特征編碼
由于機器學習演算法都是在矩陣上執行線性代數計算,所以參加計算的特征必須是數值型的,對于非數值型的特征需要進行編碼處理,對于離散型資料的編碼,我們通常會使用兩種方式來實作,分別是標簽編碼和獨熱編碼
標簽編碼
將類別型特征從字串轉換為數字
特點:
- 解決了分類編碼的問題,可以自由定義量化數字
- 數值本身沒有任何含義,僅是標識或者排序的作用
- 可解釋性比較差
適用范圍:
- 對于定序型別的資料,使用標簽編碼更好,雖然定序型別也屬于分類,但是其有排序邏輯
- 對數值大小不敏感的模型(如樹模型),建議使用標簽編碼
方式一:map 或 replace
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.feature_extraction import DictVectorizer
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
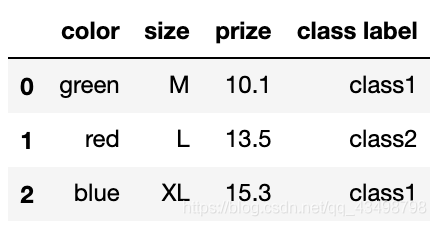
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)
df
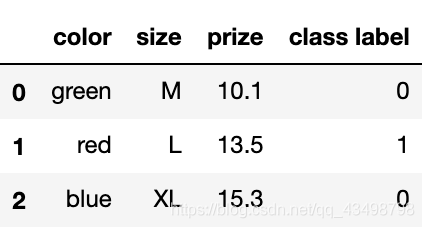
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
df
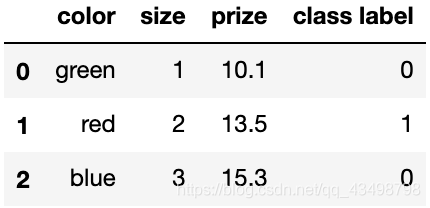
color_mapping = {
'green': 1,
'red': 2,
'blue': 3}
df['color'] = df['color'].map(color_mapping)
df
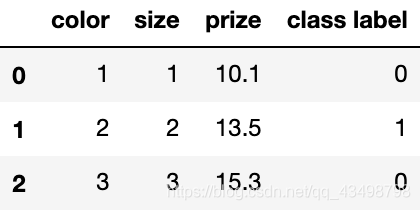
反向變換
inv_color_mapping = {v: k for k, v in color_mapping.items()}
inv_size_mapping = {v: k for k, v in size_mapping.items()}
inv_class_mapping = {v: k for k, v in class_mapping.items()}
df['color'] = df['color'].map(inv_color_mapping)
df['size'] = df['size'].map(inv_size_mapping)
df['class label'] = df['class label'].map(inv_class_mapping)
df
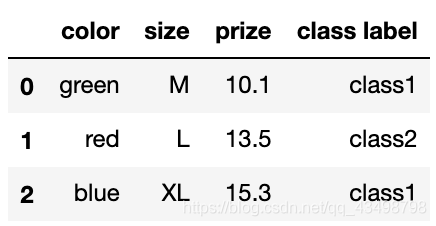
方式二:sklearn LabelEncoder
將離散型的資料轉換成 0 0 0 到 n ? 1 n ? 1 n?1 之間的數
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
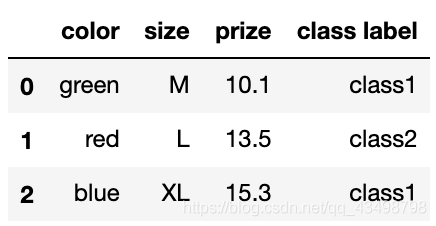
# 將類別標簽轉化為數值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
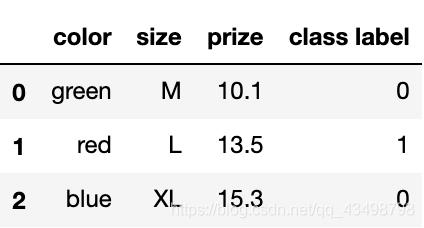
# 反向變換可以用函式 inverse_transform
df['class label'] = class_le.inverse_transform(df['class label'])
df
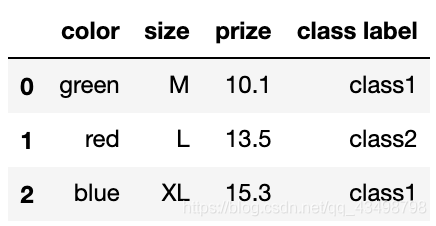
獨熱編碼
采用 N N N 位狀態暫存器來對 N N N 個可能的取值進行編碼,每個狀態都由獨立的暫存器來表示,并且在任意時刻只有其中一位有效
特點:
- 解決了分類器不好處理分類變數的問題,同時也可以擴展特征
- 編碼后的屬性是稀疏的,存在大量的零元分量
- 當類別非常多時,特征空間會非常大,容易導致維度災難的問題
適用范圍:
- 適用于定型別別的資料,該型別資料是純分類,不進行排序,互相之間也沒有邏輯關系
- 對數值大小敏感的模型,必須使用獨熱編碼
方式一:sklearn DictVectorizer
