只聽到P8大佬不急不慢問道:談談對JDK并發工具的認識?

我開始仔細梳理多年的并發八股文積累的經驗,道:
執行緒池、Future、CompletableFuture和CompletionService這些并發工具都幫助SE站在任務角度解決并發問題,而非糾結于執行緒之間協作的細節,比如執行緒之間如何實作等待、通知,
- 簡單并行任務
執行緒池+Future 組合拳解決 - 任務之間有聚合關系
AND、OR聚合,都可以CompletableFuture一招鮮解決 - 批量的并行任務
CompletionService一把梭方案
并發編程可分為三個層面問題
分工- 協作
- 互斥
當關注于任務時,你會發現你的視角已脫離于并發編程細節,而使用現實世界思維模式,類比現實世界的分工,其實執行緒池、Future、CompletableFuture和CompletionService都可列為分工問題,
- 簡單并行任務、聚合任務和批量并行任務的現實的作業流程圖
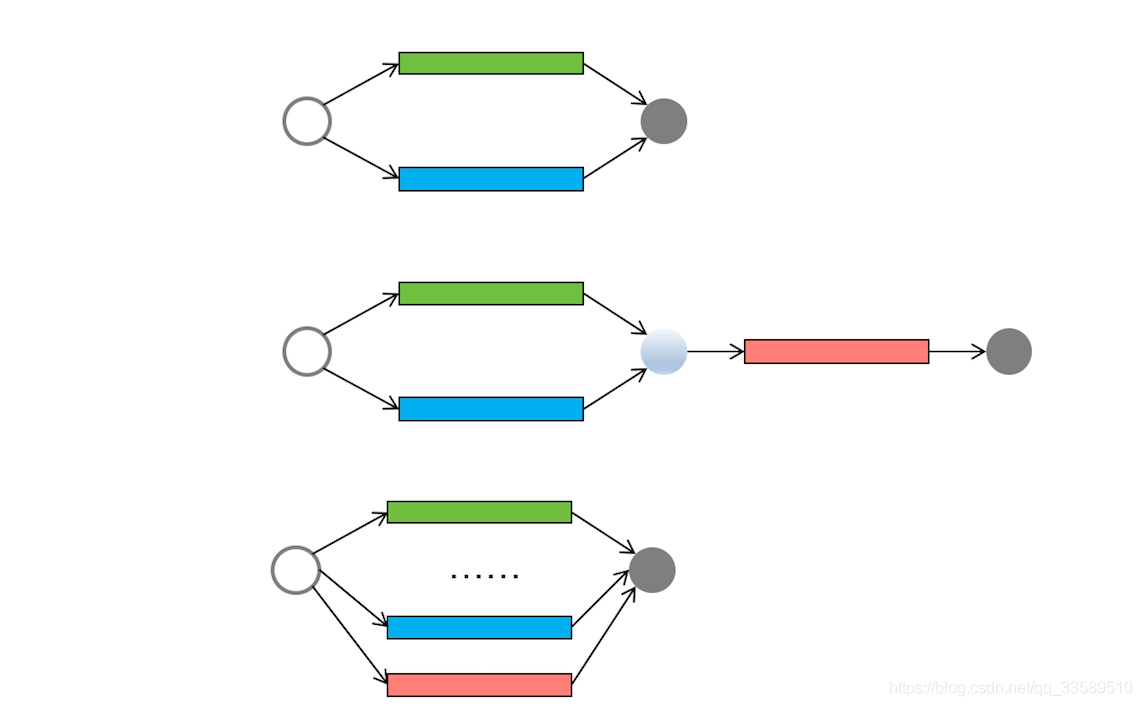
這三種任務模型,基本覆寫日常作業中的并發場景,但肯定不全面,還有一種“分治”任務模型,
分治,分而治之,一種解決復雜問題的思維方法和模式,把一個復雜問題分解成多個相似的子問題,然后再把子問題分解成更小的子問題,直到子問題簡單到可以直接求解,理論上解決每一個問題都對應著一個任務,所以對于問題的分治,實際上就是對于任務的分治,

P8 大佬直接開問,那你說說什么是分治任務模型?
分治任務模型可分為兩個階段:
- 任務分解
將任務迭代地分解為子任務,直至子任務可計算出結果 - 結果合并
逐層合并子任務的執行結果,直至獲得最終結果
就像官僚制度一樣:
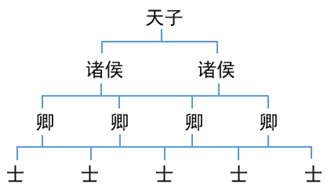
那你平時開發是如何使用Fork/Join的?

