分布式事務
- 最早的分布式事務應用架構很簡單
- 不涉及服務間的訪問呼叫,僅僅是
服務內操作涉及到對多個資料庫資源的訪問,
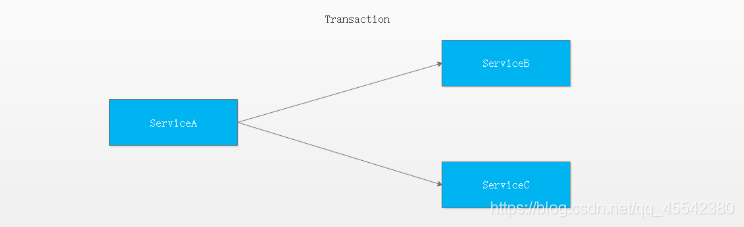
多服務分布式事務
- 一個服務操作訪問不同的資料庫資源
對于上面介紹的分布式事務應用架構,盡管一個服務操作會訪問多個資料庫資源,但是畢竟整個事務還是控制在單一服務的內部, - 一個服務操作需要呼叫另外一個服務,
這時的事務就需要跨越多個服務了
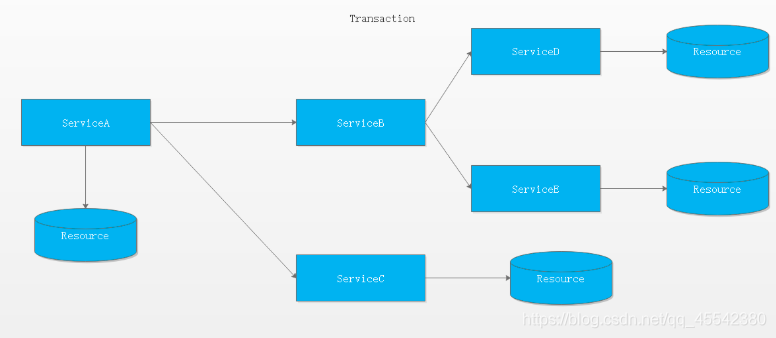
多服務多資料源分布式事務
- 在多個服務之間,且不同服務存在不同的資料庫,的環境下的分布式事務
好牛啊!
事務的作用:
保證每個事務的資料一致性,
分布式事務基礎理論
CAP理論
理解CAP
- CAP是 Consistency、Availability、Partition tolerance三個詞語的縮寫分別表示:
一致性、可用性、磁區容忍性
C (一致性)
- 一致性是指: 寫操作后的 讀操作可以
讀取到最新的資料狀態實時更新! - 對于資料分布在不同節點上的資料來說
如果在某個節點更新了資料,那么在其他節點如果都能讀取到這個最新的資料,那么就稱為 強一致
如果有某個節點沒有讀取到,那就是 分布式不一致
A (可用性)
-
可用性,就是提高程式的高可用… 提高安全…
類似于搭建 集群,一個服務掛了,其它服務繼續作業不影響使用!,但這必然影響了C一致性的性能速度! -
但注意,可用行 會導致 一致性的效率,但也要保證
最終一致性這是事務必須的!
非故障的節點在合理的時間內回傳合理的回應 (不是錯誤和超時的回應) -
所以分布式系統理論上不可能選擇 CA 架構, 只能選擇 CP 或者 AP 架構,
P (磁區容錯性)
-
分布式系統的各各結點部署在不同的子網,這就是
網路磁區
不可避免的會出現由于網路問題而導致結點之間通信失敗,此時仍可對外提供服務,這叫磁區容忍性 -
如何實作磁區容忍性?
盡量使用異步取代同步操作
例如使用異步方式將資料從主資料庫同步到從資料,這樣結點之間能有效的實作
松耦合,
添加從資料庫結點,其中一個從結點掛掉其它從結點提供服務, -
分布式磁區容忍性的特點:
磁區容忍性分是布式系統具備的基本能力,
CAP有哪些組合方式呢?
AP:
- 放棄一致性,追求磁區容忍性和可用性,
- 例如:
商品管理,完全可以實作AP,前提是只要用戶可以接受所查詢的到資料在一定時間內不是最新的即可,
一些業務場景比如: 訂單退款,今日退款成功,明日賬戶到賬,只要用戶可以接受在一定時間內到賬即可,
CP:
- 放棄可用性,追求一致性和磁區容錯性,我們的zookeeper其實就是追求的強一致
- 一些業務場景比如: 搶購商品 秒殺!
CA:
- 放棄磁區容忍性,即不進行磁區,不考慮由于網路不通或結點掛掉的問題,則可以實作一致性和可用性,
- 那么系統將不是一個標準的分布式系統,我們最常用的
關系型資料就滿足了CA
面試題:ZooKeeper 和 eureka 的區別
- ZooKeeper 是 cp eureka 是ap 的架構….
總結
-
CAP理論告訴我們一個分布式系統最多只能同時滿足一致性(Consistency)、可用性(Availability)和磁區容忍
性(Partition tolerance)這三項中的兩項. -
在實際生產中很多場景都要實作一致性
比如我們舉的例子:主資料庫向從資料庫同步資料,即使不要一致性,但是最終也要將資料同步成功來保證資料一致 -
