前言
大家好,我是囧輝,面試系列開篇:Java 基礎高頻面試題(2021年最新版),發表后受到不少同學的喜歡,
今天我們繼續下一個重要的面試內容:集合框架,HashMap 作為 Java 中最靚的仔,毋庸置疑將是本文的主角,

可能有些同學看過我之前的 HashMap 文章:面試阿里,HashMap 這一篇就夠了,會想:輝哥果然又頹廢了、墮落了,估計是將之前的內容就照搬過來水一篇,鄙視,取關,不看也罷,*()&*……&*,

你們不對勁,你輝哥是這種人?當然不是的,本文的 HashMap 部分在之前的基礎上進行了補充和完善,希望大家能看到完善的點,
最后,本文按 BAT 面試標準給出決議,希望在這金三銀四的日子里,祝你一臂之力,拿下大廠 Offer,
面試系列
我自己前前后后加起來總共應該參加了不下四五十次的面試,拿到過幾乎所有一線大廠的 offer:阿里、位元組、美團、快手、拼多多等等,
每次面試后我都會將面試的題目進行記錄,并整理成自己的題庫,最近我將這些題目整理出來,并按大廠的標準給出自己的決議,希望在這金三銀四的季節里,能助你一臂之力,
面試文章持續更新中...
| 內容 | 鏈接地址 |
|---|---|
| 面試經驗分享 | 921天,從小廠到入職阿里 |
| 兩年Java開發作業經驗面試總結 | |
| 4 年 Java 經驗,阿里網易拼多多面試總結、心得體會 | |
| 5 年 Java 經驗,位元組、美團、快手核心部門面試總結(真題決議) | |
| 復習2個月拿下美團offer,我都做了些啥 | |
| 如何準備好一場大廠面試 | |
| 簡歷 | 如何寫一份讓 HR 眼前一亮的簡歷(附模板) |
| Offer 選擇 | 跳槽,如何選擇一家公司 |
| Java 基礎 | Java 基礎高頻面試題(2021年最新版) |
| 一道有意思的“初始化”面試題 | |
| 集合(HashMap) | Java 集合框架高頻面試題(2021年最新版) |
| 面試阿里,HashMap 這一篇就夠了 | |
| 并發編程 | 面試必問的執行緒池,你懂了嗎? |
| 面試必問的CAS,你懂了嗎? | |
| MySQL | 面試必問的 MySQL,你懂了嗎? |
| MySQL 8.0 MVCC 核心原理決議(核心原始碼) | |
| Spring | 面試必問的 Spring,你懂了嗎? |
| Mybatis | 面試題:mybatis 中的 DAO 介面和 XML 檔案里的 SQL 是如何建立關系的? |
| Redis | 面試必問的快取使用:如何保證資料一致性、快取設計模式 |
| 面試必問的 Redis:Memcached VS Redis | |
| 面試必問的 Redis:高可用解決方案哨兵、集群 | |
| 面試必問的 Redis:主從復制 | |
| 面試必問的 Redis:RDB、AOF、混合持久化 | |
| 面試必問的 Redis:資料結構和基礎概念 | |
| JVM | Java虛擬機面試題精選(二) |
| Java虛擬機面試題精選(一) | |
| 分布式 | 面試必問的分布式鎖,你懂了嗎? |
| 演算法 | 位圖法:判斷一個數是否在40億個整數中? |
正文
1、介紹下 HashMap 的底層資料結構吧,
在 JDK 1.8,HashMap 底層是由 “陣列+鏈表+紅黑樹” 組成,如下圖所示,而在 JDK 1.8 之前是由 “陣列+鏈表” 組成,就是下圖去掉紅黑樹,
2、為什么使用“陣列+鏈表”?
