索引
什么是索引
類似于書籍的目錄,是為了加快查找速度存在的東西,可以快速定位,檢索資料,索引對于提高資料庫的性能有很大幫助,可以對表中的一列或者多列創建索引,并且指定索引型別,各類索引有各自的資料結構實作,
索引的內部結構長啥樣
回想我們資料結構學到的各種,線性表作為索引的話,通過下標訪問,好像和原本的相比完全沒有變化呀,二叉搜索樹的高度會隨著節點個數的增多,變高,不太方便,哈希表只能進行值相等的查找,不太方便,
這時就有一個B+樹(N叉搜索樹)
結構如下圖
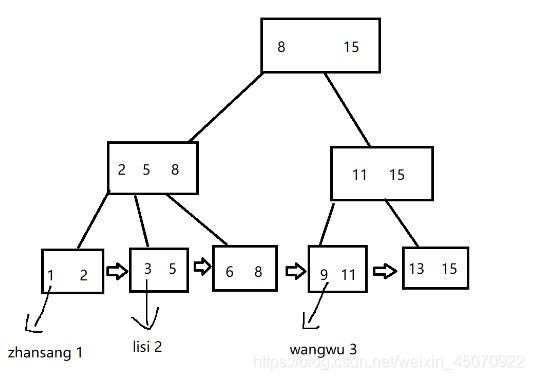
具有這些特點:
1.父節點里面的值,會作為子節點的最大值出現(也可以是最小值)目的就是讓所有葉子節點就包含了整體資料的全集
2.葉子節點按照順序通過鏈表的方式連接起來了,這個時候,就可以很方便很高效的實作范圍查找了
3.每一行資料的其他列資訊,只存于葉子節點上,非葉子節點僅僅包含索引列的資料(占有的空間就比較少了,就可以把這部分內容直接放到記憶體中,后續查找的時候,就可以只要去讀記憶體,減少了很多次的磁盤操作)
索引分類
聚簇索引:把資料的每一行資料都給放到索引結構中
非聚簇索引:把資料的每一行還是按照順序在磁盤上存盤,索引里面除了存盤這個用來構建索引的列之外,再存盤一個行號或者主鍵id
索引的操作
查看索引
show index from 表名;
創建索引
對于非主鍵、非唯一約束、非外鍵的欄位,可以創建普通索引
create index 索引名 on 表名(欄位名);
創建班級表中,name欄位的索引
create index idx_classes_name on classes(name);
洗掉索引
drop index 索引名 on 表名;
事務
事務是什么
事務指邏輯上的一組操作,組成這組操作的各個單元,要么全部成功,要么全部失敗,
在不同的環境中,都可以有事務,對應在資料庫中,就是資料庫事務,
最簡單的例子就是轉賬,要從一個賬戶轉出,又要轉入到另一個賬戶,要是中途出現意外,陳述句只執行了一半,那么資料不就全錯了,回也回不去了,
事務的特性
1.原子性(是個整體,不能再分割了)
2.一致性,事務執行完畢后,資料仍然是合理的(合理性程式員來定義的)
3.隔離性,并發執行事務所產生的問題和解決方案:盡管多個事務并發執行,單系統必須保證,每個事務都感覺不到系統中有其他事務在并發執行
4.持久性,一個事務成功完成之后,它對資料庫的改變必須是永久的,即使系統出現故障
MySQL并發執行事務可能產生的問題
1.臟讀
事務A在修改資料,另外一個事務B直接就讀取A正在修改的資料,此時B讀到的資料就是臟資料,因為此時B讀到的資料很有可能就在A的后續操作中又進行了修改,相當于B讀到資料只是一個中間狀態,這就是臟資料,這個動作即為臟讀.
防止:給寫操作加鎖
2.不可重復讀
事務A修改資料然后提交,提交完畢事務B開始讀取資料
事務B中包含了很多次的讀操作,如果事務B兩次操作得到的結果不一樣,就是不可重復讀
原因是事務A雖然把資料已經提交了,但是可能又執行了一次事務A,又把這個資料給改了
事務B第一次讀到的資料是事務A提交的,第二次讀到的資料是事務A又提交了一次的
防止:給讀操作加鎖
3.幻讀
事務B正在讀取資料,事務A,插入到新的資料/洗掉了某個資料,事務B兩次讀取到的資料集的個數發生了變化;
防止:串行化,徹底的讓事務之間串行執行,此時就沒有涉及到任何并發的事了
MySQL中事務的隔離級別
1.read uncommitted 沒有做出任何隔離性的限制,三個問題都存在
2.read committed 相當于進行了寫加鎖,并發程度降低了,隔離級別就提高了,臟讀問題解決,其 他兩個還在
3.repeatable read 相當于讀寫加鎖,并發程度又降低了,隔離性又提高了,現在只有幻讀還未解決(MySQL的默認隔離級別)
4.Serializable 串行化,并發程度最低,隔離性最高,問題都解決了,執行效率也是最低的.
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278444.html
標籤:其他