文章目錄
- 《高質量的C/C++編程》
- 一 著作權宣告
- 二 做題點這里,考察質量,按答案嚴格打分,
- 三 前言
- 我的前言
- 博士的前言總結
- 第一二章:
- 防止頭檔案被重復包含,
- 目錄結構
- 程式的版式追求清晰、美觀,是程式風格的重要構成因素,
- 代碼行
- 對齊
- 長行拆分
- 類的版式
- 第三章:命名規則
- Windows 簡單的命名規則
- 簡單的 Unix 應用程式命名規則
- 第 4 章 運算式和基本陳述句
- 運算子的優先級
- 復合運算式
- if陳述句_本節以“與零值比較”為例,展開討論, _
- 布爾變數與零值比較
- 整型變數與零值比較
- 浮點變數與零值比較
- 指標變數與零值比較
- 4.4 回圈陳述句的效率
- 4.5 for 陳述句的回圈控制變數
- 4.6 switch 陳述句
- 第五章 常量
- 5.1 為什么需要常量
- 5.2 const 與 #define 的比較
- 5.3 常量定義規則
- 5.4 類中的常量
- 第六章 函式設計
- 這里有一個很細的講解
- 引數的規則
- 6.2 回傳值的規則
- 6.3 函式內部實作的規則
- 6.4 其他建議
- 6.5 使用斷言
- 第 7 章 記憶體管理
- 7.3 指標與陣列的對比
- 7.4 指標引數是如何傳遞記憶體的?
- 7.5 free 和 delete 把指標怎么啦
- 7.6 切記要初始化指標,釋放指標后要置成空指標,
- 7.8 有了 malloc/free 為什么還要 new/delete
- 7.9 記憶體耗盡怎么辦?
- 試圖耗盡作業系統的記憶體
- 7.10 malloc/free 的使用要點
- 7.11 new/delete 的使用要點
- 7.12 一些心得體會
- 第 8 章 C++函式的高級特性
- 8.1 函式多載的概念
- 8.2 成員函式的多載、覆寫與隱藏、
- 8.3 引數的預設值
- 8.4 運算子多載
- 8.5 函式行內
- 8.6 一些心得體會
- 第 9 章 類的建構式、解構式與賦值函式
- 第 10 章 類的繼承與組合
- 第 11 章 其它編程經驗
- 使用 const 提高函式的健壯性
- 提高程式的效率
- 一些有益的建議
- GG.本文結尾語:
《高質量的C/C++編程》
一 著作權宣告
上海貝爾網路應用-林銳


二 做題點這里,考察質量,按答案嚴格打分,
大俠!!點這里做題,!做完題記得回來哦~~!
三 前言
我的前言
目前還在C語言階段,大部分是C語言能用到的細節,看一遍總會忘,記得收藏~
C++復制粘貼了一部分,然而越看越吃力,就待定了…
博士的前言總結
- (1)知錯就改;
- (2)經常溫故而知新;
- (3)堅持學習,天天向上,
第一二章:
防止頭檔案被重復包含,
- `ifndef famer_h`
- define famer_h
- ..
- endif
- <>頭檔案,編譯器將參考標準庫的頭檔案,從標準目錄開始搜索、
- “”頭檔案,將從用戶的作業目錄開始搜索,用戶自己創建的頭檔案
- 頭檔案只存放宣告,不存放定義
- 不建議使用全域變數

目錄結構
- 如果一個軟體的頭檔案數目比較多(如超過十個),通常應將頭檔案和定義檔案分
- 別保存于不同的目錄,以便于維護,
- 例如可將頭檔案保存于 include 目錄,將定義檔案保存于 source 目錄(可以是多級
- 目錄),
- 如果某些頭檔案是私有的,它不會被用戶的程式直接參考,則沒有必要公開其“宣告”,為了加強資訊隱藏,這些私有的頭檔案可以和定義檔案存放于同一個目錄
程式的版式追求清晰、美觀,是程式風格的重要構成因素,
- 空行起著分隔程式段落的作用,
- 空行不會浪費記憶體
- 【規則 2-1-1】在每個類宣告之后、每個函式定義結束之后都要加空行,
- 【規則 2-1-2】在一個函式體內,邏揖上密切相關的陳述句之間不加空行,其它地方應加空行分隔,

代碼行
- 一行代碼只做一件事情,如只定義一個變數,或只寫一條陳述句,這樣的代碼容易閱讀,并且方便于寫注釋,
- if、for、while、do 等陳述句自占一行,執行陳述句不得緊跟其后,
- 不論執行陳述句有多少都要加{},這樣可以防止書寫失誤,
- 關鍵字之后要留空格,象 const、virtual、inline、case 等關鍵字之后至少要留一個空格,否則無法辨析關鍵字,象 if、for、while 等關鍵字之后應留一個空格再跟左括號‘(’,以突出關鍵字,
- z 【規則 2-3-4】‘,’之后要留空格,如 Function(x, y, z),如果‘;’不是一行的結束符號,其后要留空格,如 for(initialization; condition; update),
- z 【規則 2-3-5】賦值運算子、比較運算子、算術運算子、邏輯運算子、位域運算子,如“=”、“+=” “>=”、“<=”、“+”、“”、“%”、“&&”、“||”、“<<”,“^”等二元運算子的前后應當加空格,

