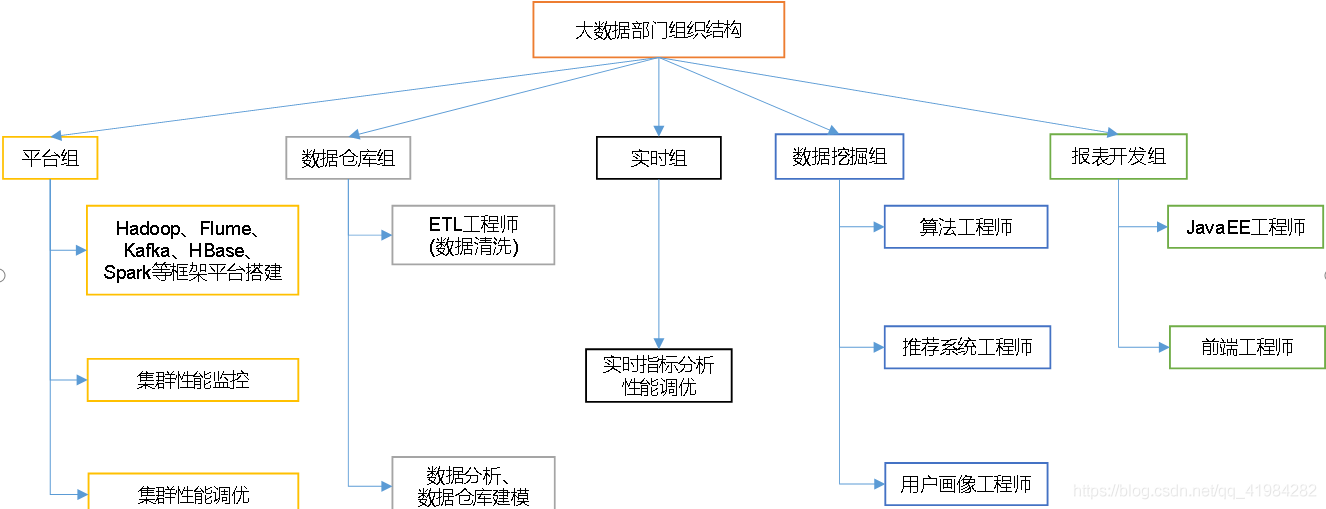
1 大資料部門組織結構
2 Hadoop概述
2.1 Hadoop發展史
Hadoop是由Apache基金會所開發的分布式系統基礎架構,主要解決海量資料的存盤和海量資料的分析計算問題,Lucene框架是Doug Cutting開創的開源軟體,用Java語言開發,實作與Google類似的全文搜索功能,它提供了全文檢索引擎的架構,包括完整的查詢引擎和索引引擎,2001年底Lucene成為Apache基金會的一個子專案,對于海量資料的場景,Lucene面對與Google同樣的困難,存盤資料困難,檢索速度慢,Google是Hadoop的思想之源,Google在大資料方面的三篇論文,

2003-2004年,Google公開了部分GFS和MapReduce思想的細節,以此為基礎Doug Cutting等人用了2年業余時間實作了DFS和MapReduce機制,使得Nutch性能飆升,
2005年Hadoop作為Lucene的子專案Nutch的一部分正式引入Apache基金會,
2006年3月份,MapReduce和Nutch Distributed File System(NDFS)分別被納入到Hadoop專案中,Hadoop正式誕生,標志著大資料時代來臨,
名字來源于Doug Cutting兒子的玩具大象

2.2 Hadoop三大發行版本
Hadoop三大發行版本:Apache、Cloudera、Hortonworks,
Apache版本最原始(最基礎)的版本,對于入門學習最好,
Cloudera內部集成了很多大資料框架,對應產品CDH,
