ElasticSearch總結
- ES介紹
- ES核心組成
- ES的集群
ES介紹
1)什么是ES?
a. ES是基于Apache Lucene的開源搜索引擎,Lucene是搜索引擎庫,由Shay Banon最早創立,(這家伙為了他老婆才設計的)
b. ES使用java開發并使用Lucene作為核心來實作索引和搜索功能,它是通 過RESTful API來隱藏Lucene的復雜性,從而讓全文搜索變得簡單,
2)為什么要用ES,它的優點是什么?
why:在搜索程序中,MySQL主要用于主鍵搜索查詢,而隨著業務量的需 求,我們同時需要大量的全文搜索,全文搜索需要匹配大量的文本,用 MySQL的like模糊查詢將導致性能下滑,而ES全文搜索引擎就能保證大本 文的匹配查詢性能,
優點:
- 分布式功能,資料高可用,集群高可用
- 支持PB級別的資料
- 基于Lucene,提供簡單的API
- 支持多語言
- 完成搜索的功能和分析功能
3)ES原理
- ES主要運用了倒排索引,根據文章中的關鍵字建立搜索
- ES在Lucene的基礎上進行封裝,實作了分布式搜索引擎
- ES中的索引,型別,檔案概念類似于MySQL中的資料庫,表,行
- ES也是Master-slave構架,實作了資料的分片和備份
ES核心組成
1)ES基本組件
ES主要是由,索引,型別,檔案和欄位組成的,類似于資料庫
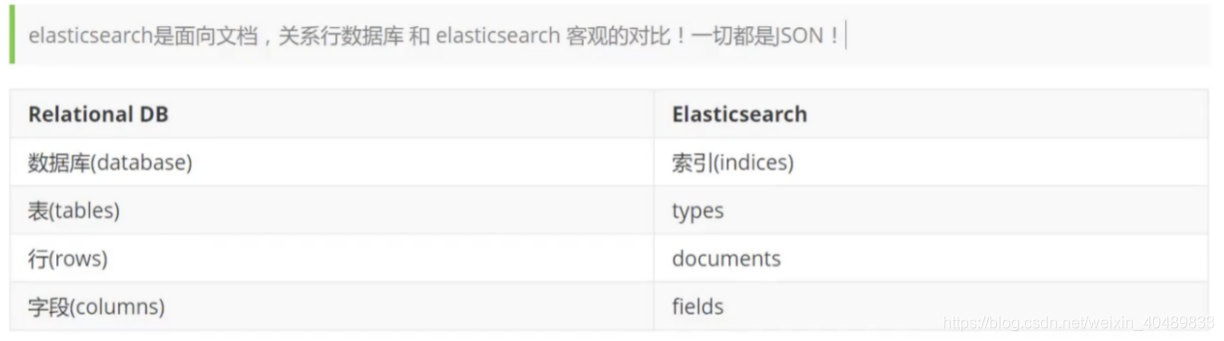
索引:ES中可以包含多個索引,每個索引可以包含多個型別,每一個型別包多個檔案,每個檔案包含多個欄位
型別:用來定義資料機構,相當于表結構的描述,描述每個欄位的型別. 主要用于mapping中,mapping在es中相當于sql中的創建schema
檔案:ES里面最小的資料單元,好比一條資料,可以對檔案進行索引,搜索,排序,過濾,ES使用JSON作為檔案序列化格式
欄位:資料庫中列的概念,一個document可以有一個或多個field
例子:Get /megacorp/employee/1

2)倒排索引
– ES使用的是倒排索引的結構,采用Lucene倒排索引作為底層,一個索引由檔案中所有不重復的串列構成,對于每一個詞,都有一個包含它的檔案串列,
– 為了創建倒排索引,首先將每個檔案拆分成獨立的詞,然后創建一個包含所有不重復詞條的排序串列,然后列出每個出現在哪個檔案,
Eg.
