堆
- 二叉樹
- 二叉樹的概念
- 滿二叉樹
- 完全二叉樹
- 堆
- 堆的分類
- 如何建堆(將資料變成堆的存盤方式)
- 堆排序演算法
堆是利用 完全二叉樹的結構來維護一組資料,然后進行相關操作,一般的操作進行一次的時間復雜度在O(1)~O(logn)之間,我們在了解學習堆這個資料結構之前,必須先學習一些二叉樹的概念和性質,
二叉樹
二叉樹的概念
一棵二叉樹是結點的一個有限集合,該集合或者為空,或者是由一個根節點加上兩棵別稱為左子樹和右子樹的二叉樹組成,
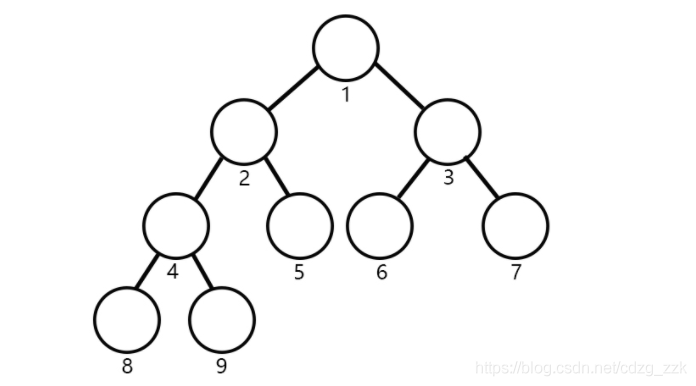
簡單來說,二叉樹就是每個節點的度(樹的度)小于等于2的數
滿二叉樹
一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹,也就是說,如果一個二叉樹的層數為K,且結點總數是(2^k) -1 ,則它就是滿二叉樹,
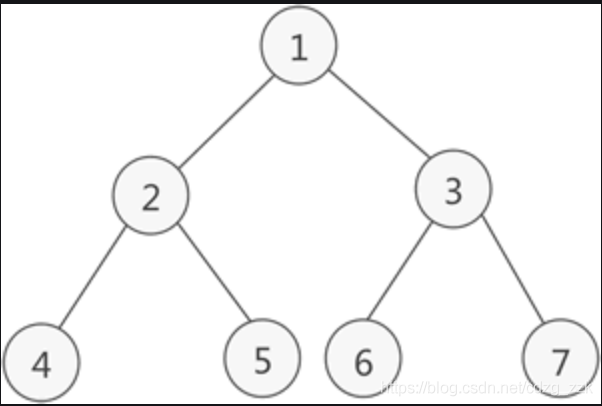
簡單來說,滿二叉樹就是每個結點的度都為2,每個結點都有兩個孩子結點
完全二叉樹
完全二叉樹是效率很高的資料結構,完全二叉樹是由滿二叉樹而引出來的,對于深度為K的,有n個結點的二叉樹,當且僅當其每一個結點都與深度為K的滿二叉樹中編號從1至n的結點一一對應時稱之為完全二叉樹, 要注意的是滿二叉樹是一種特殊的完全二叉樹,
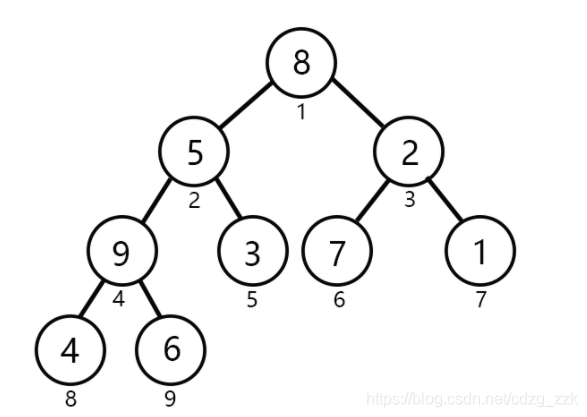
堆
堆的分類
堆分為:
1.小根堆
2.大根堆
(1)小根堆:小根堆的任一非終端節點的資料值均不大于其左子節點和右子節點的值,
每個結點的數值一定小于它的子節點的數值
(2)大根堆:與小根堆相反,根節點的數值不小于其左右子節點的數值
如何建堆(將資料變成堆的存盤方式)
我們以小根堆為例(大根堆的話,就是將對應位置的 < 變為 > )
情況一:根的左子樹、右子樹都恰好是小根堆
采用“向下調整法”
步驟一:首先對于要操作的堆的根節點,找出根節點的孩子節點中數值較小的孩子節點
步驟二:將較小的孩子節點的數值與根節點的數值進行比較
a.若根節點的數值大于較小的子節點的數值,那么將這兩個結點的數值進行交換,使小的數交換到根節點去(就是為了使根節點的數值最小)然后進行步驟三
b.若較小的孩子結點的數值大于根節點,則直接進行步驟三
步驟三:進行迭代,將步驟一中求出的較小的孩子結點作為下一次迭代中的根節點繼續重復以上步驟,直到走到最后的末端節點(葉子節點),
//代碼實作
void AdjustDown(int* a, int sz, int parent)
{
int child = 2 * parent + 1;
while (child<sz)
{
if (child<sz - 1 && a[child]>a[child + 1])
child++;
if (a[child] < a[parent]) //如果雙親大于孩子,就不對,就要交換
{
Swap(&a[child], &a[parent]); //將兩值交換
parent = child;
child = 2 * parent + 1;
}
else //存在一次孩子都小于雙親,(由于根節點的兩個子樹都是小根堆)后面肯定符合小根堆,所以就不用回圈了
break;
}
}
hehe
情況二:一般情況,左右子樹不是小根堆
分析:我們可以將左右子樹先建成小根堆,左右子樹建成小根堆又分為相同的情況一和情況二,如果還是情況二,就將它的左右子樹建成小根堆,如下重復
所以,總結起來,就是將整個二叉樹的從最后一個非葉子結點開始,從后往前,按編號,依次將每個結點都作為一個根來建堆,直到整個二叉樹的根節點結束,
//代碼實作
void HeapBuild(int* a, int sz)
{
int child = sz - 1; //找到最后一個葉子節點
for (int i = (child-1) / 2; i >= 0; i--) //child為最后位置的葉子節點,根據公式:左孩子 = 雙親*2+1 右孩子 = 雙親*2+2
//(child-1)/2為其雙親結點
{
AdjustDown2(a, sz, i); //由于將一個根節點的兩個子樹都建好堆,所以問題退化成情況一
} //對于葉子結點的雙親結點作為“根”的時候,也相當于它的左右葉子結點為堆
}
堆排序演算法
**
分析為啥可以用堆來排序捏?