Hortonworks檔案較好,對應產品HDP,
1)Apache Hadoop
官網地址:http://hadoop.apache.org/releases.html
下載地址:https://archive.apache.org/dist/hadoop/common/
2)Cloudera Hadoop
官網地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下載地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早將Hadoop商用的公司,為合作伙伴提供Hadoop的商用解決方案,主要是包括支持、咨詢服務、培訓,
(2)2009年Hadoop的創始人Doug Cutting也加盟Cloudera公司,Cloudera產品主要為CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop發行版,完全開源,比Apache Hadoop在兼容性,安全性,穩定性上有所增強,Cloudera的標價為每年每個節點10000美元,
(4)Cloudera Manager是集群的軟體分發及管理監控平臺,可以在幾個小時內部署好一個Hadoop集群,并對集群的節點及服務進行實時監控,
3)Hortonworks Hadoop
官網地址:https://hortonworks.com/products/data-center/hdp/
下載地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎與硅谷風投公司Benchmark Capital合資組建,
(2)公司成立之初就吸納了大約25名至30名專門研究Hadoop的雅虎工程師,上述工程師均在2005年開始協助雅虎開發Hadoop,貢獻了Hadoop80%的代碼,
(3)Hortonworks的主打產品是Hortonworks Data Platform(HDP),也同樣是100%開源的產品,HDP除常見的專案外還包括了Ambari,一款開源的安裝和管理系統,
(4)Hortonworks目前已經被Cloudera公司收購,
2.3 Hadoop的優勢
1)高可靠性:Hadoop底層維護多個資料副本,所以即使Hadoop某個計算元素或存盤出現故障,也不會導致資料的丟失,
2)高擴展性:在集群間分配任務資料,可方便的擴展數以千計的節點,
3)高效性:在MapReduce的思想下,Hadoop是并行作業的,以加快任務處理速度,
4)高容錯性:能夠自動將失敗的任務重新分配,
2.4 Hadoop的組成
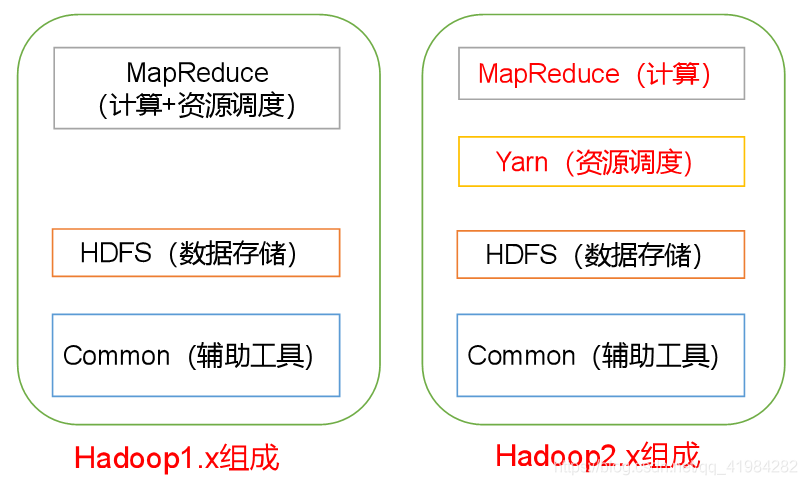
在Hadoop1.x時代,Hadoop中的MapReduce同時處理業務邏輯運算和資源的調度,耦合性較大,在Hadoop2.x時代,增加了Yarn,Yarn只負責資源的調度,MapReduce只負責運算,
2.4.1 HDFS架構概述
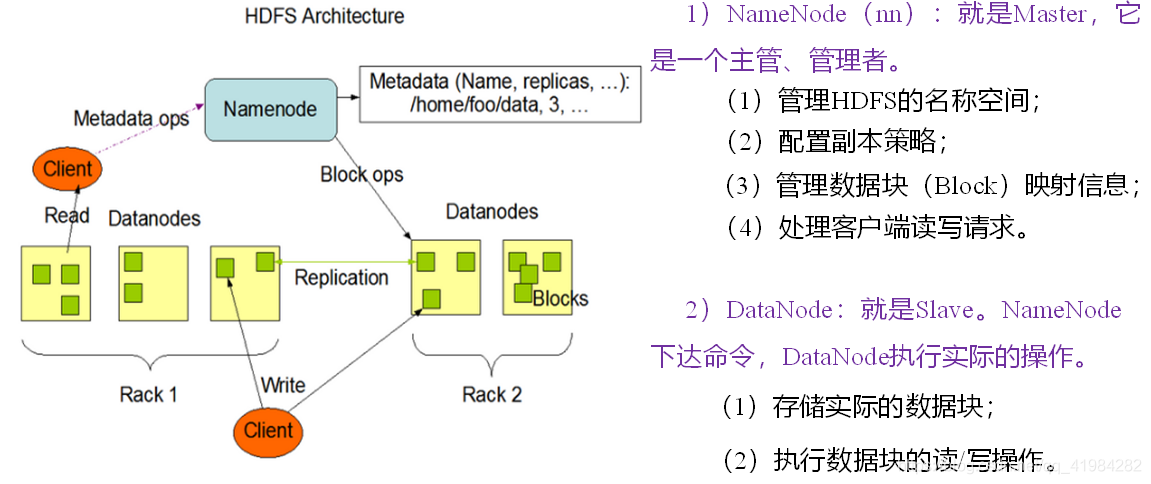
NameNode(nn):存盤檔案的元資料,如檔案名、檔案目錄結果、檔案屬性(生成時間、副本數、檔案權限),以及每個檔案的塊串列和塊所在的DataNode等,管理檔案系統命名空間的主服務器和管理客戶端對檔案的訪問組成,如打開,關閉和重命名檔案和目錄,負責管理檔案目錄、檔案和block的對應關系以及block和datanode的對應關系,維護目錄樹,接管用戶的請求,
