指標詳解
| . | . | . | . |
|---|---|---|---|
| 1.字符指標 | 2.指標陣列 | 3.陣列指標 | 4.陣列與指標引數 |
| 5.函式指標 | 6.函式指標陣列 | 7.函式指標陣列指標 | 8.回呼函式 |
| 9.模擬qsort |
在這篇文章之前我還寫了一篇指標基礎
1.字符指標
我們知道 字符指標指向字符地址,并且非常熟悉他的用法,比如下面:
#include <stdio.h> int main() { char arr[] = "abcdef"; char* p = arr; printf("%s\n", arr); printf("%s\n", p); return 0; }輸出結果是:
abcdef
abcdef
那如果我們這樣寫呢???
#include <stdio.h> int main() { char* p = "abcdef"; // 這是一個常量字串 printf("%s\n", p); printf("%c\n", *p); return 0; }運行結果是:
abcdef
a這個代碼特別讓人容易誤會是把字串 abcdef放到字符指標p里面,實際是把該字串的首字符地址放到了指標p里面,
并且強調 !!! ,這樣寫就代表著 abcdef是一個常量字串,不可修改.
比如我們再寫一個陳述句 *p = ‘w’;
就會發生段錯誤,因為不可修改
因此,如果我們進行第二種寫法,最好規范書寫,就是加上const,以便我們理解
#include <stdio.h> int main() { const char* p = "abcdef"; printf("%s\n", p); printf("%c\n", *p); return 0; }
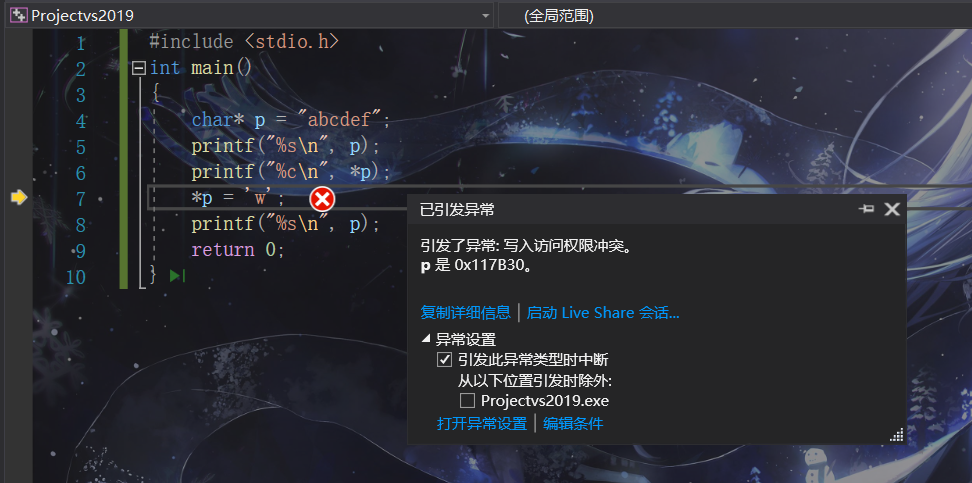
下面有兩道面試題,請寫出答案:

答案:
第一道 哈哈
第二道 呵呵
決議:
第一道: 因為arr1與arr2是兩個陣列,他們所占據的空間不同.而陣列名是陣列首元素地址,因此arr1與arr2的地址又不同,
所以 arr1 != arr2,所以回列印 哈哈
第二道: 因為這種寫法代表著就是abcdef是常量字串,而p1與p2的值都是abcdef,所以計算機為了節約空間,就不再開辟多的空間,只開辟一塊
所以 p1 == p2,列印 呵呵
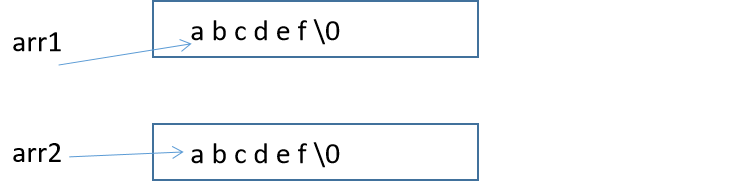
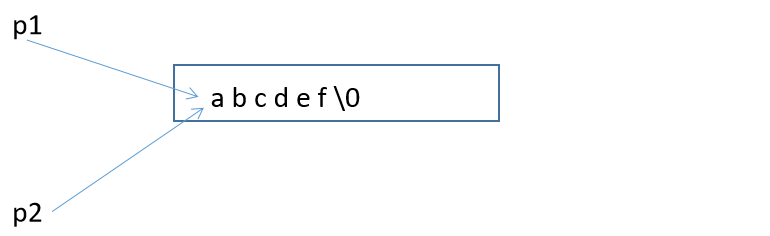
同理,我們為了規范書寫,還是在char*前面加上const
2.指標陣列
指標陣列:重點是后面,陣列,所以指標陣列是陣列,即陣列里面的元素型別是指標.
