大家好,我是冰河~~
從今天開始,我們正式更新【精通Zookeeepr系列】專題內容,首先我們對Zookeeper的基礎內容做下簡單的回顧和總結,本文的總體內容如下,
什么是Zookeeper?
簡單來說,Zookeeper是一個開源的分布式協同服務系統,Zookeeper的設計目標就是把復雜并且容易出錯的分布式協同服務進行封裝,并抽象出一個高效可靠的原語介面,并對外提供一系列簡單的介面為其他服務呼叫,其他應用只要使用Zookeeper提供的介面,就可以實作各種分布式應用,例如:分布式鎖、分布式選舉,主從切換等等,這些案例我們在實戰內容中會詳細說明,
Zookeeper發展史
Zoookeeper最早是雅虎為了解決內部多個系統之間的協同問題而研發的,后來將其開源并捐贈給了Apache組織,后來Zookeeper在開源界被廣泛使用,這里,我列舉幾個使用了Zookeeper的著名的開源專案,
- Hadoop:使用Zookeeper來提供NameNode的高可用機制,
- HBase:使用Zookeeper來保證整個集群中只有一個Master節點,保存集群中的RegionServer串列,保存hbase:meta表的位置,
- Kafka:使用Zookeeper來對進群中的成員進行管理,并使用Zookeeper提供controller節點的選舉機制,
- Dubbo:使用Zookeeper來實作分布式治理服務的注冊中心,
- SpringCloud:使用Zookeeper來實作微服務注冊中心,
還有很多使用Zookeeper作為分布式協同的開源專案,由于數量比較多,這里就不一一列舉了,小伙伴們可以自行通過網路查閱,
Zookeeper應用場景
簡單點說,Zookeeper可以應用于以下場景當中,
- 配置管理,
- DNS服務,
- 組成員管理,
- 各種分布式鎖,
- 分布式選舉,
- 資料一致性場景,
但是,需要注意的是:Zookeeper只適合于存盤和協同相關的關鍵資料,不適合用來存盤大資料量的資料,
Zookeeper服務的使用
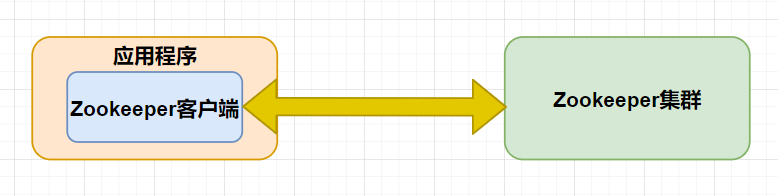
一般情況下,我們在使用Zookeeper時,是通過Zookeeper庫來連接并使用Zookeeper的,由Zookeeper客戶端負責和Zookeeper集群進行互動,
Zookeeper的資料模型
從本質上講,Zookeeper的資料模型是層次模型,如下所示,
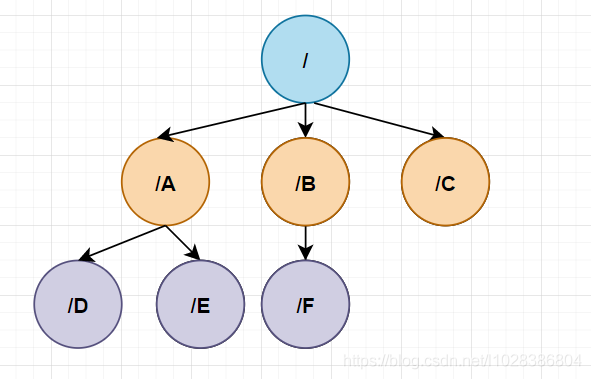
這種層次模型常見于檔案系統,而這種層次模型和Key-Value模型是兩種主流的資料模型,Zookeeper使用檔案系統模型主要的考慮點如下,
- 檔案系統的樹形結構便于表達資料之間的層次關系,
- 檔案系統的樹形結構便于為不同的應用分配獨立的命名空間,
在Zookeeper中,層次結構的每個節點叫做znode,它不同于檔案系統,每個節點都可以保存資料,而且每個節點都有一個版本號,版本號從0開始遞增計數,
接下來,我們再來看一個Zookeeper節點的具體示例,
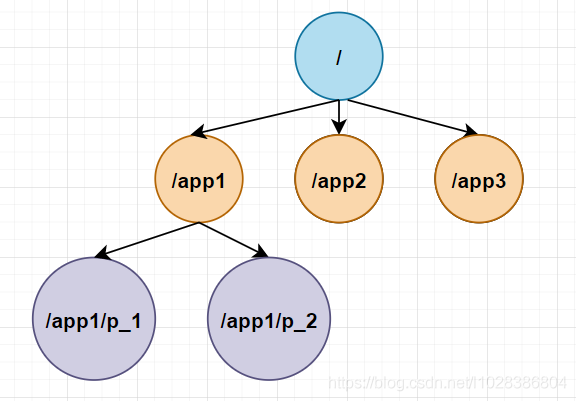
例如,上圖中有三個子樹,三個子樹分別應用于app1、app2和app3三個應用,其中app1的子樹實作了一個簡單的組成員協議,也就是每個客戶端進行p創建一個znode在/app1節點下,而且每個行程創建的znode是以/app1/p_1,/app1/p_2,...,/app1/p_n 這種結構依次存放,只要 /app1/p_n 節點存在,就說明Pn行程在正常的運行,
Zookeeper的節點分類
總體來說,Znode節點可以分為以下四類,
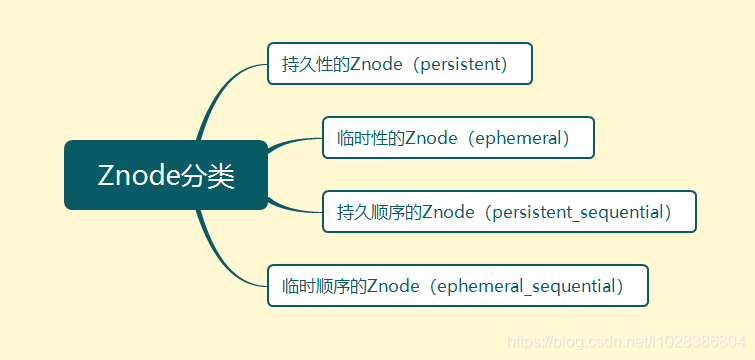
一個Znode節點可以是持久性的,也可以是臨時性的,
- 持久性的Znode:創建節點后即使Zookeeper集群宕機,或者Zookeeper客戶端宕機,節點也不會丟失,
- 臨時性的Znode:Zookeeper客戶端宕機或者客戶端在指定的超時時間內沒有給Zookeeper集群發送訊息,那么這個節點就會消失,
Znode節點也可以是順序性的,所謂的順序性,就是指每個節點會關聯一個唯一的單調遞增整數,這個單調遞增的整數就是Znode節點名稱的后綴,比如:/app1/p_1,/app1/p_2等,由此,Znode又有如下兩種分類:
- 持久順序性的Znode:除了具備持久性的Znode的特性之外,Znode的名稱還具備順序性,
- 臨時順序性的Znode:除了具備臨時性的Znode的特性之外,Znode的名稱還具備順序性,
好了,今天就到這兒吧,我是冰河,大家有啥問題可以在下方留言,也可以加我微信:sun_shine_lyz,我拉你進群,一起交流技術,一起進階,一起進大廠~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/276746.html
標籤:其他