其中AP在實際應用中較多,AP即舍棄一致性,保證可用性和磁區容忍性
BASE理論
- BASE 是 Basically Available(基本可用)、Soft state(軟狀態)和 Eventually consistent (最終一致性)三個短語的縮寫,
- BASE理論是對CAP中AP的一個擴展,通過犧牲強一致性來獲得可用性
當出現故障允許部分不可用但要保證核心功能可用,允許資料在一段時間內是不一致的,但最終達到一致狀態, - 滿足BASE理論的事務,我們稱之為
“柔性事務”
基本可用:
- 分布式系統在出現故障時,允許損失部分可用功能,保證核心功能可用,
- 如,電商網站交易付款出現問題了,商品依然可以正常瀏覽,
軟狀態:
- 由于不要求強一致性,所以BASE允許系統中存在中間狀態(也叫軟狀態)
- 這個狀態不影響系統可用性,如訂單的"支付中"、“資料同步中”等狀態,待資料最終一致后狀態改為“成功”狀態,
最終一致:
- 最終一致是指經過一段時間后,所有節點資料都將會達到一致,
如訂單的"支付中"狀態,最侄訓變為“支付成功”或者"支付失敗",
使訂單狀態與實際交易結果達成一致,但需要一定時間的延遲、等待,
分布式事務解決方案
XA分布式事務協議
- 分布式事務常見的解決方案有:
2pc傳統方案
2PC的傳統方案是在資料庫層面實作的,如Oracle、MySQL都支持2PC協議 - 為了統一標準減少行業內不必要的對接成本,需要制定標準化的處理模型及介面標準
- 國際開放標準組織
Open Group定義了 分布式事務處理模型 DTPDistributed Transaction Processing Reference Model
DTP模型

DTP模型定義如下角色:
-
AP(Application Program):即應用程式,可以理解為使用DTP分布式事務的程式,
-
RM(Resource Manager):即資源管理器
可以理解為事務的參與者,一般情況下是指一個資料庫實體,
通過資源管理器對該資料庫進行控制,資源管理器控制著分支事務, -
TM(Transaction Manager):事務管理器
負責協調和管理事務,事務管理器控制著全域事務,管理事務生命周期,并協調各個RM,
全域事務 是指分布式事務處理環境中,需要操作多個資料庫共同完成一個作業,這個作業即是一個全域事務,
基于XA協議的兩階段提交(2PC)
兩階段提交協議 Two Phase Commitment Protocol 涉及到兩種角色
- 一個
事務協調者(coordinator)TM事務管理器
負責協調多個參與者進行事務投票及提交(回滾) - 多個
事務參與者(participants)RM資源管理器
即本地事務執行者
總共處理步驟有兩個
-
投票階段
(voting phase)參與者操作
協調者將通知,事務參與者 準備提交或取消事務,然后進入表決程序投票階段參與者將告知協調者自己的決策
true: 事務參與者,本地事務執行成功,但未提交
flase: 本地事務執行故障 -
提交階段
(commit phase)協調者操作
收到參與者的通知后,協調者再向參與者發出通知,根據反饋投票情況決定,各參與者是否要提交還是回滾
多個參與者,只要有一個false , 就表示事務執行失敗,通知所有的參與者未提交的事務進行回滾!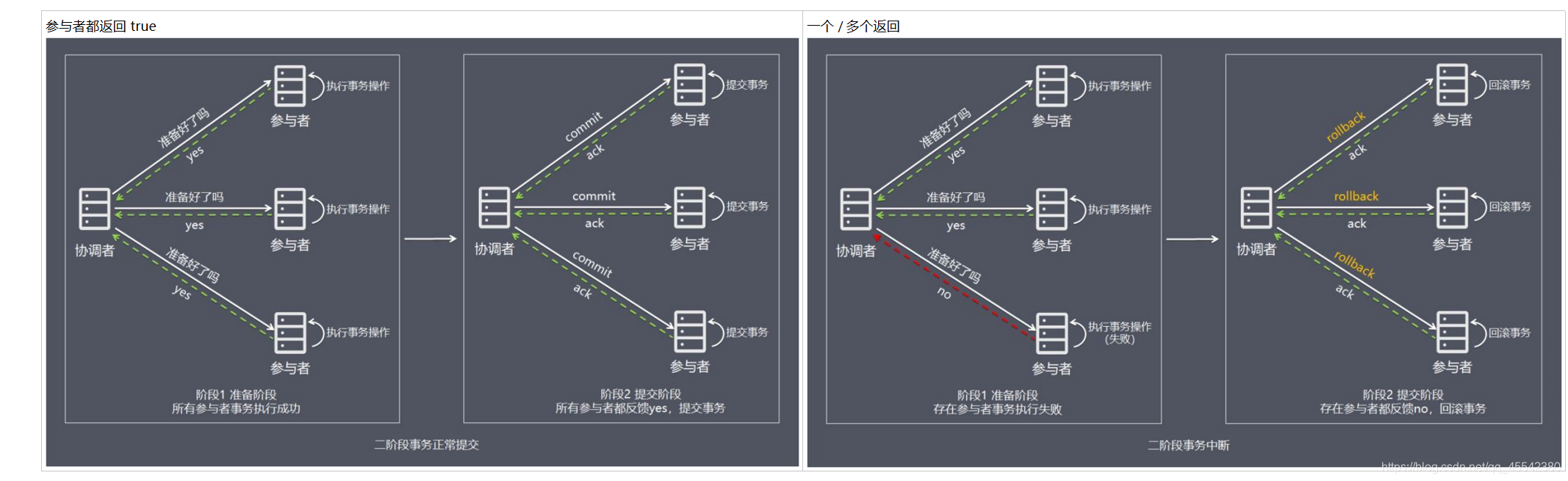
2PC總結:
- 整個2PC的事務流程涉及到三個角色AP、RM、TM,
- AP指的是使用2PC分布式事務的應用程式;