對齊
- z 【規則 2-4-1】程式的分界符‘{’和‘}’應獨占一行并且位于同一列,同時與參考它們的陳述句左對齊,
- 【規則 2-4-2】{ }之內的代碼塊在‘{’右邊數格處左對齊

長行拆分
-
【規則 2-5-1】代碼行最大長度宜控制在 70 至 80 個字符以內,代碼行不要過長,否則眼睛看不過來,也不便于列印,
- 【規則 2-5-2】長運算式要在低優先級運算子處拆分成新行,運算子放在新行之首(以便突出運算子),拆分出的新行要進行適當的縮進,使排版整齊,陳述句可讀,
-
【規則 2-6-1】應當將修飾符 * 和 & 緊靠變數名 *
- 【規則 2-7-2】如果代碼本來就是清楚的,則不必加注釋,否則多此一舉,令人厭煩,注釋的花樣要少

- 【規則 2-7-2】如果代碼本來就是清楚的,則不必加注釋,否則多此一舉,令人厭煩,注釋的花樣要少
類的版式
- 類可以將資料和函式封裝在一起,其中函式表示了類的行為(或稱服務),類提供關鍵字 public、protected 和 private,分別用于宣告哪些資料和函式是公有的、受保護的或者是私有的,這樣可以達到資訊隱藏的目的,即讓類僅僅公開必須要讓外界知道的內容,而隱藏其它一切內容,我們不可以濫用類的封裝功能,不要把它當成火鍋,什么東西都往里扔,
- (1)將 private 型別的資料寫在前面,而將 public 型別的函式寫在后面,“以資料為中心”,重點關注類的內部結構,
- (2)將 public 型別的函式寫在前面,而將 private 型別的資料寫在后面,“以行為為中心”,重點關注的是類應該提供什么樣的介面(或服務),
- 建議“以行為為中心”的書寫方式.

第三章:命名規則
- 【規則 3-1-1】識別符號應當直觀且可以拼讀,可望文知意,不必進行“解碼”,識別符號最好采用英文單詞或其組合,便于記憶和閱讀,
- 【規則 3-1-2】識別符號的長度應當符合“min-length && max-information”原則,
- 【規則 3-1-3】命名規則盡量與所采用的作業系統或開發工具的風格保持一致
Windows 簡單的命名規則
-
Windows 應用程式的識別符號通常采用“大小寫”混排的方式,如 AddChild,
- 而 Unix 應用程式的識別符號通常采用“小寫加下劃線”的方式,如 add_child,
-
【規則 3-1-6】變數的名字應當使用“名詞”或者“形容詞+名詞”,
-
【規則 3-1-7】全域函式的名字應當使用“動詞”或者“動詞+名詞”(動賓詞組),
-
【規則 3-1-8】用正確的反義詞組命名具有互斥意義的變數或相反動作的函式等.
- 例如:int minValue;
- int maxValue;
- int SetValue(…);
- int GetValue(…)
-
【規則 3-2-1】類名和函式名用大寫字母開頭的單詞組合而成,
-

-
【規則 3-2-3】常量全用大寫的字母,用下劃線分割單詞,
-
【規則 3-2-4】靜態變數加前綴 s_(表示 static),
-
【規則 3-2-5】如果不得已需要全域變數,則使全域變數加前綴 g_(表示 global),
-
-
【規則 3-2-6】類的資料成員加前綴 m_(表示 member),這樣可以避免資料成員與_成員函式的引數同名,
-

