三天爆肝快速入門機器學習【第三天】
- 線性回歸
- 過擬合和欠擬合
- 嶺回歸
- 邏輯回歸
前言:這個系列終于寫完了,只寫了三篇,但是基礎知識基本都寫了,但是閱讀量都不高,可能也是自己初次寫這種系列的沒什么經驗,排版內容都有很大改進的空間,后面會出基礎內容的系列和面試題這塊的講解,主要更新這兩個內容,同時也會出視頻講解,這樣的話比看文章更容易理解,碼字不易,希望各位朋友給個三連,精彩內容持續更新中.
線性回歸
優點
解決回歸問題
思想簡單,實作容易
許多強大的非線性模型的基礎(多項式回歸,邏輯回歸,SVM)
結果具有很好的可解釋性
蘊含機器學習中的很多重要思想

上一篇講K近鄰演算法時,分類二維平面圖橫軸縱軸都是樣本的特征
上圖只有橫軸是樣本的特征,縱軸是樣本的輸出標記
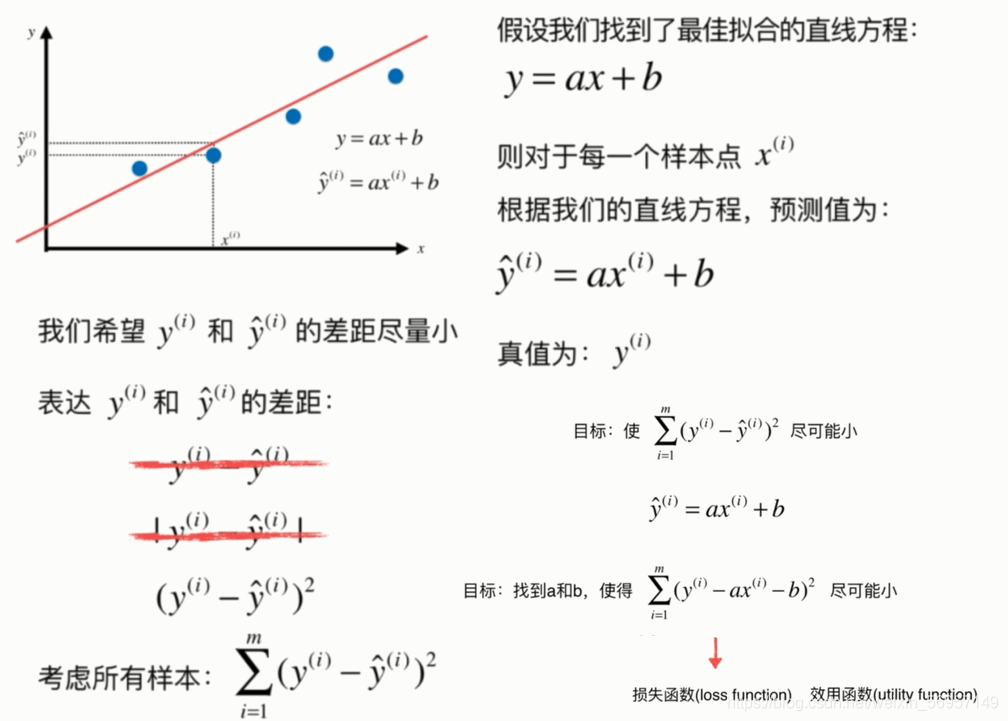
通過分析問題,確定問題的損失函式或者效用函式;
通過最優化損失函式或者效用函式,獲得機器學習的模型,
近乎所有引數學習演算法都是這樣的套路(多項式回歸,邏輯回歸,SVM,神經網路)->學科:最優化原理->分支:凸優化
最小二乘法
典型的最小二乘法問題:最小化誤差的平方
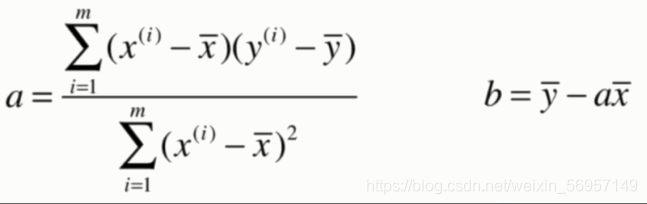

簡單來說,就是求函式的極值,對函式各個未知分量求導,讓導數等于零

向量化
提升大概五十倍的性能
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x,y in zip(x_train,y_train):
num += (x-x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num /d
self.b_ = y_mean - self.a_*x_mean
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean)
d = (x_train - x_mean).dot(x_train - x_mean)
d = 0.0
self.a_ = num /d