使用 “陣列+鏈表” 是為了解決 hash 沖突的問題,
陣列和鏈表有如下特點:
陣列:查找容易,通過 index 快速定位;插入和洗掉困難,需要移動插入和洗掉位置之后的節點;
鏈表:查找困難,需要從頭結點或尾節點開始遍歷,直到尋找到目標節點;插入和洗掉容易,只需修改目標節點前后節點的 next 或 prev 屬性即可;
HashMap 巧妙的將陣列和鏈表結合在一起,發揮兩者各自的優勢,使用一種叫做 “拉鏈法” 的方式來解決哈希沖突,
首先通過 index 快速定位到索引位置,這邊利用了陣列的優點;然后遍歷鏈表找到節點,進行節點的新增/修改/洗掉操作,這邊利用了鏈表的優點,簡直,完美,

3、為什么要改成“陣列+鏈表+紅黑樹”?
通過上題可以看出,“陣列+鏈表” 已經充分發揮了這兩種資料結構的優點,是個很不錯的組合了,
但是這種組合仍然存在問題,就是在定位到索引位置后,需要先遍歷鏈表找到節點,這個地方如果鏈表很長的話,也就是 hash 沖突很嚴重的時候,會有查找性能問題,因此在 JDK1.8中,通過引入紅黑樹,來優化這個問題,
使用鏈表的查找性能是 O(n),而使用紅黑樹是 O(logn),
4、那在什么時候用鏈表?什么時候用紅黑樹?
對于插入,默認情況下是使用鏈表節點,當同一個索引位置的節點在新增后超過8個(閾值8):如果此時陣列長度大于等于 64,則會觸發鏈表節點轉紅黑樹節點(treeifyBin);而如果陣列長度小于64,則不會觸發鏈表轉紅黑樹,而是會進行擴容,因為此時的資料量還比較小,
對于移除,當同一個索引位置的節點在移除后達到 6 個(閾值6),并且該索引位置的節點為紅黑樹節點,會觸發紅黑樹節點轉鏈表節點(untreeify),
5、為什么鏈表轉紅黑樹的閾值是8?
我們平時在進行方案設計時,必須考慮的兩個很重要的因素是:時間和空間,對于 HashMap 也是同樣的道理,簡單來說,閾值為8是在時間和空間上權衡的結果(這 B 我裝定了),
紅黑樹節點大小約為鏈表節點的2倍,在節點太少時,紅黑樹的查找性能優勢并不明顯,付出2倍空間的代價作者覺得不值得,
理想情況下,使用隨機的哈希碼,節點分布在 hash 桶中的頻率遵循泊松分布,按照泊松分布的公式計算,鏈表中節點個數為8時的概率為 0.00000006(就我們這QPS不到10的系統,根本不可能遇到嘛),這個概率足夠低了,并且到8個節點時,紅黑樹的性能優勢也會開始展現出來,因此8是一個較合理的數字,
6、那為什么轉回鏈表節點是用的6而不是復用8?
如果我們設定節點多于8個轉紅黑樹,少于8個就馬上轉鏈表,當節點個數在8徘徊時,就會頻繁進行紅黑樹和鏈表的轉換,造成性能的損耗,
7、HashMap 有哪些重要屬性?分別用于做什么的?
除了用來存盤我們的節點 table 陣列外,HashMap 還有以下幾個重要屬性:
1)size:HashMap 已經存盤的節點個數;
2)threshold:1)擴容閾值(主要),當 HashMap 的個數達到該值,觸發擴容,2)初始化時的容量,在我們新建 HashMap 物件時, threshold 還會被用來存初始化時的容量,HashMap 直到我們第一次插入節點時,才會對 table 進行初始化,避免不必要的空間浪費,
3)loadFactor:負載因子,擴容閾值 = 容量 * 負載因子,
8、HashMap 的默認初始容量是多少?HashMap 的容量有什么限制嗎?
默認初始容量是16,HashMap 的容量必須是2的N次方,HashMap 會根據我們傳入的容量計算一個“大于等于該容量的最小的 2 的 N 次方”,例如傳 16,容量為16;傳17,容量為32,
9、“大于等于該容量的最小的2的N次方”是怎么算的?