- 【規則 3-2-7】為了防止某一軟體庫中的一些識別符號和其它軟體庫中的沖突,可以為各種識別符號加上能反映軟體性質的前綴,例如三維圖形標準 OpenGL 的所有庫函式均以 gl 開頭,所有常量(或宏定義)均以 GL 開頭,
簡單的 Unix 應用程式命名規則
- 這是個迷
第 4 章 運算式和基本陳述句
運算子的優先級
-
C++/C 語言的運算子有數十個,運算子的優先級與結合律如表 4-1 所示,注意一元運算子 + - * 的優先級高于對應的二元運算子,
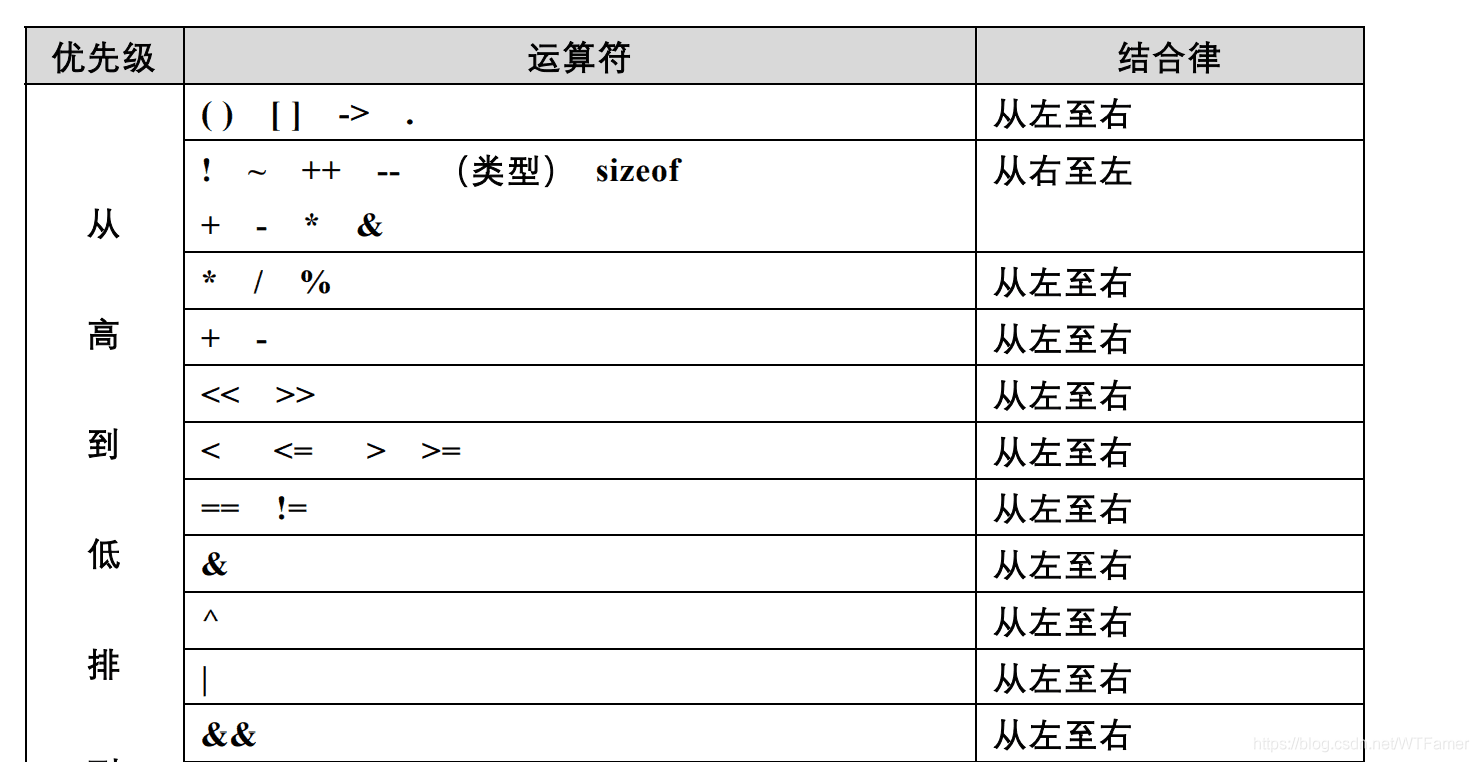