還好這道題,我面試前也準備了…
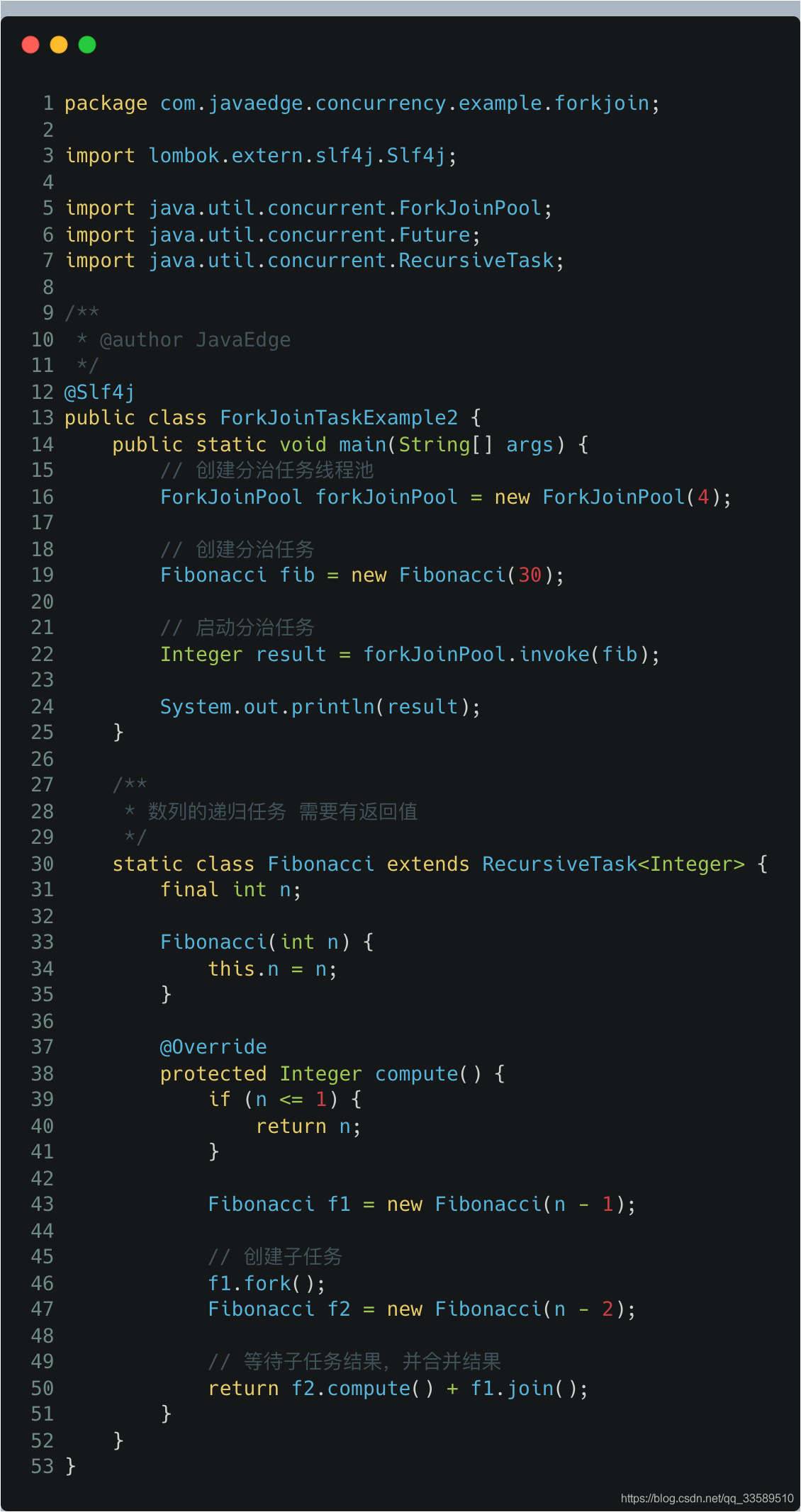
Fork/Join是一個并行計算框架,以支持分治任務模型
- Fork對應分治任務模型里的任務分解
- Join對應結果合并
Fork/Join計算框架主要包含兩部分:
- 分治任務的執行緒池ForkJoinPool
- 分治任務ForkJoinTask
這倆的關系類似于 ThreadPoolExecutor 和 Runnable,都是提交任務到執行緒池,只不過分治任務有自己獨特的任務型別ForkJoinTask,
ForkJoinTask
JDK7 提供,一個抽象類,核心方法如下:
- fork()
異步執行一個子任務 - join()
阻塞當前執行緒來等待子任務的執行結果
ForkJoinTask有兩個子類——RecursiveAction和RecursiveTask,顯然都是用遞回處理分治任務,這兩個子類都定義了抽象方法compute():
-
RecursiveAction#compute()無回傳值