String1: “study every day, good good up to forever ”
String2: “To forever, study every day, good good up”
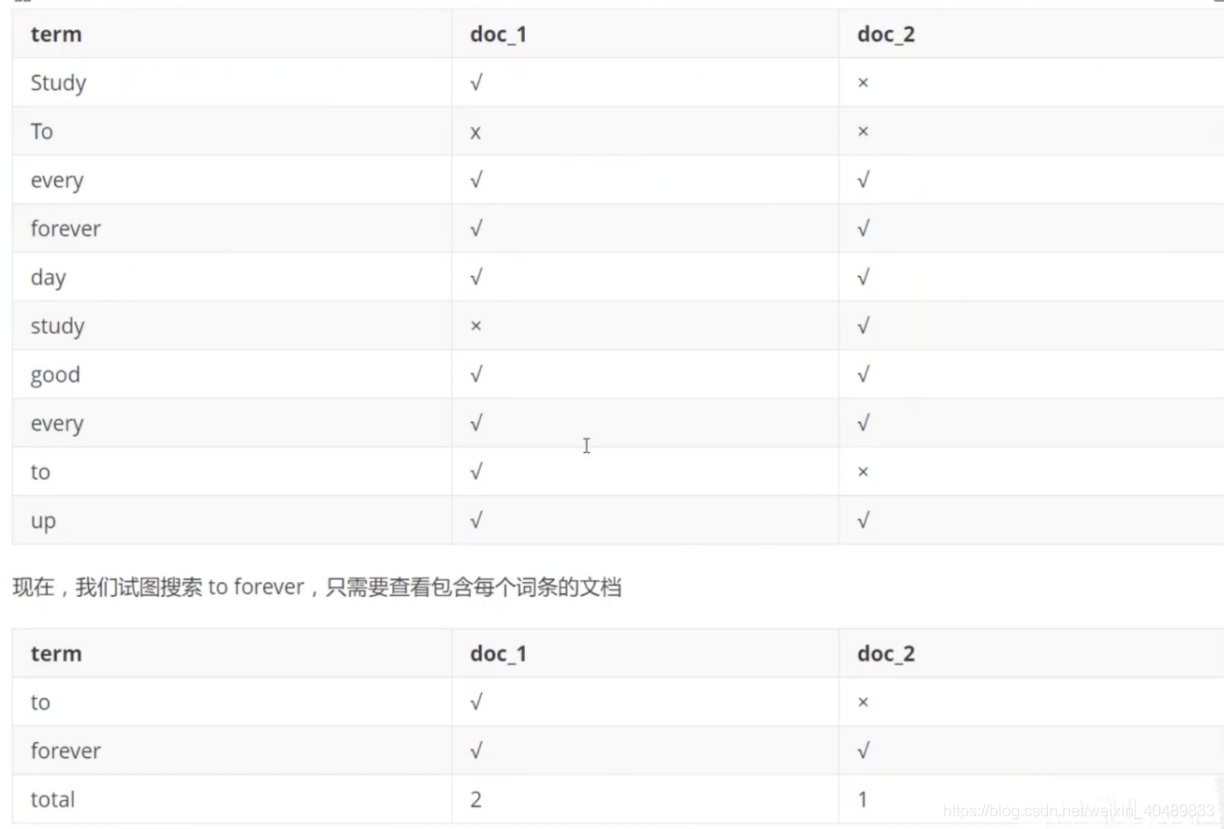
我們能看見doc1和doc2都出現了以上的關鍵詞,所以ES會把doc1和doc2找出來,但是doc1的匹配率更高,在顯示時會先把doc1展示在前面,
3)分析器(analysis)
分析器是三個順序執行的組件的組合(字符過濾器,分詞器,表征過濾器)
字符過濾器:讓字符在被分詞前變得更整潔,比如說html_strip字符過濾器,可以用來洗掉所有HTML標簽,并將HTML物體類轉換成相應的Unicode字符,eg. á 轉換成A
分詞器:一個分析器必須包含一個分詞器,分詞器將字串分割成單獨的詞(terms)或者表征(token). 比如說standard分詞器會將字串分割成單獨的字詞,洗掉大部分標點符號;比如說whitespace分詞器,通過空格來分割文本
表征過濾器:分詞結果的表征流會根據各自情況,傳遞給特定的表征過濾器,
表征過濾器可能修改,添加,或者洗掉表征,比如說lowercase表征過濾器,會將所有表征轉換成小寫;比如說stop表征過濾器,會洗掉所有可能會造成搜索歧義的停用詞,比如a,the,and,is