- RM指的是資源管理器,它控制著分支事務;
- TM指的是事務管理器,它控制著整個全域事務,
缺點:
-
在
投票階段,RM執行實際的業務操作,但不提交事務,資源鎖定 -
協調者單點故障問題
3PC階段解此問題!
事務協調者是整個XA模型的核心,
一旦事務協調者節點掛掉,參與者收不到提交或是回滾通知,參與者會一直處于中間狀態無法完成事務, -
丟失訊息導致的不一致問題,
在XA協議的第二個階段,如果發生區域網路問題,一部分事務參與者收到了提交訊息
另一部分事務參與者沒收到提交訊息,那么就導致了節點之間資料的不一致…!!
Seata 實作2PC
Seata方案
- Seata是由阿里中間件團隊發起的開源專案 Fescar,
后更名為SeataSimple Extensible Autonomous Transaction Architecture一套一站式分布式事務解決方案,
解決分布式事務問題,有兩個設計初衷
- 對業務無侵入
即減少技術架構上的微服務化所帶來的分布式事務問題對業務的侵入,實際開發中只要一個注解就搞定了!@Configuration - 高性能
減少分布式事務解決方案所帶來的性能消耗,添加 undo_log 表,本地放心提交事務,可以依靠undo_log進行回滾處理..
seata中有兩種分布式事務實作方案:AT 及TCC
- 本人目前只會AT的…😢
Seata AT模式是基于 XA事務演進而來的一個分布式事務中間件
Seata的設計思想:
Seata的設計目標其一是對業務無侵入,因此從業務無侵入的2PC方案著手 在傳統2PC的基礎上演進,并解決 2PC方案面臨的問題, 第二階段資源占用!
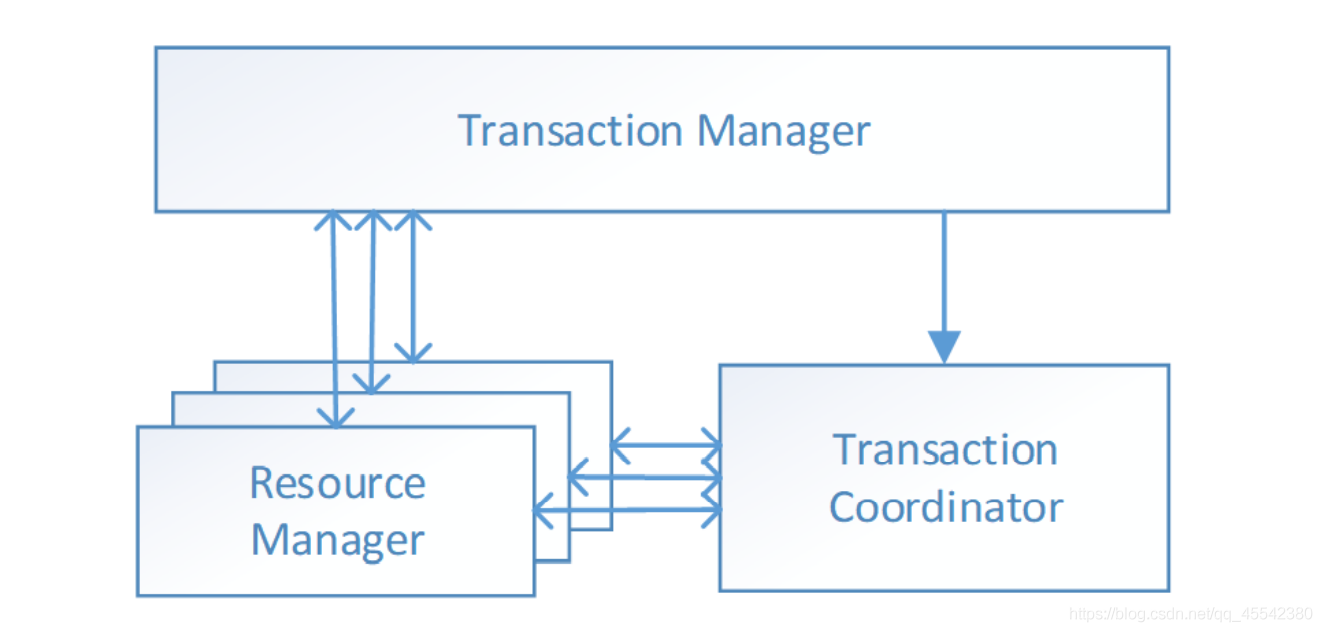
與 傳統2PC 的模型類似,Seata定義了3個組件來協議分布式事務的處理程序:
-
Transaction Manager (TM ): 事務管理器
控制全域事務的邊界,負責開啟一個全域事務,并最終向TC發起全域提交或全域回滾的決議, -
Transaction Coordinator (TC): 事務協調器
事務協調器,維護全域事務的運行狀態,負責協調并驅動全域事務的提交或回滾, -
Resource Manager (RM): 控制分支事務
控制分支事務,負責分支注冊、狀態匯報(投票),
并接收事務協調器的指令,驅動分支(本地)事務的提交和回滾,
具體執行流程:
第一階段
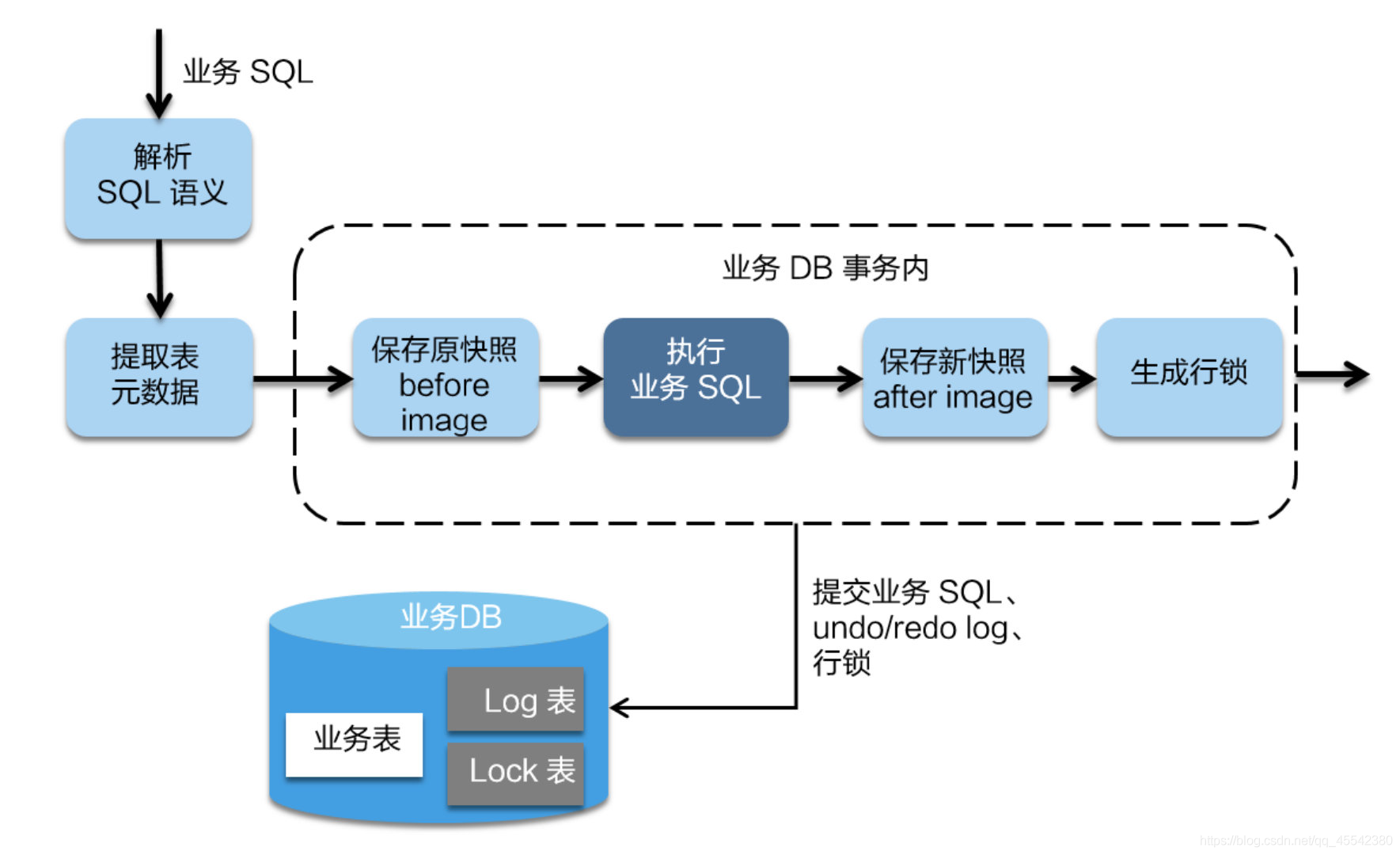
- 在一階段,Seata 會攔截“業務 SQL”
- 首先決議 SQL 語意,找到“業務 SQL”要更新的業務資料,在業務資料被更新前,將其保存成“before image”快照 存在undo_log表中!
- 然后執行“業務 SQL”更新業務資料,在業務資料更新之后,再將其保存成“after image”,最后生成行鎖,
資料庫行鎖:確保多執行緒情況下,改記錄只能由一個執行緒操作! - 以上操作全部在一個資料庫事務內完成,這樣保證了一階段操作的原子性,
- TM 向 TC 申請開啟一個全域事務,全域事務創建成功并生成一個全域唯一的XID
確保后面執行...
第二階段
提交
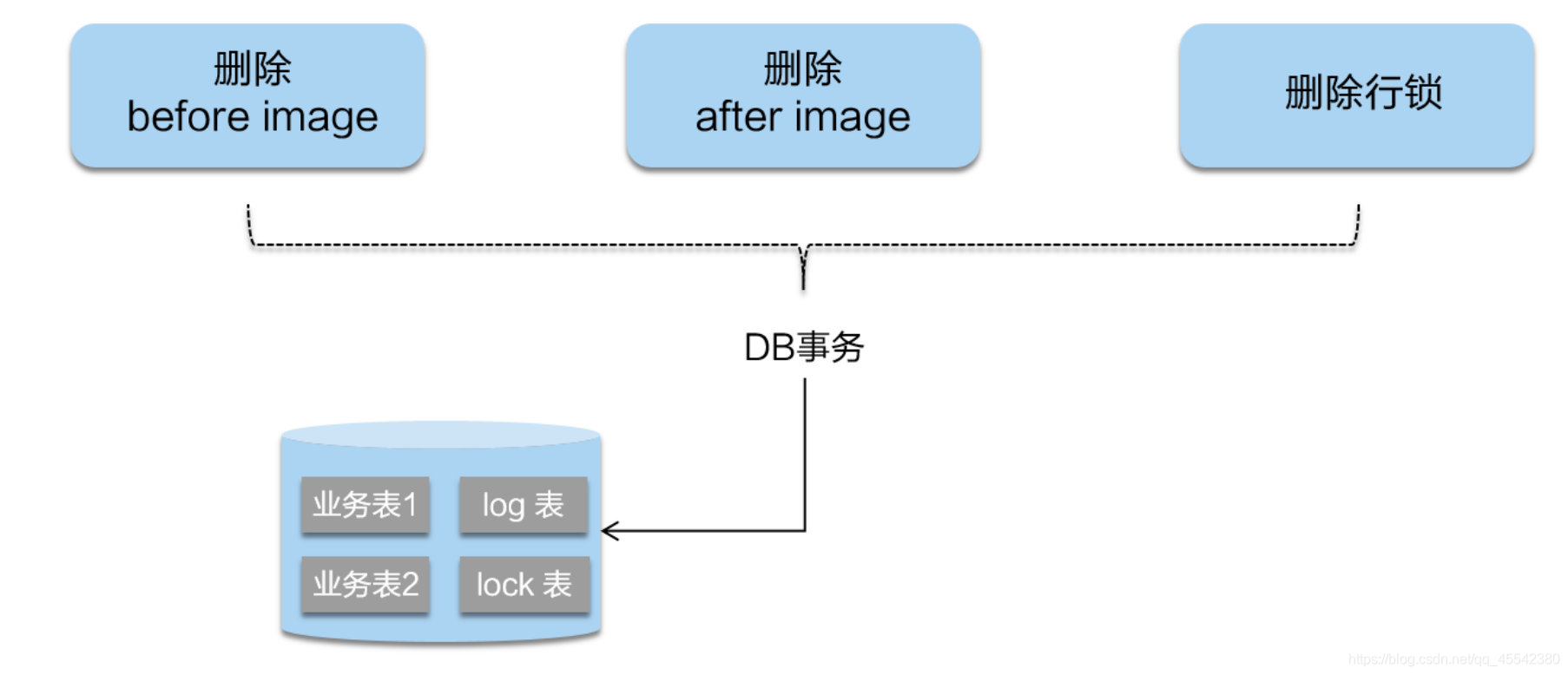
- 第二階段如果是提交的話,因為業務SQL在一階段已經提交至資料庫(已通過)
- 所以 Seata 框架只需將一階段保存的快照資料和行鎖刪掉,完成資料清理即可,
極大提高了第二階段的執行性能!