DataNode(dn):在本地檔案系統存盤檔案塊資料,以及塊資料的校驗和,(資料節點)管理連接到它們運行的??節點的存盤,負責處理來自檔案系統客戶端的讀寫請求,DataNodes還執行塊創建,洗掉,
Client:(客戶端)代表用戶通過與nameNode和datanode互動來訪問整個檔案系統,HDFS對外開放檔案命名空間并允許用戶資料以檔案形式存盤,用戶通過客戶端(Client)與HDFS進行通訊互動,
Secondary NameNode(2nn):每隔一段時間對NameNode元資料備份,
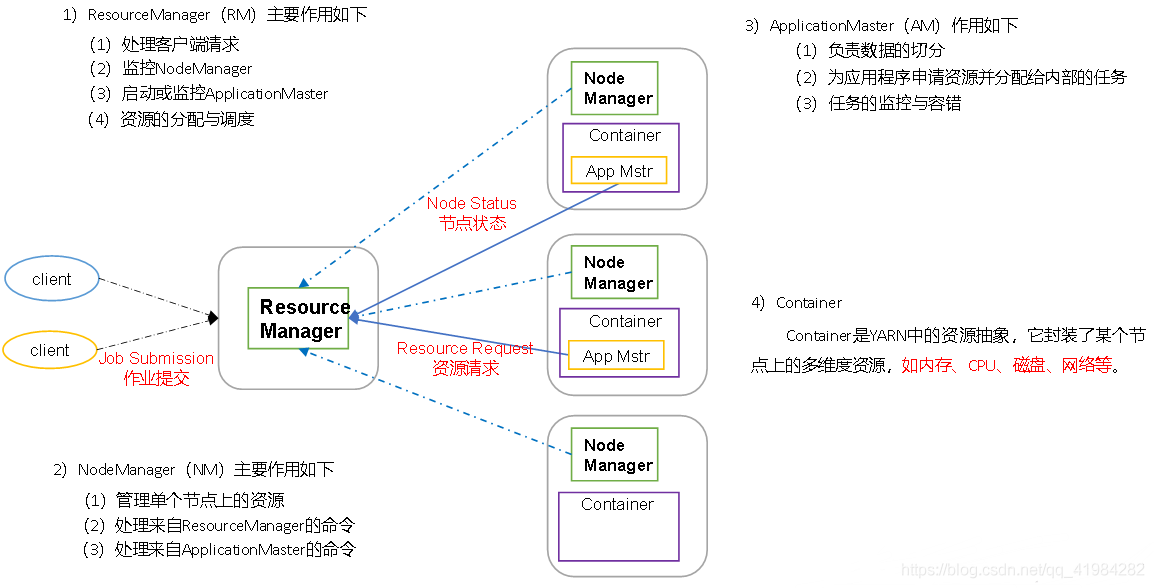
2.4.2 YARN架構概述
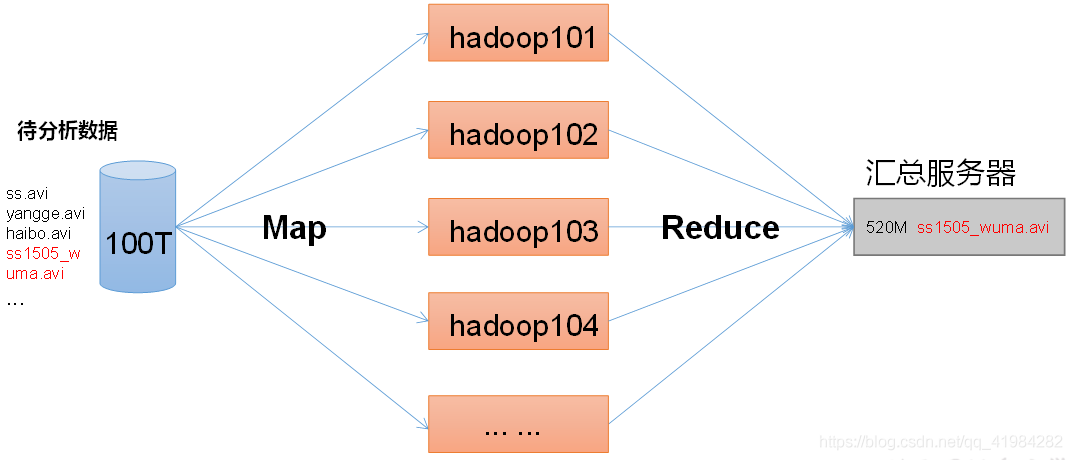
2.4.3 MapReduce架構概述
MapReduce將計算程序分為兩個階段:Map和Reduce
1)Map階段并行處理輸入資料
2)Reduce階段對Map結果進行匯總
2.5 大資料技術生態
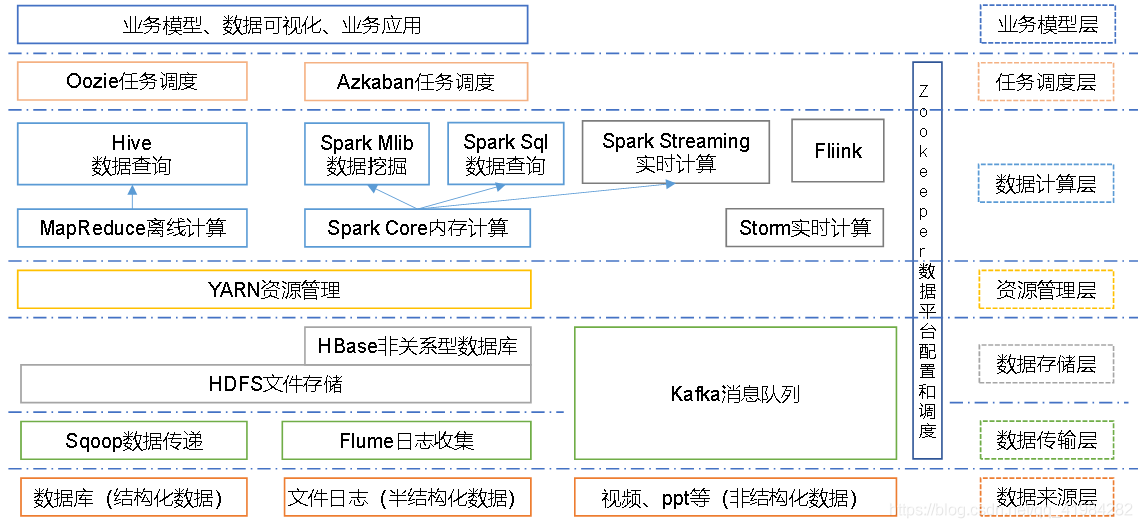
圖中涉及的技術名詞解釋如下:
1)Sqoop:Sqoop是一款開源的工具,主要用于在Hadoop、Hive與傳統的資料庫(MySql)間進行資料的傳遞,可以將一個關系型資料庫(例如 :MySQL,Oracle 等)中的資料導進到Hadoop的HDFS中,也可以將HDFS的資料導進到關系型資料庫中,
