前言
之前小撰寫的文章從未有過精通二字,因為感覺自己不配,這次發奮圖強努力做到第一個框架的精通,就是這Mybatis了,為什么挑Mybatis因為他比較簡潔(原始碼里面連注釋都不太有),然后國內用的比較廣泛以及代碼量不大,小編還是比較有信心的,這次學習原始碼如之前在其他文章中所說的,我們從最核心開始,然后一步一步往外擴展,畢竟最外部的呼叫Api往往做了層層封裝運用了各種設計模式,代碼的聯調也會不斷的跳躍,讓人很痛苦,所以咱們扒開外層看本質,一如既往的廢話不多說,進入正題,
JDBC回顧
眾所周知,Mybatis是對JDBC的封裝,那底層肯定是JDBC,那是不是很有必要回顧一下jdbc(小編想起了面試題的時候問到jdbc的執行程序),先寫一段代碼
//首先加載驅動
Class.forName("com.mysql.jdbc.Driver");
//提供JDBC連接的URL
String url="jdbc:mysql://0.0.0.0:3306/xxxx";
String username="root";
String password="root";
//創建資料庫的連接
Connection con = DriverManager.getConnection(url,username,password);
//創建一個statement執行者
String sql="SELECT * FROM biz_spot WHERE spot_id = ";
PreparedStatement statement = con.prepareStatement(sql);
statement.setLong(1,11L);
//執行SQL陳述句
ResultSet result = statement.executeQuery();
//處理回傳結果
while (result.next()){
System.out.println(result.getString("xxx") + "---" + result.getString("xxx"));
}
//關閉JDBC物件
con.close();
result.close();
statement.close();
執行程序如下圖所示:
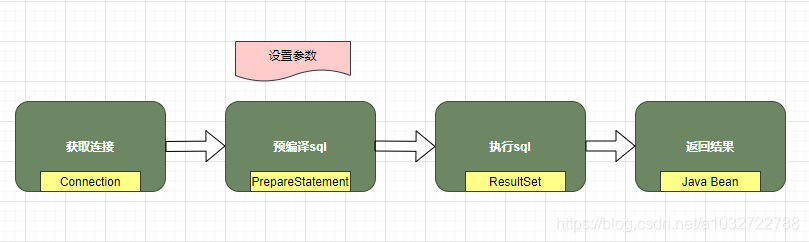
今天著重講執行器,所以呢我們先來看看JDBC的Statement,statement的重要作用就是設定sql引數然后執行sql,先來看看jdbc的三種sql處理器:

除了存盤程序執行器,小編用編碼方式來一一解釋下:
Statement 中非常規方法
addBatch: 批處理操作,將多個SQL合并在一起,最后呼叫executeBatch 一起發送至資料庫執行
setFetchSize:設定從資料庫每次讀取的數量單位,該舉措是為了防止一次性從資料庫加載資料過多,導致記憶體溢位,
編碼示例:
//批量執行sql
@Test
public void prepareBatchTest() throws SQLException {
String sql = "INSERT INTO `users` (`name`,age) VALUES ('bob',18);";
Statement statement = connection.createStatement();
//設定最大行數
statement.setFetchSize(100);
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
statement.addBatch(sql);
}
// 批處理 一次發射
statement.executeBatch();
System.out.println(System.currentTimeMillis() - start);
statement.close();
}
//批量設定引數然后執行
@Test
public void prepareBatchTest() throws SQLException {
String sql = "INSERT INTO `users` (`name`,age) VALUES (?,18);";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.setFetchSize(100);
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
preparedStatement.setString(1, UUID.randomUUID().toString());
preparedStatement.addBatch(); // 添加批處理引數
}
preparedStatement.executeBatch(); // 批處理 一次發射
System.out.println(System.currentTimeMillis() - start);
preparedStatement.close();
}
上面批處理的話當然比單次回圈執行速度要快很多,
PreparedStatement 中防sql注入