將 {特征名稱:特征值} 字典組成的串列轉化為陣列或稀疏矩陣,當特征值為字串時,就會對特征進行獨熱編碼
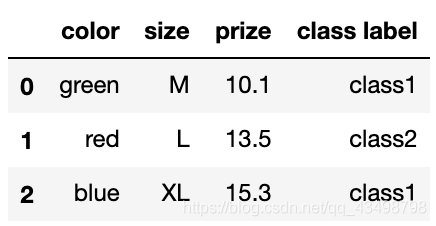
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
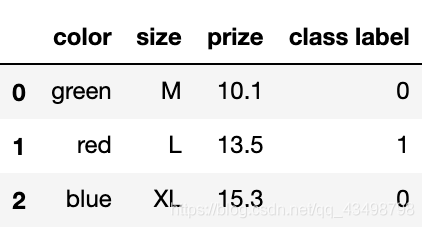
# 將類別標簽轉化為數值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
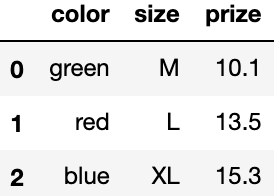
# 獲取特征
feature = df.iloc[:,:-1]
feature
# 由 {特征名稱:特征值} 字典組成的串列
feature.transpose().to_dict().values()
dict_values([{‘color’: ‘green’, ‘size’: ‘M’, ‘prize’: 10.1}, {‘color’: ‘red’, ‘size’: ‘L’, ‘prize’: 13.5}, {‘color’: ‘blue’, ‘size’: ‘XL’, ‘prize’: 15.3}])
dvec = DictVectorizer(sparse=False)
X = dvec.fit_transform(feature.transpose().to_dict().values())
X

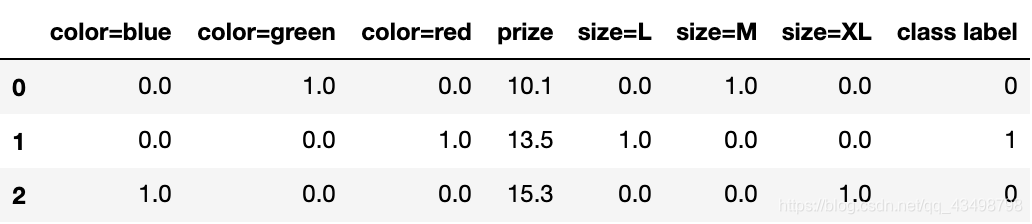
可以呼叫 get_feature_names 來回傳新的列的名字,其中0和1就代表是不是這個屬性
X = pd.DataFrame(X, columns=dvec.get_feature_names())
X.join(df['class label'])
方式二:sklearn OneHotEncoder
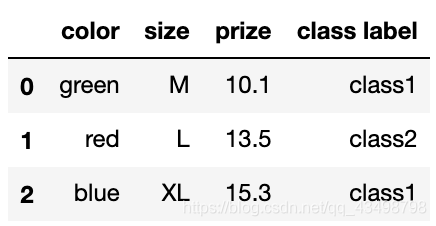
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
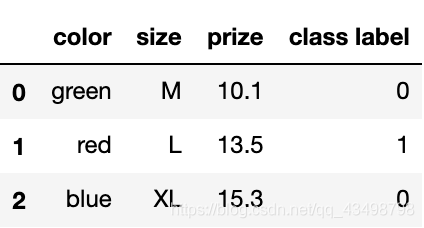
# 將類別標簽轉化為數值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
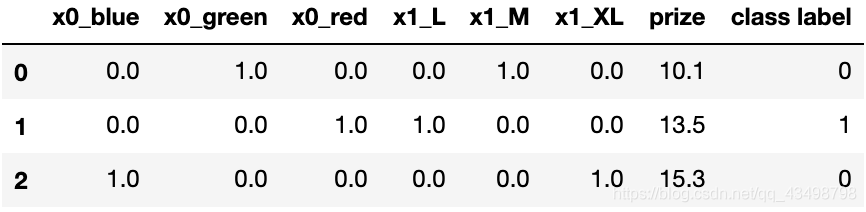
ohe = OneHotEncoder(sparse=False) # Will return sparse matrix if set True else will return an array.
X = ohe.fit_transform(df[['color','size']].values)
X

X = pd.DataFrame(X, columns=ohe.get_feature_names())
X.join(df[['prize','class label']])
方式三:pandas get_dummies
Pandas庫中同樣有類似的操作,使用 get_dummies 也可以得到相應的特征
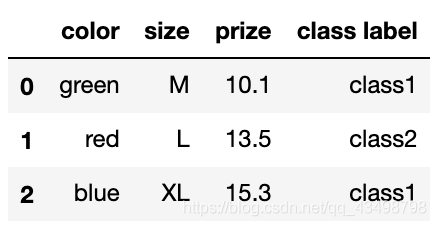
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
df
# 將類別標簽轉化為數值
class_le = LabelEncoder()
df['class label'] = class_le.fit_transform(df['class label'])
df
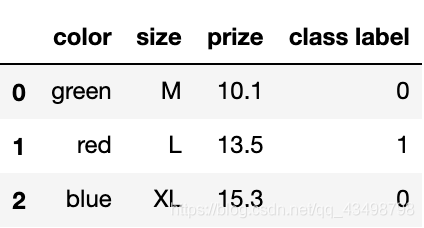
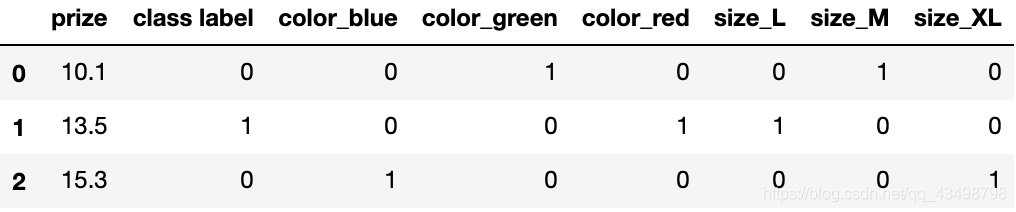
# 對整個DF使用 get_dummies 將會得到新的列
pd.get_dummies(df)
本文到此結束,后續將會不斷更新,如果發現上述有誤,請各位大佬及時指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279627.html
標籤:其他