前言
一、為什么創建行程?
二、行程虛擬地址空間
1.空間布局圖
三.通過虛擬地址找到物理記憶體地址
1.資料在物理記憶體中的存盤
2.如何通過虛擬地址找到物理記憶體呢?
1.分段式
2.分頁式
3.段頁式
總結
前言
我們上一篇介紹到行程的概念,運行,管理,以及它的狀態,那么我們這一篇就了解一下行程的創建,
提示:以下是本篇文章正文內容,下面案例可供參考
一、為什么創建行程?
我們說過:行程就是運行起來的程式,程式運行起來需要被加載到記憶體中,
對作業系統來說:管理程式的運行,就是將程式的運行程序描述起來,然后組織起來進行管理,描述的運行資訊對作業系統來說就是運行中的行程,
行程就是pcb,創建一個行程不就相當于是創建一個它的描述,也就是PCB,復制了呼叫fork的這個行程pcb的資訊(記憶體指標、程式計數器、.背景關系資料)
我們用代碼看一下
#include<stdio.h>
#include<unistd.h>
int main (int argc, char *argv[])
{
pid_ t pid = fork();//創建子行程
//因為子行程復制了父行程,因此子行程與父行程運行的代碼以及運行的位置都是一樣的
//從代碼運行的角度來看,就都是從fork函式之后開始運行的
//因為父子行程運行的代碼資料都一樣,因此無法直接分辨,只能通過回傳值判斷
//對于父行程fork回傳值>0;對 于子行程回傳值==0
//雖然父子行程代碼相同,但是因為回傳值不同,因此會各自進入不同的判斷執行體
if(pid>0)
{
//this is parents
printf("this is parents:%d\n" ,getpid());
}
else if (pid == 0)
{
//this is child
printf("this is child:%d\n", getpid());//getpid() 獲取呼叫 的識別符號-pid-行程ID[
}
else
{
//error
printf("error\n");
}
return 0;
}
這個新的行程,運行的代碼與呼叫fork的行程一樣, 并且運行位置也相同,
fork創建子行程之后,父好行程誰先運行,不一定, 大家都是pcb,作業系統調度到誰誰就運行,
為什么要創建子行程的原因:
子行程干的事情與父行程一樣,當然使用回傳值分流后可以有所不同
有任務了,創建一個子行程,讓子行程去完成任務,出問題了崩潰的就是子行程,父行程就不會崩潰了(保護父行程-分攤壓力)