關于防止sql注入,Statement是直接發送靜態sql執行,而PreparedStatement 發送的是sql(這邊會帶問號)以及若干引陣列,引數需要轉義進去,所有的轉義操作都在資料庫端執行,并不是在我們的應用層轉義的,
代碼示例
// sql注入測驗
public int selectByName(String name) throws SQLException {
String sql = "SELECT * FROM users WHERE `name`='" + name + "'";
System.out.println(sql);
Statement statement = connection.createStatement();
statement.executeQuery(sql);
ResultSet resultSet = statement.getResultSet();
int count=0;
while (resultSet.next()){
count++;
}
statement.close();
return count;
}
//PreparedStatement防止sql注入測驗
public int selectByName2(String name) throws SQLException {
String sql = "SELECT * FROM users WHERE `name`=?";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setString(1,name);
System.out.println(statement);
statement.executeQuery();
ResultSet resultSet = statement.getResultSet();
int count=0;
while (resultSet.next()){
count++;
}
statement.close();
return count;
}
@Test
public void injectTest() throws SQLException {
//正常情況下
System.out.println(selectByName("bob"));
//sql注入
System.out.println(selectByName("bob' or '1'='1"));
//sql注入并沒作用
System.out.println(selectByName2("bob' or '1'='1"));
}
Mybatis執行程序
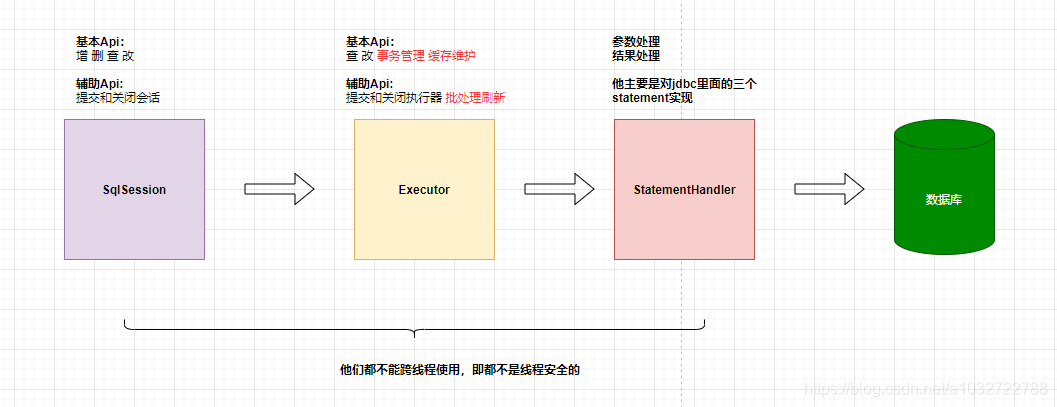
想不到隨便回顧一下JDBC就花了一大個篇幅,那緊接著小編帶大家看看Mybatis的執行程序:

小編稍微解釋一下各個程序也是各個組件的作用:
- 介面代理: 其目的是簡化對MyBatis使用,底層使用動態代理實作,
- Sql會話: 提供增刪改查API,其本身不作任何業務邏輯的處理,所有處理都交給執行器,采用了設計模式中的門面模式,
- 執行器: 核心作用是處理SQL請求、事務管理、維護快取以及批處理等 ,執行器在的角色更像是一個管理員,接收SQL請求,然后根據快取、批處理等邏輯來決定如何執行這個SQL請求,并交給JDBC處理器執行具體SQL,
- JDBC處理器:他的作用就是用于通過JDBC具體處理SQL和引數的,在會話中每呼叫一次CRUD,JDBC處理器就會生成一個實體與之對應(命中快取除外),
各個組件的功能以及注意事項如下圖:
Executor
那接下來小編主要講Mybatis的Executor執行器
Executor是MyBatis執行介面,小編不厭其煩的在對執行器的功能做下總結:
- 基本功能:改、查,沒有增刪的原因是所有的增刪操作都可以歸結到改,
- 快取維護:這里的快取主要是為一級快取服務,功能包括創建快取Key、清理快取、判斷快取是否存在,
- 事務管理:提交、回滾、關閉、批處理重繪,(一般我們都交由spring管理,不會使用mybatis的)
- Executor:可包含多個statement
Executor有主要的三個實作子類,分別是:SimpleExecutor(簡單執行器)、ReuseExecutor(重用執行器)、BatchExecutor(批處理執行器),
簡單執行器
SimpleExecutor是默認執行器,它的行為是每處理一次會話當中的SQl請求都會通過對應的StatementHandler 構建一個新個Statement,這就會導致即使是相同SQL陳述句也無法重用Statement,所以就有了(ReuseExecutor)可重用執行器
可重用執行器
ReuseExecutor 區別在于他會將在會話期間內的Statement進行快取,并使用SQL陳述句作為Key,所以當執行下一請求的時候,不在重復構建Statement,而是從快取中取出并設定引數,然后執行,閱讀原始碼可以知道其實里面就包含一個statementMap,執行的時候看一下是否存在,如果有了就不需要新構建statement了
這也說明為什么執行器不能跨執行緒呼叫,這會導致兩個執行緒給同一個Statement 設定不同場景引數,
批處理執行器