self.b_ = y_mean - self.a_*x_mean
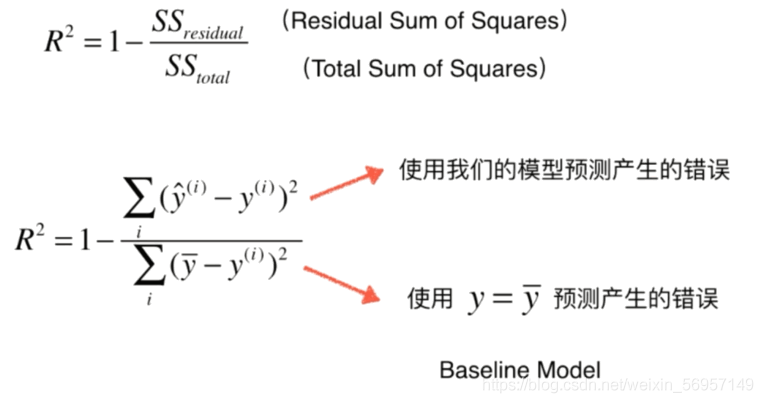
衡量指標 MSE,RMS,MAE



最好的指標 R Squared

多元線性回歸
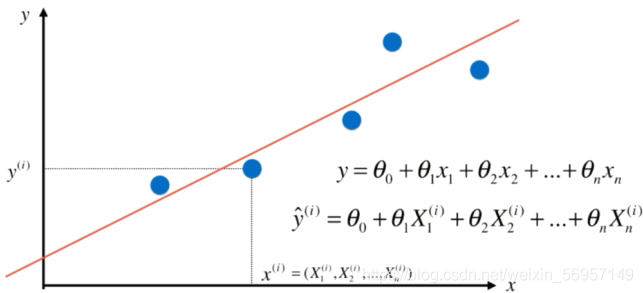
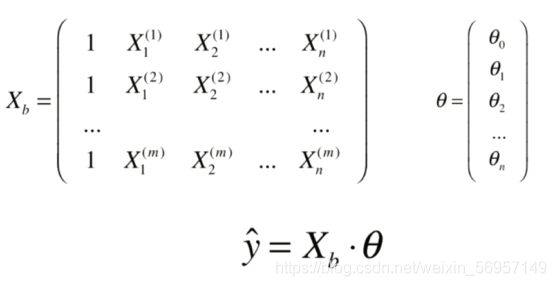

問題:時間復雜度高:O(n3)(優化O(n2.4)
優點:不需要對資料做歸一化處理


過擬合和欠擬合
1 過擬合
過擬合的表現是模型在訓練集上表現很好,在測驗集上表現不好,樣本集和整體資料集之間存在偏差,而過于復雜的模型可能對這個偏差也會進行擬合,
1.1 過擬合的原因
訓練樣本不足或缺乏代表性,沒有涵蓋所有資料型別,
訓練資料中噪聲過大,
模型過于復雜,
1.2 解決過擬合的方法
正則化,包括L1正則化、L2正則化
Dropout
Batch Normalization
early stopping
data augmentation
從簡單的模型開始,而不是一開始就選擇比較復雜的模型,
增加訓練樣本,
使用bagging方法,
降維,
2 欠擬合
欠擬合的表現是模型在訓練集上的表現差,沒有學習到資料的規律,
2.1 欠擬合的原因
模型過于簡單,
特征數目太少,

2.2 解決欠擬合的方法
增加更多的特征,
增大模型復雜度,
使用boosting方法,
3 偏差和方差
可以從偏差和方差的角度理解過擬合和欠擬合,模型的泛化誤差可以分為偏差和方差,設特征向量為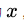
,目標函式為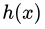
,擬合出來的函式為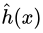
3.1 偏差(bias)
偏差是模型本身導致的誤差,即錯誤的模型假設導致的誤差,它表示預測結果的期望和真實值之間的差距,描述了演算法的擬合能力,
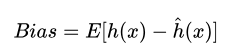