創建了子行程,那么就會讓子行程有相應的作業,但是由于子行程是拷貝父行程的,看起來并沒有什么區別,那么它們是如何訪問資料,及記憶體空間的,這就引入到了下面這個問題,
二、行程虛擬地址空間
1.空間布局圖
在32位作業系統下
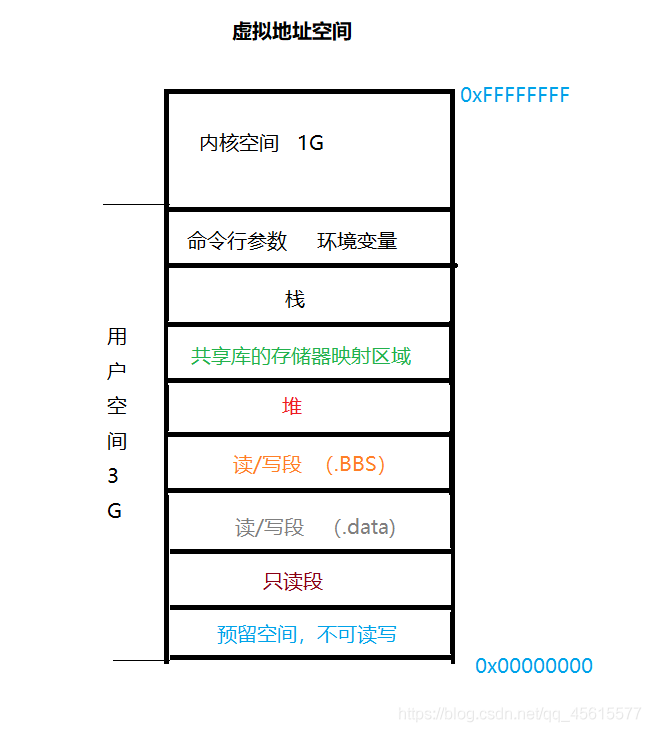
內核:內核總是駐留在記憶體中,是作業系統的一部分,內核空間為內核保留,不允許應用程式讀寫該區域的內容或直接呼叫內核代碼定義的函式,
堆疊:
- 函式的回傳值和引數,
- 臨時變數,包括非靜態區域變數,以及編譯器自動生成的臨時變數,
- 保存背景關系:包括函式呼叫前后需保持不變的暫存器,
存盤映射區域:該區域用于映射可執行檔案用到的元件,,若可執行檔案依賴共享庫,則系統會為這些動態庫分配相應空間,并在程式裝載時將其載入到該空間,,
堆區:堆用于存放行程運行時動態分配的記憶體段,可動態擴張或縮減,堆中內容是匿名的,不能按名字直接訪問,只能通過指標間接訪問,當行程呼叫malloc/new等函式分配記憶體時,新分配的記憶體動態添加到堆上(擴張);當呼叫free/delete等函式釋放記憶體時,被釋放的記憶體從堆中剔除(縮減) ,
BBS段:
- 未初始化的全域變數和靜態區域變數
- 初始值為0的全域變數和靜態區域變數
- 未定義且初值不為0的符號
Data段:
資料段通常用于存放程式中已初始化且初值不為0的全域變數和靜態區域變數,資料段屬于靜態記憶體分配(靜態存盤區),可讀可寫,資料段保存在目標檔案中,其內容由程式初始化,
保留區:位于虛擬地址空間的最低部分,未賦予物理地址,任何對它的參考都是非法的,用于捕捉使用空指標和小整型值指標參考記憶體的例外情況,
有了上面的認識,我們在看一下代碼:
1 #include <stdio.h>
2 #include <unistd.h>
3 int val=5;
4 int main()
5 {
6 pid_t pid=fork();
7 if(pid>0)
8 {
9 printf("this is parent:%d ,val: %d, %p\n",getpid(),val,&val );
10 }
11 else if(pid==0)
12 {
13 printf("this is child%d ,val: %d, %p\n",getpid(),val,&val);
14 }
15 else
16 {
17 printf("error\n");
18 }
19 return 0;
20 }
21

