目錄
- 1. 交換排序——冒泡排序
- 2. 交換排序——快速排序
- 3. 選擇排序——簡單選擇排序
- 4. 選擇排序——堆排序
- 什么是堆
- 堆排序基本思想
- 步驟圖解
- 代碼實作
- 5. 插入排序——簡單插入排序
- 6. 插入排序——希爾排序
- 7. 歸并排序
- 8. 基數排序
1. 交換排序——冒泡排序
從要排序序列的第一個元素開始,一次比較相鄰元素的值,發現逆序則交換,將值較大的元素逐漸從前向后移動,

public void bubbleSort(int[] arr){
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int t = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = t;
}
}
}
}
優化:如果某次排序中,沒有發生交換,則可結束排序
public void bubbleSort(int[] arr){
boolean flag = false;//表示沒有發生過交換
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int t = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = t;
flag = true;//發生交換
}
}
if (!flag)
break;
else
flag = false;//重置flag,進行下次判斷
}
}
- 時間復雜度:O(n^2)
- 穩定
2. 交換排序——快速排序
快速排序(Quicksort)是對冒泡排序的一種改進,基本思想是:通過一趟排序將要排序的資料分割成獨立的兩部分,其中一部分的所有資料都比另外一部分的所有資料都要小,然后再按此方法對這兩部分資料分別進行快速排序,整個排序程序可以遞回進行,以此達到整個資料變成有序序列

public static void quickSort(int[] arr, int left, int right) {
int l = left;
int r = right;
int pivot = arr[(left + right) / 2];
//while回圈是為了讓比pivot小的值放其左邊,比pivot大的值放其右邊
while (l < r) {
while (arr[l] < pivot)//直到找到比pivot小的數
l++;
while (arr[r] > pivot)//直到找到比pivot大的數
r--;
if (l >= r)//說明比pivot小的值都在其左邊,比pivot大的值都在其右邊
break;
//找到pivot左邊比其大的元素,右邊比其小的元素;進行交換