高偏差意味著模型的輸出值和真實值之間的差距很大,故而會導致欠擬合問題,
3.2 方差(variance)
方差的出現是由于訓練集中存在的一定程度的波動,可以理解為預測結果的波動程度,描述了資料擾動帶來的影響,
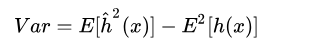
高方差意味著模型會對訓練集中存在的噪聲進行擬合,從而出現過擬合,
3.3 偏差-方差窘境
一般來說,偏差和方差是有沖突的,當模型的擬合能力不足時,訓練資料的擾動不足以使模型的性能發生明顯變化,此時偏差在總體誤差中占據主導;隨著模型擬合能力的上升,偏差越來越小,訓練資料中存在的擾動會被模型學習到,故而方差逐漸占據主導,
3.4 方差和偏差的折中
模型的總體誤差是偏差平方、方差和噪聲之和(偏差-方差分解):
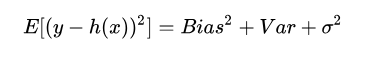
如果模型過于簡單,一般會有大的偏差;如果模型過于復雜,會有大的方差和小的偏差,因此,一般需要在偏差和方差之間進行折中,一般情況下,交叉驗證有助于這種折中,

嶺回歸
嶺回歸的概念
在進行特征選擇時,一般有三種方式:
子集選擇
收縮方式(Shrinkage method),又稱為正則化(Regularization),主要包括嶺回歸個lasso回歸,
維數縮減
嶺回歸(Ridge Regression)是在平方誤差的基礎上增加正則項
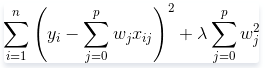
通過確定
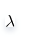
的值可以使得在方差和偏差之間達到平衡:隨著
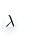
的增大,模型方差減小而偏差增大,
對
求導,結果為
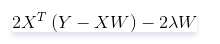
令其為0,可求得
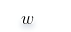
的值:
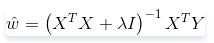
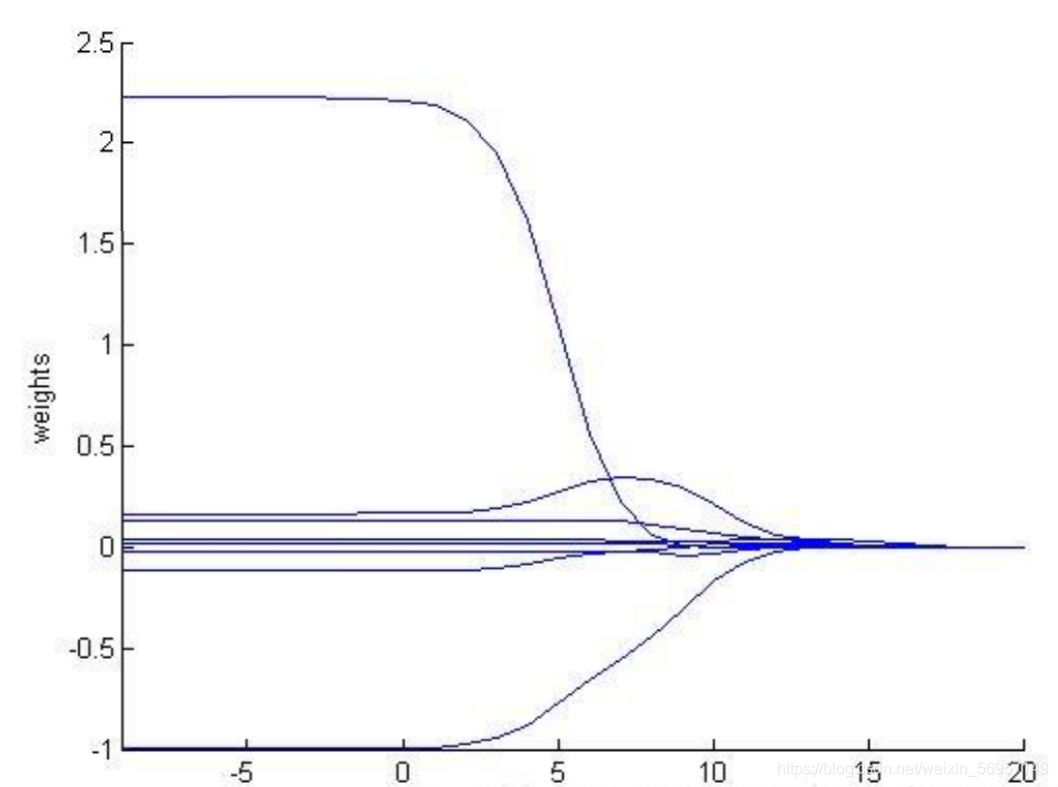