自定義分析器:

在配置好stadard分詞器,lowercase表征過濾器,stop表征過濾器后,

此外,除非我們告訴ES在哪里使用,否則分析器不會作用,所以我們要通過映射將它應用在一個string型別的欄位上,

由于分析器不是全域的,在創建索引后,用analyze API來測驗新的分析器,
4)排序(analysis)
默認情況下,結果會按照相關性進行排序,在ES的查詢結果中,相關性分值會用_score欄位來給出一個浮點的數值,結果集以_score進行倒序排列,
所謂相關性,即
- 檢索詞頻率 -> 詞出現的次數
- 反向檔案頻率 -> 檢索詞在當前檔案出現的次數與索引中其它檔案的出現總數的比率
- 欄位長度準冊 -> 內容越長,數值越小
ES的集群
1)集群構架
ES是分布式的集群,每一個節點其實就是Lucene,當用戶搜索的時候,會隨機挑選一臺,然后這太機器自己知道資料在哪,
在ES中,默認clustername的值是ElasticSearch,由于一臺服務器無法儲存大量資料,ES把一個index里面的資料,分為多個shard,分布式地儲存在各個服務器上面,
總而言之,一個集群至少有一個節點,每一個節點就是ES行程,節點可以有多個索引默認的,如果創建索引,那么索引將會有五個分片(primary shard, 主分片)構成的,每一個分片會有一個副本(replica shard,復制分片)