int t = arr[l];
arr[l] = arr[r];
arr[r] = t;
}
//如果l==r,則要l++、r--;否則會出現堆疊溢位
if (l == r) {
l++;
r--;
}
//向左遞回
if (left < r)
quickSort(arr, left, r);
//向右遞回
if (right > l)
quickSort(arr, l, right);
}
- 時間復雜度:O(nlog2n)
- 不穩定
3. 選擇排序——簡單選擇排序
基本思想:
- 第一次從 arr[0]~arr[n-1]中選取最小值,與 arr[0]交換
- 第二次從 arr[1]~arr[n-1]中選取最小值,與 arr[1]交換
- 第三次從 arr[2]~arr[n-1]中選取最小值,與 arr[2] 交換…
- 第 i 次從 arr[i-1]~arr[n-1]中選取最小值,與 arr[i-1]交換…
- 第 n-1 次從 arr[n-2]~arr[n-1]中選取最小值,與 arr[n-2]交換
總共通過 n-1 次,得到一個按排序碼從小到大排列的有序序列

public void selectSort(int[] arr){
for (int i = 0; i < arr.length - 1; i++) {
int min = arr[i];//假設當前值最小
int minIndex = i;//記錄最小值的索引
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < min) {
min = arr[j];
minIndex = j;
}
}
if (minIndex != i) {
arr[minIndex] = arr[i];
arr[i] = min;
}
}
}
- 時間復雜度:O(n^2)
- 不穩定
4. 選擇排序——堆排序
堆排序是利用
堆這種資料結構而設計的一種排序演算法,堆排序是一種選擇排序,它的最壞,最好,平均時間復雜度均為O(nlogn),它也是不穩定排序,
什么是堆
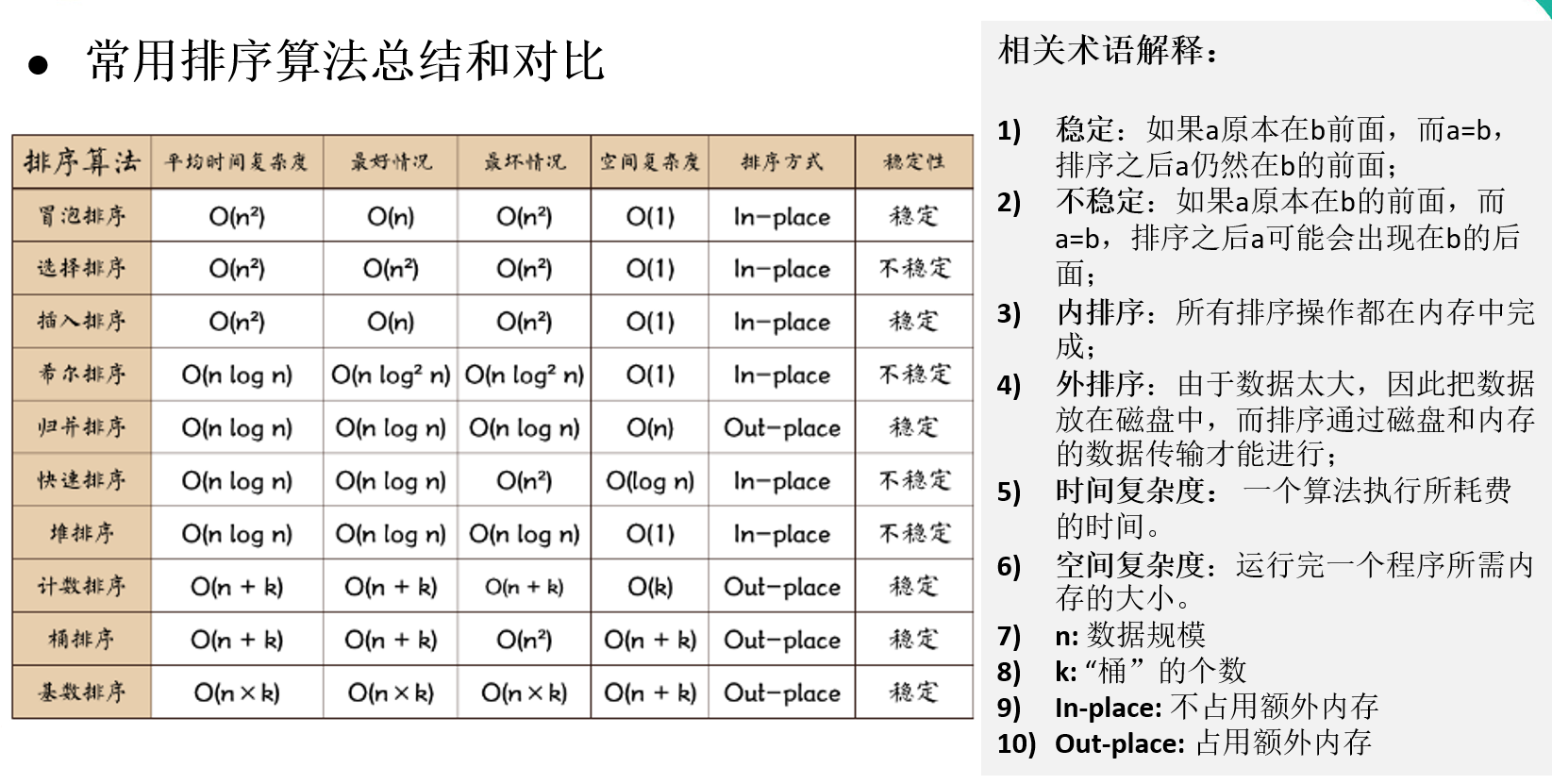
堆是具有以下性質的完全二叉樹
1?? 每個結點的值都大于或等于其左右孩子結點的值,稱為大頂堆(沒有要求結點的左孩子的值和右孩子的值的大小關系)
arr[i] >= arr[2*i+1] && arr[i] >= arr[2*i+2] //i對應第幾個節點,i從0開始編號

我們對堆中的結點按層進行編號,映射到陣列中就是下面這個樣子:

2?? 每個結點的值都小于或等于其左右孩子結點的值,稱為小頂堆