回滾
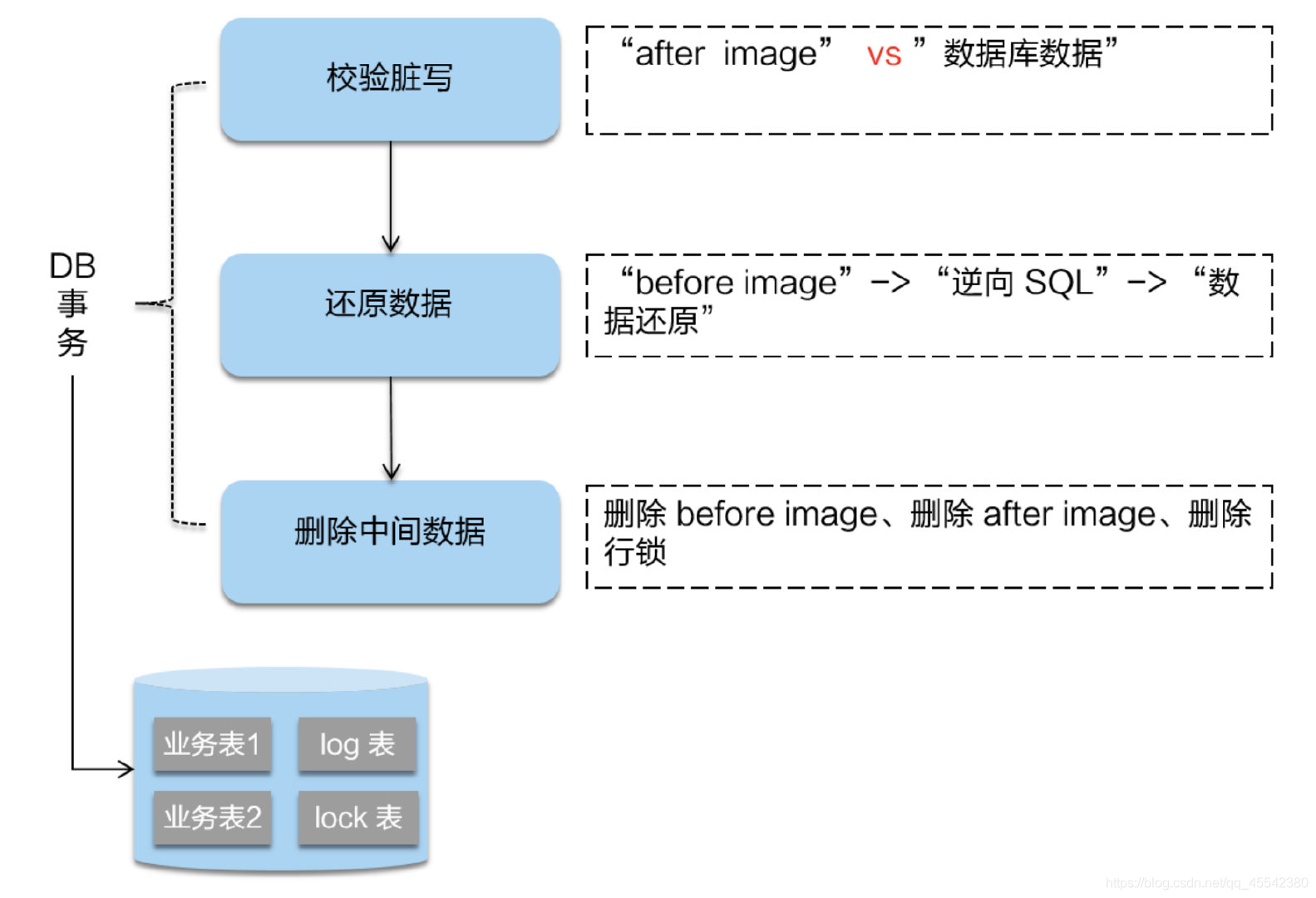
- 第二階段如果是回滾的話
Seata就需要回滾一階段已執行的的業務SQL,當然回滾方式是使用before image鏡像還原業務資料, - RM 收到協調器發來的回滾請求,通過 XID執行緒id 和 Branch ID 分支id 找到相應的回滾日志記錄
- 在還原之前還要進行校驗臟寫
判斷當前的資料,和undo表中,執行后的資料是否一致.事務執行后的資料是否被更改過!
如果兩份資料完全一致就說明沒有臟寫,可以還原業務資料
如果不一致就說明有臟寫,出現臟寫就需要轉人工處理,
Seata 2PC與傳統2PC的差別
架構層次方面
- 傳統2PC方案的 RM 實際上是在資料庫層,RM 本質上就是資料庫自身 通過 XA 協議實作
- 而Seata的 RM 是以jar包的形式作為中間件層部署在應用程式這一側的,
兩階段提交方面
- 傳統2PC無論第二階段的決議是commit還是rollback
事務性資源的鎖都要保持到第二階段完成才釋放, - 而Seata的做法是在 階段一就將本地事務提交
將提交前的資料資訊,保存在undo_log表中...,這樣就可以省去階段二持鎖的時間,整體提高效率,
Spring Cloud 快速集成 Seata
- 上面理論,了解即可…具體的本人還不是很清除后面可能會整理學習…
目前會用即可! - Seata使用起來還是非常簡單的!
- Github 集成檔案
依賴:
- 一般給要管理的微服加入即可,但因為幾乎所有的微服都需要,所有就放在公共的
util微服里了!
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-seata</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
或
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
因為:
spring-cloud-starter-alibaba-seata 這個依賴中只依賴了spring-cloud-alibaba-seata
所以在專案中添加spring-cloud-starter-alibaba-seata和spring-cloud-alibaba-seata是一樣的
添加組態檔
- 同上一般都放在公共的
util微服模塊的, resourece資源檔案目錄下:
registry.conf
- 該配置用于指定 TC 的注冊中心和組態檔,默認都是 file;
- 如果使用其他的注冊中心,要求 Seata-Server 也注冊到該配置中心上
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "file" #默認 file檔案型別
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
file.conf
- 該配置用于指定TC的相關屬性;如果使用注冊中心也可以將配置添加到配置中心
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.my_test_tx_group = "default"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
## transaction log store
store {
## store mode: file、db
mode = "file"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
committing-retry-delay = 30
asyn-committing-retry-delay = 30
rollbacking-retry-delay = 30
timeout-retry-delay = 30
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
修改應用程式yml
- 在各個需要分布式事務的模塊添加yml,并且指定file.conf中配置通信指定組名
my_test_tx_group
.yml
spring:
cloud:
alibaba:
seata:
tx-service-group: my_test_tx_group
注入資料源
- 同上,為了方便操作
一般直接放在公共的util 模塊中 - Seata 通過代理資料源的方式實作分支事務,MyBatis和JPA都需要注入
io.seata.rm.datasource.DataSourceProxy - 不同的是MyBatis 還需要額外注入
org.apache.ibatis.session.SqlSessionFactory
DataSourceProxyConfig.Java
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
//JPA 不需要注入sqlSessionFactoryBean
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
return sqlSessionFactoryBean.getObject();
}
}
添加 undo_log 表
- 在業務相關的資料庫中添加 undo_log 表,
用于保存需要回滾的資料每個參與分布式事務都要加這個庫! - 分布式事務是多個資料庫的操作,
給每個資料庫加入一個undo_log日志表!