2)Flume:Flume是一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類資料發送方,用于收集資料;
3)Kafka:Kafka是一種高吞吐量的分布式發布訂閱訊息系統;
4)Storm:Storm用于“連續計算”,對資料流做連續查詢,在計算時就將結果以流的形式輸出給用戶,
5)Spark:Spark是當前最流行的開源大資料記憶體計算框架,可以基于Hadoop上存盤的大資料進行計算,
6)Flink:Flink是當前最流行的開源大資料記憶體計算框架,用于實時計算的場景較多,
7)Oozie:Oozie是一個管理Hdoop作業(job)的作業流程調度管理系統,
8)Hbase:HBase是一個分布式的、面向列的開源資料庫,HBase不同于一般的關系資料庫,它是一個適合于非結構化資料存盤的資料庫,
9)Hive:Hive是基于Hadoop的一個資料倉庫工具,可以將結構化的資料檔案映射為一張資料庫表,并提供簡單的SQL查詢功能,可以將SQL陳述句轉換為MapReduce任務進行運行, 其優點是學習成本低,可以通過類SQL陳述句快速實作簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統計分析,
10)ZooKeeper:它是一個針對大型分布式系統的可靠協調系統,提供的功能包括:配置維護、名字服務、分布式同步、組服務等,
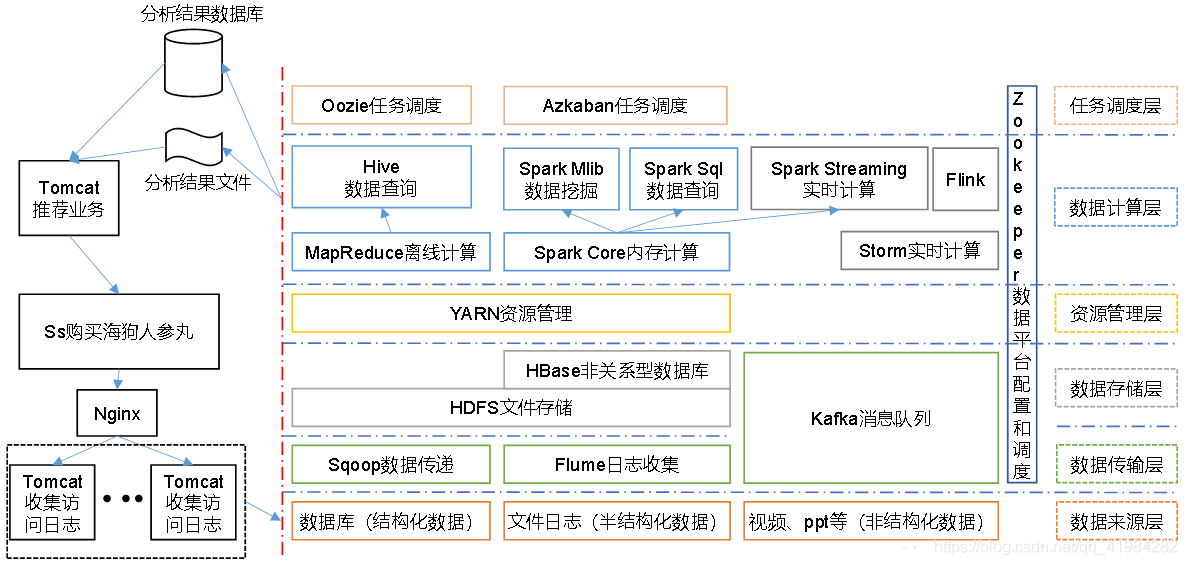
推薦系統框架圖
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279969.html
標籤:其他
上一篇:高級前端-Babel