分析為啥可以用堆來排序捏?
堆中的第一個元素一定是所有資料中最大/最小的資料,所以我們可以通過一次一次排序將最大/最小的資料得到,重復回圈從而得到一個有序陣列,
我們以將資料排序成升序來舉例
####靈魂問題####我們將資料排成升序,應該將堆建成大堆還是小堆捏?
有的同學說:肯定是小堆啊:只有小堆才能獲得最小的資料放在最前面,再將剩下的資料重復建小堆,就可以了啊
有的同學說:這么弱智的問題都問出來了,肯定不簡單,所以我認為要建大堆!!
于是我們就要恭喜投機取巧,揣測出題人意圖的同學們回答正確了!!
下面就要著重解釋一下為啥要建大堆了
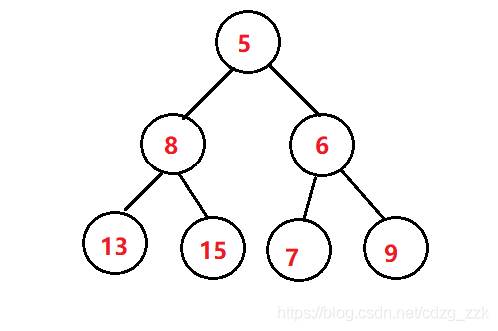
hehe
上圖是已經建好的小堆,我們獲取根節點的元素作為最小的數值,剩下的結點如下圖
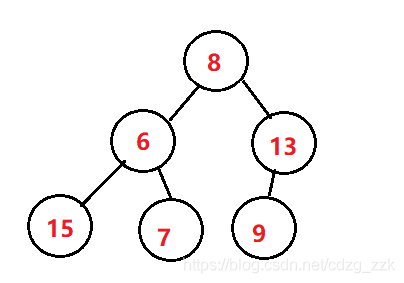
我們可以發現,這完全是一個亂序的二叉樹,屬于情況二,我們需要完全重新建堆,時間復雜度飆升至O(N*N),所以說,效率是極低的,那如果采用大堆排序呢?
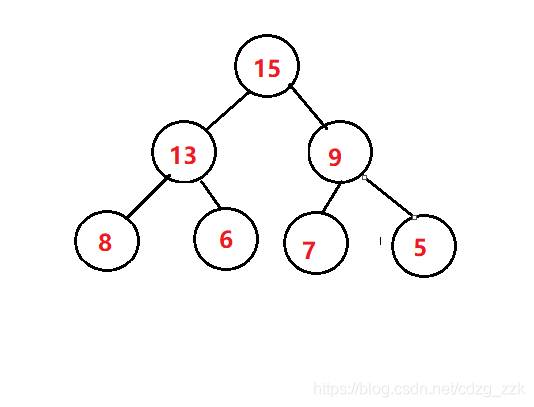
建完大堆后,我們需要將第一元素和最后一個元素互換位置
注:1.目的是將第一個元素(最大元素)移動到最后位置, 2.最后元素不一定就是最小的元素
此時前n-1個元素是符合情況一的,所以再建堆的時候只需要進行一次向下調成操作,復雜度就變為O(N*logN)
//代碼實作
void HeapSort(int* a, int sz)
{
HeapBuild(a, sz); //先建大堆
int end = sz - 1; //始終指向剩余元素的最后位置,既方便交換,又可以監視是否排序完成
while (end>0)
{
Swap(&a[0], &a[end]);
AdjustDown2(a, end, 0); //建大堆的向下調整方法
end--;
}
}
hehe
hehe
這次的分享就先到這里,堆這里確實有好多部分不好理解,所以有問題可以私信給博主,相互交流,我一定盡力解答,臨走別忘留下評論與點贊哦~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279631.html
標籤:其他
上一篇:最短路問題的各種求法(一)