arr[i] <= arr[2*i+1] && arr[i] <= arr[2*i+2] //i對應第幾個節點,i從0開始編號
堆排序基本思想
- 將待排序序列構造成一個大頂堆
- 此時,整個序列的最大值就是堆頂的根節點,
- 將其與末尾元素進行交換,此時末尾就為最大值,
- 然后將剩余n-1個元素重新構造成一個堆,這樣會得到n個元素的次小值,如此反復執行,便能得到一個有序序列了,
一般升序采用大頂堆,降序采用小頂堆
步驟圖解
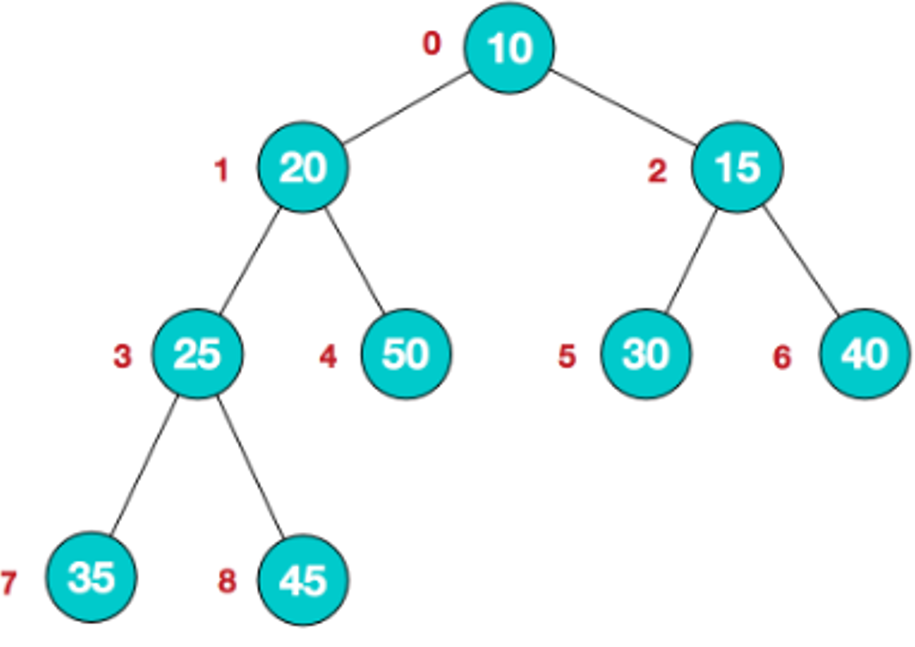
步驟一:構造初始堆,將給定無序序列構造成一個大頂堆(一般升序采用大頂堆,降序采用小頂堆)
原始的陣列 [4, 6, 8, 5, 9]
- 假設給定無序序列結構如下
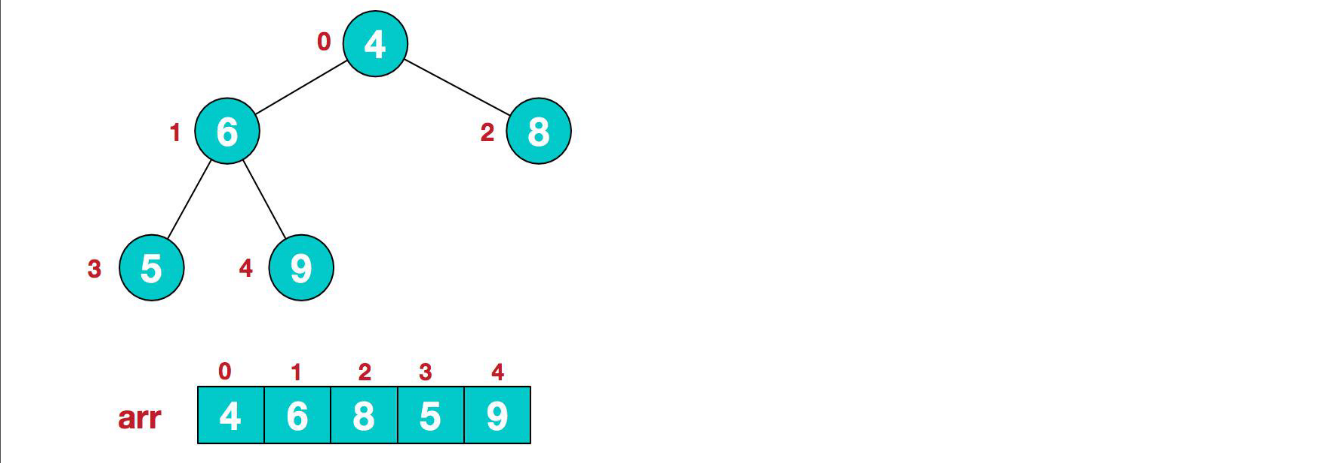
- 此時我們從最后一個非葉子結點開始(葉結點不用調整,第一個非葉子結點
arr.length/2-1=5/2-1=1,也就是下面的6結點),從左至右,從下至上進行調整
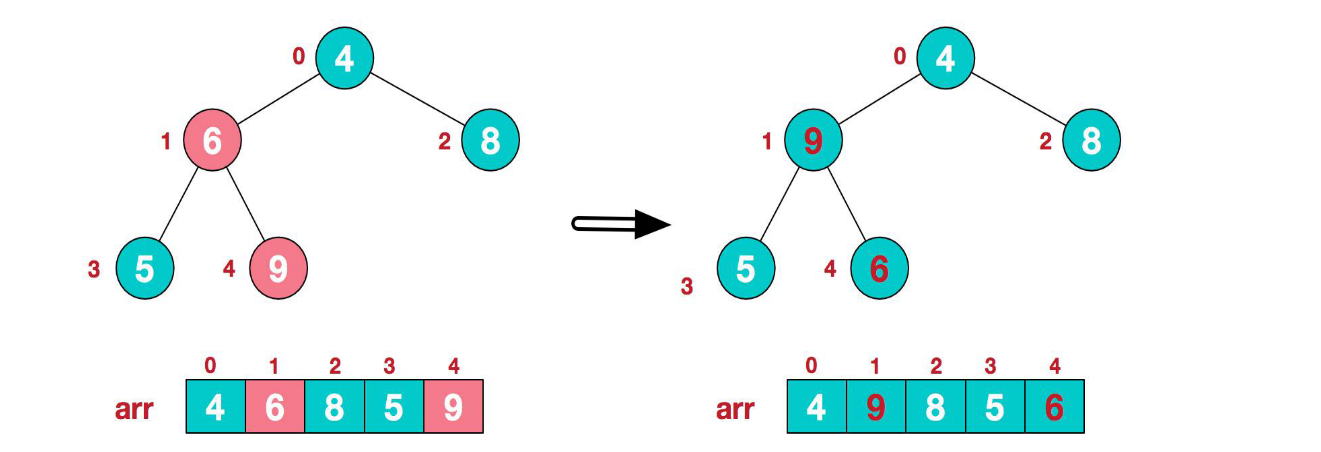
- 找到第二個非葉節點 4,由于[4,9,8]中 9 元素最大,4 和 9 交換
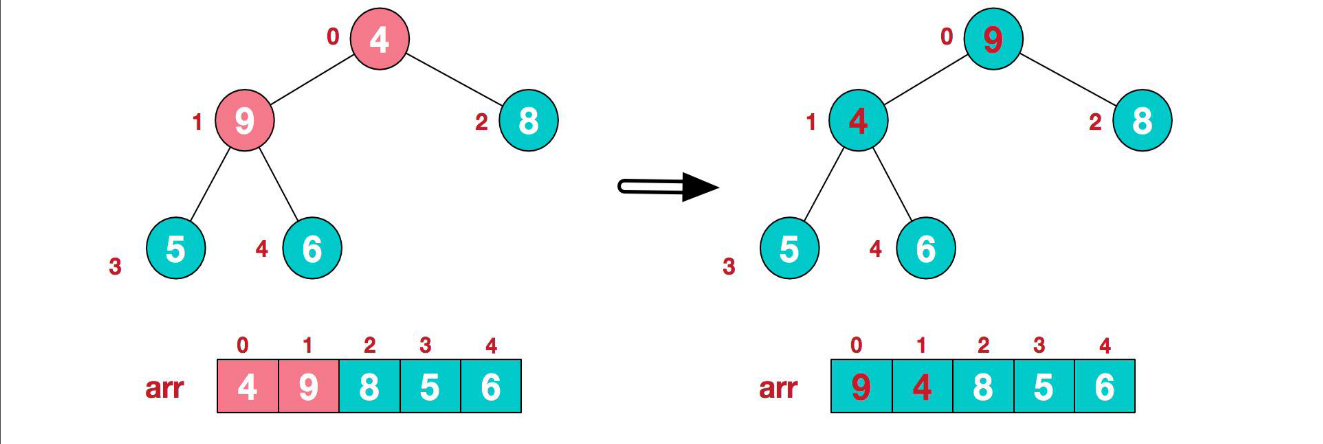
- 這時,交換導致了子根[4,5,6]結構混亂,繼續調整,[4,5,6]中 6 最大,交換 4 和 6
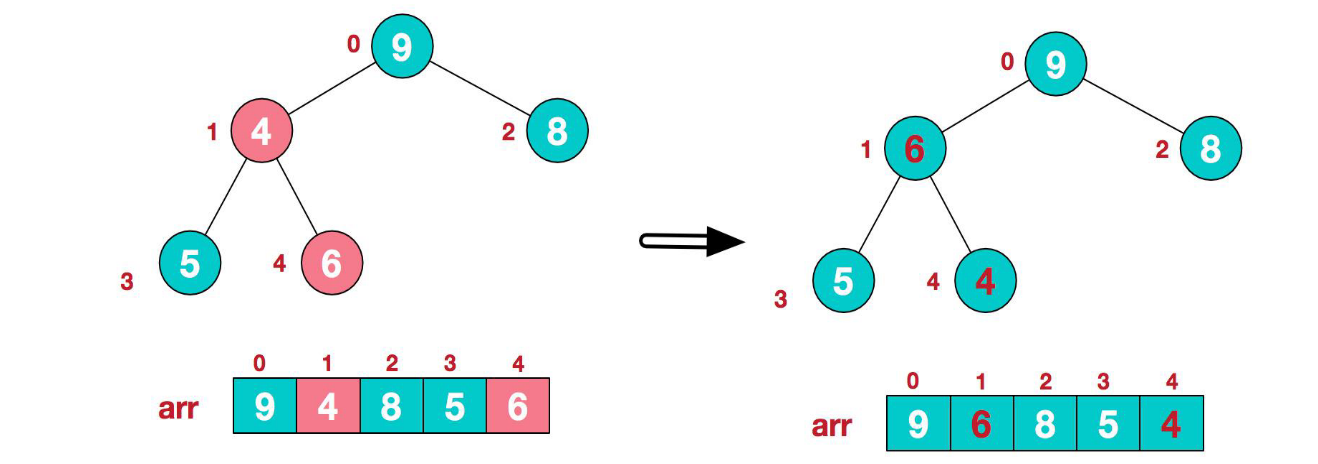
此時,我們就將一個無序序列構造成了一個大頂堆
步驟二:將堆頂元素與末尾元素進行交換,使末尾元素最大,然后繼續調整堆,再將堆頂元素與末尾元素交換,得到第二大元素,如此反復進行交換、重建、交換
- 將堆頂元素 9 和末尾元素 4 進行交換
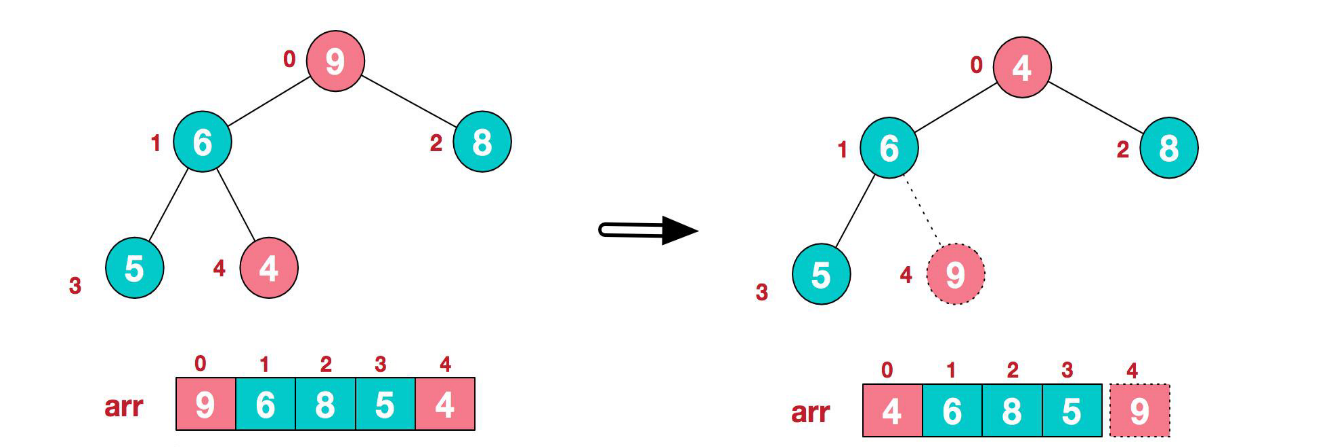
- 重新調整結構,使其繼續滿足堆定義
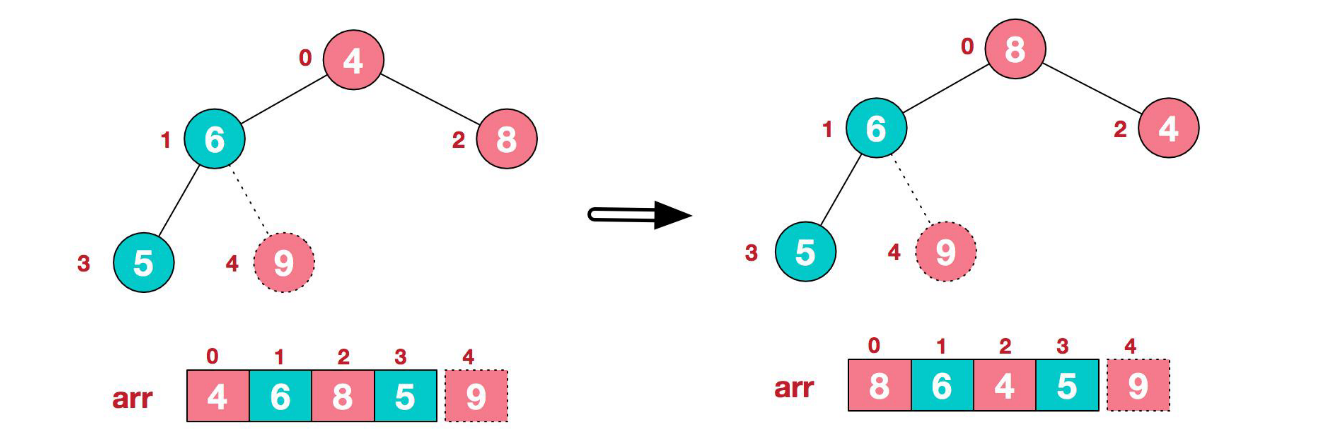
- 再將堆頂元素 8 與末尾元素 5 進行交換,得到第二大元素 8
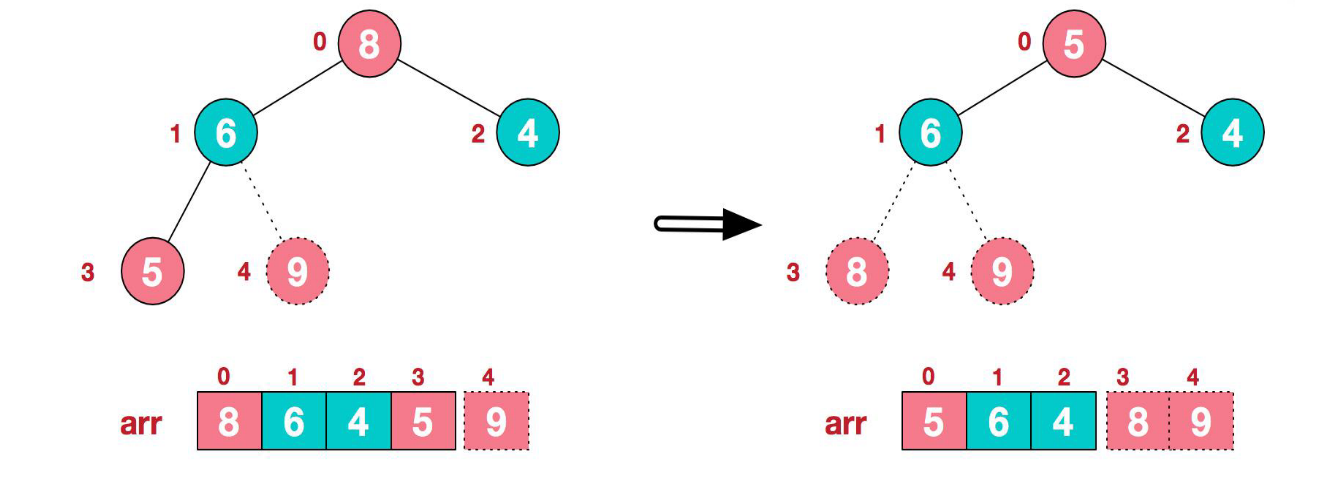
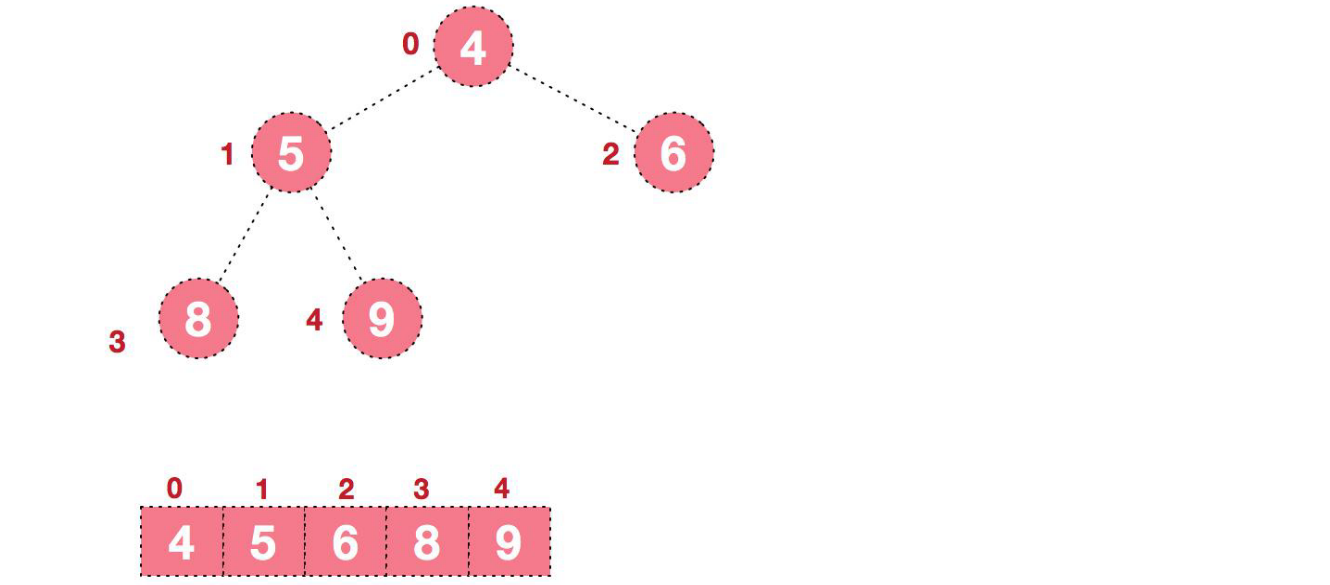
- 后續程序,繼續進行調整,交換,如此反復進行,最終使得整個序列有序
代碼實作
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
int[] arr = {3, 5, 2, 7, 8, 0, -1, 99};
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
//堆排序