-
RecursiveTask#compute()有回傳值
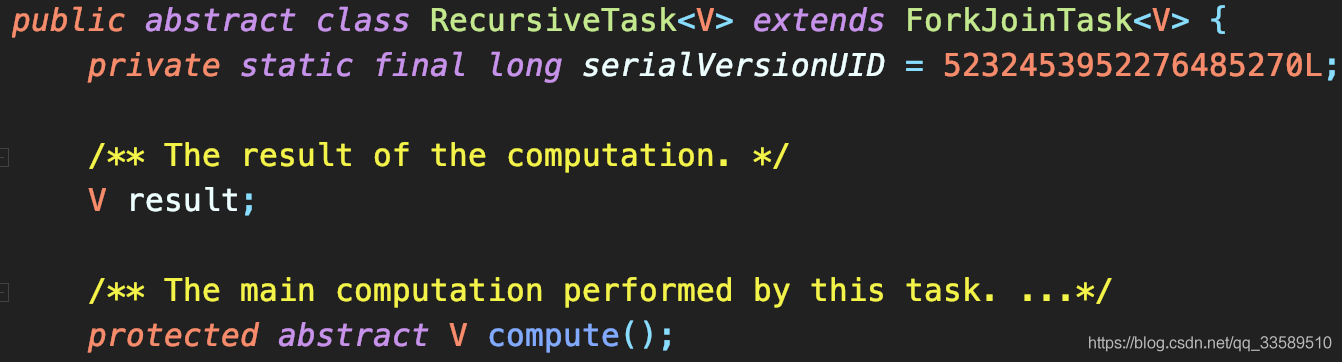
注意到這倆類都是抽象類,使用要定義子類實作,

只見 P8 開始冷笑,看來要問原始碼級別原理了!