我們知道 一個陣列的構成包括是三個部分 : 元素型別 陣列符號[] 陣列名(可以省略)
比如 **int arr [3] 意思是一個陣列,他的名字是arr,該陣列含有3個元素,每個陣列型別是int **
char arr[4] 意思是一個陣列,他的名字是arr,該陣列含有4個元素,每個陣列型別是char
那么,指標陣列該怎么寫呢??我們一步一步的來.
-
第一步,陣列符號 []
-
第二步,寫上陣列名 arr
-
第三步,寫上陣列型別 (指標) int* char*…等
先在我們要求寫一個陣列名是pp,含有6個元素的整型指標陣列.
int* pp[6];
運用:
低級運用
#include <stdio.h> int main() { int a = 10; int b = 20; int c = 30; int* all[3] = {&a,&b,&c}; for(int i = 0;i<3;i++) { printf("%d\n",*all[i]); } return 0; }運算結果:
10
20
30
高級運用
#include <stdio.h> int main() { int arr1[] = {1,2,3}; int arr2[] = {4,5,6}; int arr3[] = {7,8,9}; int* all[3] = {arr1,arr2,arr3}; int i = 0; for(i = 0;i<3;i++) { int j = 0; for(j = 0;j<3;j++) { printf("%d ", *(all[i]+j));//利用了指標加減整數 //還可以這樣寫printf("%d ", all[i][j]); } printf("\n"); } return 0; }運行結果:
1 2 3
4 5 6
7 8 9注釋里面這樣寫
all[i][j]的原因是all[i]等于陣列名,陣列名再跟上陣列符號[],就等于新陣列
3.陣列指標
我們在2里面說了指標陣列,現在我們討論陣列指標,注意,重點是指標,所以陣列指標是 指標,指向的是陣列,存放的是陣列地址
我們知道指標的寫法是 指標型別加上變數名.
比如 char p,稱為字符指標 int p稱為整型指標**
那么陣列指標的型別怎么寫呢???,假設有個整型陣列叫arr
是這樣嗎? int *p = &arr 錯,這是整型指標,引陣列符號
是這樣嗎? int[] *p = &arr 錯,int[]這種形式代表著int是一個陣列名,而我們不能用資料型別做變數名
是這樣嗎? int *p[] = &arr 錯,[]的結合性比
*高,即p是陣列,不是指標,即*p[]代表著在解參考一個陣列p[]綜合上述,我們把(*p)括起來,這樣就代表p是指標了.
