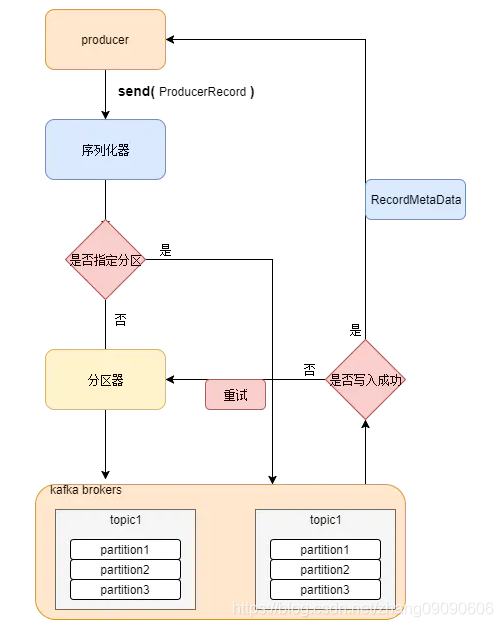
一、生產者發送訊息的程序
1.包裝 ProducerRecord 物件
Kafka 會將發送訊息包裝為 ProducerRecord 物件, ProducerRecord 物件包含了目標主題和要發送的內容,同時還可以指定鍵和磁區,在發送 ProducerRecord 物件前,生產者會先把鍵和值物件序列化成位元組陣列,這樣它們才能夠在網路上傳輸,
2.指定磁區
接下來,資料被傳給磁區器,如果之前已經在 ProducerRecord 物件里指定了磁區,那么磁區器就不會再做任何事情,如果沒有指定磁區 ,那么磁區器會根據 ProducerRecord 物件的鍵來選擇一個磁區,緊接著,這條記錄被添加到一個記錄批次里,這個批次里的所有訊息會被發送到相同的主題和磁區上,
3.放入快取
分好區的訊息不是直接被發送到服務端,而是放入了生產者的一個快取里面,在這個快取里面,多條訊息會被封裝成為一個批次(batch),默認一個批次的大小是 16K,
4.發送訊息
Sender 執行緒啟動以后會從快取里面去獲取可以發送的批次,把這些記錄批次發送到相應的 broker 上,
5.接識訓傳
服務器在收到這些訊息時會回傳一個回應,如果訊息成功寫入 Kafka,就回傳一個 RecordMetaData 物件,它包含了主題和磁區資訊,以及記錄在磁區里的偏移量,如果寫入失敗,則會回傳一個錯誤,生產者在收到錯誤之后會嘗試重新發送訊息,如果達到指定的重試次數后還沒有成功,則直接拋出例外,不再重試
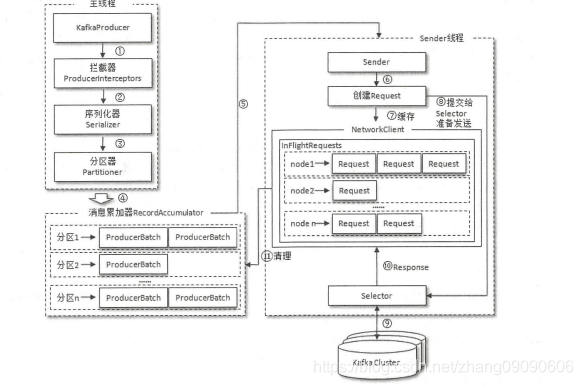
二、生產者整體架構
三、序列化
生產者需要用序列化器(Serializer)把物件轉換成位元組陣列才能通過網路發送給Kaflca, 而在對側, 消費者需要用反序列化器(Deserializer)把從Kaflca 中收到的位元組陣列轉換成相應的物件,訊息的key和value都使用了字串, 對應程式中的 序列化器也使用了客戶端自帶的org.apache.kaflca. common. serialization. StringSerializer, 除了用于 String 型別的序列化器,還有ByteArray、ByteBuffer、 Bytes、 Double、Integer、 Long這幾種類 型, 它們都實作了org.apache.kaflca. common. serialization. Serializer介面, 此介面有3個方法:
public void configure(Map<String, ?> configs, boolean isKey)
public byte[] serialize(String topic, T data)
public void close()configure()方法用來配置當前類,serialize()方法用來執行序列化操作, 而close()方法用來關閉當前的序列化器, 一般情況下close()是一個空方法, 如果實作了此方法, 則必須確保此方法的幕等性, 因為這個方法很可能會被KafkaProducer 呼叫多次, 生產者使用的序列化器和消費者使用的反序列化器是需要一一對應的, 如果生產者使用了 某種序列化器, 比如StringSerializer, 而消費者使用了另 一種序列化器, 比如IntegerSerializer,那么是無法決議出想要的資料的
kakfa支持配置自定義序列化:只需將KafkaProducer的value.serializer 引數設定為CompanySerializer類的全限定名即可,
四、磁區器
public int partition(S七ring topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
public void close()如果key不為null,那么磁區號會是所有磁區中的任意一個,如果為null則僅會為可用磁區中的任意一個
五、生產者攔截器
public ProducerRecord<K, V> onSend (ProducerRecord<K, V> record );
public void onAcknowledgement(RecordMetadata metadata , Exception exception );
public void close() ;KafkaProducer 在將訊息序列化和計算磁區 前會調 生產者攔截器 onSend() 方法來對消息進行相應 定制化操作,一般來說最好不要修改訊息 ProducerRecord 的topic和partition 等資訊,如果要修改,則需確保對其有準確的判斷,否則會與預想的效果出現偏 差,比如修改 key 不僅會影響磁區的計算,同樣會影響 broker 端日志壓縮( Log Compaction) 的功能
