我的Hadoop筆記
一、背景
起源于google的3篇論文中的GFS和MapReduce,作者是Doug cutting,截止到2021-04-07為止,最新的正式版本為3.2.2,本筆記還是基于Hadoop2.x的內容
二、Hadoop是什么?
狹義的Hadoop包括HDFS(Hadoop Distributed File System)和MapReduce,本篇筆記只包括狹義的Hadoop
HDFS是一個分布式檔案存盤系統,MapReduce是計算框架
廣義的Hadoop可以理解為Hadoop生態(hdfs,mapreduce,hive,hbase,yarn,oozie,sqoop,flume,phoenix,kafka,spark)
三、HDFS
是一個分布式檔案系統,從用戶角度看就是個存檔案的地方,可以創建目錄,創建檔案,上傳檔案,下載檔案等等,
支持Java API、RestFul API操作HDFS,
1 HDFS存盤模型
- 檔案被切割成一個個block,每個block大小默認128兆
- 單個block大小一致,檔案和檔案的block大小可以不一致
- block分散存盤在集群的多個節點
- block可以設定副本個數,默認值是3,一般副本數不建議超過節點數
- 已存盤的block副本數可以重新設定數量,大小不可變
- 支持一次寫入多次讀取,同一時刻只能有一個寫入者
- 只支持append操作,不支持修改,修改可以通過洗掉檔案重寫實作
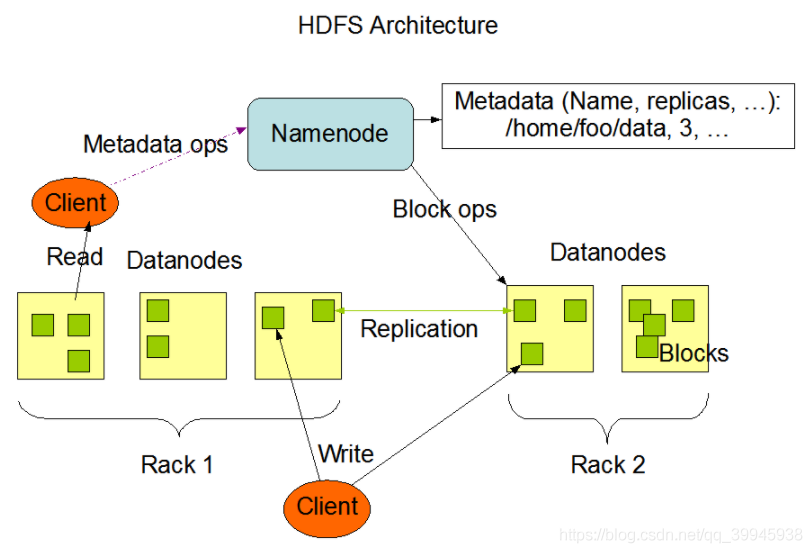
2 HDFS架構
NameNode 管理結點
職責:
存盤元資料,資料存盤在記憶體中
元資料包括三類:
1.檔案與目錄的屬性,包括檔案名、創建時間、修改時間等
2.資料所在DataNode、偏移量,block副本位置(由DataNode上報)
3.記錄所有DataNode的資訊,管理DataNode
接收客戶端的讀寫服務
DataNode 資料結點
存盤資料
職責:
1.存盤資料和block元資料
2.向NameNode匯報block資訊
3.向NameNode保持心跳
如果NameNode10分鐘未收到DataNode心跳認為該DataNode已經無效
將會拷貝無效DataNode上的block到其他DataNode
JournalNode 存盤資料變動記錄
職責:
保存editlog(資料變化記錄)
Client 客戶端
職責:
切分資料檔案
從NameNode讀取檔案元資料
從DataNode讀取資料
FailoverController
職責:
檢測NameNode的健康狀況
選舉Active NameNode
架構示意圖:
3 HDFS 元資料持久化
元資料分為兩個檔案,其一是fsimage,是記憶體中元資料的一個快照;其二是editslog,記錄了快照之后的所有編輯操作,
集群重啟后,通過合并fsimage和editslog來恢復元資料,
4 HDFS 啟動程序(HA 模式)
- 啟動2個NameNode,一個為Active(主),一個是Standby(備)
- Active NameNode讀取元資料fsimage,加載到記憶體中
- Active NameNode讀取editslog,合并到fsimage中,將fsimage傳輸給Standby NameNode,在磁盤上生成一個新的fsimage檔案,同時創建新的editslog,Active NameNode將其不斷發送到JournalNode
- Standby NameNode不間斷的從JournalNode讀取editslog,合并到fsimage
- DataNode啟動,向NameNode報告block資訊
- 進入SafeMode(安全模式),此時只回應讀取操作
- 退出安全模式
5 HDFS 安全模式
- Hadoop集群啟動后會進入安全模式,此時HDFS只回應讀請求,不會回應洗掉修改請求,
- Active NameNode獲得DataNode上報的block資訊,檢查block副本數是否滿足條件(NameNode統計元資料和DataNode發送過來的塊報告中的統計資訊匹配度達到99.999%),滿足條件則會退出安全模式,
- 如果塊有丟失,會自動復制丟失副本的block到DataNode上,直至達到配置的副本數為止,復制后,過一段時間會退出安全模式,
# 退出安全模式
hdfs dfsadmin -safemode leave;
# 強制退出安全模式,上面命令不生效可使用下面的命令
hdfs dfsadmin -safemode forceExit;
6 HA 切換程序
1 當Active NameNode掛掉
- Active NameNode掛了
- Zookeeper洗掉Active NameNode 對應的FailoverController創建的結點,Active NameNode 對應的FailoverController之后將Active NameNode的狀態修改為Standby狀態
- Standby NameNode 對應的FailoverController發現洗掉了,則立即到Zookeeper創建節點,之后將Standby NameNode的狀態調整為Active
2 當FailoverController掛掉
- Active NameNode對應的FailoverController掛了