所以,整型陣列指標這樣寫
int (*p)[] = &arr,意思是,指標p指向陣列arr,arr的型別是int現在我們進行剖析 p是指標,那么剩下的就是 型別 即 int(* )[]
有人會問,為什么不這樣寫? int(* )[] p,這是c的規定,*與p必須在一起
出題,這里有一個陣列
char arr[10] = "abcdefabc";請寫出陣列指標存放arr第一步,寫出指標 (*p)
第二步,寫出指向的型別 [10]
第三部,寫出指向的陣列的型別 char
所以就是 char (*p) [10] = &arr;
出題,這里有個整型指標陣列 int* arr[3] = {&a,&b,&c};請寫出陣列指標存放arr
按照上面的步驟就是下面答案
int* (*p) [10] = &arr; 意思是,指標p,指向陣列arr,arr的元素型別是
int*
低級運用:
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9};
int (*pa)[10] = &arr; //一定是存放陣列地址哦,而不是arr首元素地址哦
for(int i = 0;i<10;i++)
{
printf("%d ",(*pa)[i]); //把(*pa)括起來是因為[]的結合性比*高,保證pa是指標
//因為 pa等于 &arr
//所以 *pa等于arr
// *pa+1 等于 arr+1
//所以,我們還可以這樣寫 printf("%d ",*(*pa + 1)); 利用指標加減整數訪問
}
return 0;
}
結果 1 2 3 4 5 6 7 8 9 10
但是就是一個一維陣列而已,我么完全不用這樣寫,太累了,所以,陣列指標我么是用于二維陣列
高級運用:
#include <stdio.h>
void test(int(*p)[5],int a,int b)//因為arr是第一行的陣列地址,就相當于是一個一維陣列,所以用陣列指標接收
{
int i = 0,j = 0;
for (i = 0;i<a;i++)
{
for(j = 0;j<b;j++)
{
printf("%d ",*(*(p+i)+j));//因為p是第一行的陣列地址,即整個地址,所以*(p)就是 arr,這里感覺矛盾的請看最下面注釋
//所以*(p+i)就等于 &arr+i,即地址跳到下一行,*(*(p+i) +j)相當于解參考每一行中的每一列的某個值
//不懂的其實這樣寫更好理解 (*(p + i))[j] 因為*(p+i)是某一行的陣列名
}
printf("\n");
}
}
int main()
{
int arr[5][5] = {
{1,2,3,4,5},
{2,3,4,5,6},
{3,4,5,6,7},
{4,5,6,7,8},
{5,6,7,8,9}
};
test(arr,5,5);//二維陣列的陣列名是首元素地址,但是二維陣列的首元素是整個第一行,所以二維arr相當于就是一維陣列&arr
return 0;
}
結果:
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
4 5 6 7 8
5 6 7 8 9
文章目錄前三個例子的總結:
①
int arr[5];這是一個陣列,陣列名是arr,有五個元素,每個元素型別是int,叫做 整型陣列②
int *arr[10];這是一個陣列([]的結合性比*高),陣列名是arr,有10個元素,每個元素的型別是int*,所以叫做 指標陣列③
int (*arr2)[10];這是一個指標,指向一個陣列名是arr2的陣列,該陣列有10個元素,每個元素型別是int 所以叫做 陣列指標④
int(*arr3[10])[5]這是一個陣列([]的結合性比*高),陣列名叫做arr3,有10個元素,每個元素型別是 陣列指標,元素型別指向的是一個整形陣列