public static void heapSort(int[] arr) {
//將無序序列構建成一個堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, arr.length);
}
//將堆頂元素和末尾元素交換,將最大元素放置陣列末端
//重新調整至堆結構,然后繼續將堆頂元素和當前末尾元素交換,以此往復
for (int i = arr.length - 1; i > 0; i--) {
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, i);
}
}
/**
* 將二叉樹調整為堆
*
* @param arr 待調整的陣列
* @param i 表示非葉子結點在陣列中索引
* @param length 表示對多少個元素繼續調整,length逐漸減少
*/
public static void adjustHeap(int[] arr, int i, int length) {
int temp = arr[i];
//k=2i+1是i的左子節點
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if (k + 1 < length && arr[k] < arr[k + 1])//左子節點的值<右子節點的值
k++;//指向右節點
if (arr[k] > temp) {//如果子結點的值>父節點的值
arr[i] = arr[k];//將較大的值賦給當前節點
i = k;//i指向k,繼續回圈比較
} else
break;
}
//for回圈后,已經將以i為父結點的樹的最大值,放在了頂部
arr[i] = temp;//將temp值放到調整后的位置
}
}
5. 插入排序——簡單插入排序
基本思想:把 n 個待排序的元素看成為一個
有序表和一個無序表,開始時 有序表 中只包含一個元素,無序表中包含有 n-1 個元素,排序程序中每次從無序表中取出第一個元素,與有序表中的元素進行比較,將它插入到有序表中的適當位置,使之成為新的有序表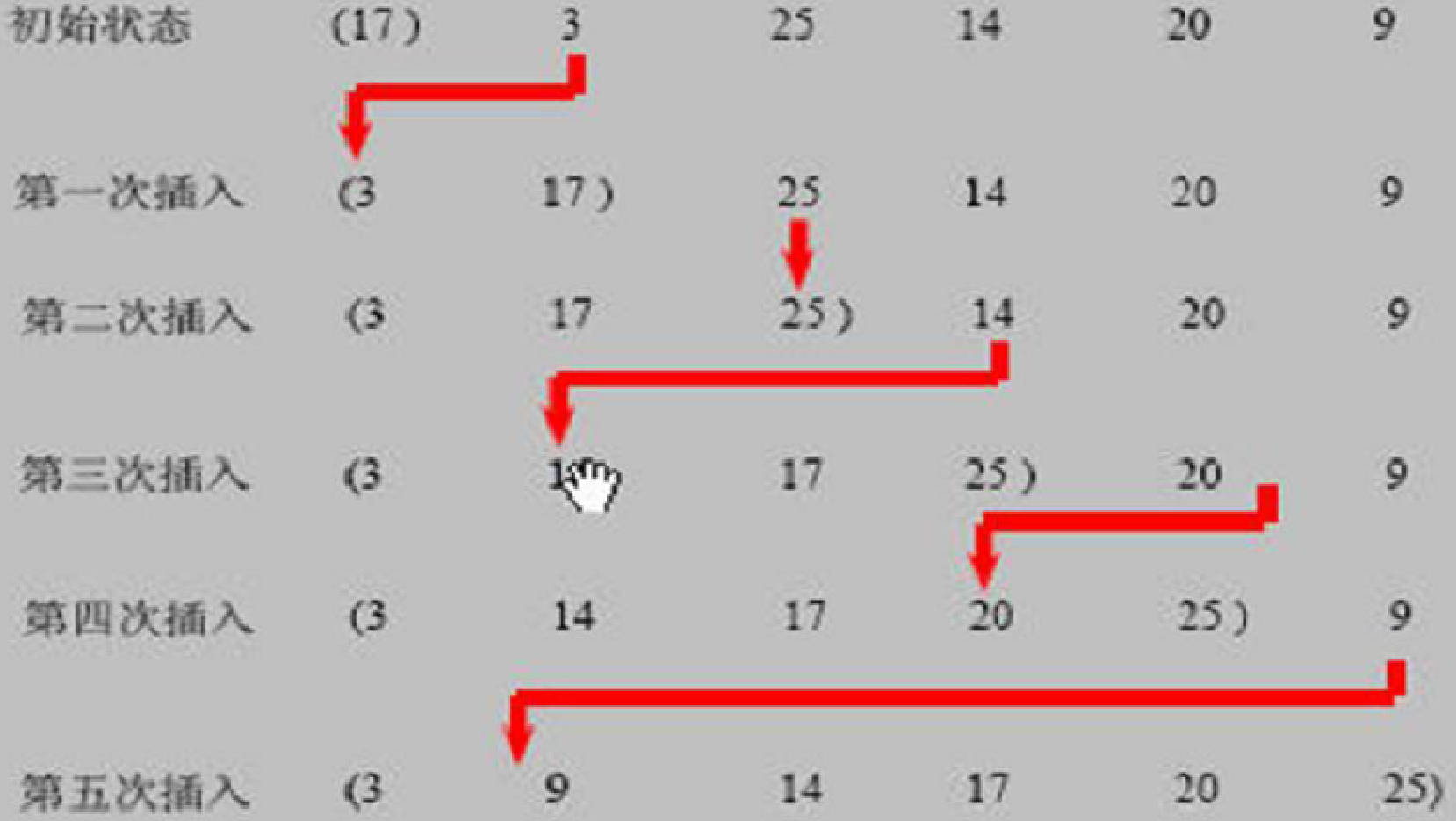
public void InserSort(int[] arr){
for (int i = 1; i < arr.length; i++) {
int insertVal = arr[i];//待插入左邊有序表的數
int left_index = i - 1;//左邊有序表的索引,初值為有序表最右數的索引
while (left_index >= 0 && insertVal < arr[left_index]) {//不斷遍歷左邊的有序表進行比較