我們可以看到 相同的變數 在父行程和子行程中都一樣的,地址也一樣,那么他是什么原理呢,我們畫圖了解一下
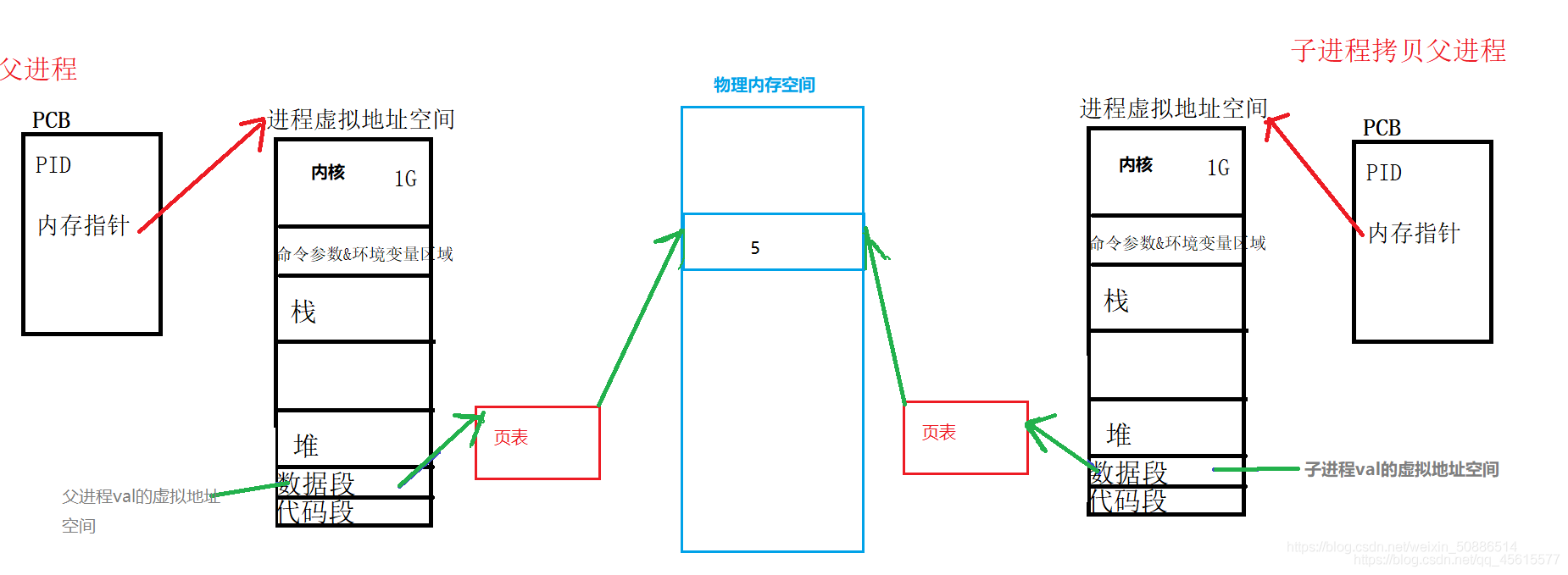
我們知道一個記憶體地址只能指向一個唯一的記憶體單元一個記憶體單元只能存盤一個資料
我們通過上面可以看到其實行程中所訪問的地址都是虛擬地址,都是一個假的地址,并非物理記憶體地址
我們所說的程式地址空間,實際上也是一個虛擬的地址空間,是作業系統為行程通過一個mm. struct結構體所描述的一個假的地址空間,mm_ struct (task_ size, start_ code, end_ code) --通過大小以及區域的編號描述
我們再將上面的代碼修改一下
1 #include <stdio.h>
2 #include <unistd.h>
3 int val=5;
4 int main()
5 {
6 pid_t pid=fork();
7 if(pid>0)
8 {
9 printf("this is parent:%d ,val: %d, %p\n",getpid(),val,&val);
10 }
11 else if(pid==0)
12 {
13 val=10;
14 printf("this is child%d ,val: %d, %p\n",getpid(),val,&val);
15 }
16 else
17 {
18 printf("error\n");
19 }
20 return 0;
21 }
我們在看一下結果

我們看到了 資料不同 但是地址相同為什么呢?我們畫一幅簡圖了解一下,
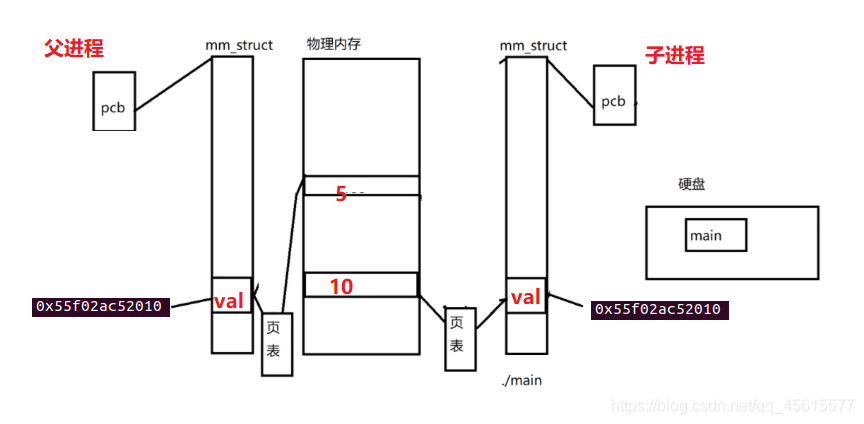
資料不同 但是地址相同的原因:
子行程復制父行程,復制了pcb,頁表,虛擬地址空間,所以父子行程除了個別資料(識別符號)之外都是一樣,并且父子行程的資料指向的是同一塊物理記憶體,所以看起來父行程有什么子行程也有什么,但是行程之間要保持獨立性 資料獨有 各有個的資料,因此當某一塊空間中的資料即將發生改變,則為子行程重新開辟物理記憶體,將資料拷貝過去,(寫時拷貝技術----為 了提高子行程創建效率(畢竟有些資料從來不會改變(比如代碼)重新開辟一塊記憶體將資料拷貝過去,沒有意義,反而占據了更多的記憶體) )
我們知道了行程是通過虛擬地址空間訪問資料,那么又帶來了下面這個問題,
為什么作業系統不讓行程直接訪問物理記憶體,而是弄了一個虛擬地址空間,讓行程訪問虛擬地址呢? ?若行程直接訪問物理記憶體,有哪些不好的?