④有點不好理解,我畫圖分層寫出來
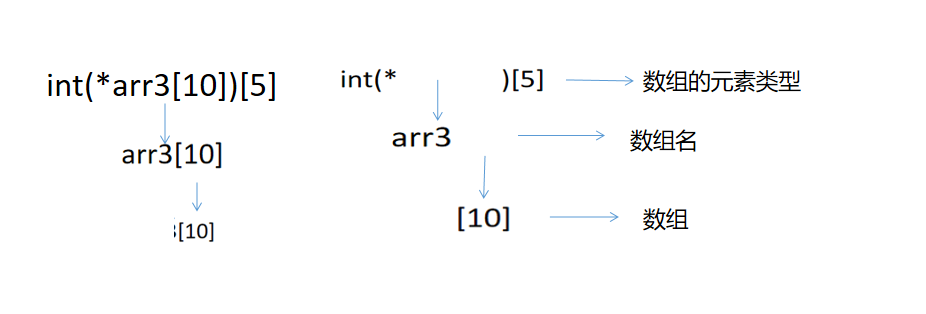
我們能看見arr3由 三部分組成,陣列名,陣列標志[],元素型別
我在畫細節圖給大家理解
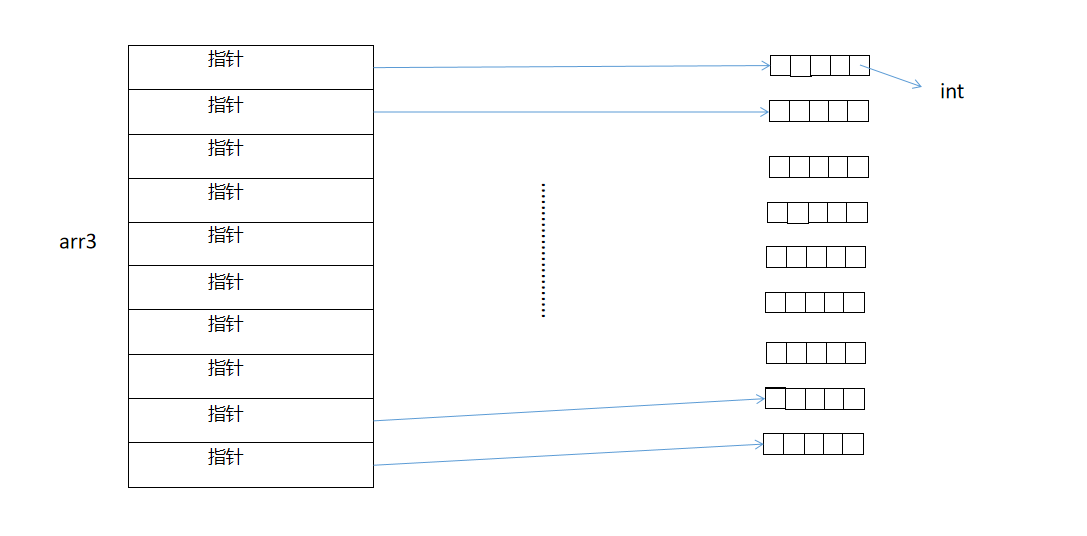
現在我出一個題,請寫出用什么存盤
int arr1[3] = { 1, 2, 3 };
int arr2[3] = { 4, 5, 6 };
int arr3[3] = { 7, 8, 9 };
?????????? = { &arr1, &arr2, &arr3 };
答案: int(*parr[3])[3]
決議: &arr是 陣列地址,陣列地址用指 陣列指標指向,一個指標指向一個陣列地址
有三個所以需要三個陣列指標
所以用陣列存盤
就是
int(*parr[3])[3]而這也呼吁了上面的圖
4.陣列與指標傳參
一維陣列傳參
#include <stdio.h>
void test(int arr[]);// 1
void test(int arr[10]);//2
void test(int* arr);//3
void test2(int* arr[20]);//4
void test2(int** arr);//5
int main()
{
int arr1[10] = {0}; //整形陣列
int* arr2[20] = {0}; //陣列指標
test(arr1);
test2(arr2);
return 0;
}
/*
以上傳參均正確.
arr1是整形陣列,他的每一個元素是int
所以1和2種接參法正確,表示接受的是int陣列
因為arr1是一個地址,所以可以用指標接受,3也是正確的
arr2是指標陣列,他的每一個元素都是指標int*
所以用4接受方法,表示接受一個陣列指標, 正確
因為arr2是首元素地址,而首元素就是一個指標,所以要用二級指標接受,也是正確
*/
二維陣列傳參
#include <stdio.h>
void test(int arr[][]);//1
void test(int arr[3][5]);//2
void test(int* arr)//3
void test(int(*p)[5]);//4
int main()
{
int arr[3][5] = {0};
test(arr);
return 0;
}
/*
解釋:
1種 錯誤; 二維陣列[][]里面的數字不能省略
2種 正確; 傳的arr,arr的型別是int, 所以2的int arr[3][5]正確,表示接受二維整型陣列
3種 錯誤; 二維陣列的陣列名是首元素地址,但是二維陣列的首元素是 第一行 相當于一維陣列&arr
所以,如果想要用指標接參,我們應該怎么弄?? 答案是 陣列指標;
陣列指標:指向----->陣列地址 陣列地址: 一維:&arr 二維:arr
*/
針對二維陣列傳參中那個陣列指標案例,我寫了一個代碼加以理解,二維陣列的陣列名和一維陣列的陣列名區別
#include <stdio.h>
void test(int(*p)[3]) /*一維陣列名接收*/
{
for (int j = 0; j < 3; j++)
{
printf("%d ", (*p)[j]);
}
printf("\n");
}
void test1(int(*p)[5])/*二維陣列名接收*/
{
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 5; j++)
{
printf("%d ", (*(p + i))[j]);
}
printf("\n");
}
}
int main()
{
int arr1[3] = { 1, 2, 3 };
//一個陣列
int arr[3][5] = { {1,2,3,4,5} ,{2,3,4,5,6}, {3,4,5,6,7} };