-
【規則 4-1-1】如果代碼行中的運算子比較多,用括號確定運算式的操作順序,避免使用默認的優先級,
- 例如:word = (high << 8) | low
- if ((a | b) && (a & c))
復合運算式
-
如 a = b = c = 0 這樣的運算式稱為復合運算式,允許復合運算式存在的理由是:(1)書寫簡潔;(2)可以提高編譯效率,但要防止濫用復合運算式,
-
z 【規則 4-2-1】不要撰寫太復雜的復合運算式,
例如:
i = a >= b && c < d && c + f <= g + h ; // 復合運算式過于復雜 -
z 【規則 4-2-2】不要有多用途的復合運算式,
例如:d = (a = b + c) + r ;
該運算式既求 a 值又求 d 值,應該拆分為兩個獨立的陳述句:
a = b + c;
d = a + r;
- 【規則 4-2-3】不要把程式中的復合運算式與“真正的數學運算式”混淆, 例如:
if (a < b < c) // a < b < c 是數學運算式而不是程式運算式
并不表示 if ((a<b) && (b<c))
而是成了令人費解的 if ( (a<b)<c )
if陳述句_本節以“與零值比較”為例,展開討論, _
布爾變數與零值比較
- 【規則 4-3-1】不可將布爾變數直接與 TRUE、FALSE 或者 1、0 進行比較,
- 根據布爾型別的語意,零值為“假”(記為 FALSE),任何非零值都是“真”(記為TRUE),TRUE 的值究竟是什么并沒有統一的標準,例如 Visual C++ 將 TRUE 定義為1,而 Visual Basic 則將 TRUE 定義為-1,
- 假設布爾變數名字為 flag,它與零值比較的標準 if 陳述句如下:
- if (flag) 表示 flag 為真
- if (!flag) 表示 flag 為假
整型變數與零值比較
- 【規則 4-3-2】應當將整型變數用“==”或“!=”直接與 0 比較,
- 假設整型變數的名字為 value,它與零值比較的標準 if 陳述句如下:
- if (value == 0)
- if (value != 0)
浮點變數與零值比較
- 【規則 4-3-3】不可將浮點變數用“==”或“!=”與任何數字比較,
- 千萬要留意,無論是 float 還是 double 型別的變數,都有精度限制,
- 所以一定要避免將浮點變數用“==”或“!=”與數字比較,應該設法轉化成“>=”或“<=”形式,
- 假設浮點變數的名字為 x,應當將 if (x == 0.0) 隱含錯誤的比較
- 轉化為 if ((x>=-EPSINON) && (x<=EPSINON))
- 其中 EPSINON 是允許的誤差(即精度),
指標變數與零值比較
- 【規則 4-3-4】應當將指標變數用“==”或“!=”與 NULL 比較,指標變數的零值是“空”(記為 NULL
- 盡管 NULL 的值與 0 相同但是兩者意義不同,假設指標變數的名字為 p,它與零值比較的標準 if 陳述句如下:
- if (p == NULL) // p 與 NULL 顯式比較,強調 p 是指標變數 if (p != NULL)
4.4 回圈陳述句的效率
-
C++/C 回圈陳述句中,for 陳述句使用頻率最高,while 陳述句其次,do 陳述句很少用,
- 本節重點論述回圈體的效率,提高回圈體效率的基本辦法是降低回圈體的復雜性,
-
【建議 4-4-1】在多重回圈中,如果有可能,應當將最長的回圈放在最內層,最短的回圈放在最外層,以減少 CPU 跨切回圈層的次數,
- for (col=0; col<5; col++ )
- {
- for (row=0; row<100; row++)
- {
- sum = sum + a[row][col];
- }
- }
- 【建議 4-4-2】如果回圈體記憶體在邏輯判斷,并且回圈次數很大,宜將邏輯判斷移到回圈體的外面,
- 示例 4-4?的程式比示例 4-4(d)多執行了 N-1 次邏輯判斷,并且由于前者老要進行邏輯判斷,打斷了回圈“流水線”作業,使得編譯器不能對回圈進行優化處理,降低了效率,
- for (i=0; i<N; i++) *C
- {
- if (condition)
- DoSomething();
- else
- DoOtherthing();
- }
- if (condition) *D
- {
- for (i=0; i<N; i++)
- DoSomething();
- }
- else
- {
- for (i=0; i<N; i++)
- DoOtherthing();
- }
4.5 for 陳述句的回圈控制變數
- 【規則 4-5-1】不可在 for 回圈體內修改回圈變數,防止 for 回圈失去控制,
4.6 switch 陳述句
- switch 是多分支選擇陳述句,而 if 陳述句只有兩個分支可供選擇,
- 雖然可以用嵌套的if 陳述句來實作多分支選擇,但那樣的程式冗長難讀,這是 switch 陳述句存在的理由,
- switch (variable)
- {
- case value1 : …
- break;
- case value2 : …
- break;
- ….
- default : …
- break;
- }
- 【規則 4-6-1】每個 case 陳述句的結尾不要忘了加 break,否則將導致多個分支重疊(除非有意使多個分支重疊),
- 【規則 4-6-2】不要忘記最后那個 default 分支,即使程式真的不需要 default 處理,也應該保留陳述句 default : break; 這樣做并非多此一舉,而是為了防止別人誤以為你忘了 default 處理,
第五章 常量
5.1 為什么需要常量
- 如果不使用常量,直接在程式中填寫數字或字串,將會有什么麻煩?
- (1) 程式的可讀性(可理解性)變差,程式員自己會忘記那些數字或字符什么意思,用戶則更加不知它們從何處來、表示什么,
- (2) 在程式的很多地方輸入同樣的數字或字串,難保不發生書寫錯誤,
- (3) 如果要修改數字或字串,則會在很多地方改動,既麻煩又容易出錯,

5.2 const 與 #define 的比較
-
(1) const 常量有資料型別,而宏常量沒有資料型別,編譯器可以對前者進行型別安全檢查,而對后者只進行字符替換,沒有型別安全檢查,并且在字符替換可能會產生意料不到的錯誤(邊際效應),
-
(2) 有些集成化的除錯工具可以對 const 常量進行除錯,但是不能對宏常量進行除錯,
-
【規則 5-2-1】在 C++ 程式中只使用 const 常量而不使用宏常量,即 const 常量完全取代宏常量,
5.3 常量定義規則
- 【規則 5-3-1】需要對外公開的常量放在頭檔案中,不需要對外公開的常量在定義檔案的頭部,為便于管理,可以把不同模塊的常量集中存放在一個公共的頭檔案中,
- 【規則 5-3-2】如果某一常量與其它常量密切相關,應在定義中包含這種關系,而不應給出一些孤立的值,
- 例如:
- const float RADIUS = 100;
- const float DIAMETER = RADIUS * 2;
5.4 類中的常量
- 列舉常量不會占用物件的存盤空間,它們在編譯時被全部求值,列舉常量的缺點是:它的隱含資料型別是整數,其最大值有限,且不能表示浮點數(如 PI=3.14159),

第六章 函式設計
這里有一個很細的講解
【C語言從青銅到王者】第二篇·詳解函式
- C 語言中,函式的引數和回傳值的傳遞方式有兩種
- 值傳遞(pass by value)和
- 指標傳遞(pass by pointer),
- C++ 語言中多了參考傳遞(pass by reference),由于參考傳遞的性質象指標傳遞,而使用方式卻象值傳遞,
引數的規則
- 【規則 6-1-1】引數的書寫要完整,不要貪圖省事只寫引數的型別而省略引數名字,如果函式沒有引數,則用 void 填充
- 【規則 6-1-2】引數命名要恰當,順序要合理,
- void StringCopy( char *strDestination,char *strSource);
- 【規則 6-1-3】如果引數是指標,且僅作輸入用,則應在型別前加 const,以防止該指標在函式體內被意外修改,
void StringCopy(char *strDestination,const char *strSource);- 【規則 6-1-4】如果輸入引數以值傳遞的方式傳遞物件,則宜改用“const &”方式來傳遞,這樣可以省去臨時物件的構造和析構程序,從而提高效率,
6.2 回傳值的規則
-
【規則 6-2-1】不要省略回傳值的型別
- C 語言中,凡不加型別說明的函式,一律自動按整型處理,這樣做不會有什么好處,卻容易被誤解為 void 型別
- C++語言有很嚴格的型別安全檢查,不允許上述情況發生,由于C++程式可以呼叫C 函式,為了避免混亂,規定任何 C++/ C 函式都必須有型別,
- 如果函式沒有回傳值,那么應宣告為 void 型別
-
如果 getchar 碰到檔案結束標志或發生讀錯誤,它必須回傳一個標志 EOF,為了區別于正常的字符,只好將 EOF 定義為負數(通常為負 1),因此函式 getchar 就成了 int 型別,
-