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}我們先不看第一行“int n = cap - 1”,先看下面的5行計算,
|=(或等于):這個符號比較少見,但是“+=”應該都見過,看到這你應該明白了,例如:a |= b ,可以轉成:a = a | b,
>>>(無符號右移):例如 a >>> b 指的是將 a 向右移動 b 指定的位數,右移后左邊空出的位用零來填充,移出右邊的位被丟棄,
假設 n 的值為 0010 0001,則該計算如下圖:
相信你應該看出來,這5個公式會通過最高位的1,拿到2個1、4個1、8個1、16個1、32個1,當然,有多少個1,取決于我們的入參有多大,但我們肯定的是經過這5個計算,得到的值是一個低位全是1的值,最后回傳的時候 +1,則會得到1個比n 大的 2 的N次方,
這時再看開頭的 cap - 1 就很簡單了,這是為了處理 cap 本身就是 2 的N次方的情況,
計算機底層是二進制的,移位和或運算是非常快的,所以這個方法的效率很高,
PS:這是 HashMap 中我個人最喜歡的設計,非常巧妙,
10、HashMap 的容量必須是 2 的 N 次方,這是為什么?
核心目的是:實作節點均勻分布,減少 hash 沖突,
計算索引位置的公式為:(n - 1) & hash,當 n 為 2 的 N 次方時,n - 1 為低位全是 1 的值,此時任何值跟 n - 1 進行 & 運算的結果為該值的低 N 位,達到了和取模同樣的效果,實作了均勻分布,實際上,這個設計就是基于公式:x mod 2^n = x & (2^n - 1),因為 & 運算比 mod 具有更高的效率,
如下圖,當 n 不為 2 的 N 次方時,hash 沖突的概率明顯增大,
11、HashMap 的插入流程是怎么樣的?
真香,建議收藏,
12、插入流程的圖里剛開始有個計算 key 的 hash 值,是怎么設計的?
原始碼如下:拿到 key 的 hashCode,并將 hashCode 的高16位和 hashCode 進行異或(XOR)運算,得到最終的 hash 值,
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
13、為什么要將 hashCode 的高16位參與運算?
主要是為了在 table 的長度較小的時候,讓高位也參與運算,并且不會有太大的開銷,
例如下圖,如果高位不參與運算,由于 n - 1 是 0000 0111,所以結果只取決于 hash 值的低3位,無論高位怎么變化,結果都是一樣的,
如果我們將高位參與運算,則索引計算結果就不會僅取決于低位,
14、擴容(resize)流程介紹下?
真香,建議收藏,
15、紅黑樹和鏈表都是通過 e.hash & oldCap == 0 來定位在新表的索引位置,這是為什么?
請看對下面的例子,
擴容前 table 的容量為16,a 節點和 b 節點在擴容前處于同一索引位置,
擴容后,table 長度為32,新表的 n - 1 只比老表的 n - 1 在高位多了一個1(圖中標紅),
因為 2 個節點在老表是同一個索引位置,因此計算新表的索引位置時,只取決于新表在高位多出來的這一位(圖中標紅),而這一位的值剛好等于 oldCap,
因為只取決于這一位,所以只會存在兩種情況:1) (e.hash & oldCap) == 0 ,則新表索引位置為“原索引位置” ;2)(e.hash & oldCap) != 0,則新表索引位置為“原索引 + oldCap 位置”,
16、HashMap 是執行緒安全的嗎?
不是,HashMap 在并發下存在資料覆寫、遍歷的同時進行修改會拋出 ConcurrentModificationException 例外等問題,JDK 1.8 之前還存在死回圈問題,
17、介紹一下死回圈問題?