BatchExecutor 顧名思議,它就是用來作批處理的,但會將所有SQL請求集中起來,最后呼叫Executor.flushStatements() 方法時一次性將所有請求發送至資料庫,
下面小編有三個示例的代碼:
public class ExecutorTest {
private Configuration configuration;
private Connection connection;
private JdbcTransaction jdbcTransaction;
private MappedStatement ms;
private SqlSessionFactory factory;
@Before
public void init() throws SQLException {
// 獲取構建器
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
// 決議XML 并構造會話工廠
factory = factoryBuilder.build(ExecutorTest.class.getResourceAsStream("/mybatis-config.xml"));
configuration = factory.getConfiguration();
jdbcTransaction = new JdbcTransaction(factory.openSession().getConnection());
// 獲取SQL映射
ms = configuration.getMappedStatement("xxx.xxx.xxx.UserMapper.selectByid");
}
// 簡單執行器測驗
@Test
public void simpleTest() throws SQLException {
SimpleExecutor executor = new SimpleExecutor(configuration, jdbcTransaction);
List<Object> list = executor.doQuery(ms, 10, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(10));
executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
System.out.println(list.get(0));
}
// 重用執行器
@Test
public void ReuseTest() throws SQLException {
ReuseExecutor executor = new ReuseExecutor(configuration, jdbcTransaction);
List<Object> list = executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
// 相同的SQL 會快取對應的 PrepareStatement-->快取周期:會話
executor.doQuery(ms, 1, RowBounds.DEFAULT,
SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(1));
System.out.println(list.get(0));
}
// 批處理執行器
@Test
public void batchTest() throws SQLException {
BatchExecutor executor = new BatchExecutor(configuration, jdbcTransaction);
MappedStatement setName = configuration
.getMappedStatement("xxx.xxx.xxx.UserMapper.setName");
Map<String,Object> param = new HashMap<>(2);
param.put("arg0", 1);
param.put("arg1", "good man");
//設定
executor.doUpdate(setName, param);
executor.doUpdate(setName, param);
executor.doFlushStatements(false);
}
}
注意:這邊代碼示例,小編的環境當然搭建好了可以跑起來了,大家的話可以自己搭建環境,具體用意只是讓大家對三個執行器的執行有相對了解,并且知道怎么直接呼叫這三個執行器的,
這邊批處理執行器想必大家覺得和上面有所不一樣吧,為什么他不寫查詢,其實他如果寫查詢的話和上面的SimpleExecutor 一樣,他有批處理功能,和上面jdbc的批處理一樣,他是一條sql,設定多個引數過去,然后執行,而ReuseExecutor 是設定一次引數執行一次,設定一次執行一次,還是有本質的區別,不知道小編說清楚沒有,
基礎以及二級快取執行器
前面我們所說Executor其中有一個職責是負責快取維護,以及事務管理,上面三個執行器并沒有涉及,這部分邏輯去哪了呢?別急,快取和事務無論采用哪種執行器,都會涉及,這屬于公共邏輯,所以就完全有必要三個類之上抽象出一個基礎執行器用來處理公共邏輯,