6.3 函式內部實作的規則
-
函式的出口入口處對引數的有效性進行檢查
-

-
編譯器直接把臨時物件創建并初始化在外部存盤單元中,省去了拷貝和析構的化費,提高了效率,
-

6.4 其他建議
- 【建議 6-4-1】函式的功能要單一,不要設計多用途的函式,
- 【建議 6-4-2】函式體的規模要小,盡量控制在 50 行代碼之內,
- 建議 6-4-3】盡量避免函式帶有“記憶”功能,如:static
6.5 使用斷言
- 程式一般分為 Debug 版本和 Release 版本,Debug 版本用于內部除錯,Release 版本發行給用戶使用,
- 斷言 assert 是僅在 Debug 版本起作用的宏,它用于檢查“不應該”發生的情況,
- 而是宏,程式員可以把assert 看成一個在任何系統狀態下都可以安全使用的無害測驗手段,

第 7 章 記憶體管理
-
640K ought to be enough for everybody — Bill Gates 1981
-
記憶體分配方式有三種:
- (1) 從靜態存盤區域分配,記憶體在程式編譯的時候就已經分配好,這塊記憶體在程式的整個運行期間都存在,例如全域變數,static 變數,
- (2) 在堆疊上創建,在執行函式時,函式內區域變數的存盤單元都可以在堆疊上創建,函式執行結束時這些存盤單元自動被釋放,堆疊記憶體分配運算內置于處理器的指令集中,效率很高,但是分配的記憶體容量有限,
- (3) 從堆上分配,亦稱動態記憶體分配,程式在運行的時候用 malloc 或 new 申請任意多少的記憶體,程式員自己負責在何時用 free 或 delete 釋放記憶體,動態記憶體的生存期由我們決定,使用非常靈活,但問題也最多
-
要對堆區開辟的記憶體判斷是否為NULL
- 開辟的記憶體要進行初始化
- 注意初始化成功時不要越界
- 動態記憶體的申請與釋放必須配對,程式中 malloc 與 free 的使用次數一定要相同,
- 注意不要回傳指向“堆疊記憶體”的“指標”
- 將指標設定為 NULL
7.3 指標與陣列的對比
-
陣列要么在靜態存盤區被創建(如全域陣列),要么在堆疊上被創建,陣列名對應著(而不是指向)一塊記憶體,其地址與容量在生命期內保持不變,只有陣列的內容可以改變,
-
指標可以隨時指向任意型別的記憶體塊,它的特征是“可變”,所以我們常用指標來高質量 C++/C 編程指南,操作動態記憶體,指標遠比陣列靈活,但也更危險
-
指標 p 指向常量字串“world”(位于靜態存盤區,內容為 world\0),
常量字串的內容是不可以被修改的,從語法上看,編譯器并不覺得陳述句 p[0]= ‘X’有什么不妥,但是該陳述句企圖修改常量字串的內容而導致運行錯誤

-
陣列之間比較用 strcmp ,賦值用strcpy,
-

-
sizeof(字串) ,’\0’也算字串大小,
7.4 指標引數是如何傳遞記憶體的?
- 用“指向指標的指標”

