一.概述
Mysql可以分為Server層和存盤引擎兩部分
下面的是mysql的邏輯架構圖
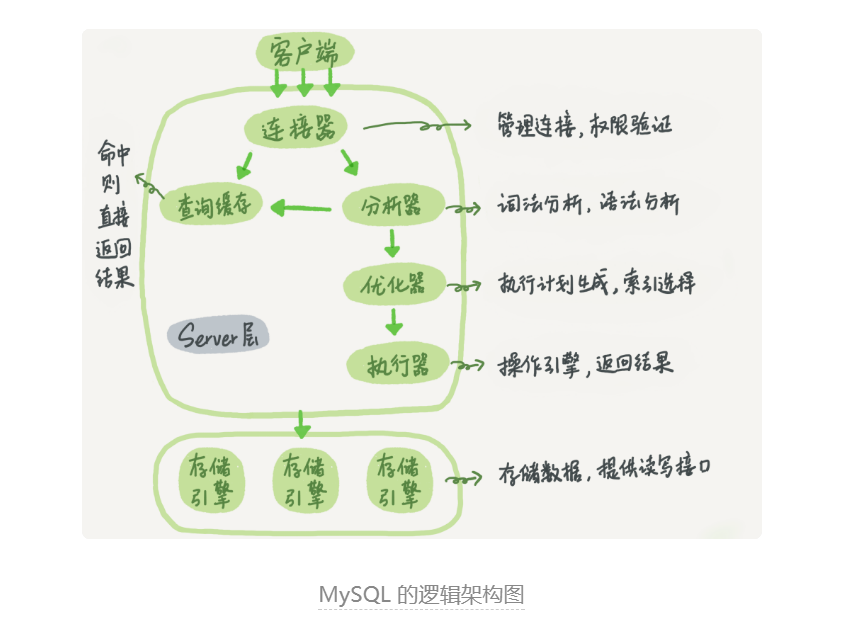
1.Server 層包括連接器、查詢快取、分析器、優化器、執行器等,涵蓋 MySQL 的大多數核心服務功能,以及所有的內置函式(如日期、時間、數學和加密函式等),所有跨存盤引擎的功能都在這一層實作,比如存盤程序、觸發器、視圖等,且****不同的存盤引擎共用一個Server層
2.存盤引擎層負責資料的存盤和提取,其架構模式是插件式的,支持 InnoDB、MyISAM、Memory 等多個存盤引擎,現在最常用的存盤引擎是 InnoDB,它從 MySQL 5.5.5 版本開始成為了默認存盤引擎,
補充:(插件式的架構模式)
插件(Plugin)模式向用戶提供了一種擴展程式的介面,用戶可以在程式本體之外,按照指定介面撰寫插件來為程式增加功能,