基礎執行器
BaseExecutor 基礎執行器主要是用于維護快取和事務,事務是通過會話中呼叫commit、rollback進行管理,重點在于快取這塊它是如何處理的? (這里的快取是指一級快取),它實作了Executor中的query與update方法,會話中SQL請求,正是呼叫的這兩個方法,Query方法中處理一級快取邏輯,即根據SQL及引數判斷快取中是否存在資料,有就走快取,否則就會呼叫子類的doQuery() 方法去查詢資料庫,然后在設定快取,在doUpdate() 中主要是用于清空快取,
二級快取執行器
BaseExecutor 只有一級快取,那二級快取其實是在CachingExecutor,那為什么不把它和一級快取一起處理呢?因為二級快取和一級快取相對獨立的邏輯,而且二級快取可以通過引數控制關閉,而一級快取是不可以的,綜上原因把二級快取單獨抽出來處理,抽取的方式采用了裝飾者設計模式,即在CachingExecutor 對原有的執行器進行包裝(明白點就是CachingExecutor 包含了一個Executor,這里為三大子類執行器,子類擁有父類的方法基本就是指向了父類BaseExecutor的方法),處理完二級快取邏輯之后,把SQL執行相關的邏輯交給實際的Executor處理(交由BaseExecutor 以及其子類處理),
CachingExecutor直接實作了Executor介面,
接下來小編帶大家看這些執行器的關系,相信看完之后一目了然:
Executor執行器關系圖
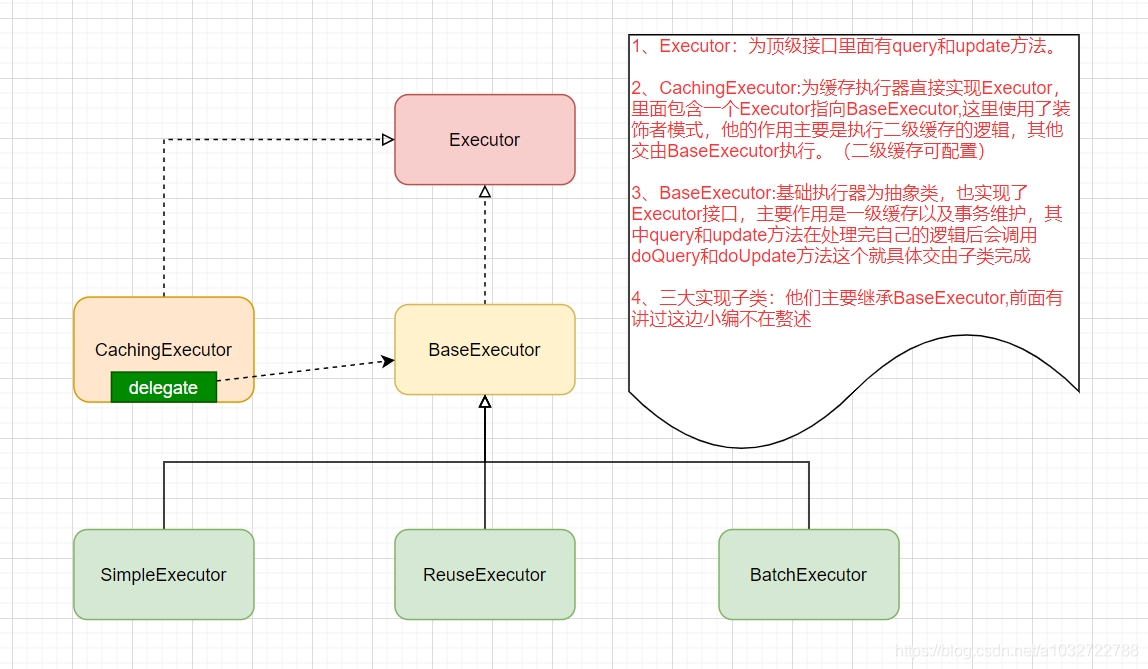
題外話:根據上圖大家可以自己了解一下各類圖箭頭和線的含義,
會話與執行器的結構關系
從Mybatis執行程序的圖中我們可以知道,SqlSession是呼叫Executor,從原始碼中可看成SqlSession實作中,其實包含一個Executor(二級快取),這樣整個流程就串起來了,那小編給大家講述一下流程呼叫,咱們以sqlsession的查詢方法的selectList方法為例(因為select方法最終都會調到selectList)
- SqlSession呼叫selectList方法,就呼叫到CachingExecutor中的query方法
- 如果配置了二級快取CachingExecutor先執行完自己的方法(是否有快取從快取里面取值操作),第一次快取沒有或沒開啟快取交由BaseExecutor 的query方法
- BaseExecutor方法執行完一級快取后,然后交由子類doQuery方法,咱們默認為SimpleExecutor執行器
- SimpleExecutor執行doQuery方法
當然如何創建會話以及如何將執行器包裝成CachingExecutor又是另一個話題了小編稍微講解一下:
- SqlSessionFactory.openSession,這里需要一個configuration
- 里面會有個方法configuration.newExecutor(tx, execType);這里會創建Executor
- 這里首先會根據executorType判斷用三大執行器的哪個默認為SimpleExecutor
- 再使用CachingExecutor 對其包裝:new CachingExecutor(executor)
會話與重用執行器以及批量執行器的關系
這里為什么要講這兩個執行器與會話的關系,小編主要為了說明一下statement 這里為jdbc的statement,
重用執行器
假如我們用會話呼叫兩個不同的方法,然后里面的sql是一樣的,這里說的一樣只是引數不同,那我們會預編譯幾次呢?下面代碼示例
public interface EmployeeMapper {
List<Employee> getAll();
@Select("select * from employee where id= #{id}")
List<Employee> getById(@Param("id") Long id);
@Select("select * from employee where id= #{id}")
List<Employee> selectById(@Param("id") Long id);
}
@Test
public void reuseExecutorTest() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//使用ExecutorType.REUSE設定重用執行器ReuseExecutor
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE);
try {
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
employeeMapper.selectById(1L);
employeeMapper.getById(2L);
} finally {
sqlSession.close();
}
}
列印結果
==> Preparing: select * from employee where id= ?