三、實驗的程序
我們去探討一下取不同的
對整個模型的影響,
MATLAB代碼
主函式
%% 嶺回歸(Ridge Regression)
%匯入資料
data = load('abalone.txt');
[m,n] = size(data);
dataX = data(:,1:8);%特征
dataY = data(:,9);%標簽
%標準化
yMeans = mean(dataY);
for i = 1:m
yMat(i,:) = dataY(i,:)-yMeans;
end
xMeans = mean(dataX);
xVars = var(dataX);
for i = 1:m
xMat(i,:) = (dataX(i,:) - xMeans)./xVars;
end
% 運算30次
testNum = 30;
weights = zeros(testNum, n-1);
for i = 1:testNum
w = ridgeRegression(xMat, yMat, exp(i-10));
weights(i,:) = w';
end
% 畫出隨著引數lam
hold on
axis([-9 20 -1.0 2.5]);
xlabel log(lam);
ylabel weights;
for i = 1:n-1
x = -9:20;
y(1,:) = weights(:,i)';
plot(x,y);
end
嶺回歸求回歸系數的函式
function [ w ] = ridgeRegression( x, y, lam )
xTx = x'*x;
[m,n] = size(xTx);
temp = xTx + eye(m,n)*lam;
if det(temp) == 0
disp('This matrix is singular, cannot do inverse');
end
w = temp^(-1)*x'*y;
end
邏輯回歸
邏輯回歸將樣本特征和樣本發生的概率聯系起來,用于解決分類問題,
Sigmoid 函式
在最簡單的二分類中,邏輯回歸里樣本發生的概率的值域為 [0, 1],對于線性回歸
y
^
=
θ
T
?