- Zookeeper中Active NameNode對應的FailoverController創建的臨時結點被洗掉
- Standby NameNode對應的FailoverController在Zookeeper
- Active FailoverController控制當前的Active NameNode狀態變為Standby
- Active FailoverController控制之前為Standby的NameNode的狀態變為Active
7 FS Shell
常用的一些shell命令,命令和linux shell命令很相似
# 創建目錄
hdfs dfs -mkdir /test_mkdir
# 查看制定目錄內容,類似shell命令里的ls
hdfs dfs -ls /
# 洗掉目錄
hdfs dfs -rm -R /test_mkdir
命令的官方參考檔案:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html
四、MapReduce
MapReduce思想認為所有的資料計算都可以通過map和reduce的組合實作,
1 執行流程
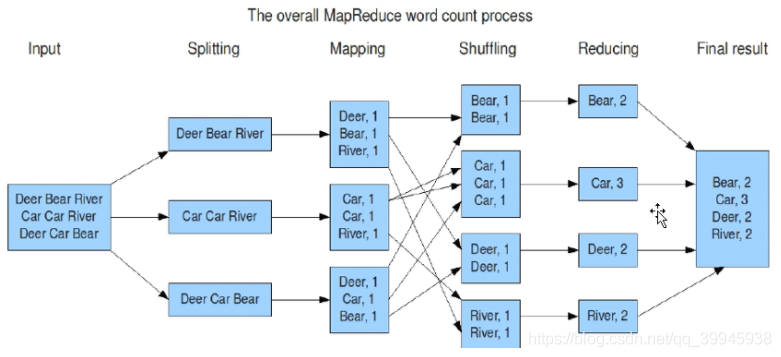
一段資料的處理程序:
- 一行一行讀取資料
- 按分隔符切割一行資料
- map進行轉換映射
- 拉取相同的key到一個reduce
- reduce將拿到的資料聚合
- 將所有reduce的輸出匯聚到一起即是最終的結果
2 Map
- map接收到前面輸入的一條資料
- 按一條記錄為單位進行拆分,形成一條Key-Value資料
- 計算Key-Value資料的Partition(哈希取余),把KVP存進buffer里,排序
- 寫成小檔案
- 合并成一個大檔案(大檔案中磁區相同的磁區的資料放到一起,相同key的放到一起)
- map完全執行完畢
map完全執行完畢才會執行reduce
3 Reduce
- 拉取map執行完后的結果,進行歸并排序,生成一個大檔案
- 從其他map中拉取key相同的資料,再歸并排序,但不生成大檔案
- 一條條的計算key相同的資料
一組資料呼叫一次reduce,reduce迭代計算的單位是一條,所以需要的記憶體很少
五、Yarn
1 資源分配程序
yarn資源分配程序
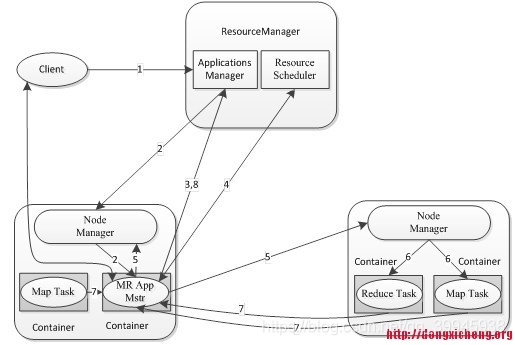
- 用戶向YARN提交應用程式,包括ApplicationMaster程式,啟動ApplicationMaster的命令、用戶程式等,
- Resource Manager通知不忙的NodeManager,為該應用程式分配一個Container,并在Container中啟動一個負責管理此次運行的ApplicationMaster
- ApplicationMaster啟動后,向Resource Manager注冊,方便用戶通過Resource Manger查看程式的運行狀態,之后Application Master為此次任務向Resource Manger申請資源,同時監控程式運行狀態,直到程式運行結束,如果沒有足夠資源,會重復第4步,直到申請到足夠資源
- Application Master 采用輪巡方式通過RPC協議向Resource Manger申請和領取資源
- 一旦Application Master申請到足夠的記憶體和core,就會要求對應的NodeManager啟動任務
- NodeManger設定運行環境(包括環境變數、jar包、二進制程式等),將任務啟動命令寫到腳本中,通過運行腳本啟動任務
- 各個任務通過RPC協議向Application Master匯報狀態和進度,既可以讓Application Master掌握任務運行狀態,又可以在任務失敗時進行重試,
8.程式運行完畢后,Application Master向Resource Manager注銷,然后關閉自己
2 Yarn Commond
常用命令
# 查看所有已快取的包
yarn cache list
# 查看快取位置
yarn cache dir
# 查看應用串列
yarn application -list
# 查看指定應用程式id或應用名的程式的狀態
yarn application -status <ApplicationId or ApplicationName>
# 殺死指定Application ID的程式
yarn application -kill <Application ID>
# 查看指定Application ID的程式的日志
yarn logs -applicationId <application ID> [options]
Yarn命令 官方參考手冊:
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YarnCommands.html
參考鏈接
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://blog.csdn.net/zpf_940810653842/article/details/106569759
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/275446.html
標籤:其他
上一篇:[SRv6]《SRv6網路編程》SRv6網路在電信云中的應用
下一篇:Kubernetes入門須知