test(&arr1);//傳的陣列地址;
test1(arr);//傳的是一維的陣列地址(二維陣列本質上是多個一維陣列連接在一起儲存)
return 0;
}
/*運行結果:
1 2 3
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7
*/
解釋:
一維陣列: &arr這個代表陣列地址,不是首元素地址,而陣列地址一般用陣列指標接收,因為陣列指標指向陣列
p是指標,p等于&arr, 所以
*p就等于arr, arr[] 就等于(*p)[]二維陣列:arr可以理解為就等于&arr,只是沒有&. 就相當于 p = &arr,只是寫的時候沒有&
所以
*p就是二維陣列中真正的首元素地址,即第一個元素地址.在上面程式中i是行,所以*(p+i)就是下一行中的第一個元素地址.所以
*(p+i) + j就是第i行j列的某一個元素地址,所以*(*(p+i) + j)就是i行j列某一個具體元素 也可以寫成(*(p+i))[j]
一級指標傳參與二級指標傳參
看看下面兩邊的代碼
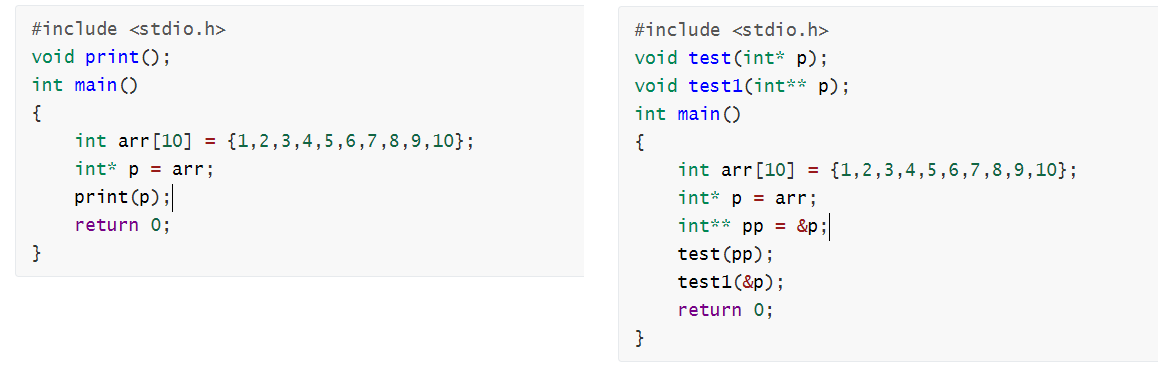
可以很明顯的看到,一級指標,我傳的是一級指標,我函式就用一級指標接收
二級指標,我傳的是二級指標,我就用二級指標接收
總結:看完上面的知識,我們思考一個問題,那就是:
如果一個函式的引數是 一級指標,那么他可以接收什么?
如果一個函式的引數是 二級指標,那么他可以接收什么?
答案1:
如果一個函式的引數是一級指標,那么他可以接收 普通陣列,變數地址,和一級指標
如果一個函式的引數是二級指標,那么他可以接收 二級指標,一級指標地址,和 一級指標陣列 (int arr[10])*
5.函式指標
函式指標:重點是指標,指向一個函式;
那么函式指標我們該怎么寫呢??? 我們回顧一下在最開始寫陣列指標的時候是怎么寫的.
先確定是一個指標(用括號括起來) 然后指向的東西是…(陣列符號[]),再給陣列寫上元素型別
所以函式指標同樣. 假設有一個函式是int add(int x, int y),那函式指標就是
int (*p)(int ,int )
例子:
#include <stdio.h>
int add(int x,int y)
{
return x+y;
}
int main()
{
printf("%p\n", &add);
int a,b;
a = 4;b = 3;
int (*p)(int ,int);
printf("%d", (*p)(a,b));
return 0;
}
/*答案:
00F012BC
7
*/
下面有三個有趣的題:
void *p ();與
void (*p) ();這兩個運算式的意思一樣嗎? 不一樣. 上面是函式的宣告,下面是函式指標
(*(void(*)())0)();請問這個是啥???答案: 這是一個函式呼叫,并且該函式的地址在
0X00000000處.決議: 首先看0左邊括號里面的東西------
void(*)(),這是什么?? ----函式指標型別 在他的外面又添加了一層(),然后在緊挨著0左邊說明
(void(*)())這是一個強制型別轉換,即把0轉換為某一個函式的地址,地址在0處.*(void(*)())這是解參考地址為0的該函式最后
(*(void(*)())) ()這就是再呼叫該函式. 之所以在解參考外面加一個(),是因為()的結合性比*高
void (*signal(int,void(*)(int)))(int);請問這個是啥??答案: 這是一個回傳型別為函式指標的函式
決議: 首先我們可以把他們拆開成
signal(int,void(*)(int))和void (*)(int)清晰的看到 前者是一個函式他的引數是一個整型和函式指標 后者是一個型別,函式指標型別. 所以這是一個回傳型別為函式指標的函式.
