談到服務器監控,大家的印象都是服務器系統性能指標監控、應用程式可用性監控等,對服務器硬體監控反而了解的比較少,今天我們就來探討一下,
大綱:
1. 選擇采集工具
2. 建立監控模板
3. 設計架構
4. 保障時效
1、選擇采集工具(監控工具)
服務器自帶一個管理芯片BMC,它會收集硬體的資訊和日志,并監控硬體的狀態,如何獲取硬體這些資訊,目前一般有三種方式,Redfish、SNMP和IPMI,我們將三種方式從難度程度、作業量、兼容性、安全性等多個維度做了對比,對比詳請如下:
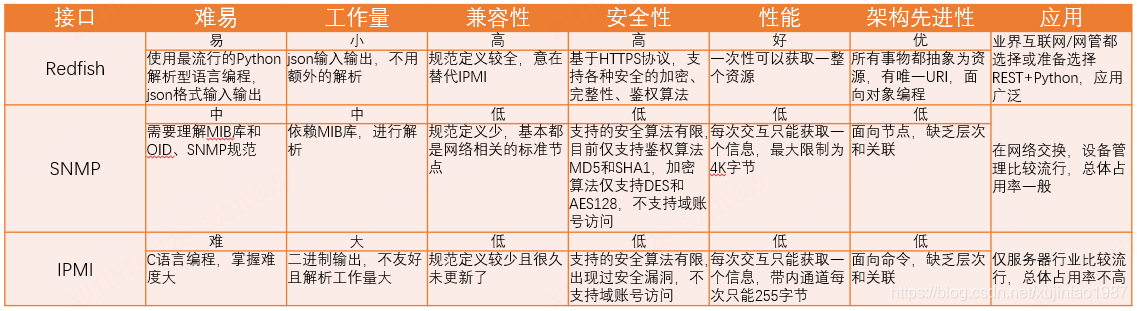
圖一:Redfish、SNMP和IPMI對比圖
經比較,最終確認了采用通過Redfish的方式來進行資料采集,不僅僅是因為其易于呼叫且回傳值較為友好,還因為其支持介面定制,Redfish是2014年提出來的,對于不支持Redfish的機器,會繼續采用IPMI監控,所以平安云集中管理的機器都是采用這兩種采集方式,完全走帶外網路,對OS系統沒有任何影響,
這里提一句,有人會有疑問,為什么不采用SNMP協議? SNMP協議在網路設備管理上采用的比較多,為什么不能用在服務器上呢? 這樣與網路設備的監控就可以使用類似的方式,就不用重復造輪子了,這里需要說明的是SNMP協議比較依賴MIB庫和OID,相同配置的機器因廠商機型不一而硬體模塊的OID不一,相同的機型因硬體配置不一而OID不一,變數較大,監控模板會很多,不易管理,而網路設備大多數都是以整機出售的,變化就比較小,監控模板不會很多,容易管理,
2、建立監控模板
除了工具,監控項也是需要確認的,需要監控哪些硬體,然后把它做成統一的模板,經過和同事們的好幾輪討論,最終的監控項如下圖示:
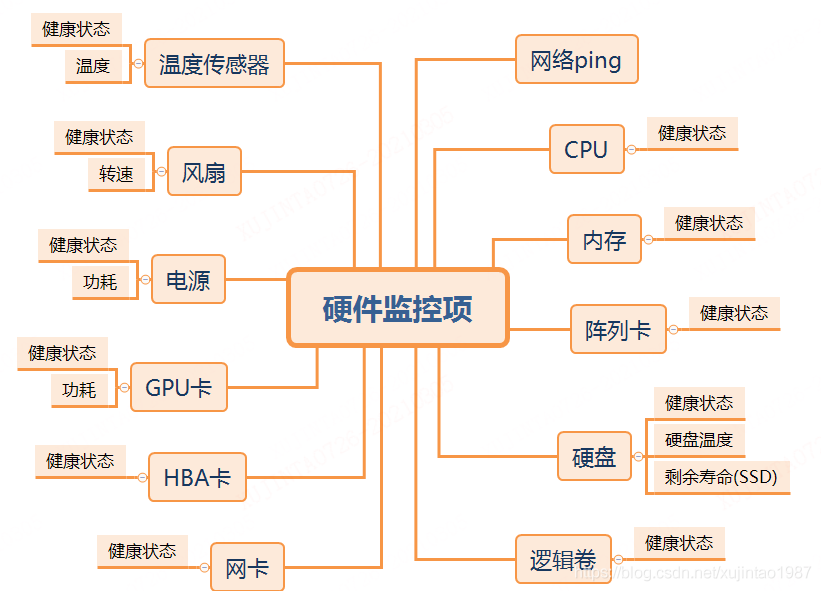
