分片,Redis 資料的分布方式,分片就是將資料拆分到多個 Redis 實體,這樣每個實體將只是所有鍵的一個子集,
1 分片有什么作用?
- 分片可以讓Redis管理更大的記憶體,Redis將可以使用所有機器的記憶體,如果沒有磁區,你最多只能使用一臺機器的記憶體,
- 分片使Redis的計算能力通過簡單地增加計算機得到成倍提升,Redis的網路帶寬也會隨著計算機和網卡的增加而成倍增長,
2 分片方案
假想我們有 4 個 Redis 實體 R0,R1,R2,R3;
很多表示用戶的鍵,像 user:1,user:2等,
有如下方案可映射鍵到指定 Redis 節點,
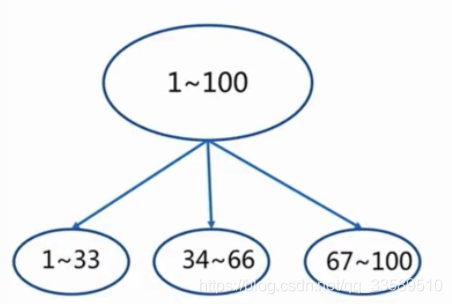
2.1 范圍分片(range partitioning)
也叫順序分片,最簡單的分片方式,通過映射物件的范圍到指定的 Redis 實體來完成分片,
例如,可假設用戶從 ID 0 ~ 10000 進入實體 R0,10001 ~ 20000 進入實體 R1,
這套辦法行得通,并且事實上在實踐中被很多人采用,
特點
- 資料分散度易傾斜
- 鍵值業務相關
- 可順序訪問
- 支持批量操作
缺點
需要一個映射范圍到實體的表格,該表需要管理,不同型別的物件都需要一個表,所以范圍分片在 Redis 中常常并不可取,因這要比其他分片可選方案低效得多,
產品
- BigTable
- HBase
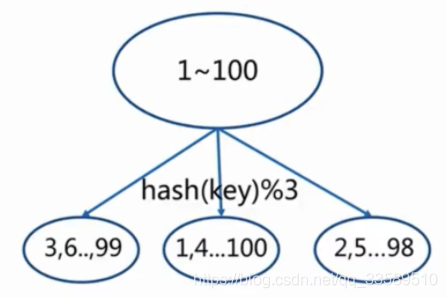
2.2 哈希分片(hash partitioning)
該模式適于任何鍵,不必是 object_name:<id> 形式,就像這樣簡單:
- 使用一個哈希函式(例如crc32) ,將key轉為一個數字,比如93024922
- 對該資料進行取模,將其轉換為一個 0 到 3 之間數字,該數字即可映射到4個 節點之一,93024922 模 4 等于 2,所以鍵 foobar 應當存盤到 R2,
分類
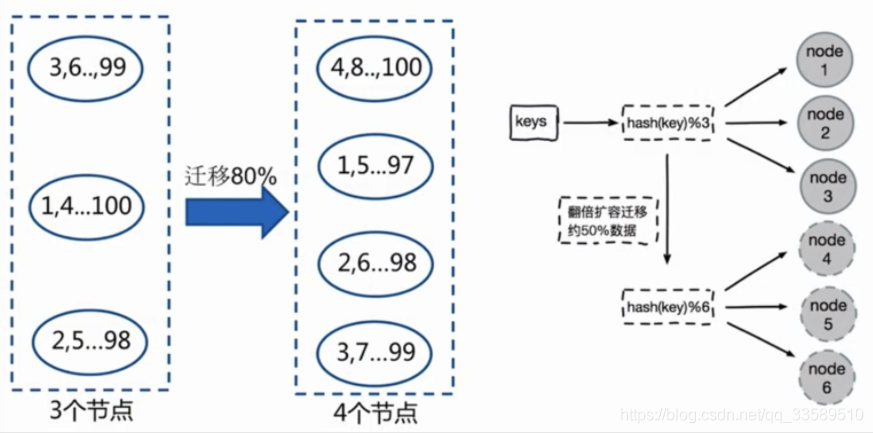
節點取余磁區
- hash(key) % nodes
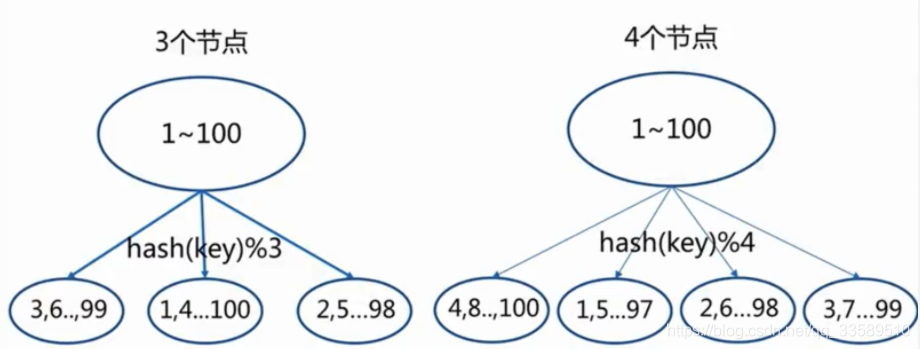
資料遷移:當添加一個節點時
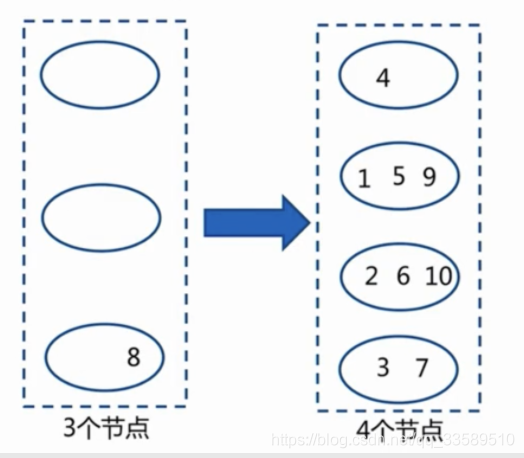
- 多倍擴容
客戶端分片:哈希+取余
節點伸縮:資料節點關系變化,導致資料遷移
遷移數量和添加節點數量有關:建議翻倍擴容
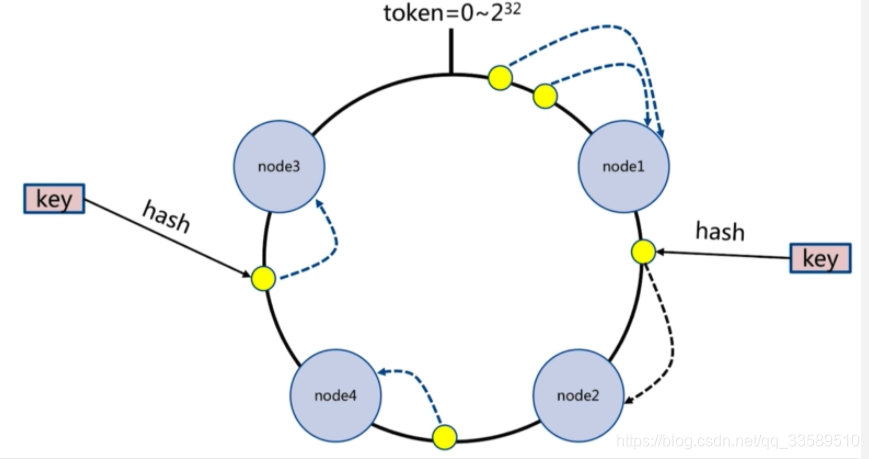
一致性哈希磁區
- 一致性哈希-擴容
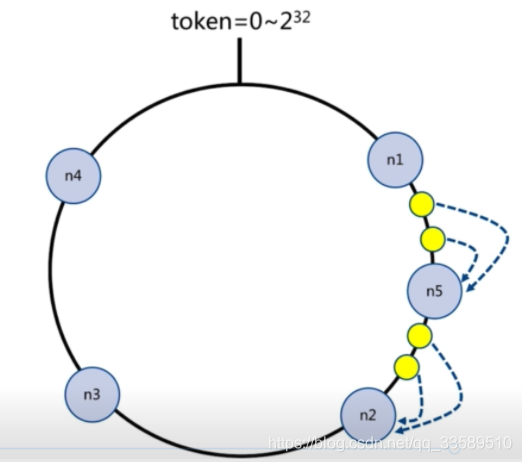
客戶端分片:哈希+順時針(優化取余)
節點伸縮:只影響鄰近節點,但還是有資料遷移
翻倍伸縮:保證最小遷移資料和負載均衡
虛擬槽哈希磁區(Redis Cluster采用)
- 虛擬槽分配
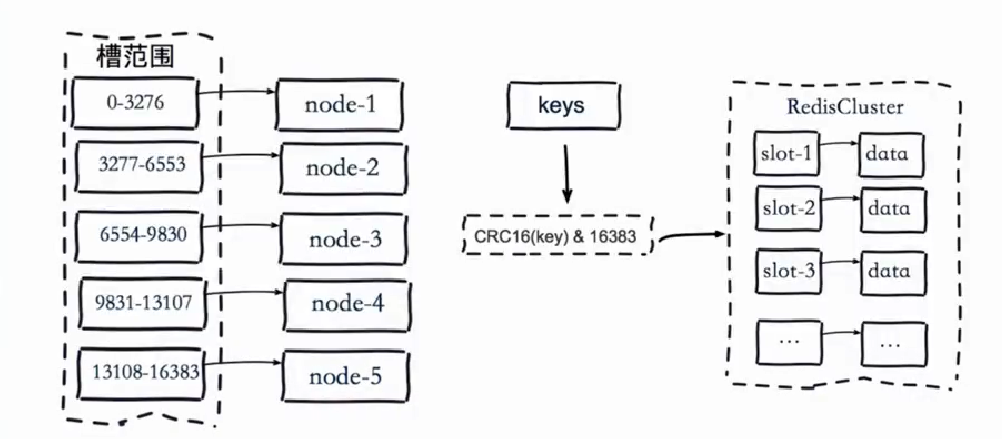
預設虛擬槽:每個槽映射一個資料子集, 一般比節點數大
良好的哈希函式:例如CRC16
服務端管理節點、槽、資料:例如Redis Cluster
特點
- 資料分散度高
- 鍵值分布業務無關
- 無法順序訪問
- 支持批量操作
產品
- 一致性哈希Memcache
- Redis Cluster
- …
