相信大家最近一定關注到一款重量級訊息中間件Kafka發布了2.8版本,并且正式移除了對Zookeeper的依賴,背后的設計哲學是什么呢?僅僅只是減少了一個外部依賴嗎?
答案顯然不會這么簡單,容我慢慢道來,
在解答為什么之前,我覺得非常有必要先來闡述一下Zookeeper的經典使用場景,
1、Zookeeper的經典使用場景
zookeeper是伴隨著大資料、分布式領域的興起,大資料中的一個非常重要的議題是如何使用眾多廉價的機器來實作可靠存盤,
所謂廉價的機器就是發生故障的概率非常大,但單臺的成本也非常低,分布式領域希望使用多臺機器組成一個集群,將資料存盤在多臺機器上(副本),為了方便實作資料一致性,通常需要從一個復制組中挑選一臺主節點用戶處理資料的讀寫,其他節點從主節點拷貝資料,當主節點宕機,需要自動進行重新選舉,實作高可用,
上述場景中有一個非常重要的功能Leader選舉,如何選舉出一個主節點、并支持主節點宕機后自動觸發重新選舉,實作主從自動切換,實作高可用,
使用Zookeeper提供的臨時順序節點與事件監聽機制,能非常輕松的實作Leader選舉,
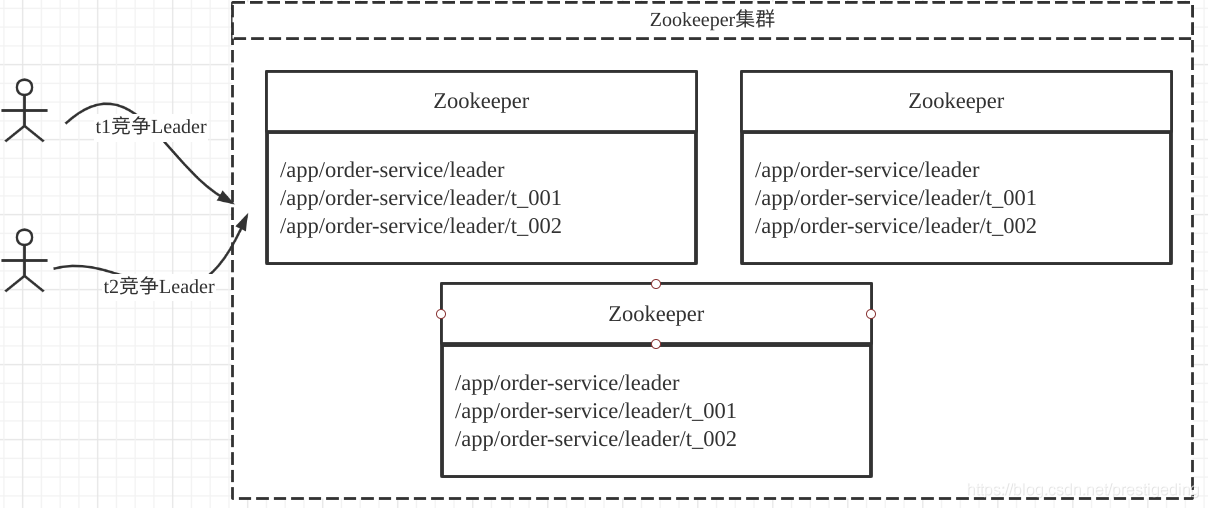
上面的t1,t2可以理解為一個組織中的多個成員,能提供相同的服務,但為了實作冷備效果(即同一時間只有一個成員對外提供服務,我們稱之為Leader,當Leader宕機或停止服務后,該組織中的其他成名重新競爭Leader,然后繼續對外提供服務),
正如上圖所示,Zookeeper是以集群部署的,能有效避免單點故障,并且集群內部提供了對資料的強一致性,
當成員需要競爭Leader時,借助Zookeeper的實作套路是向zookeeper中的一個資料節點(示例中為/app/order-service/leader)節點創建兩個子節點,并且是順序的臨時節點,
客戶端判斷創建的節點的序號是否為/app/order-service/leader中序號最小的節點,如果是則成為Leader,對外提供服務;
如果序號不是最小的,則向自己前置的注冊節點洗掉事件,一旦Leader代表的行程宕機,它與Zookeeper的會話失效后,與之關聯的臨時節點會被洗掉,一旦Leader創建的節點被洗掉,其后繼節點會得到通知,從而再次觸發選主,選舉出新的Leader,繼續對外提供服務,保質服務的高可用性,
回顧上述場景,借助Zookeeper能非常輕松的實作選主,為應用提高可用帶來簡便性,主要是利用了Zookeeper的幾個特性:
- 臨時節點
臨時節點是與會話關聯的,一點創建該臨時節點的會話結束,與之會被自動洗掉,無需應用方人工洗掉, - 順序節點
- 事件機制
借助與事件機制,Zookeeper能及時通知存活的其他應用節點,重新觸發選舉,使得實作自動主從切換變的非常簡單,
2、Kafka對Zookeeper的迫切需求
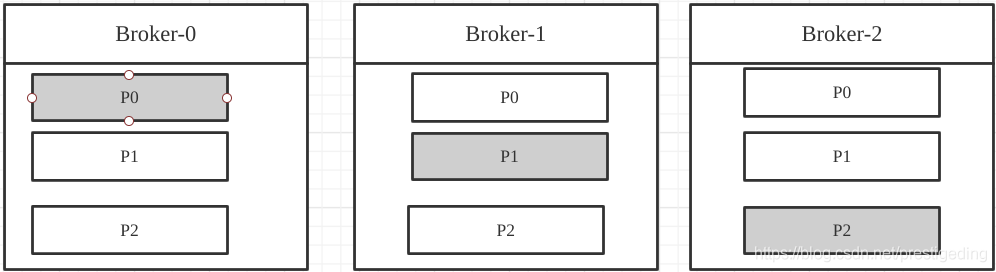
Kafka中存在眾多的Leader選舉,熟悉Kafka的朋友應該知道,一個主題可以擁有多個磁區(資料分片),每一個資料分片可以配置多個副本,如何保證一個磁區的資料在多個副本之間的一致性成為一個迫切的需求,