導致死回圈的根本原因是 JDK 1.7 擴容采用的是“頭插法”,會導致同一索引位置的節點在擴容后順序反掉,在并發插入觸發擴容時形成環,從而產生死回圈,
而 JDK 1.8 之后采用的是“尾插法”,擴容后節點順序不會反掉,不存在死回圈問題,
JDK 1.7.0 的擴容代碼如下,用例子來看會好理解點,
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}PS:這個流程較難理解,建議對著代碼自己模擬走一遍,
例子:我們有1個容量為2的 HashMap,loadFactor=0.75,此時執行緒1和執行緒2 同時往該 HashMap 插入一個資料,都觸發了擴容流程,接著有以下流程,
1)在2個執行緒都插入節點,觸發擴容流程之前,此時的結構如下圖,
2)執行緒1進行擴容,執行到代碼:Entry<K,V> next = e.next 后被調度掛起,此時的結構如下圖,
3)執行緒1被掛起后,執行緒2進入擴容流程,并走完整個擴容流程,此時的結構如下圖,
由于兩個執行緒操作的是同一個 table,所以該圖又可以畫成如下圖,
4)執行緒1恢復后,繼續走完第一次的回圈流程,此時的結構如下圖,
5)執行緒1繼續走完第二次回圈,此時的結構如下圖,
6)執行緒1繼續執行第三次回圈,執行到 e.next = newTable[i] 時形成環,執行完第三次回圈的結構如下圖,
如果此時執行緒1呼叫 map.get(11) ,悲劇就出現了——無限回圈,
18、總結下 JDK 1.8 主要進行了哪些優化?
JDK 1.8 的主要優化剛才我們都聊過了,主要有以下幾點:
1)底層資料結構從“陣列+鏈表”改成“陣列+鏈表+紅黑樹”,主要是優化了 hash 沖突較嚴重時,鏈表過長的查找性能:O(n) -> O(logn),
2)計算 table 初始容量的方式發生了改變,老的方式是從1開始不斷向左進行移位運算,直到找到大于等于入參容量的值;新的方式則是通過“5個移位+或等于運算”來計算,
// JDK 1.7.0
public HashMap(int initialCapacity, float loadFactor) {
// 省略
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// ... 省略
}
// JDK 1.8.0_191
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}3)優化了 hash 值的計算方式,老的通過一頓瞎JB操作,新的只是簡單的讓高16位參與了運算,
4)擴容時插入方式從“頭插法”改成“尾插法”,避免了并發下的死回圈,
5)擴容時計算節點在新表的索引位置方式從“h & (length-1)”改成“hash & oldCap”,性能可能提升不大,但設計更巧妙、更優雅,
19、Hashtable 是怎么加鎖的 ?
Hashtable 通過 synchronized 修飾方法來加鎖,從而實作執行緒安全,
public synchronized V get(Object key) {
// ...
}
public synchronized V put(K key, V value) {
// ...
}
20、LinkedHashMap 和 TreeMap 排序的區別?
LinkedHashMap 和 TreeMap 都是提供了排序支持的 Map,區別在于支持的排序方式不同:
LinkedHashMap:保存了資料的插入順序,也可以通過引數設定,保存資料的訪問順序,
TreeMap:底層是紅黑樹實作,可以指定比較器(Comparator 比較器),通過重寫 compare 方法來自定義排序;如果沒有指定比較器,TreeMap 默認是按 Key 的升序排序(如果 key 沒有實作 Comparable介面,則會拋例外),
21、HashMap 和 Hashtable 的區別?
HashMap 允許 key 和 value 為 null,Hashtable 不允許,
HashMap 的默認初始容量為 16,Hashtable 為 11,
HashMap 的擴容為原來的 2 倍,Hashtable 的擴容為原來的 2 倍加 1,
HashMap 是非執行緒安全的,Hashtable 是執行緒安全的,使用 synchronized 修飾方法實作執行緒安全,
HashMap 的 hash 值重新計算過,Hashtable 直接使用 hashCode,
HashMap 去掉了 Hashtable 中的 contains 方法,
HashMap 繼承自 AbstractMap 類,Hashtable 繼承自 Dictionary 類,
HashMap 的性能比 Hashtable 高,因為 Hashtable 使用 synchronized 實作執行緒安全,還有就是 HashMap 1.8 之后底層資料結構優化成 “陣列+鏈表+紅黑樹”,在極端情況下也能提升性能,
22、介紹下 ConcurrenHashMap,要講出 1.7 和 1.8 的區別?