arr[left_index + 1] = arr[left_index];//比較過的值右移
left_index--;//索引-1,繼續比較
}
if (left_index + 1 != i)
arr[left_index + 1] = insertVal;
}
}
- 時間復雜度:O(n^2)
- 不穩定
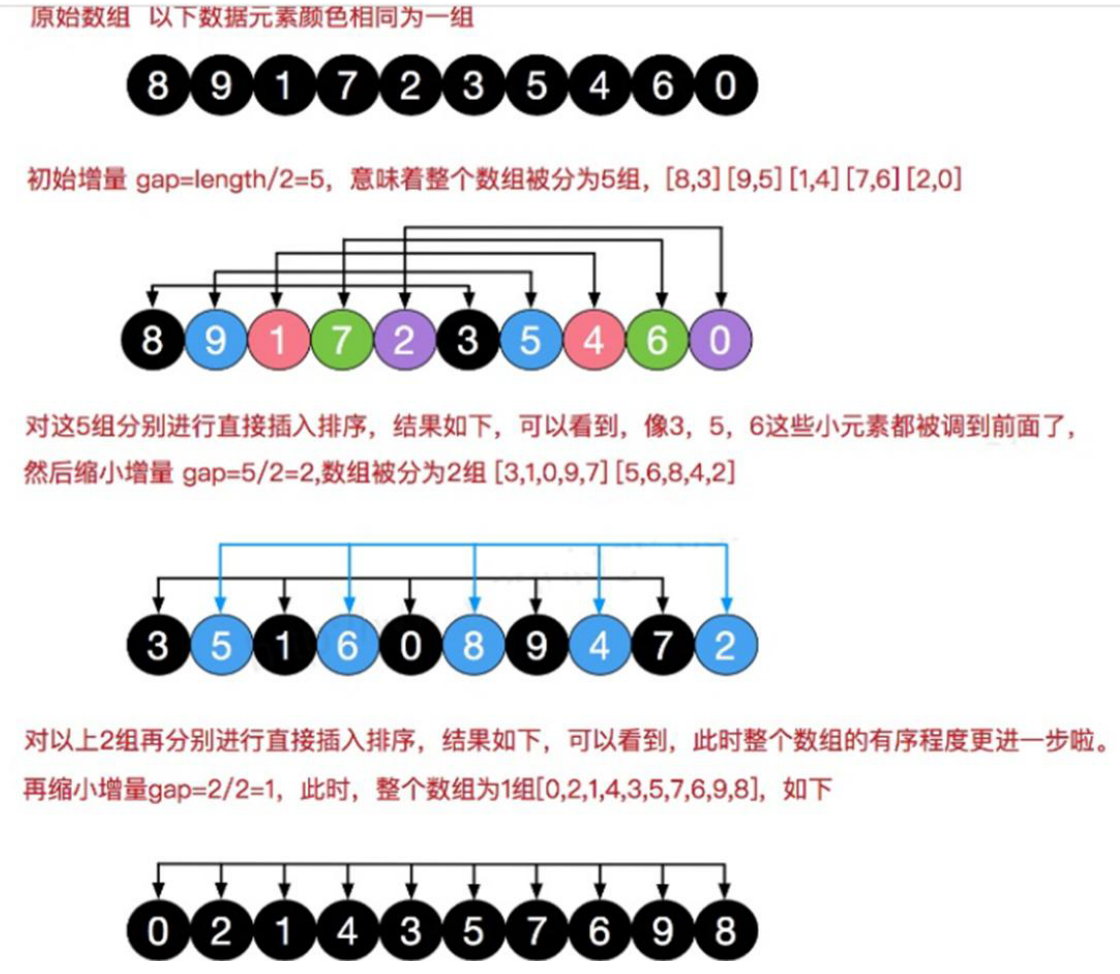
6. 插入排序——希爾排序
簡單的插入排序可能存在的問題:當需要插入的數是較小的數時,后移的次數明顯增多,對效率有影響
# 比如陣列 arr = {2,3,4,5,6,1} 這時需要插入的數 1(最小),這樣的程序是 {2,3,4,5,6,6} {2,3,4,5,5,6} {2,3,4,4,5,6} {2,3,3,4,5,6} {2,2,3,4,5,6} {1,2,3,4,5,6}為了改進,提出了希爾排序演算法:
希爾排序是希爾(Donald Shell)于 1959 年提出的一種排序演算法,希爾排序也是一種插入排序,它是簡單插入排序經過改進之后的一個更高效的版本,也稱為縮小增量排序

//交換式
public void shellSort(int[] arr){
for(int gap=arr.length/2;gap>0;gap/=2){ //步長gap逐次遞減
for(int i=gap;i<arr.length;i++){
for(int j=i-gap;j>=0;j-=gap){
if(arr[j]>arr[j+gap]){
int t=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=t;
}
}
}
}
}
//改進成移位法
public void shellSort(int[] arr){
for (int gap = arr.length / 2; gap > 0; gap /= 2) {//步長gap逐次遞減
for (int i = gap; i < arr.length; i++) {
int left_index = i - gap;//左邊有序表的索引,初值為有序表最右數的索引
int insertVal = arr[i];//要插入的值
while (left_index >= 0 && insertVal < arr[left_index]) {
arr[left_index + gap] = arr[left_index];//比較過的值右移
left_index -= gap;
}
arr[left_index + gap] = insertVal;
}
}
}
- 時間復雜度:O(nlog2n)