圖二:硬體監控模板
優點是,這個模板比較通用,與服務器廠商以及服務器型號關聯不緊密,不需要區分對待,
3、設計架構
監控項和采集方式都已確認,最后要解決架構的問題,后臺總體架構會采用分布式微服務的形式,可以做到橫向擴展,分云環境可用區部署,金融云與公有云分開部署,互不干擾,單臺Proxy壓力較大的時候,可以通過增加Proxy來分壓,如下為簡單架構圖:
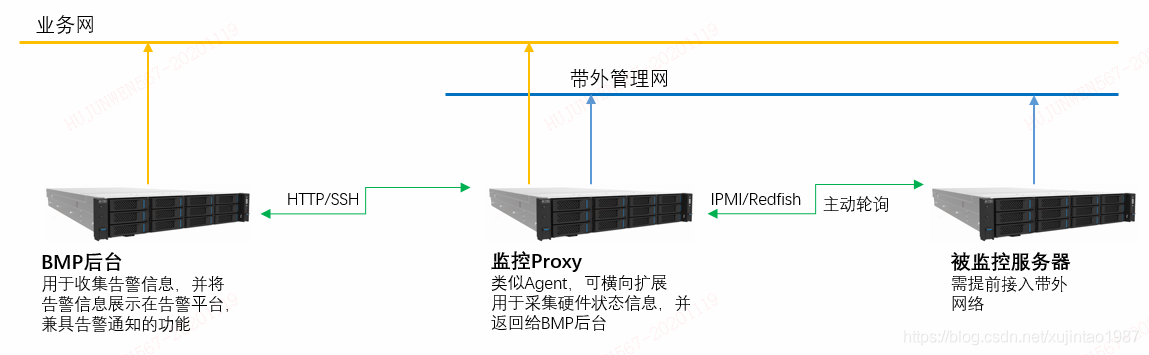
圖三:監控系統架構示意圖
監控平臺作為監控中樞,用于收集和展示告警資訊,并通知給用戶,監控Proxy主要是發起硬體狀態的采集,并回傳給平臺,本身不存盤資料,
4、保障時效
服務器數量規模一旦多起來,時效性就是個比較有挑戰性的事情,雖然監控Proxy可以擴展多臺,一定程度上可以把負載平均下去,但更需要考慮網路的問題以及BMC芯片負載的問題,一直記得曾因為大量的請求導致帶外交換機Hold不住被網路組追責的情形,而且請求太過頻繁,導致BMC Hang住,整臺機器的帶外都沒法用,所以控制一定頻率是非常有必要的,
既然加快頻率比較困難,那么就得另辟蹊徑,怎么把SNMP Trap與現有的監控形式結合,比如說一塊硬碟故障,現有技術能準確的知道硬碟的ID,槽位號、型號以及其他規格資訊,在報修時就可以直接把這些資訊發給維修人員就行,于是我在原有基礎上做了些許改造,讓SNMP Trap實時把故障上報過來,這樣時效性就能一定程度上做到提升,滿足2min之內獲取硬體故障要求,
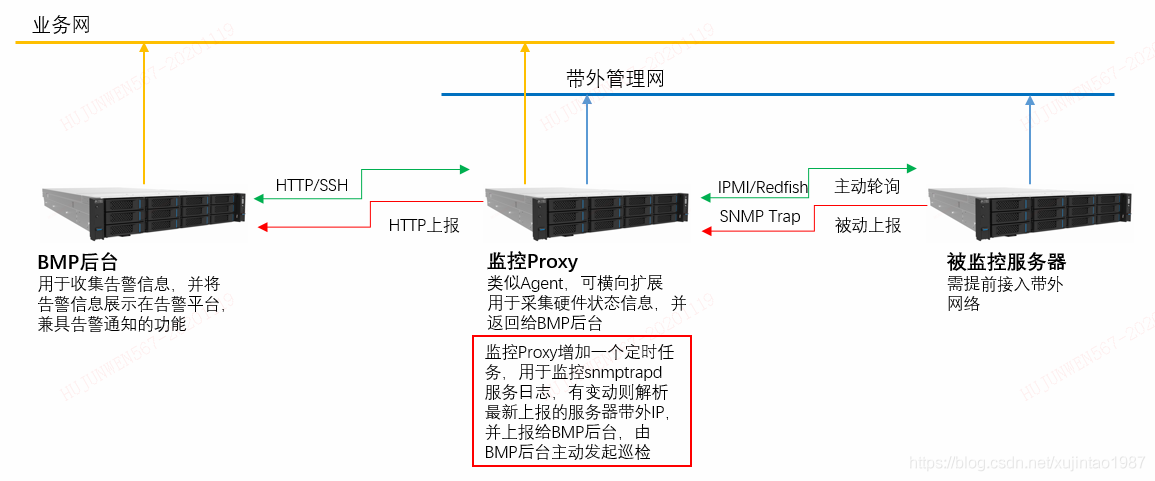
圖四:監控資訊流示意圖
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282299.html
標籤:其他