- 程式在編譯時,編譯器就會給指令和資料進行地址編號;但是如果某個地址記憶體已經被占用,則這個程式就運行不起來了--編譯器的地址管理麻煩(無法動態的獲知什么時候那塊記憶體是否被使用,也就無法進行代碼以及資料的地址賦值)
- 行程直接訪問物理記憶體,如果有一個野指標, 你在操作的時候有可能就把其它行程中的資料改變了(無法進行記憶體訪問控制)
- 程式運行加載通常需要使用一塊連續的記憶體空間,對記憶體的利用率比較低
三.通過虛擬地址找到物理記憶體地址
1.資料在物理記憶體中的存盤
1.順序存盤
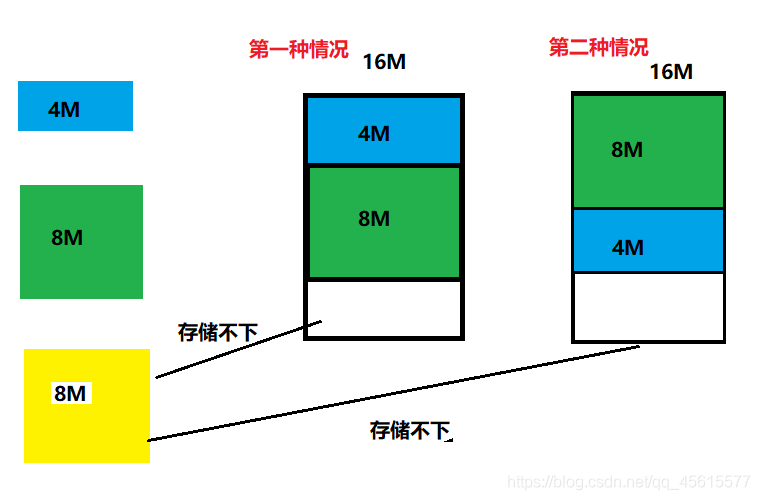
我們上面這種情況是屬于,順序存盤,其必須要使用一塊連續的記憶體,對記憶體的利用率比較低,
比如上面的,第一種情況,有一個16M的記憶體,但是里面有一個4M 8M的資料,所以想要在放一個8M的資料,它是放不下的,必須等上面8M的資料釋放了之后才能存進來,
第二種情況,同樣16M的記憶體,但是里面的資料分別是8M 4M,所以想要在放一個8M的資料,它同樣是放不下的,必須等上面的4M的資料釋放了之后才能存進來,
為了提高效率,我們又有了離散存盤,
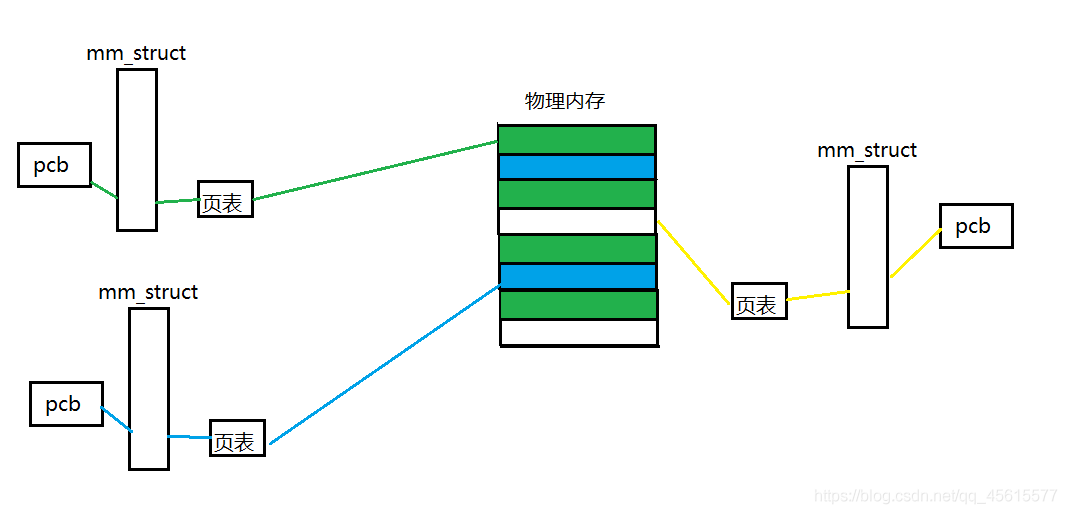
通過虛擬地址空間映射到物理記憶體上進行資料存盤,可以實作資料在物理記憶體上的離散式存盤,提高記憶體的利用率,
并且每個行程都有自己的虛擬地址空間,因此對于每個行程來說,都會擁有自己的- -塊連續的空間使用,
2.如何通過虛擬地址找到物理記憶體呢?