第三個例子,我為了大家更好理解我這樣寫.
typedef void (*)(int) a; a signal(int,a); 這樣好理解了嗎?? 好理解!!!! 但是這是有錯誤的寫法哦~~~~~~~~~~,我只是為了大家好理解才這樣寫的 應該是這樣寫: typedef void (* a)(int); a signal(int,a); 即名字必須挨著*!!!!!!這樣是不是解非常好理解了呢??? 那么有人會問,既然
a signal(int,a);可以這樣寫 那么原來為什么不這樣寫??? 看下面
void (*)(int)signal(int,void(*)(int))這個其實就和上面一樣,即名字必須挨著*,所以要揉在一起.
6.函式指標陣列
顧名思義:重點在最后面!!!**這是一個陣列,**只是他的存盤物件是 函式指標
為什么會有他呢??我們看看下面的例子:
#include <stdio.h>
int add(int x,int y)
{
return x+y;
}
int sub (int x,int y)
{
return x-y;
}
int mul(int x,int y)
{
return x*y;
}
int div(int x,int y)
{
return x/y;
}
int main()
{
int a,b;
a = 4;b = 3;
/*現在我們需要呼叫上面的所有函式,如果一個一個的寫就太麻煩了.因此現在就需要一個陣列存盤所有函式*/
return 0;
}
函式指標陣列的寫法::
我們知道一個陣列由三個型別組成,分別是: 存盤型別 陣列名 陣列符號[] 比如
int num[]所以按照上面的定義我么可以知道這樣寫
int(*)(int,int) num[4]是不是這樣??? 對!!! 了90% 不要忘記我上面所說的*必須和名字結合所以應該是這樣
int (*num[4])(int ,int)
問題: 現在有一個函式 char* my_strcpy(char* dest, const char* src);
第一,請寫一個函式指標指向 my_strcpy 第二,請寫一個函式指標陣列,可以存放四個函式該地址
第一:
char* (*p)(char*, const char*)第二:
char* (*num[4])(char*, const char*)
下面,我們來撰寫一個小程式 (計算器),需要用到上面的東西
該計算器的作用是實作 基本加減乘除
1實作+ 2實作- 3實作* 4實作 0退出 其余數字報錯,提醒重按.
按照上面的邏輯,我們可以很快想到用 do while回圈 和 switch;
/*我們首先搭建結構*/
//結構搭建
#include <stdio.h>
int main()
{
int input = 0;
int x,y;
do
{
remind();//提醒按鍵選單
printf("請根據上面的提醒,按下命令數字1或2或3或4:\n");
scanf("%d", &input);
switch (input)
{
case 1:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",add(x,y));
break;
case 2:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",sub(x,y));
break;
case 3:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",mul(x,y));
break;
case 4:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d", div(x,y));
break;
case 0:
printf("成功退出計算器\n\n\n");
break;
default:
printf("對不起,你輸入的命令有誤,請重新輸入!\n");
break;
}
}while(input);
return 0;
}
上面的結構已經搭建好了,現在我么開始寫函式 加減乘除的功能以及remind的功能
#include <stdio.h>
void remind()
{
printf("**********************************************\n");
printf("*********按1加 按2減 按3乘 按4除*********\n");
printf("************** 其他操作報告提示 ***************\n");
}
int add(int x,int y)
{
return x+y;
}
int sub (int x,int y)
{
return x-y;
}
int mul(int x,int y)
{
return x*y;
}
int div(int x,int y)
{
return x/y;
}
然后我么總體合并,就可以實作了…
#include <stdio.h>
void remind()
{
printf("**********************************************\n");
printf("****按1加 按2減 按3乘 按4除 按0退出*****\n");
printf("************** 其他操作報告提示 ***************\n");
}
int add(int x,int y)
{
return x+y;
}
int sub (int x,int y)
{
return x-y;
}
int mul(int x,int y)
{
return x*y;
}
int div(int x,int y)
{
return x/y;