哈希分片的一種高端形式稱為一致性哈希(consistent hashing),被一些 Redis 客戶端和代理實作,
3 分片的各種實作
分片可由軟體堆疊中的不同部分來承擔,
3.1 客戶端分片
客戶端直接選擇正確節點來寫入和讀取指定鍵,許多 Redis 客戶端實作了客戶端分片,
3.2 代理協助分片
客戶端發送請求到一個可以理解 Redis 協議的代理上,而不是直接發送到 Redis 實體,代理會根據配置好的分片模式,來保證轉發我們的請求到正確的 Redis 實體,并回傳回應給客戶端,
Redis 和 Memcached 的代理 Twemproxy 都實作了代理協助的分片.
3.3 查詢路由
可發送你的查詢到一個隨機實體,該實體會保證轉發你的查詢到正確節點,
Redis 集群在客戶端的幫助下,實作了查詢路由的一種混合形式,請求不是直接從 Redis 實體轉發到另一個,而是客戶端收到重定向到正確的節點,
4 分片的缺點
Redis 的一些特性與分片在一起時玩的不是很好:
- 涉及多個鍵的操作通常不支持,例如,無法直接對映射在兩個不同 Redis 實體上的鍵執行交集
- 涉及多個鍵的事務不能使用
- 分片的粒度是鍵,所以不能使用一個很大的鍵來分片資料集,例如一個很大的sorted set
- 當使用了分片,資料處理變得更復雜,例如,你需要處理多個 RDB/AOF 檔案,備份資料時需要聚合多個實體和主機的持久化檔案
- 添加和洗掉容量也很復雜,例如,Redis 集群具有運行時動態添加和洗掉節點的能力來支持透明地再均衡資料,但是其他方式,像客戶端分片和代理都不支持這個特性,但有一種稱為預分片(Presharding)的技術在這一點上能幫上忙,
5 資料存盤or快取?