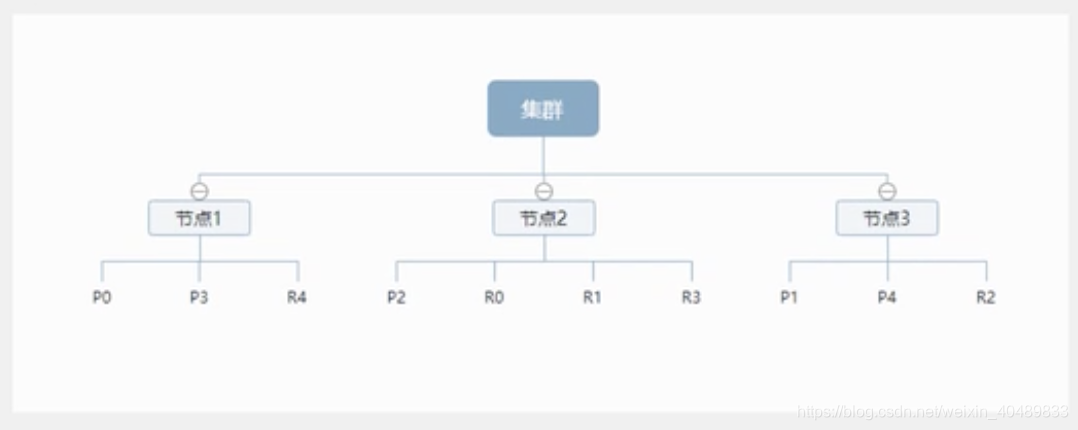
上圖是一個3個節點的集群,可以看到主分片和對應的復制分片都不在同一個節點內,這樣有利于某個節點掛掉了,資料也不會丟失,(類似hdfs思想)
2)ES的分布式原理
– 將檔案磁區到不同的容器或者分片(shards)中,它們可以存在于一個或者多個節點中
– 將分片均勻的分配到各個節點,對索引和搜索做負載均衡
– 沉余每一個分片,防止硬體故障造成的資料丟失
– 將集群任意一個節點上的請求路由到相應資料所在的節點
– 無論是增加節點,還是移除節點,分片都可以做到無縫的擴展和遷移
3)ES設計構架
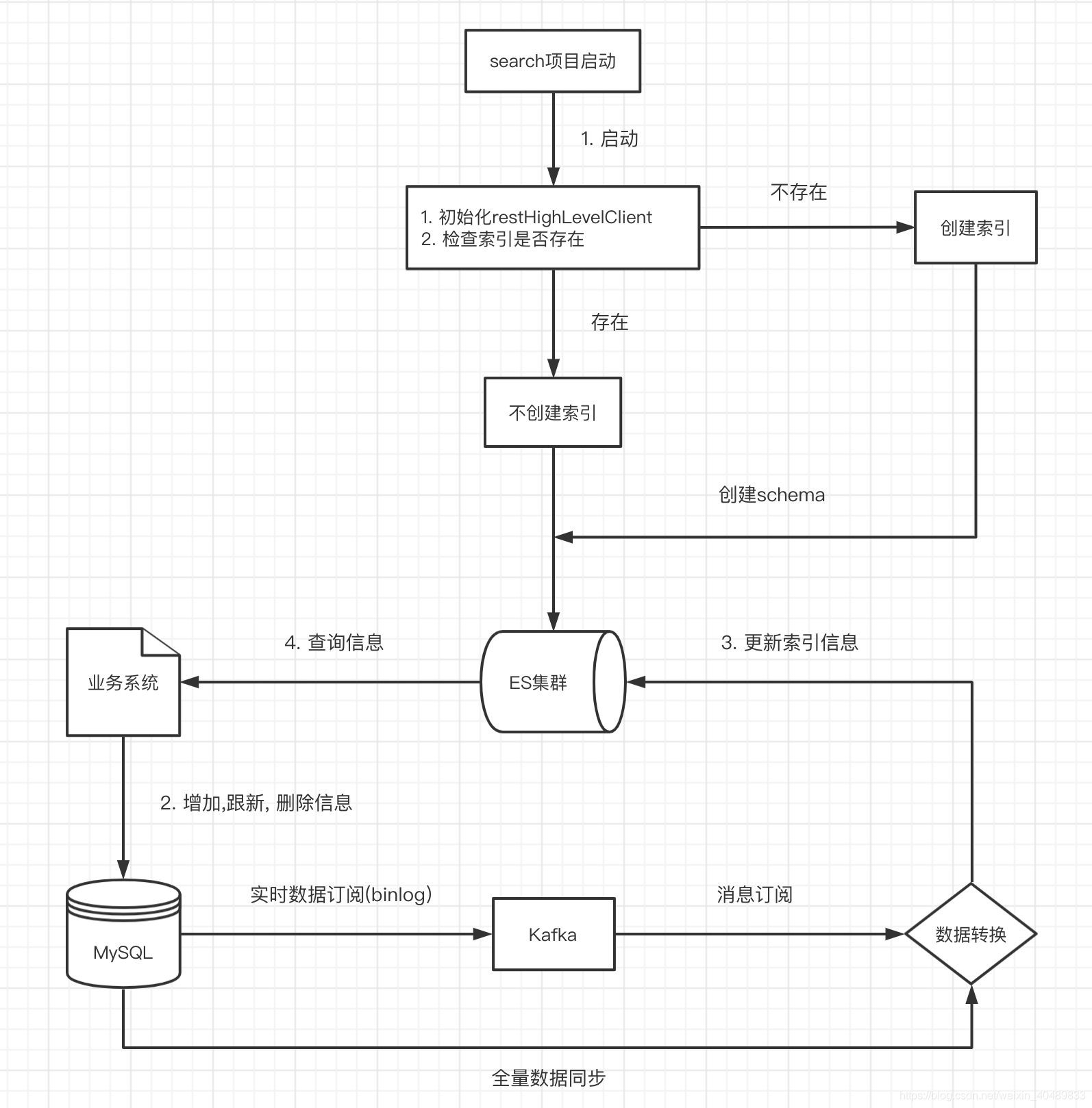
- 啟動ES的服務,初始化restHighLevelClient并查看是否已經建有索引,如果沒有,就通過自定義的mapping創建索引,
- 業務系統通過增加,更新或者洗掉資訊,把資訊儲存到資料庫中
- 將流式資料和全量資料通過資料轉換儲存到ES集群中
- 通過呼叫API呼叫查詢資訊,并回傳給業務系統
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/275767.html
標籤:其他