ConcurrentHashMap 是 HashMap 的執行緒安全版本,和 HashMap 一樣,在JDK 1.8 中進行了較大的優化,
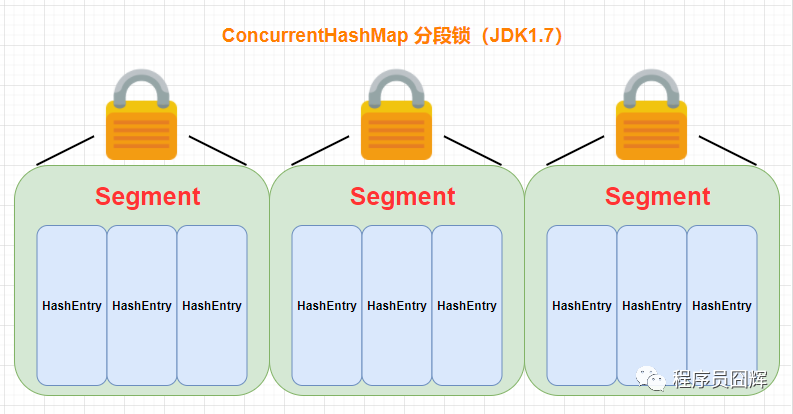
JDK1.7:底層結構為:分段的陣列+鏈表;實作執行緒安全的方式:分段鎖(Segment,繼承了ReentrantLock),如下圖所示,
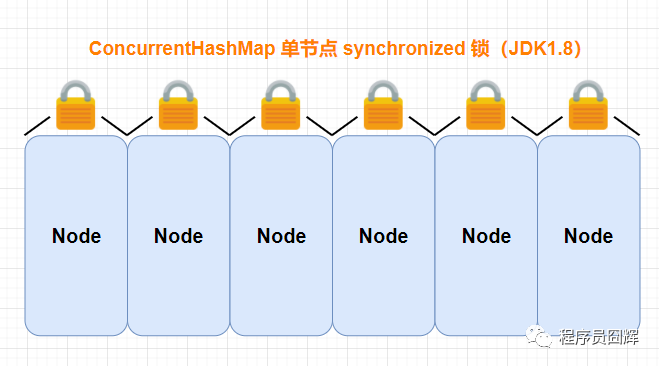
JDK1.8:底層結構為:陣列+鏈表+紅黑樹;實作執行緒安全的方式:CAS + Synchronized
區別:
1、JDK1.8 中降低鎖的粒度,JDK1.7 版本鎖的粒度是基于 Segment 的,包含多個節點(HashEntry),而 JDK1.8 鎖的粒度就是單節點(Node),
2、JDK1.8 版本的資料結構變得更加簡單,使得操作也更加清晰流暢,因為已經使用 synchronized 來進行同步,所以不需要分段鎖的概念,也就不需要 Segment 這種資料結構了,當前還保留僅為了兼容,
3、JDK1.8 使用紅黑樹來優化鏈表,跟 HashMap 一樣,優化了極端情況下,鏈表過長帶來的性能問題,
4、JDK1.8 使用內置鎖 synchronized 來代替重入鎖 ReentrantLock,synchronized 是官方一直在不斷優化的,現在性能已經比較可觀,也是官方推薦使用的加鎖方式,
23、ConcurrentHashMap 的并發擴容
ConcurrentHashMap 在擴容時會計算出一個步長(stride),最小值是16,然后給當前擴容執行緒分配“一個步長”的節點數,例如16個,讓該執行緒去對這16個節點進行擴容操作(將節點從老表移動到新表),
如果在擴容結束前又來一個執行緒,則也會給該執行緒分配一個步長的節點數讓該執行緒去擴容,依次類推,以達到多執行緒并發擴容的效果,
例如:64要擴容到128,步長為16,則第一個執行緒會負責第113(索引112)~128(索引127)的節點,第二個執行緒會負責第97(索引96)~112(索引111)的節點,依次類推,
具體處理(該流程后續可能會替換成流程圖):
1)如果索引位置上為null,則直接使用 CAS 將索引位置賦值為 ForwardingNode(hash值為-1),表示已經處理過,這個也是觸發并發擴容的關鍵點,