x
b
\hat{y} = \theta^T·x_b
y^?=θT?xb?,為了將
y
^
\hat y
y^? 映射到值域 [0, 1] 中,引入了
σ
\sigma
σ 函式得到了概率函式
p
^
\hat p
p^?,即:
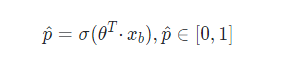
Sigmoid 函式 σ \sigma σ 表示為: σ ( t ) = 1 1 + e ? t \sigma(t)=\frac{1}{1+e^{-t}} σ(t)=1+e?t1?,圖示如下:
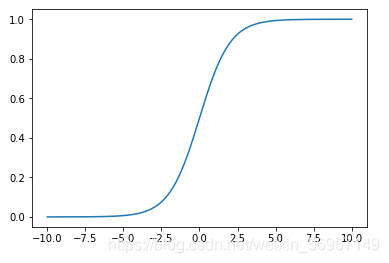
當 t > 0 時, σ \sigma σ > 0.5;當 t < 0 時, σ \sigma σ < 0.5,因此可對二分類的分類方式為:
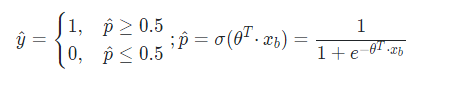
損失函式
如果實際的分類為1,p 越小時,損失越大;如果實際的分類為0,p 越大時,損失越大,引入 log 函式表示則為:
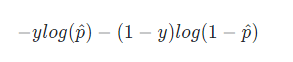
當 y=0 時,損失為 ? l o g ( 1 ? p ^ ) -log(1-\hat p) ?log(1?p^?);當 y=1 時,損失為 ? l o g ( p ^ ) -log(\hat p) ?log(p^?),
對于有 m 樣本的資料集 (X, y),損失函式為:
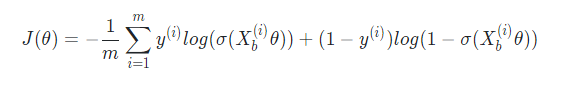
其中: X b ( i ) = ( 1 , x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) ) X_b^{(i)} = (1,x_{1}^{(i)},x_{2}^{(i)},...,x_{n}^{(i)}) Xb(i)?=(1,x1(i)?,x2(i)?,...,xn(i)?); θ = ( θ 0 , θ 1 , θ 2 , . . . , θ n ) T \theta = (\theta_{0}, \theta_{1}, \theta_{2},..., \theta_{n})^T θ=(θ0?,θ1?,θ2?,...,θn?)T,
損失函式的梯度
為了得到在損失盡可能的小的情況下的
θ
\theta
θ,可以對
J
(
θ
)
J(\theta)
J(θ) 使用梯度下降法,結果為:
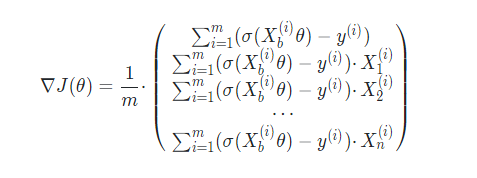
略去了公式的推導程序,
進行向量化處理后結果為:
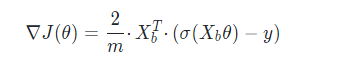

實作二分類邏輯回歸演算法
使用 Scikit Learn 的規范將邏輯回歸的程序封裝到 LogisticRegression 類中,
init() 方法首先初始化邏輯回歸模型,theta 表示 θ \theta θ,interception 表示截距,chef_ 表示回歸模型中自變數的系數:
class LogisticRegression:
def __init__(self):
self.coef_ = None
self.interceiption_ = None
self._theta = None
_sigmoid() 方法實作 Sigmoid 函式:
def _sigmoid(self, t):
return 1 / (1 + np.exp(-t))
fit() 方法根據訓練資料集訓練模型,J() 方法計算損失 J θ J\theta Jθ,dJ() 方法計算損失函式的梯度 ? J ( θ ) \nabla J(\theta) ?J(θ),gradient_descent() 方法就是梯度下降的程序,X_b 表示添加了 x 0 ( i ) ≡ 1 x_{0}^{(i)}\equiv1 x0(i)?≡1 的樣本特征資料:
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
def J(theta, X_b, y):
y_hat = self._sigmoid(X_b.dot(theta))
try:
return - np.sum(y * np.log(y_hat) + (1 - y) * np.log(1- y_hat) ** 2) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) /len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=n_iters, epsilon=1e-8):
theta = initial_theta
i_ters = 0
while i_ters < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_ters += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
predict_proba() 將傳入的測驗資料與訓練好模型后的 θ \theta θ 經過計算后回傳該測驗資料的概率:
def predict_proba(self, X_predict):
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return self._sigmoid(X_b.dot(self._theta))
predict() 方法將經過 predict_proba() 方法得到的測驗資料的概率以 0.5 為界轉換成類別(0或1):
def predict(self, X_predict):
proba = self.predict_proba(X_predict)
return np.array(proba >= 0.5, dtype='int')
score() 將測驗資料集的預測分類與實際分類進行比較計算模型準確度:
def score(self, X_test, y_test):
y_predict = self.predict(X_test)
return sum(y_predict == y_test) / len(y_test)
決策邊界
對于
p
^
=
σ
(
θ
T
?