盡管無論是將 Redis 作為資料存盤還是快取,Redis 分片概念上都是一樣的,
- 但作為資料存盤時有個重要局限:當 Redis 作為資料存盤時,一個給定的鍵總是映射到相同 Redis 實體,
- 當 Redis 作為快取時,如果一個節點不可用而使用另一個節點,這并不是啥大問題,按照我們的愿望來改變鍵和實體的映射來改進系統的可用性(即系統回應我們查詢的能力),
一致性哈希實作常常能夠在指定鍵的首選節點不可用時切換到其它節點,類似的,如果你添加一個新節點,部分資料就會開始被存盤到這個新節點上,
主要概念:
- 如果 Redis 用作快取,使用一致性哈希來實作伸縮擴展很容易
- 如果 Redis 用作存盤,使用固定的鍵到節點的映射,所以節點的數量必須固定不能改變,否則,當增刪節點時,就需要一個支持再平衡節點間鍵的系統,當前只有 Redis 集群可以做到這點,
6 預分片
分片存在一個問題,除非我們使用 Redis 作為快取,否則增加和洗掉節點都是件麻煩事,而使用固定的鍵和實體映射要簡單得多,
然而,資料存盤的需求可能一直在變化,今天可接受 10 個 Redis 節點,但明天可能就需 50 個節點,
因為 Redis 只有相當少的記憶體占用且輕量級(一個空閑的實體只使用 1MB 記憶體),一個簡單的解決辦法是一開始就開啟很多實體,即使你一開始只有一臺服務器,也可以在第一天就決定生活在分布式世界,使用分片來運行多個 Redis 實體在一臺服務器上,
你一開始就可以選擇很多數量的實體,例如,32 或者 64 個實體能滿足大多數用戶,并且為未來的增長提供足夠的空間,
這樣,當資料存盤增長,需要更多 Redis 服務器,你要做的就是簡單地將實體從一臺服務器移動到另外一臺,當你新添加了第一臺服務器,你就需要把一半的 Redis 實體從第一臺服務器搬到第二臺,以此類推,
使用 Redis 復制,就可以在很小或者根本不需要停機的時間內完成移動資料:
- 在新服務器上啟動一個空實體
- 移動資料,配置新實體為源實體的從服務
- 停止客戶端
- 更新被移動實體的服務器 IP 地址配置
- 向新服務器上的從節點發送 SLAVEOF NO ONE 命令
- 以新的更新配置啟動你的客戶端
- 最后關閉掉舊服務器上不再使用的實體
7 Redis分片實作
探討完 Redis 分片理論,如何實踐呢?又應該使用什么系統呢?
7.1 Redis 集群
Redis 集群是自動分片和高可用的首選方式,一旦 Redis 集群以及支持 Redis 集群的客戶端可用,Redis 集群將會成為 Redis 分片的事實標準,
Redis 集群是查詢路由和客戶端分片的一種混合模式,
7.2 Twemproxy
Twemproxy 是 Twitter 開發的一個支持 Memcached ASCII 和 Redis 協議的代理,它是單執行緒的,由 C 語言撰寫,運行非常快,基于 Apache 2.0 許可證,
Twemproxy 支持在多個 Redis 實體間自動分片,若節點不可用,還有可選的節點排除支持,
這會改變 <鍵,實體> 映射,所以應該只在將 Redis 作為快取是才使用該特性,
這并非單點故障,因為你可啟動多個代理,并且讓你的客戶端連接到第一個接受連接的代理,
從根本上說,Twemproxy 是介于客戶端和 Redis 實體之間的中間層,這就可以在最下的額外復雜性下可靠地處理我們的分片,這是當前建議的處理 Redis 分片的方式,
7.3 支持一致性哈希的客戶端
Twemproxy 之外的可選方案,是使用實作了客戶端分片的客戶端,通過一致性哈希或者別的類似演算法,有多個支持一致性哈希的 Redis 客戶端,例如 Redis-rb 和 Predis,
查看完整的 Redis 客戶端串列,看看是不是有支持你的編程語言的,并實作了一致性哈希的成熟客戶端即可~
參考
- https://redis.io/topics/partitioning
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282337.html
標籤:其他
上一篇:你不知道的無人機知識(建議收藏)
下一篇:C++執行緒 linux