六、RecordAccumulator訊息累加器(緩沖區)
七、kafka發送訊息
send()本身是異步的,但是呼叫send()后可以通過代碼實作同步還是異步,異步:一旦訊息被保存在等待發送的訊息快取中,此方法就立即回傳,這樣并行發送多條訊息而不阻塞去等待每一條訊息的回應,當然也可以使用同步發送但是性能差,不推薦
簡單同步發送實作方法:
在呼叫send方法后直接呼叫get方法強行堵塞
RecordMetadata metadata = producer.send(record).get();異步實作
通常我們并不關心發送成功的情況,更多關注的是失敗的情況,因此 Kafka 提供了異步發送和回呼函式, 代碼如下:
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.out.println("進行例外處理");
} else {
System.out.printf("topic=%s, partition=%d, offset=%s \n",
metadata.topic(), metadata.partition(), metadata.offset());
}
}
});
八、重要的生產者引數
在kafka生產者中大部分的引數都有合理的默認值,一般不需要修改它們
1.acks
(1)acks=1
默認值即為1 ,生產者發送訊息之后,只要磁區的 leader 副本成功寫入消 息,那么它就會收到來自服務端的成功回應,如果訊息無法寫入 leader 副本,比如在 leader副本崩潰、重新選舉新的 leader 副本的程序中,那么生產者就會收到一個錯誤的回應,為了避免訊息丟失,生產者可以選擇重發訊息,如果訊息寫入 leader 副本并 回傳成功回應給生產者,且在被其他 fo llo wer 副本拉取之前 leader 副本崩潰,那么此時訊息還是會丟失,因為新選舉的 leader 副本中并沒有這條對應的訊息 acks 設定為1,是訊息可靠性和吞吐量之間的折中方案
(2)acks = 0
(3)acks = -1或acks =all
生產者在消 息發送之后,需要等待 ISR 中的所有副本都成功寫入訊息之后才能夠收到來自服務端的成功回應,在其他配置環境相同的情況下, acks 設定為 (all )可以達到最強的可靠性,但這并不意味著訊息就一定可靠,因為 JSR 中可能只有 leader 副本,這樣就退化成了 acks=1 的情況,要獲得更高的訊息 可靠性需要配合 min.insync.replicas 引數的聯動
注意 acks 引數配置的值是一個字串型別,而不是整數型別
2.max.request.size
該引數用于控制生產者發送的請求大小,它可以指發送的單個訊息的最大值,kafka默認的發送一條訊息的大小是1M
3.retries 和 retry.backo.ms
發生錯誤后,訊息重發的次數,如果達到設定值,生產者就會放棄重試并回傳錯誤,默認是0,即在發生例外的時候不進行任何重試動作,訊息在從生產者發出到成功寫入服務器之前可能發生一些臨時性的例外, 比如網路抖動、 le der 副本的選舉等,這種例外往往是可以自行恢復的,生產者可以通過配置 retries 大于0值,以此通過內部重試來恢復而不是一昧地將例外拋給生產者的應用程式,但是不是所有例外都能處理,比如超過訊息最大值的例外
retry.backoff.ms用來設定兩次重試之間的間隔
4.compression.type
5.linge .ms
這個引數用來指定生產者發送 ProducerBatch 之前等待更多訊息( ProducerRecord )加入 Producer Batch 時間,默認值為 ,生產者客戶端會在 ProducerBatch 填滿或等待時間超過 linger.ms 值時發迭出去,增大這個引數的值會增加訊息的延遲,但是同時能提升一定的吞吐量,
6. receive.buffer.bytes & send.buffer.byte
7.timeout.ms, request.timeout.ms & metadata.fetch.timeout.ms
timeout.ms 指定了 borker 等待同步副本回傳訊息的確認時間;
request.timeout.ms 指定了生產者在發送資料時等待服務器回傳回應的時間;
metadata.fetch.timeout.ms 指定了生產者在獲取元資料(比如磁區首領是誰)時等待服務器回傳回應的時間,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/275130.html
標籤:其他