Kafka的實作套路就是一個磁區的多個副本,從中選舉出一個Leader用來承擔客戶端的讀寫請求,從節點從主節點處拷貝內容,Leader節點根據資料在副本中成功寫入情況,進行抉擇來確定是否寫入成功,
Kafka中topic的磁區分布示意圖:
故此處需要進行Leader選舉,而基于Zookeeper能輕松實作,從此一拍即合,開啟了一段“蜜月之旅”,
3、Zookeeper的致命弱點
Zookeeper是集群部署,只要集群中超過半數節點存活,即可提供服務,例如一個由3個節點的Zookeeper,允許1個Zookeeper節點宕機,集群仍然能提供服務;一個由5個節點的Zookeeper,允許2個節點宕機,
但Zookeeper的設計是CP模型,即要保證資料的強一致性,必然在可用性方面做出犧牲,
Zookeeper集群中也存在所謂的Leader節點和從節點,Leader節點負責寫,Leader與從節點可用接受讀請求,但在Zookeeper內部節點在選舉時整個Zookeeper無法對外提供服務,當然正常情況下選舉會非常快,但在例外情況下就不好說了,例如Zookeeper節點發生full Gc,此時造成的影響將是毀滅性的,
Zookeeper節點如果頻繁發生Full Gc,此時與客戶端的會話將超時,由于此時無法回應客戶端的心跳請求(Stop World),從而與會話相關聯的臨時節點將被洗掉,注意,此時是所有的臨時節點會被洗掉,Zookeeper依賴的事件通知機制將失效,整個集群的選舉服務將失效,
站在高可用性的角度,Kafka集群的可用性不僅取決于自身,還受到了外部組件的制約,從長久來看,顯然都不是一個優雅的方案,
隨著分布式領域相關技術的不斷完善,去中心化的思想逐步興起,去Zookeeper的呼聲也越來越高,在這個行程中涌現了一個非常優秀的演算法:Raft協議,
Raft協議的兩個重要組成部分:Leader選舉、日志復制,而日志復制為多個副本提供資料強一致性提供了強一致性,并且一個顯著的特點是Raft節點是去中心化的架構,不依賴外部的組件,而是作為一個協議簇嵌入到應用中的,即與應用本身是融合為一體的,
再以Kafka Topic的分布圖舉例,參考Raft協議的示例圖如下:
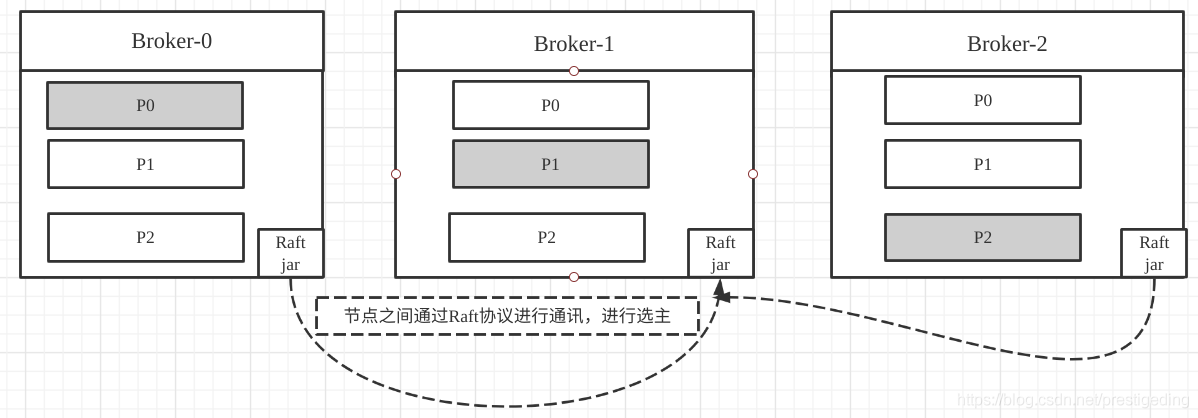
關于Raft協議,本文并不打算深入進行探討,但為選主提供了另外一種可行方案,而且還無需依賴第三方組件,何樂而不為呢?故最終Kafka在2.8版本中正式廢棄了Zookeeper,擁抱Raft,
如果大家對Raft協議感興趣,推薦閱讀筆者關于Raft協議的系列文章:
-
初探raft協議
-
Raft協議之Leader協議選主實作原理
好了,本文就介紹到這里了,鍵三連(關注、點贊、留言)是對我最大的鼓勵,,當然可以加筆者微信:dingwpmz,備注CSDN,共同交流探討,
最后分享筆者一個硬核的RocketMQ電子書,您將獲得千億級訊息流轉的運維經驗,
獲取方式:微信搜索【中間件興趣圈】,回復RMQPDF即可獲取,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278842.html
標籤:其他
上一篇:低代碼:正在改變軟體的開發方式