那你說下Fork/Join的作業原理
還好我知道阿里面試套路,凡是 java 工具,必問深入的原始碼,
因為Fork/Join的核心就是ForkJoinPool,讓我來深入講解ForkJoinPool原理,
ThreadPoolExecutor本質是個生產者-消費者實作,內部有一個任務佇列,作為生產者和消費者的通信媒介,ThreadPoolExecutor可以有多個作業執行緒,這些作業執行緒都共享一個任務佇列,
ForkJoinPool本質上也是一個生產者-消費者的實作,但更智能
- ForkJoinPool作業原理圖
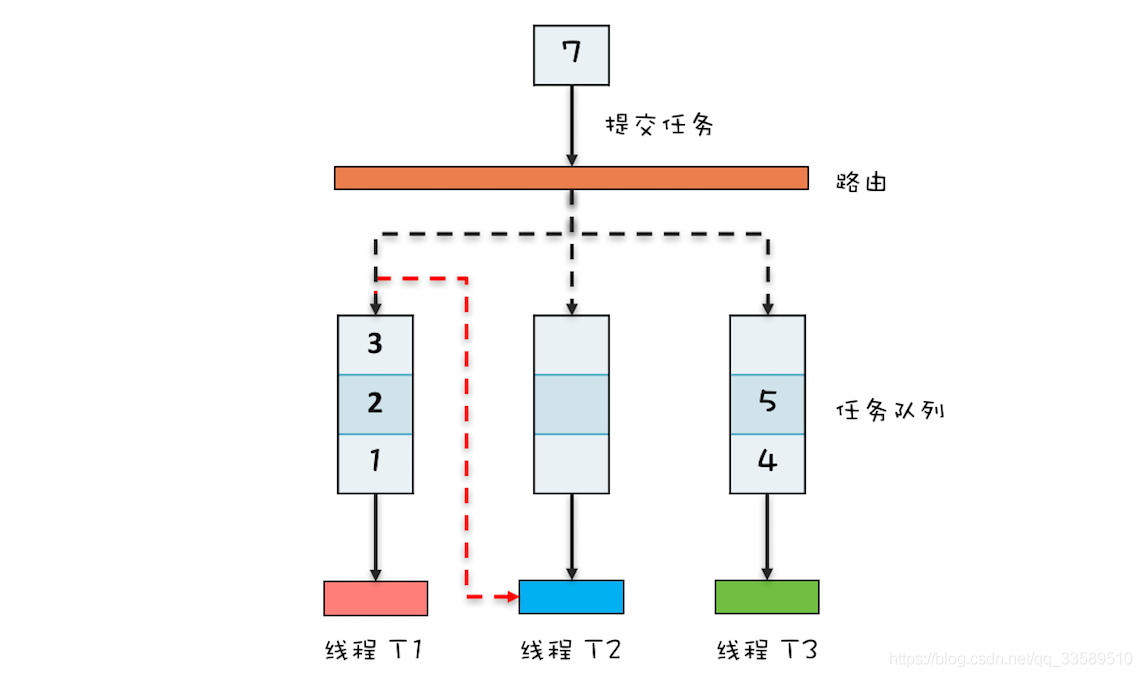
ThreadPoolExecutor內部只有一個任務佇列,而ForkJoinPool內部有多個任務佇列,當呼叫ForkJoinPool#invoke()或submit()提交任務時,ForkJoinPool把任務通過路由規則提交到一個任務佇列,如果任務在執行程序中會創建出子任務,那么子任務會提交到作業執行緒對應的任務佇列,
如果作業執行緒對應的任務佇列空,是不是就沒活兒干了?
No!ForkJoinPool有個“任務竊取”機制,若作業執行緒空閑了,它會“竊取”其他作業任務佇列里的任務,例如剛才那個圖中,執行緒T2對應任務佇列已空

那它會“竊取”執行緒T1對應的任務佇列的任務,這樣所有作業執行緒都不會閑著,
ForkJoinPool的任務佇列采用的是雙端佇列,作業執行緒正常獲取任務和“竊取任務”分別從任務佇列不同的端消費,這也能避免很多不必要的資料競爭,
ForkJoinPool支持任務竊取機制,能夠讓所有執行緒的作業量基本公平,不會出現執行緒有的很忙,有的一直在摸魚,所以性能很好,是個很公正的領導,
Java8的Stream API里面并行流也是基于ForkJoinPool,
默認,所有的并行流計算都共享一個ForkJoinPool,這個共享的ForkJoinPool的默認執行緒數是CPU核數;
若所有并行流計算都是CPU密集型,完全沒有問題,但若存在I/O密集型并行流計算,那很可能因為一個很慢的I/O計算而拖慢整個系統的性能,所以建議用不同ForkJoinPool執行不同型別的計算任務,
參考
- https://www.liaoxuefeng.com/article/1146802219354112
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278509.html
標籤:其他
上一篇:單鏈表帶環問題歸納總結
下一篇:初步認識C Lesson 2