undo_log.sql
CREATE TABLE `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`branch_id` BIGINT(20) NOT NULL,
`xid` VARCHAR(100) NOT NULL,
`context` VARCHAR(128) NOT NULL,
`rollback_info` LONGBLOB NOT NULL,
`log_status` INT(11) NOT NULL,
`log_created` DATETIME NOT NULL,
`log_modified` DATETIME NOT NULL,
`ext` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8

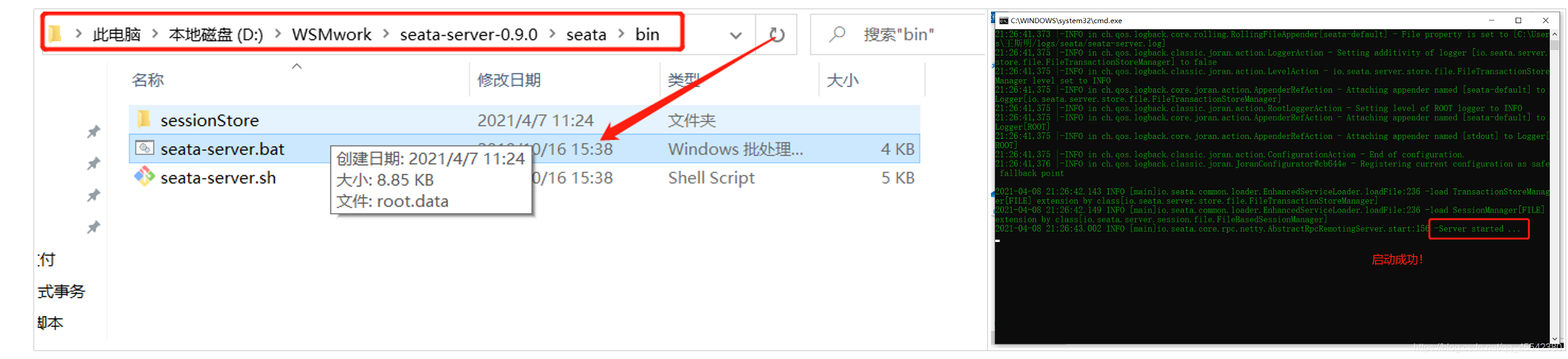
啟動 Seata-Server
- 需要的朋友,在 https://github.com/seata/seata/releases 下載相應版本的 Seata-Server
- 修改 registry.conf為相應的配置(如果使用 file 則不需要修改)
- Seata解壓即用,一般不需要配置任何東西!
- 啟動
sh ./bin/seata-server.sh
使用@GlobalTransactional開啟事務
-
在業務的發起方的方法上使用
@GlobalTransactional開啟全域事務就是你業務執行的總方法! -
Seata 會將事務的 xid 通過攔截器添加到呼叫其他服務的請求中,實作分布式事務
-
在事務調度的 總方法上加 @GlobalTransactional
全域事務注解
基于XA協議的三階段提交(3PC)
3PC三階段,提交是在二階段提交上的改進版本,主要是加入了超時機制,同時在 協調者和參與者中都引入超時機制
- XA三階段提交在兩階段提交的基礎上增加了CanCommit階段,并且引入了超時機制,
- 一旦事物參與者遲遲沒有接到協調者的commit請求,會自動進行本地commit,這樣有效解決了協調者單點故障的問題,
- 但是性能問題和不一致的問題仍然沒有根本解決,
需要開發者介入!
三階段將二階段 準備階段拆分為2個階段
- 在原先的 準備提交can Commit 后面 插入了一個preCommit 預提交階段
- 以此來處理原先:二階段參與者準備后,協調者發生崩潰或錯誤
導致參與者無法知曉是否提交或回滾的不確定狀態所引起的延時問題,
階段一 canCommit
- 不變一切正常
- 協調者向參與者發送 commit 請求,參與者如果可以提交就回傳 yes 回應(參與者不執行事務操作),否則回傳 no 回應;
階段二 preCommit
- 協調者根據階段 1 canCommit 參與者的反應情況來決定是否可以進行基于事務的 preCommit 操作,
- 根據回應情況,有以下
兩種可能
情況 1:階段 1 所有參與者均反饋 yes,參與者預執行事務
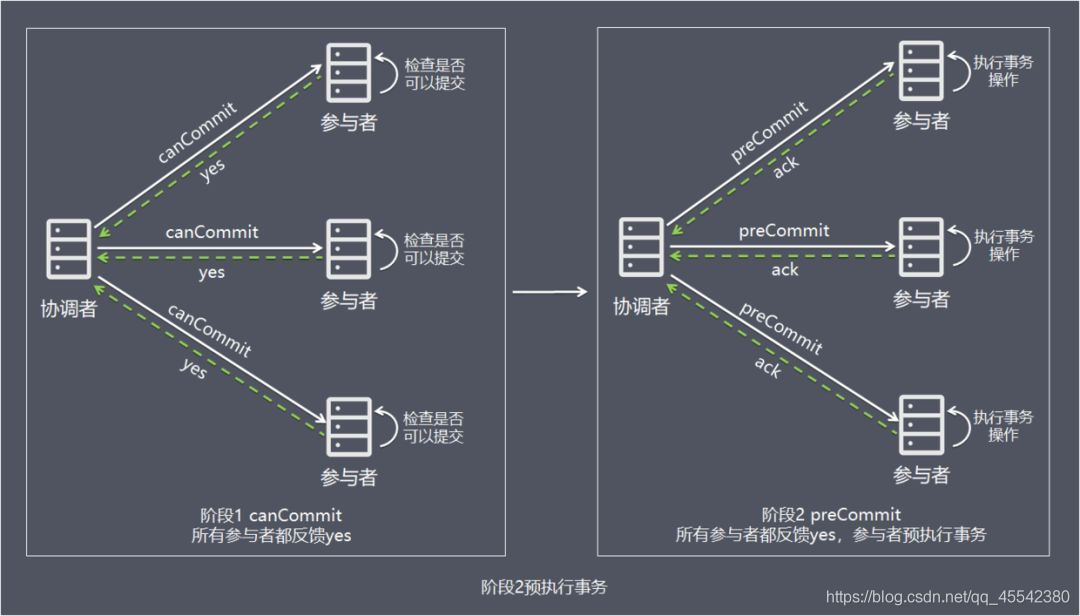
- 協調者向所有參與者發出 preCommit 請求,進入準備階段,
- 參與者收到 preCommit 請求后,執行事務操作,將 undo 和 redo 資訊記入事務日志中(但不提交事務),
- 各參與者向協調者反饋 ack 成功回應或 no 失敗回應,并等待最終指令,
情況 2:階段 1 任何一個參與者反饋 no,或者等待超時后協調者尚無法收到所有參與者的反饋,即中斷事務
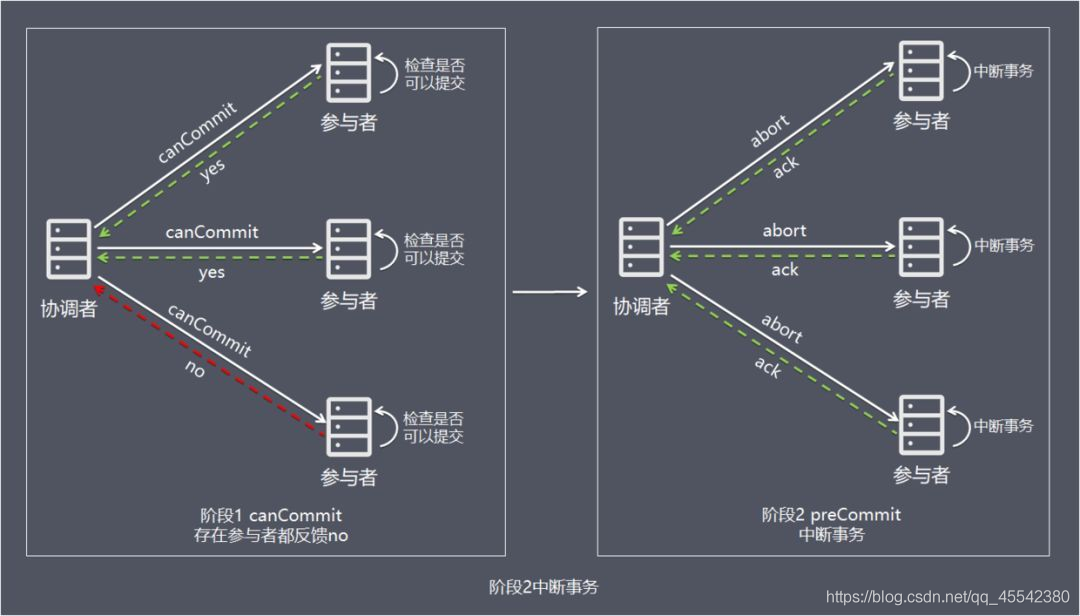
- 協調者向所有參與者發出 abort 請求,
- 無論收到協調者發出的 abort 請求,或者在等待協調者請求程序中出現超時,參與者均會中斷事務,
- 即:
階段一回傳一個 no 中斷所有事務參與者 未接收到 協調者訊息 中斷本身事務!解決了協調者突然掛了的情況!