}
int main()
{
int input = 0;
int x,y;
do
{
remind();//提醒按鍵選單
printf("請根據上面的提醒,按下命令數字1或2或3或4或0:\n");
scanf("%d", &input);
switch (input)
{
case 1:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",add(x,y));
break;
case 2:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",sub(x,y));
break;
case 3:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d\n",mul(x,y));
break;
case 4:
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n");
printf("%d", div(x,y));
break;
case 0:
printf("您成功退出計算器\n\n\n");
break;
default:
printf("對不起,你輸入的命令有誤,請重新輸入!\n");
break;
}
}while(input);
return 0;
}
現在我們看到,基本已經實作了計算器的功能,但是如果我們還有繼續多的函式,比如冪次方 開放 對數,難道也要像上面一樣,一一列舉出來嗎?這樣是不是會顯得十分繁瑣,并且代碼冗余???所以這就需要我們的 函式指標陣列 了,然后根據索引進行取功能
代碼如下:
#include <stdio.h>
int main()
{
int input = 0;
int x,y;
int(*num[5])(int,int) = {0,add,sub,mul,div};
do
{
remind();//提醒按鍵選單
printf("請根據上面的提醒,按下命令數字1或2或3或4或0:\n");
scanf("%d", &input);
if(input>=1 && input <= 4)
{
printf("系統已經識別到你的目的,請輸入你想要操作該目的兩個數字\n");
scanf("%d%d", &x,&y);
printf("輸入完畢,結果是:\n\n");
printf("%d\n",num[input](x,y));
}
else if(input == 0)
printf("成功退出\n");
else
printf("對不起,你輸入的命令有誤,請重新輸入!\n");
}while(input);
return 0;
}
是不是發現代碼量 極度減少???,這就是函式指標陣列的好處.
我們首先把加減乘除函式封裝在陣列里面,然后利用下標進行訪問
7.函式指標陣列指標
指向函式指標陣列的指標是一個 指標 ,指標指向一個 陣列 ,陣列的元素都是 函式指標 ;
那么怎么定義呢? 我們同樣可以回顧一下最開始我們是怎么定義 陣列指標 —>> 函式指標----->>>陣列指標陣列等等的
現在我們需要定義函式指標陣列指標, 所以需要明確 本體(指標) 指向型別(陣列) 所指向的陣列存的什么(函式指標)
#include <stdio.h> int add(); int main() { /*第一步,首先寫出函式指標*/ int(* func_point)() = &add; //這是一個函式指標 /*第二步,寫出一個陣列,用來存放函式指標 (所以想想怎么寫這個陣列)*/ int (* )() num[] = {func_point,func_point,func_point}; //這樣寫對嗎?對!!!!了90%,因為基本符合陣列的規范, //但是我前面一直強調一個事情,*必須怎么樣???*需要挨著名字.所以下面才是真正的寫法 int (*num[])() = {func_point,func_point,func_point}; /*第三部,寫出一個指標,用來存放函式指標陣列*/ //第一步,先寫出指標 (*point) //第二步,寫出指標指向的陣列 (*point)[] //第三部, 給所指向的陣列添加陣列型別 int (*)() (*point)[];// 成功了嗎??對!!!!了90%,但是還是不要忘記我們所說的,*必須挨著名字,所以: int (*(*point)[])(); //大工告成!!!!!!!!!!!! return 0; }所以,我們函式指標陣列指標一般這樣寫 int (*(*point)[])();
8.回呼函式
回呼函式就是一個通過函式指標呼叫的函式,如果你把函式的指標(地址)作為引數傳遞給另一
個函式,當這個指標被用來呼叫其所指向的函式時,我們就說這是回呼函式,回呼函式不是由該
函式的實作方直接呼叫,而是在特定的事件或條件發生時由另外的一方呼叫的,用于對該事件或
條件進行回應,
簡而言之,就是一個函式的引數接收的是一個函式地址.被接收的函式,這時候就稱為 回呼函式
#include <stdio.h>
int x = 2;
int y = 3;
int add(int x,int y)
{
return x+y;
}
int many( int(*func)(int,int), int b )
{
return func(x,y) + b;
}
int main()
{
printf("%d", many(add,6));
return 0;
}
/*
運行結果是:
11
*/
這時候,add就是回呼函式
9.模擬qsort函式
現在我們開始使用回呼函式以及指標來模擬
qsort,并且qsort可以排序一切但是在模擬之前,我們首先需要知道qsort函式是怎么使用的,現在我們來看官方檔案.