1.分段式
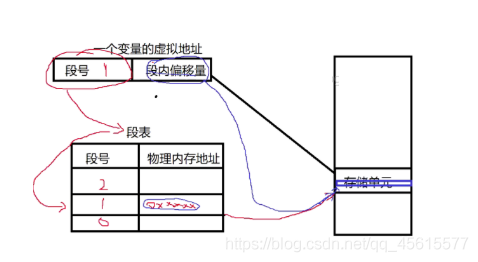
分段式:將虛擬地址的組成分為段號+段內偏移量(比如全域資料段有很多變數,他們的段號都是一樣的, 也就意味著物理記憶體段的起始地址一樣,但是每個變數的偏移量不同,)因此,通過段號對應的物理記憶體段起始地址,以及虛擬地址中的偏移量組成一個完整的物理地址,找到對應的物理記憶體單元,
分段式優缺點:
對編譯器的地址管理比較友好;但是沒有解決資料連續存盤記憶體利用率低的問題,因為一個段管理了很多變數資料,這些變數就都是通過同一個起始地址進行偏移的,也就在物理地址中使用了連續的地址空間(分段式管理中,同一個段內地資料都使用了連續的地址空間)
因為分段式還是需要連續的空間,效率不高,所以又提出了分頁式,
2.分頁式
分頁式管理=頁號+頁內偏移
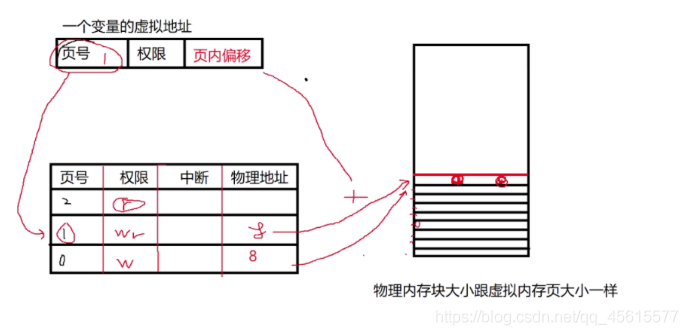
因為通常物理塊比較小,并且不要求同一個行程的多個資料必須在同一個塊內,因此分頁式實作了資料在物理記憶體中的離散式存盤,提高了記憶體利用率,
并且頁表會在進行記憶體訪問的時候進行記憶體訪問控制(是否有權限)
分頁式記憶體管理的優點:實作資料離散式存盤, 提高記憶體利用率,并且通過頁表進行記憶體訪問控制,
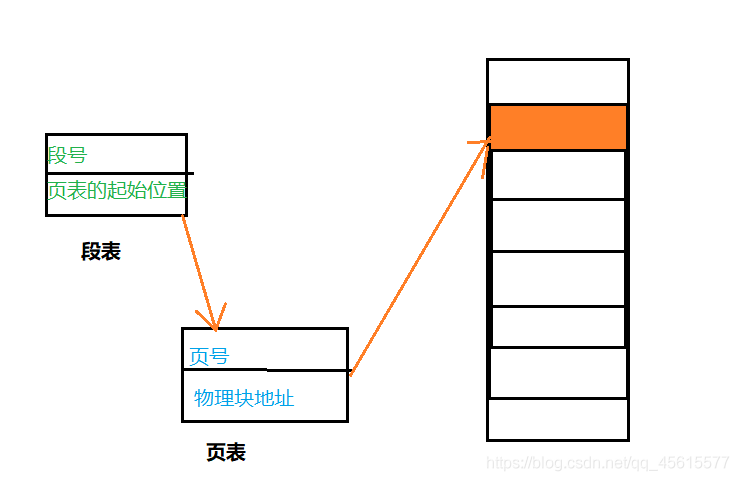
3.段頁式
段頁式的記憶體管理:將記憶體進行分段,在每個段內采用分頁管理,
也就是說:段頁式管理=段號+頁號+頁內偏移
總結
以上是所說關于行程創建以及行程如何通過虛擬地址空間訪問到物理記憶體空間的相關內容,感謝您的閱讀,如有錯誤,歡迎指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/276236.html
標籤:其他