- 不穩定
7. 歸并排序
歸并排序(MERGE-SORT)是利用歸并的思想實作的排序方法,該演算法采用經典的分治策略(divide-and-conquer)
- 分治法將問題分(divide)成一些小的問題然后遞回求解
- 而治(conquer)的階段則將分的階段得到的各答案"修補"在一起,即分而治之
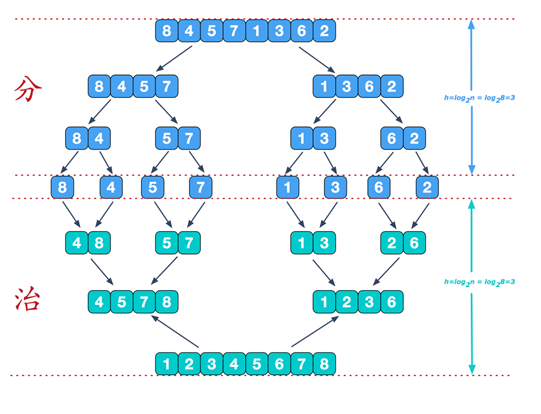
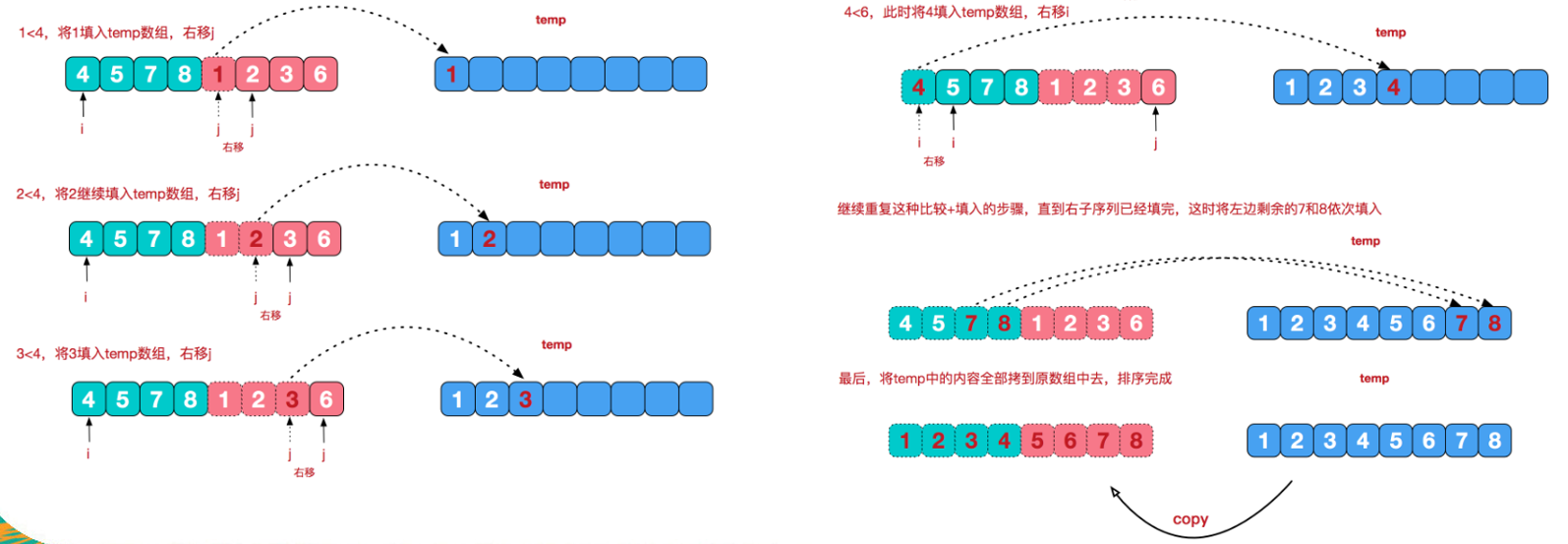
再來看看治階段,我們需要將兩個已經有序的子序列合并成一個有序序列,比如上圖中的最后一次合并,要將[4,5,7,8]和[1,2,3,6]兩個已經有序的子序列,合并為最終序列[1,2,3,4,5,6,7,8],來看下實作步驟
左邊序列和右邊序列分別有一個索引指向第一個元素,然后進行比較,較小的元素存入一個臨時陣列temp,較小元素邊序列索引右移,以此往復不斷比較存入,直到一邊的索引走到該子序列的最后;然后將有剩余資料的序列的剩余值直接按序存入temp陣列中;
最后所有元素都存入臨時陣列temp中,此時temp陣列中的元素有序
最后將temp陣列拷貝回原陣列,即實作了排序
package test;
import java.util.*;
public class Main {
public static void main(String[] args) {
int[] arr = {8, 10, -1, 6, 7, 3, 0, 40, 70};
int[] temp = new int[arr.length];//歸并排序需要額外的空間
mergeSort(arr, 0, arr.length - 1, temp);
System.out.println(Arrays.toString(arr));
}
//分+合方法
public static void mergeSort(int[] arr, int left, int right, int[] temp) {
if (left < right) {
int mid = (left + right) / 2;//中間索引
mergeSort(arr, left, mid, temp);//向左遞回分解
mergeSort(arr, mid + 1, right, temp);//向右遞回分解
merge(arr, left, mid, right, temp);//合并
}
}
//合并方法
public static void merge(int[] arr, int left, int mid, int right, int[] temp) {
int i = left;//i為指向左邊序列第一個元素的索引