2)如果索引位置的節點 f 的 hash 值為 MOVED(-1),則代表節點 f 是 ForwardingNode 節點,只有 ForwardingNode 的 hash 值為 -1,意味著該節點已經處理過了,則跳過該節點繼續往下處理,
3).否則,對索引位置的節點 f 物件使用 synchronized 進行加鎖,遍歷鏈表或紅黑樹,如果找到 key 和入參相同的,則替換掉 value 值;如果沒找到,則新增一個節點,如果是鏈表,同時判斷是否需要轉紅黑樹,處理完在索引位置的節點后,會將該索引位置賦值為 ForwardingNode,表示該位置已經處理過,
ForwardingNode:一個特殊的 Node 節點,hash 值為-1(原始碼中定義成 MOVED),其中存盤 nextTable 的參考, 只有發生擴容的時候,ForwardingNode才會發揮作用,作為一個占位符放在 table 中表示當前節點已經被處理(或則為 null ),
24、ConcurrenHashMap 和 Hashtable 的區別?
1)底層資料結構:
ConcurrentHashMap:1)JDK1.7 采用 分段的陣列+鏈表 實作;2)JDK1.8 采用 陣列+鏈表+紅黑樹,跟 JDK1.8 的 HashMap 的底層資料結構一樣,
Hashtable: 采用 陣列+鏈表 的形式,跟 JDK1.8 之前的 HashMap 的底層資料結構類似,
2)實作執行緒安全的方式(重要):
ConcurrentHashMap:
1)JDK1.7:使用分段鎖(Segment)保證執行緒安全,每個分段(Segment)包含若干個 HashEntry,當并發訪問不同分段的資料時,不會產生鎖競爭,從而提升并發性能,
2)JDK1.8:使用 synchronized + CAS 的方式保證執行緒安全,每次只鎖一個節點(Node),進一步降低鎖粒度,降低鎖沖突的概率,從而提升并發性能,
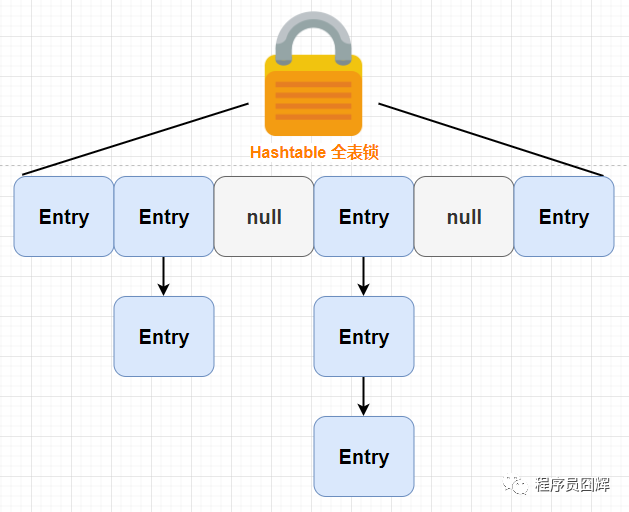
Hashtable:使用 synchronized 修飾方法來保證執行緒安全,每個實體物件只有一把鎖,并發性能較低,相當于串行訪問,
25、ConcurrentHashMap 的 size() 方法怎么實作的?