- 用函式回傳值來傳遞動態記憶體,這種方法更加簡單
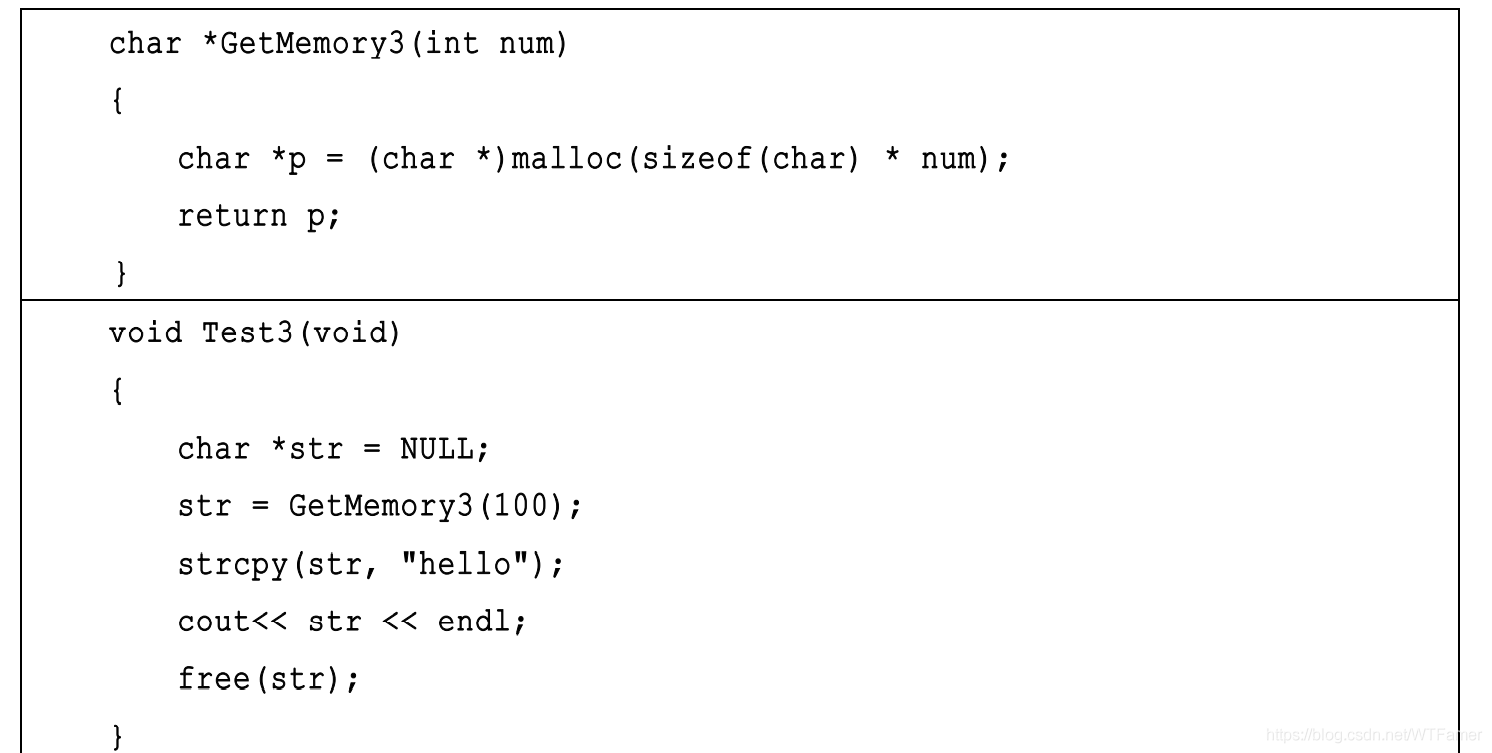
- 函式 Test5 運行雖然不會出錯,但是函式 GetString2 的設計概念卻是錯誤的, 因為 GetString2 內的“hello world”是常量字串,位于靜態存盤區,它在程式生命期內恒定不變,無論什么時候呼叫 GetString2,它回傳的始終是同一個“只讀”的記憶體塊,
-
- “堆疊指標”

7.5 free 和 delete 把指標怎么啦
- 別看 free 和 delete 的名字惡狠狠的(尤其是 delete),它們只是把指標所指的記憶體給釋放掉,但并沒有把指標本身干掉

7.6 切記要初始化指標,釋放指標后要置成空指標,
- 要么將指標設定為 NULL,要么讓它指向合法的記憶體,例如
char *p = NULL; *
char *str = (char *) malloc(100);
- 不要越界訪問
7.8 有了 malloc/free 為什么還要 new/delete
- 待定
7.9 記憶體耗盡怎么辦?
- 如果在申請動態記憶體時找不到足夠大的記憶體塊,malloc 和 new 將回傳 NULL 指標,宣告記憶體申請失敗,通常有三種方式處理“記憶體耗盡”問題,
(1)判斷指標是否為 NULL,如果是則馬上用 return 陳述句終止本函式,例如:
void Func(void)
{
A *a = new A;
if(a == NULL)
{
return;
}
…
}
(2)判斷指標是否為 NULL,如果是則馬上用 exit(1)終止整個程式的運行,例如:
void Func(void)
{
A *a = new A; *
if(a == NULL)
{
cout << “Memory Exhausted” << endl;
exit(1);
}
…
}
(3)為 new 和 malloc 設定例外處理函式,例如 Visual C++可以用_set_new_hander 函_數為 new 設定用戶自己定義的例外處理函式,也可以讓 malloc 享用與 new 相同的例外處理函式,詳細內容請參考 C++使用手冊
-
上述(1)(2)方式使用最普遍,如果一個函式內有多處需要申請動態記憶體,那么方式(1)就顯得力不從心(釋放記憶體很麻煩),應該用方式(2)來處理,很多人不忍心用 exit(1),問:“不撰寫出錯處理程式,讓作業系統自己解決行不行?”
-
不行,如果發生“記憶體耗盡”這樣的事情,一般說來應用程式已經無藥可救,如果不用 exit(1) 把壞程式殺死,它可能會害死作業系統,道理如同:如果不把歹徒擊斃,歹徒在老死之前會犯下更多的罪.
-
有一個很重要的現象要告訴大家,對于 32 位以上的應用程式而言,無論怎樣使用malloc 與 new,幾乎不可能導致“記憶體耗盡”,我在 Windows 98 下用 Visual C++撰寫了測驗程式,見示例 7-9,這個程式會無休止地運行下去,根本不會終止,因為 32 位作業系統支持“虛存”,記憶體用完了,自動用硬碟空間頂替,我只聽到硬碟嘎吱嘎吱地響,Window 98 已經累得對鍵盤、滑鼠毫無反應
試圖耗盡作業系統的記憶體
void main(void)
{
float *p = NULL;
while(TRUE)
{
p = new float[1000000];
cout << “eat memory” << endl;
if(p==NULL)
exit(1);
}
}
7.10 malloc/free 的使用要點
- 函式 malloc 的原型如下:
void * malloc(size_t size);
用 malloc 申請一塊長度為 length 的整數型別的記憶體,程式如下:
int *p = (int *) malloc(sizeof(int) * length);