==> Parameters: 1(Long)
<== Columns: id, name
<== Row: 1, zhangsan
<== Total: 1
==> Parameters: 2(Long)
<== Columns: id, name
<== Row: 2, lisi
<== Total: 1
從代碼證明也就執行一次預編譯,會話期間內所有的相同sql都只預編譯一次即可
批量執行器
上面是重用執行器,預編譯一次,那我們試一下批量執行器,小編前面說過,批量執行器需要使用修改的方法,那我們換一下代碼:
public class DemoTest {
SqlSessionFactory sqlSessionFactory;
@Before
public void init() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void batchExecutorTest() {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH,true);
try {
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
employeeMapper.updateById("wangwu", 1L);
employeeMapper.updateById("zhaoliu",2L);
//需要走flushStatements才會提交,即便上面opensession中設定自動提交為true
List<BatchResult> batchResults = sqlSession.flushStatements();
System.out.println(batchResults.size());
} finally {
sqlSession.close();
}
}
}
public interface EmployeeMapper {
@Update("update employee set name = #{name} where id=#{id}")
void updateById(@Param("name")String name,@Param("id") Long id);
@Insert("insert into emplyee id = #{employee.id}, name=#{employee.name}")
void insertEmployee(@Param("employee") Employee employee);
}
執行結果
==> Preparing: update employee set name = ? where id=?
==> Parameters: wangwu(String), 1(Long)
==> Parameters: zhaoliu(String), 2(Long)
1
這邊statement預編譯一次即可
緊接著我們繼續修改一下測驗用例:
@Test
public void batchExecutorTest() {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH,true);
try {
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
//更新
employeeMapper.updateById("wangwu", 1L);
Employee employee = new Employee(3L,"tom");
Employee employee2 = new Employee(4L,"jerry");
//插入兩次
employeeMapper.insertEmployee(employee);
employeeMapper.insertEmployee(employee2);
//再次更新
employeeMapper.updateById("zhaoliu",2L);
List<BatchResult> batchResults = sqlSession.flushStatements();
System.out.println(batchResults.size());
} finally {
sqlSession.close();
}
}
列印結果
==> Preparing: update employee set name = ? where id=?
==> Parameters: wangwu(String), 1(Long)
==> Preparing: insert into employee (id,name) values (?, ?)
==> Parameters: 3(Long), tom(String)
==> Parameters: 4(Long), jerry(String)
==> Preparing: update employee set name = ? where id=?
==> Parameters: zhaoliu(String), 2(Long)
3
從上面可有看出,相同sql陳述句在一起的與分開的是不一樣的,只有連續相同的SQL陳述句并且相同的SQL映射宣告,才會重用Statement,并利用其批處理功能,否則會構建一個新的Satement然后在flushStatements() 時一次執行,這么做的原因是它要保證執行順序,跟呼叫順序一致性,
總結
今天小編講了mybatis的執行器,可以說執行器的設計相當不錯,他將執行器的共性抽象出來,并且使用裝飾者模式進一步加入了快取執行器,希望這次小編徹底講清楚了執行器的呼叫流程其分類和各個執行器的作用,下面小編會對mybatis的多級快取做分析,
對了這次小編并沒有貼出原始碼,也希望大家自己搭個demo框架,或者下載mybatis官方原始碼來除錯,mybatis原始碼基本無注釋,但是看起來簡單易懂,總而言之,大家需要自己看原始碼來梳理一遍,希望大家繼續支持小編,一起加油努力吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277008.html
標籤:其他