x
b
)
=
1
1
+
e
?
θ
T
?
x
b
\hat p=\sigma(\theta^T·x_b)=\frac{1}{1+e^{-\theta^T·x_b}}
p^?=σ(θT?xb?)=1+e?θT?xb?1?,要使
p
^
=
0.5
\hat p=0.5
p^?=0.5 則
θ
T
?
x
b
=
0
\theta^T·x_b=0
θT?xb?=0,這就是決策邊界,
假設 X 資料集只有兩個特征,則由 θ 0 + θ 1 x 1 + θ 2 x 2 = 0 \theta_0+\theta_1x_1+\theta_2x_2=0 θ0?+θ1?x1?+θ2?x2?=0 得到 x 2 x_2 x2? 和 x 1 x_1 x1? 的關系為:
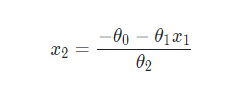
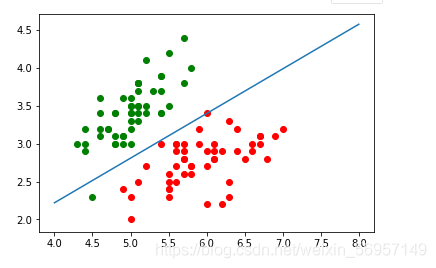
如圖所示,圖中的點為只有兩個特征的資料,縱軸為特征 x 2 x_2 x2?,橫軸為特征 x 1 x_1 x1?,梯度下降法得到的 θ \theta θ 與上面公式計算后的決策邊界即為圖中斜線:
邏輯回歸中使用多項式特征
對于多項式回歸,如對
y
=
x
1
2
+
x
2
2
?
r
y=x_1^2+x_2^2-r
y=x12?+x22??r 進行邏輯回歸,可以將
x
1
2
x_1^2
x12? 看作一個特征
z
1
z_1
z1?,將
x
2
2
x_2^2
x22? 看作一個特征
z
2
z_2
z2?,Scikit Learn 提供了 PolynomialFeatures 可以方便的進行轉換,
舉例如下,首先準備資料:
import numpy as np
X = np.random.normal(0, 1, size=(200, 2))
y = np.array(X[:, 0] ** 2 + X[:, 1] ** 2 < 1.5, dtype='int')
資料可視化如圖:
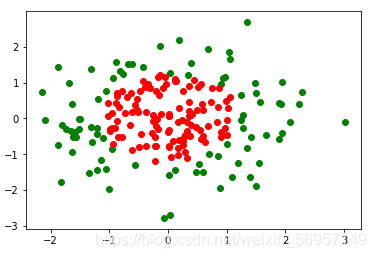
使用前面的 LogisticRegression 類進行邏輯回歸,并且使用 Scikit Learn 的 Pipeline 將多項式特征、資料歸一化和邏輯回歸組合在一起:
from LogisticRegression import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def PolynomailLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
設定 PolynomialFeatures 處理后得到的新的特征資料最高維度為2,然后 fit() 方法訓練模型:
poly_log_reg = PolynomailLogisticRegression(degree=2)
poly_log_reg.fit(X, y)
得到模型可視化如圖:
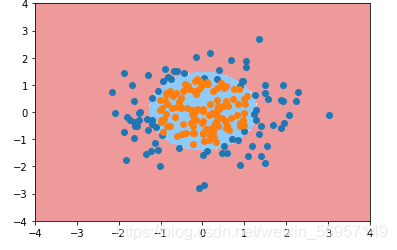

Scikit Learn 中的邏輯回歸
Scikit Learn 中的 linear_model 模塊中也提供了邏輯回歸的演算法,同時也封裝了模型正則化相關的內容,
根據正則化中的正則項的不同,正則化的方式主要有四種:
J
(
θ
)
+
α
L
1
J(\theta)+\alpha L_1
J(θ)+αL1?