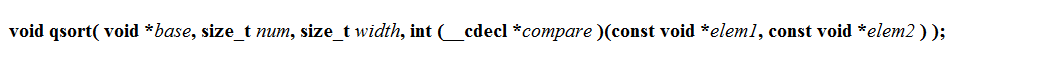
官方的
qsort是像上面一樣宣告的,我現在一一解釋什么意思:
void* base待排序元素的首元素地址,即陣列首元素地址,即陣列名
size_t num陣列元素數量
size_t width陣列單個元素的記憶體大小
int(_cdecl *compare)(const void* eleml,const void* elem2)接收一個比較函式,回傳 正數 負數 和 0
其中compare的寫法是這樣
//如果想要升序排列整型陣列,就這樣寫
int compare (const void * a, const void * b)
{
return ( *(int*)a - *(int*)b );
}
//如果想要降序排列整型陣列,就這樣寫
int compare (const void * a, const void * b)
{
return ( *(int*)b - *(int*)a );
}
現在有一個要求,有5個人,每個人有詳細的 名字 年齡 分數,請按照要求輸出分數從高到低的每一個人的名字
#include <stdio.h>
#include <stdlib.h>
struct info
{
char name[20];
int age;
int grade;
};
int compare(const void* a, const void* b)
{
return ((struct info*)a)->grade - ((struct info*)b)->grade;
}
int main()
{
struct info information[5] = {
{"夏敏",18,65},
{"李華",16,71},
{"杜美麗",17,85},
{"劉安",17,69},
{"李平",18,90}
};
qsort(information, sizeof(information) / sizeof(information[0]), sizeof(information[0]), compare);
for (int i = 0; i < 5; i++)
{
printf("%s\n", information[i].name);
}
return 0;
}
/*
運行結果:
李平
杜美麗
李華
劉安
夏敏
*/
現在我們可以開始模擬qsort函式了,因為我們知道了他的機制.現在我們開始寫my_sqort();
我們知道
qsort的主要作用就是排序,所以我們自己設計的qsort的核心程式就是排序,我們為了簡單就選擇通過冒泡思想來解決
#include <stdio.h>
struct info
{
char name[20];
int age;
int grade;
};
/*因為指標就收的地址是第一個位元組,所以需要挨個交換*/
void swap(char* a,char*b,int width)
{
for(int i = 0;i<width;i++)
{
char tmp = *b;
*b = *a;
*a = tmp;
a++;
b++;
}
}
/*第一步,首先按照標準qsort的寫法,我們直接模擬一個與其一樣的函式宣告*/
void my_sort(void* base,int number,int size,int(*compare)(const void*,const void*))
{
/*第二步,寫好冒泡排序的框架*/
int i = 0,j = 0;
for(i = 0;i<number-1;i++)
{
for(j = 0;j<number-1-i;j++)
{
/*第三步,我們需要通過呼叫compare知道他的回傳值是大于0.還是小于0;如果大于0,我們就需要升序,反之,降序.*/
//那么,當有人在qsort外面寫compare時候,他是知道自己需要排序什么型別的,但是我們模擬qsort的時候,我們是不知道的,所以我們需要實作某種方式來保證我們能夠知道: 想要使用qsort排序的人的排序陣列型別
//現在我們在my_qsort內部只知道 4 個引數 base number size 與compare
//那么怎么來利用這4個值確定我們一定可以知道待排序型別呢?? 那就是base與size,base是指標,首元素地址,size是一個元素的大小.
//那么 (char*)base就一定是第一個元素的地址
// (char*)base + size就一定是第二個元素地址
//所以,(char*)base + j*size就是前一個元素地址,
// (char*)base + (j+1)*size就是后一個元素地址.
//所以,我們可以開始自己使用compare
if(compare((char*)base + j*size,(char*)base + (j+1)*size)>0)
{
//如果回傳值大于0,說明前面的值比后面大,所以我們需要交換前后兩個值
swap((char*)base + j*size, (char*)base + (j+1)*size, size);
}
}
}
}
int main()
{
struct info information[5] = {
{"夏敏",18,65},
{"李華",16,71},
{"杜美麗",17,85},
{"劉安",17,69},
{"李平",18,90}
};
my_qsort(information, sizeof(information) / sizeof(information[0]), sizeof(information[0]), compare);
for (int i = 0; i < 5; i++)
{
printf("%s\n", information[i].name);
}
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/275840.html
標籤:其他