7.11 new/delete 的使用要點
待定
7.12 一些心得體會
- (1)越是怕指標,就越要使用指標,不會正確使用指標,肯定算不上是合格的程式員,
- (2)必須養成“使用除錯器逐步跟蹤程式”的習慣,只有這樣才能發現問題的本質
第 8 章 C++函式的高級特性
- 對比于 C 語言的函式,C++增加了多載(overloaded)、行內(inline)、const 和 virtual四種新機制,
- 其中多載和行內機制既可用于全域函式也可用于類的成員函式,const 與virtual 機制僅用于類的成員函式
8.1 函式多載的概念
- 多載的起源
- 自 然語言中,一個詞可以有許多不同的含義,即該詞被多載了,人們可以通過背景關系來判斷該詞到底是哪種含義,“詞的多載”可以使語言更加簡練,例如“吃飯”的含義十分廣泛,人們沒有必要每次非得說清楚具體吃什么不可,別迂腐得象孔已己,說茴香豆的茴字有四種寫法,
- 在 C++程式中,可以將語意、功能相似的幾個函式用同一個名字表示,即函式多載,這樣便于記憶,提高了函式的易用性,這是 C++語言采用多載機制的一個理由,例如示例 8-1-1 中的函式 EatBeef,EatFish,EatChicken 可以用同一個函式名 Eat 表示,用不同型別的引數加以區別,
void EatBeef(…); 可以改為 void Eat(Beef …);
void EatFish(…); 可以改為 void Eat(Fish …);
void EatChicken(…); 可以改為 void Eat(Chicken …);
-
多載是如何實作的?
- 幾個同名的多載函式仍然是不同的函式,它們是如何區分的呢?我們自然想到函式
- 介面的兩個要素:引數與回傳值,
- 如果同名函式的引數不同(包括型別、順序不同),那么容易區別出它們是不同的函式,

-
所以只能靠引數而不能靠回傳值型別的不同來區分多載函式,編譯器根據引數為每個多載函式產生不同的內部識別符號,例如編譯器為示例 8-1-1 中的三個 Eat 函式產生象_eat_beef、_eat_fish、_eat_chicken 之類的內部識別符號(不同的編譯器可能產生不同風格的內部識別符號),
-
如果 C++程式要呼叫已經被編譯后的 C 函式,該怎么辦?假設某個 C 函式的宣告如下:void foo(int x, int y);
- 該函式被 C 編譯器編譯后在庫中的名字為_foo,而 C++編譯器則會產生像_foo_int_int之類的名字用來支持函式多載和型別安全連接,由于編譯后的名字不同,C++程式不能直接呼叫 C 函式,
- C++提供了一個 C 連接交換指定符號 extern“C”來解決這個問題,
例如:
extern “C”
{
void foo(int x, int y);
… 其它函式
}
或者寫成
extern “C”
{
#include “myheader.h”
… 其它 C 頭檔案
}
-
這就告訴 C++編譯譯器,函式 foo 是個 C 連接,應該到庫中找名字_foo 而不是找_foo_int_int,C++編譯器開發商已經對 C 標準庫的頭檔案作了 extern“C”處理,所以我們可以用#include 直接參考這些頭檔案,
-
注意并不是兩個函式的名字相同就能構成多載,全域函式和類的成員函式同名不算多載,因為函式的作用域不同,例如:
void Print(…); 全域函式
class A
{…
void Print(…); // 成員函式
}
-
不論兩個 Print 函式的引數是否不同,如果類的某個成員函式要呼叫全域函式 Print,為了與成員函式 Print 區別,全域函式被呼叫時應加‘::’標志,
- 如
::Print(…);// 表示 Print 是全域函式而非成員函式
- 如
-
當心隱式型別轉換導致多載函式產生二義性
-
示例 8-1-3 中,第一個 output 函式的引數是 int 型別,第二個 output 函式的引數是 float 型別,由于數字本身沒有型別,將數字當作引數時將自動進行型別轉換(稱為隱式型別轉換),
- 陳述句 output(0.5)將產生編譯錯誤,因為編譯器不知道該將 0.5 轉換成int 還是 float 型別的引數,隱式型別轉換在很多地方可以簡化程式的書寫,但是也可能留下隱患,
- 示例 8-1-3 隱式型別轉換導致多載函式產生二義性 :
#include <iostream.h>
void output( int x); // 函式宣告
void output( float x); // 函式宣告
void output( int x)
{
cout << " output int " << x << endl ;
}
void output( float x)
{
cout << " output float " << x << endl ;
}
void main(void)
{
int x = 1;
float y = 1.0;
output(x); output int 1
output(y); output float 1
output(1); output int 1
output(0.5); error! ambiguous call, 因為自動型別轉換
output(int(0.5)); output int 0
output(float(0.5)); output float 0.5
}
8.2 成員函式的多載、覆寫與隱藏、
- 多載與覆寫
- 成員函式被多載的特征:
- (1)相同的范圍(在同一個類中);
- (2)函式名字相同;
- (3)引數不同;
- (4)virtual 關鍵字可有可無,
- 覆寫是指派生類函式覆寫基類函式,特征是:
- (1)不同的范圍(分別位于派生類與基類);
- (2)函式名字相同;
- (3)引數相同;
- (4)基類函式必須有 virtual 關鍵字,
其余待定
- (4)基類函式必須有 virtual 關鍵字,
- 成員函式被多載的特征:
8.3 引數的預設值
待定
8.4 運算子多載
待定
8.5 函式行內
待定
8.6 一些心得體會
- C++ 語言中的多載、行內、預設引數、隱式轉換等機制展現了很多優點,但是這些優點的背后都隱藏著一些隱患,正如人們的飲食,少食和暴食都不可取,應當恰到好處,我們要辨證地看待 C++的新機制,應該恰如其分地使用它們,雖然這會使我們編程時多費一些心思,少了一些痛快,但這才是編程的藝術,
第 9 章 類的建構式、解構式與賦值函式
待定
第 10 章 類的繼承與組合
待定
第 11 章 其它編程經驗
使用 const 提高函式的健壯性
- const 更大的魅力是它可以修飾函式的引數、回傳值,甚至函式的定義體,const 是 constant 的縮寫,“恒定不變”的意思,
- 被 const 修飾的東西都受到強制保護,可以預防意外的變動,能提高程式的健壯性,所以很多 C++程式設計書籍建議:“Use const whenever you need”,
- 用 const 修飾函式的引數
- 輸出引數不能用 const