階段三 do Commit
- 該階段進行真正的事務提交
也可以分為以下兩種情況,
情況一 階段 2 所有參與者均反饋 ack 回應,執行真正的事務提交
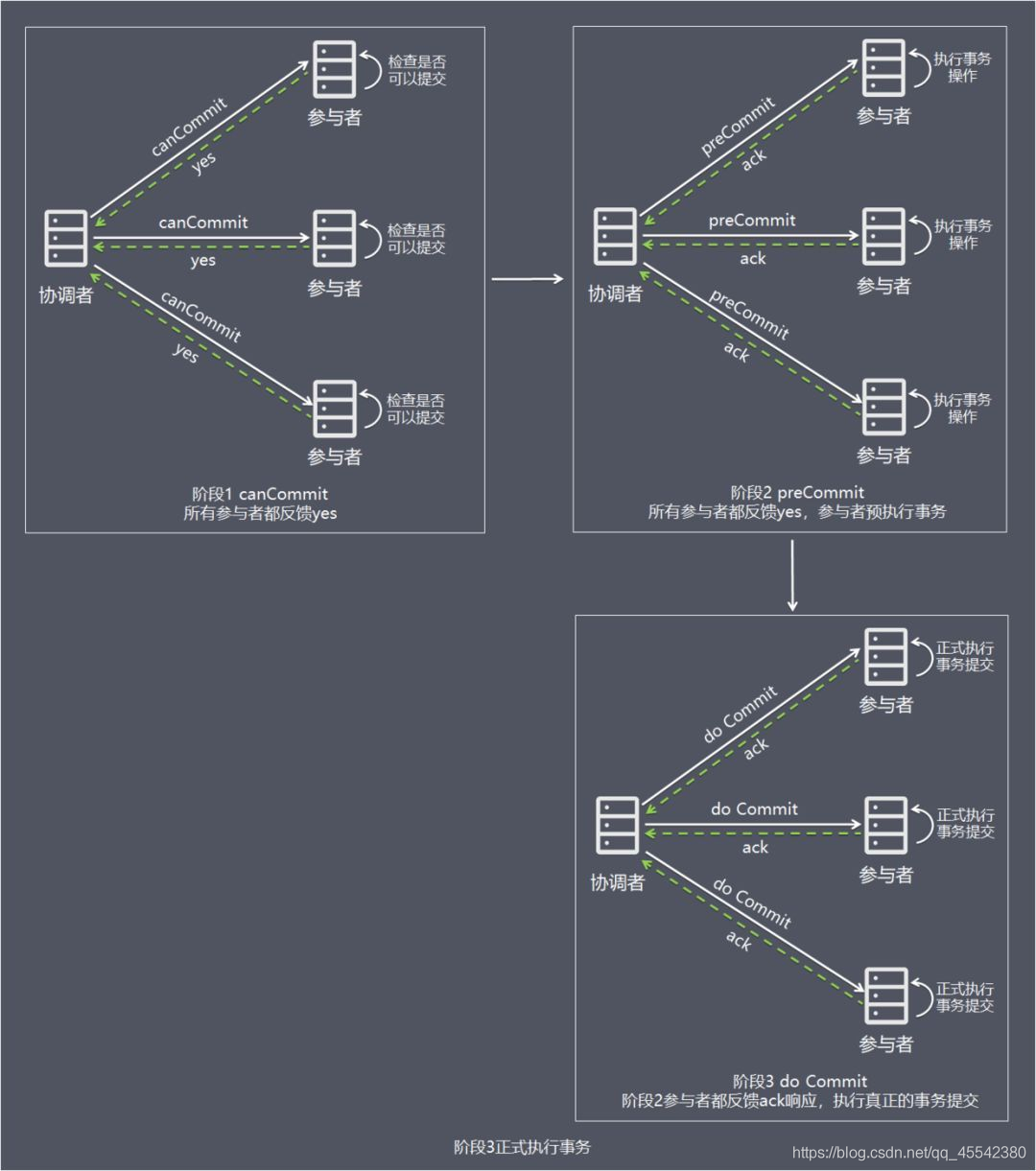
- 如果協調者處于作業狀態,則向所有參與者發出 do Commit 請求,
- 參與者收到 do Commit 請求后,會正式執行事務提交,并釋放整個事務期間占用的資源,
- 各參與者向協調者反饋 ack 完成的訊息,
- 協調者收到所有參與者反饋的 ack 訊息后,即完成事務提交,
情況二 階段 2 任何一個參與者反饋 no,或者 等待超時后 協調者尚無法收到所有參與者的反饋,即中斷事務
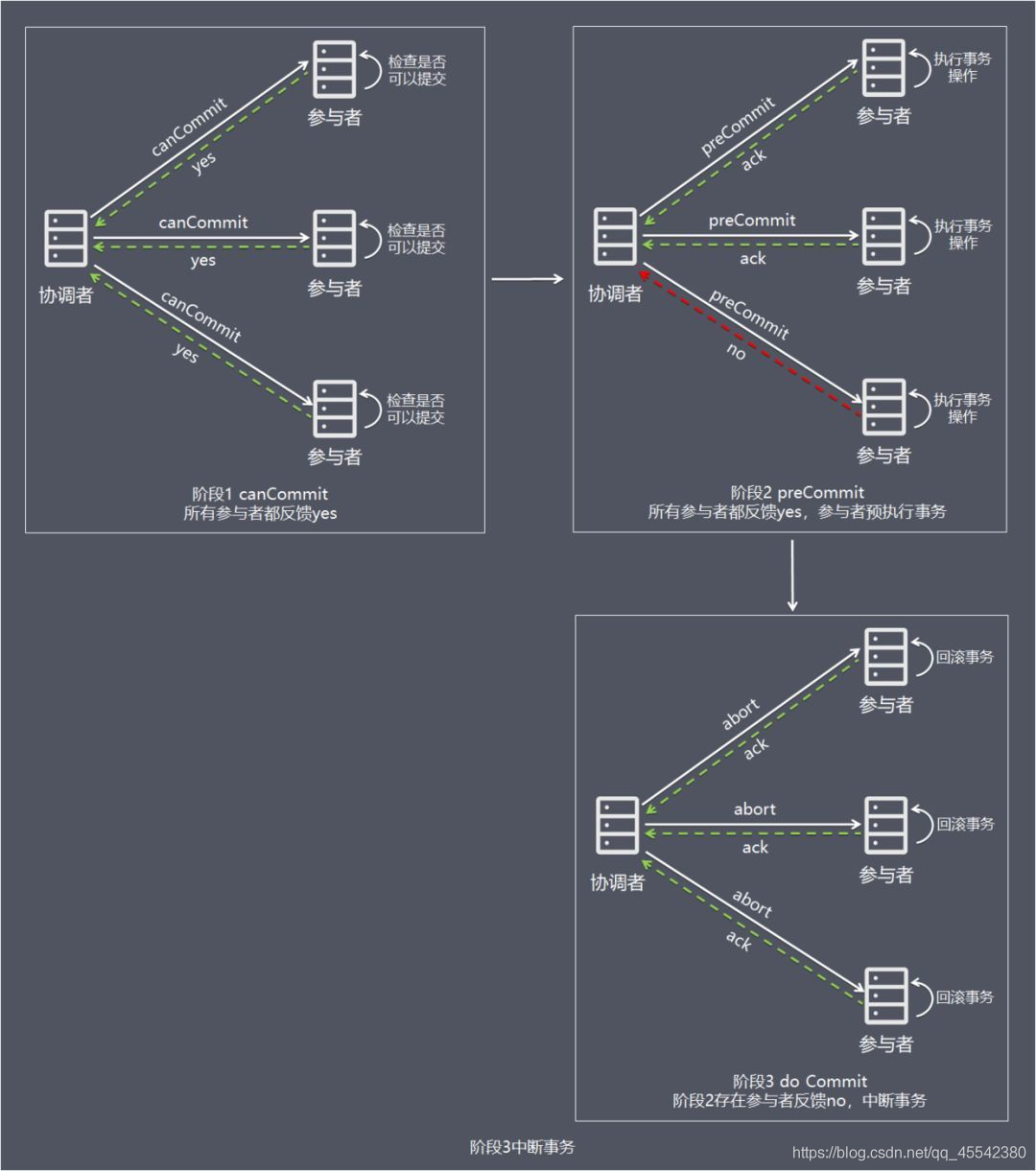
- 如果協調者處于作業狀態,向所有參與者發出 abort 請求,
- 參與者使用階段 1 中的 undo 資訊執行回滾操作,并釋放整個事務期間占用的資源,
- 各參與者向協調者反饋 ack 完成的訊息,
- 協調者收到所有參與者反饋的 ack 訊息后,即完成事務中斷,
注意:
- 進入階段 3 后,無論協調者出現問題,或者協調者與參與者網路出現問題
都會導致參與者無法接收到協調者發出的 do Commit 請求或 abort 請求, - 此時,參與者都會在等待超時之后,
繼續執行事務提交,
優點:
- 相比二階段提交,三階段提交降低了阻塞范圍,在等待超時后協調者或參與者會中斷事務,
- 避免了協調者單點問題,階段 3 中協調者出現問題時,參與者會繼續提交事務,
缺點:
- 資料不一致問題依然存在
- 當在參與者收到 preCommit 請求后等待 do commite 指令時,此時如果協調者請求中斷事務
- 而協調者無法與參與者正常通信,會導致參與者繼續提交事務,造成資料不一致,
即:階段三如果 協調者出現故障,仍會導致資料事務不一致!!需要開發者介入!
TCC三段提交
- TCC是Try
嘗試、Confirm確認、Cancel撤銷三個詞語的縮寫
Try操作做業務檢查及資源預留
Confirm做業務確認操作
Cancel實作一個與Try相反的操作即回滾操作 - TM首先發起所有的分支事務的try操作,任何一個分支事務的try操作執行失敗