JDK 1.7:先嘗試在不加鎖的情況下嘗進行統計 size,最多統計3次,如果連續兩次統計之間沒有任何對 segment 的修改操作,則回傳統計結果,否則,對每個segment 進行加鎖,然后統計出結果,回傳結果,
JDK 1.8:直接統計 baseCount 和 counterCells 的 value 值,回傳的是一個近似值,如果有并發的插入或洗掉,實際的數量可能會有所不同,
該統計方式改編自 LongAdder 和 Striped64,這兩個類在 JDK 1.8 中被引入,出自并發大神 Doug Lea 之手,是原子類(AtomicLong 等)的優化版本,主要優化了在并發競爭下,AtomicLong 由于 CAS 失敗的帶來的性能損耗,
值得注意的是,JDK1.8中,提供了另一個統計的方法 mappingCount,實作和 size 一樣,只是回傳的型別改成了 long,這也是官方推薦的方式,
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
// 一個ConcurrentHashMap包含的映射數量可能超過int上限,
// 所以應該使用這個方法來代替size()
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
26、比較下常見的幾種 Map,在使用時怎么選擇?
30、ArrayList 和 Vector 的區別,
Vector 和 ArrayList 的實作幾乎是一樣的,區別在于:
1)最重要的的區別: Vector 在方法上使用了 synchronized 來保證執行緒安全,同時由于這個原因,在性能上 ArrayList 會有更好的表現,
2) Vector 擴容后容量默認變為原來 2 倍,而 ArrayList 為原來的 1.5 倍,
有類似關系的還有:StringBuilder 和 StringBuffer、HashMap 和 Hashtable,
31、ArrayList 和 LinkedList 的區別?
1、ArrayList 底層基于動態陣列實作,LinkedList 底層基于雙向鏈表實作,
2、對于隨機訪問(按 index 訪問,get/set方法):ArrayList 通過 index 直接定位到陣列對應位置的節點,而 LinkedList需要從頭結點或尾節點開始遍歷,直到尋找到目標節點,因此在效率上 ArrayList 優于 LinkedList,
3、對于隨機插入和洗掉:ArrayList 需要移動目標節點后面的節點(使用System.arraycopy 方法移動節點),而 LinkedList 只需修改目標節點前后節點的 next 或 prev 屬性即可,因此在效率上 LinkedList 優于 ArrayList,
4、對于順序插入和洗掉:由于 ArrayList 不需要移動節點,因此在效率上比 LinkedList 更好,這也是為什么在實際使用中 ArrayList 更多,因為大部分情況下我們的使用都是順序插入,
5、兩者都不是執行緒安全的,
6、記憶體空間占用: ArrayList 的空 間浪費主要體現在在 list 串列的結尾會預留一定的容量空間,而 LinkedList 的空間花費則體現在它的每一個元素都需要消耗比 ArrayList 更多的空間(因為要存放直接后繼和直接前驅以及資料),
32、HashSet 是如何保證不重復的?
HashSet 底層使用 HashMap 來實作,見下面的原始碼,元素放在 HashMap 的 key 里,value 為固定的 Object 物件,當 add 時呼叫 HashMap 的 put 方法,如果元素不存在,則回傳 null 表示 add 成功,否則 add 失敗,
由于 HashMap 的 Key 值本身就不允許重復,HashSet 正好利用 HashMap 中 key 不重復的特性來校驗重復元素,簡直太妙了,
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
33、TreeSet 清楚嗎?能詳細說下嗎?
“TreeSet 和 TreeMap 的關系” 和上面說的 “HashSet 和 HashMap 的關系” 幾乎一致,
TreeSet 底層默認使用 TreeMap 來實作,而 TreeMap 通過實作 Comparator(或 Key 實作 Comparable)來實作自定義順序,
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
34、介紹下 CopyOnWriteArrayList?