J
(
θ
)
+
α
L
2
J(\theta)+\alpha L_2
J(θ)+αL2?
C
?
J
(
θ
)
+
L
1
C·J(\theta)+L_1
C?J(θ)+L1?
C
?
J
(
θ
)
+
L
2
C·J(\theta)+L_2
C?J(θ)+L2?
Scikit Learn 中的邏輯回歸演算法的模型正則化采用后兩種的方式,
L1 為 L1正則項,即
∑
i
=
1
n
∣
θ
i
∣
\sum_{i=1}^n|\theta_i|
∑i=1n?∣θi?∣,LASSO 回歸使用了L1;
L2 為 L2正則項,即
1
2
∑
i
=
1
n
θ
i
2
\frac{1}{2}\sum_{i=1}^n\theta_i^2
21?∑i=1n?θi2?,嶺回歸使用了L2;
Scikit Learn 的邏輯回歸演算法中的引數 c 設定 C 的大小,引數 penalty 設定使用哪種正則項(l1 或 l2),使用方式如下:
from sklearn.linear_model import LogisticRegression
def PolynomailLogisticRegression(degree, C, penalty='l2'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
])
poly_log_reg = PolynomailLogisticRegression(degree=20, C=0.1, penalty='l1')
poly_log_reg.fit(X_train, y_train)
OvR 與 OvO
前面說的都是二分類的邏輯回歸,如果要進行多分類的邏輯回歸,有 OvR 和 OvO 兩種方式,
OvR(One vs Rest)將多類別簡化成其中一個類別和其余類別為一個類別這種二分類,因此 n 個類別就進行 n 次分類,對于新的資料,看它在這 n 個分類結果中哪個分類得分最高即為哪個類別,
OvO(One vs One)在多類別中選取兩個類別作為二分類,因此 n 個類別就進行 C n 2 C_n^2 Cn2? 次分類,對于新的資料,看它在這 C n 2 C_n^2 Cn2? 次分類結果中數量最大即為哪個類別,
Scikit Learn 的邏輯回歸演算法中的引數 multi_class 用于設定使用 OvR(引數值為 ovr)還是 OvO(引數值為 multinomial),如:
LogisticRegression(multi_class='ovr')
LogisticRegression(multi_class='multinomial')
同時 Scikit Learn 中的 multiclass 模塊中也提供了 OneVsRestClassifier(OvR)類和 OneVsOneClassifier(OvO)類,可以將任意的二分類演算法(要求符合 Scikit Learn 規范)應用在這兩個類上完成多分類,使用方式如下:
# OvR
from sklearn.multiclass import OneVsRestClassifier
ovr = OneVsRestClassifier(LogisticRegression())
ovr.fit(X, y)
# OvO
from sklearn.multiclass import OneVsOneClassifier
ovo = OneVsOneClassifier(log_reg)
ovo.fit(X, y)

如果你也想掌握一門門技能就從現在開始學讓自己變得更好吧,通通無償分享給你們!免費自取!●:關十后臺call“學習”●:評論:機器學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/277381.html
標籤:其他