- TM將會發起所有分支事務的Cancel操作,
- 若try操作全部成功,TM將會發起所有分支事務的Confirm操作
- 其中Confirm/Cancel操作若執行失敗,TM會進行重試,
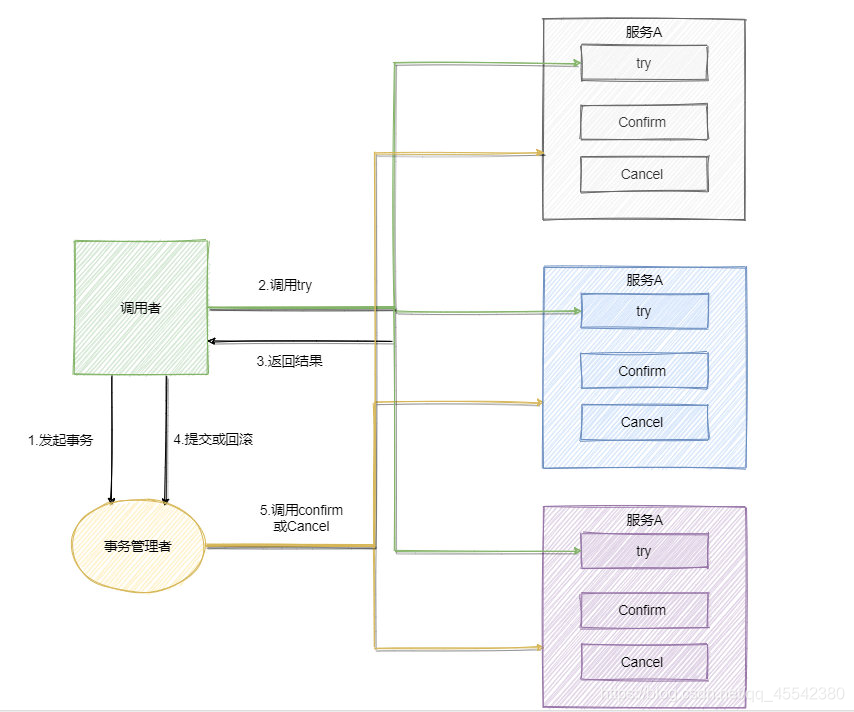
其實從思想上看和 2PC 差不多,都是先試探性的執行,如果都可以那就真正的執行,如果不行就回滾,
流程還是很簡單的
- 難點在于業務上的定義,對于每一個操作你都需要定義三個動作分別對應
Try - Confirm - Cancel
因此 TCC 對業務的侵入較大和業務緊耦合需要根據特定的場景和業務邏輯來設計相應的操作,很多時候需要手動補償代碼! - 注意 撤銷和確認操作的執行可能需要重試,因此還需要保證操作的冪等,
冪等:無論程式執行n次,保證最終執行結果唯一!
2PC 和 3PC 都是資料庫層面的,而 TCC 是業務層面的分布式事務
- 開發者,手動撰寫邏輯,進行提交回滾,
補償代碼發送短信等… - 目前本人沒有具體的了解… 后面也許會更新!
本地訊息表 (MQ+Table) 最終一致性
- 學習之前需要了解: MQ 定時框架
可靠訊息最終一致性事務
- 利用訊息中間件來異步完成事務的后一半更新,實作系統的最終一致性
這個方式避免了像XA協議那樣的性能問題,
方案簡介:
- 本地訊息表的方案最初是由 eBay 提出,
核心思路是將分布式事務拆分成本地事務進行處理, - 事務主動發起方 微服 資料庫額外新建
事務訊息表 - 事務發起方,發起處理業務 并記錄訊息在
事務訊息表中 - 通過
輪詢事務訊息表的資料發送事務訊息 - 事務被動方基于訊息中間件消費事務訊息表中的事務,
進行處理!
優點:
- 可以避免:
業務處理成功 + 事務訊息發送失敗或業務處理失敗 + 事務訊息發送成功多個系統事務的資料最終一致性
缺點:
- 與具體的業務場景系結,耦合性強,不可公用,
- 訊息資料與業務資料同庫,占用業務系統資源,
- 業務系統在使用關系型資料庫的情況下,訊息服務性能會受到關系型資料庫并發性能的局限,
業務實作:
-
上面的說法可能不是很清晰,這里可以結合業務場景進行處理!