CopyOnWriteArrayList 是 ArrayList 的執行緒安全版本,也是大名鼎鼎的 copy-on-write(COW,寫時復制)的一種實作,
在讀操作時不加鎖,跟ArrayList類似;在寫操作時,復制出一個新的陣列,在新陣列上進行操作,操作完了,將底層陣列指標指向新陣列,適合使用在讀多寫少的場景,
例如 add(E e) 方法的操作流程如下:使用 ReentrantLock 加鎖,拿到原陣列的length,使用 Arrays.copyOf 方法從原陣列復制一個新的陣列(length+1),將要添加的元素放到新陣列的下標length位置,最后將底層陣列指標指向新陣列,
35、Comparable 和 Comparator 比較?
1、Comparable 是排序介面,一個類實作了 Comparable介面,意味著“該類支持排序”,Comparator 是比較器,我們可以實作該介面,自定義比較演算法,創建一個 “該類的比較器” 來進行排序,
2、Comparable 相當于“內部比較器”,而 Comparator 相當于“外部比較器”,
3、Comparable 的耦合性更強,Comparator 的靈活性和擴展性更優,
4、Comparable 可以用作類的默認排序方法,而 Comparator 則用于默認排序不滿足時,提供自定義排序,
耦合性和擴展性的問題,舉個簡單的例子:
當實作類實作了 Comparable 介面,但是已有的 compareTo 方法的比較演算法不滿足當前需求,此時如果想對兩個類進行比較,有兩種辦法:
1)修改實作類的源代碼,修改 compareTo 方法,但是這明顯不是一個好方案,因為這個實作類的默認比較演算法可能已經在其他地方使用了,此時如果修改可能會造成影響,所以一般不會這么做,
2)實作 Comparator 介面,自定義一個比較器,該方案會更優,自定義的比較器只用于當前邏輯,其他已有的邏輯不受影響,
36、List、Set、Map三者的區別?
List(對付順序的好幫手): 存盤的物件是可重復的、有序的,
Set(注重獨一無二的性質):存盤的物件是不可重復的、無序的,
Map(用 Key 來搜索的專業戶): 存盤鍵值對(key-value),不能包含重復的鍵(key),每個鍵只能映射到一個值,
37、Map、List、Set 分別說下你了解到它們有的執行緒安全類和執行緒不安全的類?
Map
執行緒安全:CocurrentHashMap、Hashtable
執行緒不安全:HashMap、LinkedHashMap、TreeMap、WeakHashMap
List
執行緒安全:Vector(執行緒安全版的ArrayList)、Stack(繼承Vector,增加pop、push方法)、CopyOnWriteArrayList
執行緒不安全:ArrayList、LinkedList
Set
執行緒安全:CopyOnWriteArraySet(底層使用CopyOnWriteArrayList,通過在插入前判斷是否存在實作 Set 不重復的效果)
執行緒不安全:HashSet(基于 HashMap)、LinkedHashSet(基于 LinkedHashMap)、TreeSet(基于 TreeMap)、EnumSet
38、Collection 與 Collections的區別
Collection:集合類的一個頂級介面,提供了對集合物件進行基本操作的通用介面方法,Collection介面的意義是為各種具體的集合提供了最大化的統一操作方式,常見的 List 與 Set 就是直接繼承 Collection 介面,
Collections:集合類的一個工具類/幫助類,提供了一系列靜態方法,用于對集合中元素進行排序、搜索以及執行緒安全等各種操作,
最后
面試系列持續創作中,有疑問的地方歡迎留言,我看到后都會回復,
原創不易,如果你覺得本文寫的還不錯,對你有幫助,請通過【點贊】和【關注】讓我知道,支持我寫出更好的文章,
我是囧輝,我的目標是幫助大家拿到心儀的大廠 Offer,我們下期見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277170.html
標籤:其他