int j = mid + 1;//j為指向右邊序列第一個元素的索引
int t = 0;//指向臨時temp陣列的當前索引
//先把左右兩邊有序資料按規則存入temp陣列中,直到有一邊的資料全部填充temp中
while (i <= mid && j <= right) {
if (arr[i] <= arr[j]) {
temp[t] = arr[i];
t++;
i++;
} else {
temp[t] = arr[j];
t++;
j++;
}
}
//將有剩余資料的一邊全部存入temp中
while (i <= mid) {//左邊序列有剩余元素
temp[t] = arr[i];
t++;
i++;
}
while (j <= right) {//右邊序列有剩余元素
temp[t] = arr[j];
t++;
j++;
}
/**
* 將temp中的元素拷貝到arr中
* 注意:不是每次都拷貝全部元素
* 第一次:tempLeft=0,right=1
* 第二次:tempLeft=2,right=3
* 第三次:tempLeft=0,right=3
*/
t = 0;
int tempLeft = left;
while (tempLeft <= right) {
arr[tempLeft] = temp[t];
t++;
tempLeft++;
}
}
}
- 時間復雜度:O(nlog2n)
- 穩定
8. 基數排序
- 基數排序
radix sort屬于“分配式排序”(distribution sort),又稱“桶子法”(bucket sort)或bin sort,顧名思義,它是通過鍵值的各個位的值,將要排序的元素分配至某些“桶”中,達到排序的作用- 基數排序法是屬于穩定性的排序,基數排序法的是效率高的穩定性排序法
- 基數排序(Radix Sort)是桶排序的擴展
- 基數排序是 1887 年赫爾曼·何樂禮發明的,它是這樣實作的:將整數按位數切割成不同的數字,然后按每個位數分別比較,
基數排序基本思想:
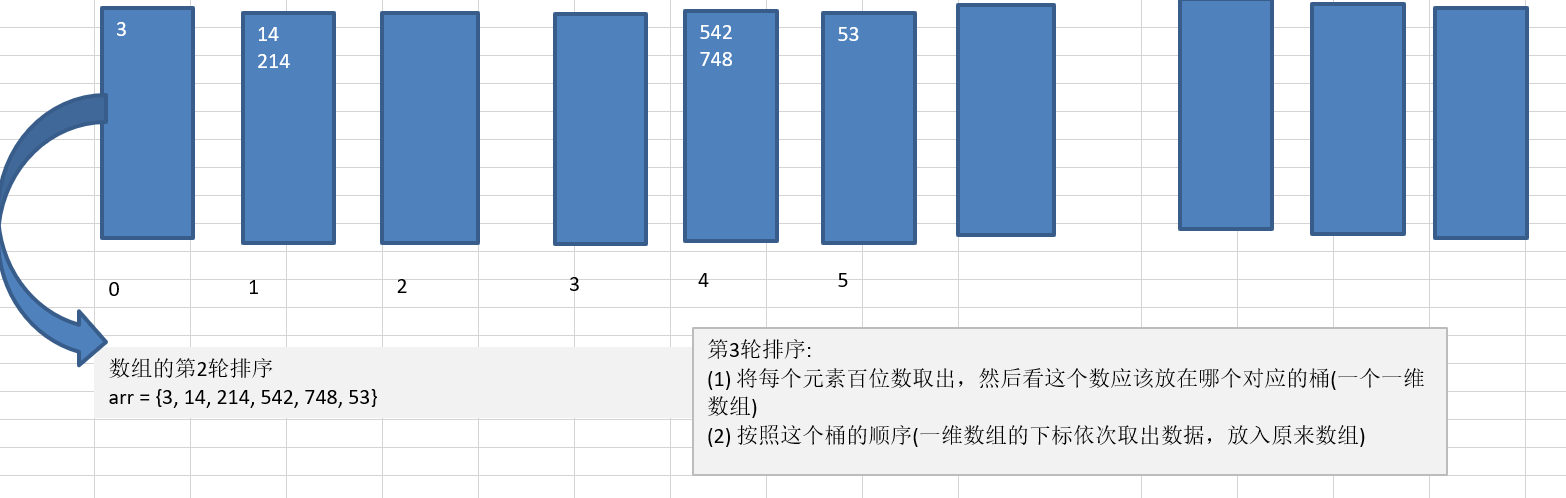
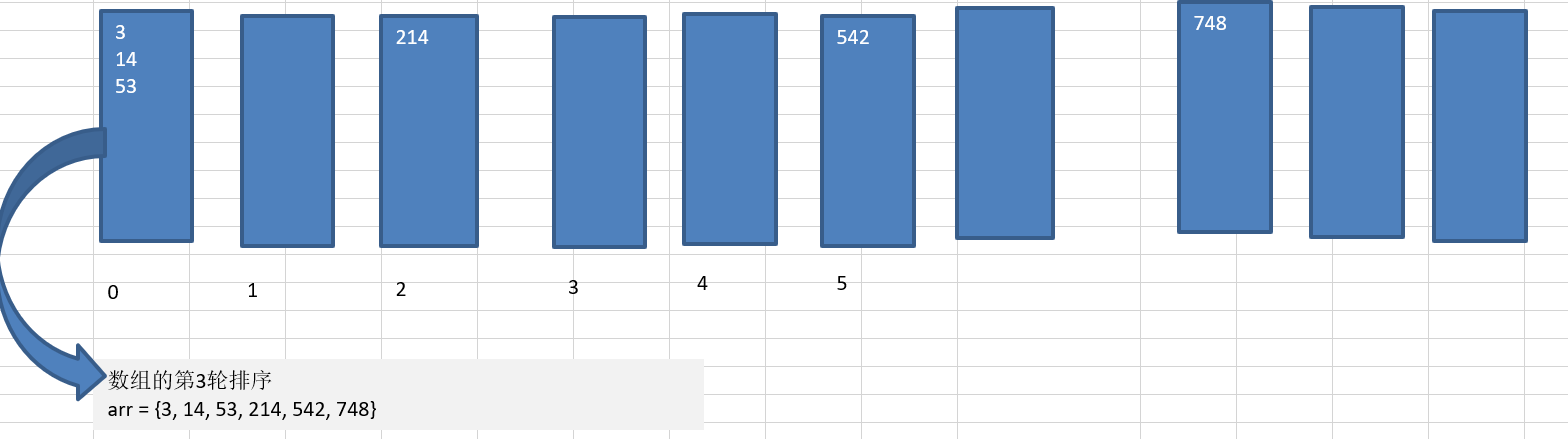
將所有待比較數值統一為同樣的數位長度,數位較短的數前面補零,然后,從最低位開始,依次進行一次排序, 這樣從最低位排序一直到最高位排序完成以后, 數列就變成一個有序序列,

package test;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] arr = {8, 10, 6, 7, 3, 0, 40, 70};
radixSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void radixSort(int[] arr) {
//定義一個二維陣列,表示10個桶,每一個桶就是一個一維陣列
int[][] bucket = new int[10][arr.length];//可能每個桶不會用滿,所以基數排序是使用空間換時間的經典演算法
//定義一個一維陣列記錄每個桶每次放入資料的個數
int[] bucketCounts = new int[10];
//找到陣列中最大數
int max = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > max)
max = arr[i];
}
//獲得最大數的位數,即為回圈的次數,也就是要判斷的總位數(個、十、百、千)
int maxLength = (max + "").length();
//針對每個元素的位進行比較
for (int c = 0, n = 1; c < maxLength; c++, n *= 10) {
for (int i = 0; i < arr.length; i++) {
//取出每個元素對應位的值(個位-->十位-->百位---)
int digit = arr[i] / n % 10;//個位:%10 十位:/10再%10 百位:/100再%10
//放入桶中
bucket[digit][bucketCounts[digit]] = arr[i];
bucketCounts[digit]++;
}
int index = 0;
//遍歷每個桶,將桶中的資料放回到原陣列
for (int j = 0; j < 10; j++) {
if (bucketCounts[j] != 0) {//如果桶不為空
for (int k = 0; k < bucketCounts[j]; k++) {
arr[index] = bucket[j][k];
index++;
}
}
bucketCounts[j] = 0;//清空每個桶的資料
}
}
}
}
負數問題:在找最大數的同時找最小值 如果最小值小于0就給每個值加上最小值的相反數,再比較
- 基數排序是對傳統桶排序的擴展,速度很快
- 基數排序是經典的空間換時間的方式,占用記憶體很大,當對海量資料排序時,容易造成
OutOfMemoryError - 基數排序時穩定的
- 有負數的陣列,我們不用基數排序來進行排序,如果要支持負數,參考: https://code.i-harness.com/zh-CN/q/e98fa9
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/279992.html
標籤:其他