-
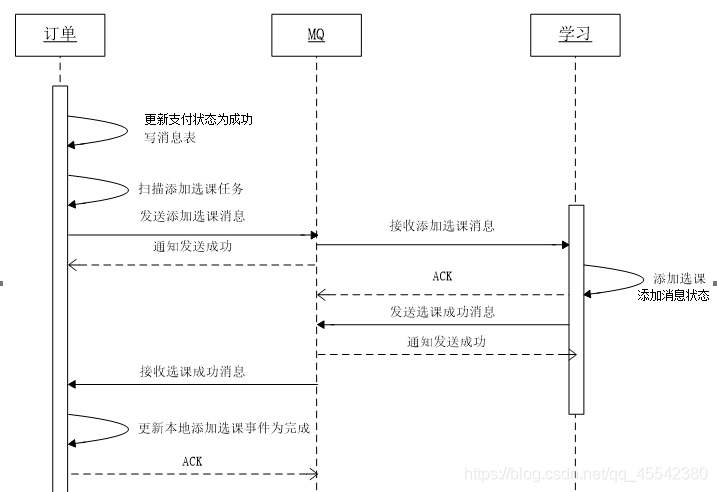
某學習平臺,用戶下單購買商品產生訂單,學習任務模塊添加 學習課程!
隨便編的業務別杠
-
支付成功后,訂單服務向本地資料庫更新訂單狀態,
并向訊息表寫入“添加選課訊息” task_his.sql:任務資訊mq 交換機/佇列version版本...
這里的 操作是本地事務執行 要么全部失敗,要么全部成功!且如果這里,就事務執行失敗了,直接回滾事務失敗! -
通過
定時框架定時掃描 task_his.sql 表資訊,向MQ中發送訊息
避免了如果在發送訊息時候,網路動蕩訊息發送失敗! -
MQ 通過
Confirm 訊息確認100%發送訊息本人使用的RabbitMQ 這個問題不大!
確保訊息一定會發送到MQ 上!
對于這里,因為定時框架會每隔一段時間,就掃描訊息表回圈向mq 上發訊息!
mq 發送成功就成功!
mq 發送失敗, 也不會立刻,重新發送當然如果直接重新發送也行不同場景不同處理! 反之無論如何都會發的MQ 上! -
學習模塊實時監聽 MQ的訊息佇列,只要有信訊息就接收,并繼續執行自己的業務操作
同時它也寫入自己的事務訊息表
事務執行成功/失敗 都寫入事務訊息表中
根據MQ的訊息確認接識訓制(ACK)訊息一旦被消費者接識訓傳 ack,佇列中的訊息就會被洗掉,
手動ACK: 訊息接收后,不會發送ACK,需要手動呼叫,學習模塊執行完畢才回傳 ack確保了訊息的消費!
注意 這里還是要做 冪等的操作!無論程式執行n次,保證結果唯一!
方式很多,可以是根據任務請求內容,獲取訂單id 判斷是否執行過… -
執行之后,學習模塊將訊息表,內容發送到MQ 上!
mq 通知發送成功/失敗
問題不大! 可以處理,或不處理,但一定會發上去的! 因為之前有定時操作第一次沒發上去后面還會執行!而對于多次執行 冪等處理. -
訂單模塊接收MQ 上訊息,判斷事務是否執行成功!回滾/提交,并洗掉
訊息表的訊息!就避免了訊息在在次 定時發送!
常見的訊息表:
- 不是絕對的,這個訊息表根據實際開發中更改即可!
task_his.sql
DROP TABLE IF EXISTS `task_his`;
CREATE TABLE `task_his` (
`id` varchar(32) NOT NULL COMMENT '任務id',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`delete_time` datetime DEFAULT NULL,
`task_type` varchar(32) DEFAULT NULL COMMENT '任務型別',
`mq_exchange` varchar(64) DEFAULT NULL COMMENT '交換機名稱',
`mq_routingkey` varchar(64) DEFAULT NULL COMMENT 'routingkey',
`request_body` varchar(512) DEFAULT NULL COMMENT '任務請求的內容',
`version` int(10) DEFAULT '0' COMMENT '樂觀鎖版本號',
`status` varchar(32) DEFAULT NULL COMMENT '任務狀態',
`errormsg` varchar(512) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 任務 創建時間 更新時間 洗掉時間
要操作MQ 交換機 佇列資訊! - 為方式分布式多服務 version 設定樂觀鎖版本號!
- …
Spring Task定時任務
- 依賴:
- 在Spring boot啟動類上添加注解:@EnableScheduling
- 任務類
- Quartz 是一個異步任務調度框架,功能豐富,可以實作按日歷調度
定時任務類:
- 僅供參考…
MessageTaskJob.Java
@Component
public class MessageTaskJob {
@Autowired
private TbTaskService taskService; //訊息表業務物件!
@Scheduled(cron = "0/30 * * * * ?") //定時每三十秒掃描一次 訊息表!
public void showTask() {
System.out.println("查詢任務資料!");
try {
//獲取一分鐘前訊息表資料!
List<TbTask> list = taskService.getBeforTaskList();
//回圈變數發送MQ訊息...
for (TbTask tbTask : list) {
//使用樂觀鎖解決高并發下的資訊發送...后面解釋!
if (taskService.updateVersionLock(tbTask.getId(), tbTask.getVersion()) > 0) {
//發送MQ...
taskService.publishTaskMessage(tbTask);
//發送之后修改,當前 訂單訊息表的記錄時間..當前時間即可!
//因為定時會回圈,如果訊息發送失敗..則直接下次在輪詢重新發送即可!
taskService.updateTaskUpdateTime(tbTask.getId());
System.out.println("發送訊息并,修改時間!");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 修改時間,是為了, 防止訊息發送失敗等原因, 將時間修改為當前時間,
定時操作執行在次發送...確保最終一致性! - 為啥MQ 存在訊息確認機制,還要這么做.
不同的人不同的寫法… 反之最終要發到 mq 上就ok了…
這里將時間重排,重新定時發送 個人覺得為了公平… 你去銀行排隊辦理業務,缺少檔案回去辦理…回來了當然要重新排隊.
Mybatis sql參考
<!-- 獲取一分鐘前訊息表的所有資料! -->
<select id="getBeforTaskList" resultType="com.zb.entity.TbTask">
select
id as id,
create_time as createTime,
update_time as updateTime,
delete_time as deleteTime,
task_type as taskType,getBeforTaskList
mq_exchange as mqExchange,
mq_routingkey as mqRoutingkey,
request_body as requestBody,
status as status,
errormsg as errormsg,
version as version
from tb_task
WHERE TIMESTAMPDIFF(MINUTE,update_time, NOW())>1
</select>
<!-- 發送訊息成功更改時間... -->
<update id="updateNowTime" >
update tb_task set update_time =now() where id=#{id}
</update>
<!-- 樂觀鎖:多執行緒情況下防止,統一訊息發送多次處理...
根據 id version版本 來進行修改..
-->
<update id="updateVersioLock">
update tb_task set version =#{version}+1 where id=#{id} and version=#{version}
</update>
樂觀鎖取任務
- 考慮訂單服務將來會集群部署
- 為了避免任務在
定時任務內重復執行,這里使用樂觀鎖
A B 執行緒執行任務都查到了訊息集合A 發送了任務1 B 也發送了任務1 重復操作! - 樂觀鎖處理:
A B執行緒都進入方法獲取到訊息集合A 先執行并帶著版本號+id去給版本+1 B因為查的訊息集合并不是最新的id+版本號去修改影響行數小于0 不執行發送任務!
但如果:A執行緒執行特別快修改了版本,但是B執行慢才查到,獲取了最新的 訊息集合
-
就悲劇了…
-
所以,可以在A修改版本號同時,修改當前時間…
-
這樣:B無論執行快慢都避免了重復操作!
快: 因為版本 id 修改不了,影響行數不大于 0
慢: 因為時間更改了,直接就獲取不到最新的資料了… -
這只是我的個人想法: 實際開發另算根據場景來定~
事務訊息 RocketMQ [alibaba提供MQ技術]
- 并不了解…但是聽說過,
后面準備學習!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/274880.html
標籤:其他
上一篇:資料結構-順序表