- const 只能修飾輸入引數:
- 如果輸入引數采用“指標傳遞”,那么加 const 修飾可以防止意外地改動該指標,起到保護作用,
- 如果輸入引數采用“值傳遞”,由于函式將自動產生臨時變數用于復制該引數,該輸入引數本來就無需保護,所以不要加 const 修飾,

- 總結:

用 const 修飾函式的回傳值
- 如果給以“指標傳遞”方式的函式回傳值加 const 修飾,那么函式回傳值(即指標)的內容不能被修改,該回傳值只能被賦給加 const 修飾的同型別指標,
- 例如函式
- const char * GetString(void); *
- 如下陳述句將出現編譯錯誤:
- char *str = GetString(); *
- 正確的用法是
- const char *str = GetString();*
- 如果函式回傳值采用“值傳遞方式”,由于函式會把回傳值復制到外部臨時的存盤單元中,加 const 修飾沒有任何價值, 例如不要把函式 int GetInt(void) 寫成 const int GetInt(void),
提高程式的效率
程式的時間效率是指運行速度,空間效率是指程式占用記憶體或者外存的狀況,
全域效率是指站在整個系統的角度上考慮的效率,區域效率是指站在模塊或函式角度上考慮的效率,
- 【規則 11-2-1】不要一味地追求程式的效率,應當在滿足正確性、可靠性、健壯性、可讀性等質量因素的前提下,設法提高程式的效率,
- 【規則 11-2-2】以提高程式的全域效率為主,提高區域效率為輔,
- 【規則 11-2-3】在優化程式的效率時,應當先找出限制效率的“瓶頸”,不要在無關緊要之處優化,
- 【規則 11-2-4】先優化資料結構和演算法,再優化執行代碼,
- 【規則 11-2-5】有時候時間效率和空間效率可能對立,此時應當分析那個更重要,作出適當的折衷,例如多花費一些記憶體來提高性能,
- 【規則 11-2-6】不要追求緊湊的代碼,因為緊湊的代碼并不能產生高效的機器碼,
一些有益的建議
-
當心那些視覺上不易分辨的運算子發生書寫錯誤,我們經常會把“==”誤寫成“=”,象“||”、“&&”、“<=”、“>=”這類符號也很容易發生“丟 1”失誤,然而編譯器卻不一定能自動指出這類錯誤,
-
變數(指標、陣列)被創建之后應當及時把它們初始化,以防止把未被初始化的變數當成右值使用,
-
當心變數的初值、預設值錯誤,或者精度不夠
-
當心資料型別轉換發生錯誤,盡量使用顯式的資料型別轉換(讓人們知道發生了什么事),避免讓編譯器輕悄悄地進行隱式的資料型別轉換,
-
當心變數發生上溢或下溢,陣列的下標越界,
-
當心忘記撰寫錯誤處理程式,當心錯誤處理程式本身有誤,
-
當心檔案 I/O 有錯誤,
-
避免撰寫技巧性很高代碼,
-
不要設計面面俱到、非常靈活的資料結構,
-
盡量使用標準庫函式,不要“發明”已經存在的庫函式,
-
盡量不要使用與具體硬體或軟體環境關系密切的變數,
-
把編譯器的選擇項設定為最嚴格狀態,
-
如果可能的話,使用 PC-Lint、LogiScope 等工具進行代碼審查,
GG.本文結尾語:
略顯倉促:
如有和原文較大差異的地方、或不完善的地方、或不明白的地方,可以百度、或者評論區柳巖…!
三聯,三聯,三聯…
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279633.html
標籤:其他