二.Server層組件介紹
以下面這句sql陳述句為例,看看sql陳述句是如何執行的
select * from T where ID=10;
1.連接器
①連接器負責和客戶端建立連接、獲取權限、維持和管理連接
②連接命令如下,密碼雖然可以直接跟在-p后面,但是會造成密碼泄露所以不要這樣做,輸入下面的命令后會額外讓你輸入密碼
mysql -h$ip -P$port -u$user -p
- 如果用戶名或密碼不對,你就會收到一個"Access denied for user"的錯誤,然后客戶端程式結束執行,
- 如果用戶名密碼認證通過,連接器會到權限表里面查出你擁有的權限,之后,這個連接里面的權限判斷邏輯,都將依賴于此時讀到的權限,
(獲取權限這點尤其注意一下,因為在連接器處獲取權限,所以后面管理員就算進行了權限修改,不能立即生效,要等下次連接的時候才能生效)
③連接完成后,如果你沒有后續的動作,這個連接就處于空閑狀態,你可以在 show processlist 命令中看到它,文本中這個圖是 show processlist 的結果,其中的 Command 列顯示為“Sleep”的這一行,就表示現在系統里面有一個空閑連接,
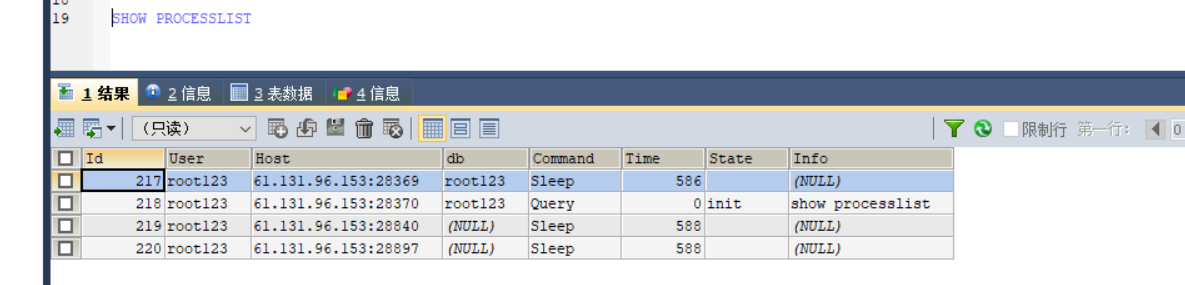
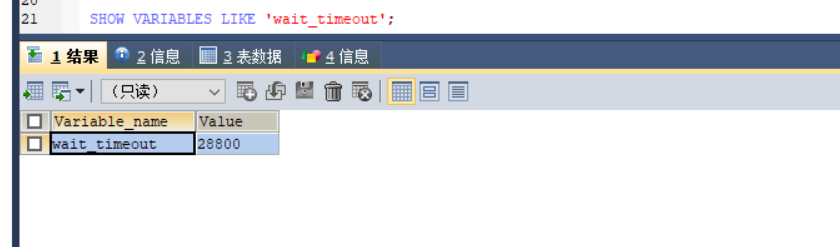
其中wait_timeout這個值控制最大空閑時間,默認8小時,超過這個時間連接會自動斷開,自動斷開連接后要重連才能成功發送請求
④資料庫中長連接和短連接的概念
- 長連接是指連接成功后,如果客戶端持續有請求,則一直使用同一個連接,
- 短連接則是指每次執行完很少的幾次查詢就斷開連接,下次查詢再重新建立一個,
因為建立資料庫連接較為復雜,一般建議盡量使用長連接,
但使用長連接非常占用記憶體,這是因為 MySQL 在執行程序中臨時使用的記憶體是管理在連接物件里面的,這些資源會在連接斷開的時候才釋放,所以如果長連接累積下來,可能導致記憶體占用太大,被系統強行殺掉(OOM),從現象看就是 MySQL 例外重啟了,
解決方案:
①定期斷開長連接,使用一段時間,或者程式里面判斷執行過一個占用記憶體的大查詢后,斷開連接,之后要查詢再重連,
②如果你用的是 MySQL 5.7 或更新版本,可以在每次執行一個比較大的操作后,通過執行 mysql_reset_connection 來重新初始化連接資源,這個程序不需要重連和重新做權限驗證,但是會將連接恢復到剛剛創建完時的狀態,
2.查詢快取
(mysql8.0已經洗掉了查詢快取,這部分了解一下就好)
2.1.在mysql拿到一個查詢請求后,會先去查詢快取里找,快取中有key-value對形式的資料,key是sql陳述句,value是結果,如果能找到就回傳結果,找不到就執行后面階段(到分析器),執行結果會被存在查詢快取
2.2但是多數情況下并不建議用查詢快取,因為非常容易失效,弊端如下:
①一張表只要更新查詢快取就會被清空(這點就足夠致命)
②除非是一張靜態表,否則查詢快取命中率非常低
2.3mysql(8.0之前的版本)支持手動開啟查詢快取

3.分析器
①先進行詞法分析,對sql陳述句字串中每個詞進行分析分別表示什么,比如select,就表示是查詢陳述句
②接著進行語法分析,根據詞法分析的結果,語法分析器會根據語法規則,判斷你輸入的這個 SQL 陳述句是否滿足 MySQL 語法,
在分析器中,會先進行一次precheck權限驗證,驗證是否有對這個表進行操作的權限,但是precheck是無法對運行時涉及到的表進行權限驗證的,所以下面執行器里還有一次驗證
小結:分析器是讓mysql知道自己要做什么
4.優化器
優化器是在表里面有多個索引的時候,決定使用哪個索引;或者在一個陳述句有多表關聯(join)的時候,決定各個表的連接順序,比如你執行下面這樣的陳述句,這個陳述句是執行兩個表的 join:
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;

這里要注意:并不是誰t1寫在前面就先查t1,而是要讓優化器去選依照怎樣的執行順序效率最高
小結:優化器負責sql陳述句的執行方案,也就是知道該怎么做
5.執行器
①開始執行的時候,要先判斷一下你對這個表 T 有沒有執行查詢的權限,如果沒有,就會回傳沒有權限的錯誤,
查詢也會在優化器之前(也就是分析)呼叫 precheck 驗證權限,而precheck是無法對運行時涉及到的表進行權限驗證的,比如使用了觸發器的情況,因此在執行器這里也要做一次執行時的權限驗證,
(疑惑:為什么不能在分析器里一次驗證完呢)
②如果有權限就打開表,然后根據表的引擎定義去使用這個引擎提供的介面
(所以到了執行的時候才會進入到資料庫引擎,然后執行器也是通過呼叫資料庫引擎的API來進行資料操作的,也因此資料庫引擎才會是插件形式的)
③對于開始的那個sql陳述句,如果沒有索引,就會一行一行地進行取資料還有判斷,符合條件的放到結果集
對于有索引的表,執行的邏輯也差不多,第一次呼叫的是“取滿足條件的第一行”這個介面,之后回圈取“滿足條件的下一行”這個介面,這些介面都是引擎中已經定義好的,
下面是關于慢查詢日志的補充(疑惑:我還不懂下面這段話什么意思):
你會在資料庫的慢查詢日志中看到一個 rows_examined 的欄位,它的數值和執行器的呼叫次數有關,一般要少于引擎掃描的行數 (這個比較好理解)
慢查詢日志的概念,簡單來說就是記錄超時的sql(慢日志的具體使用見另一條博客筆記)

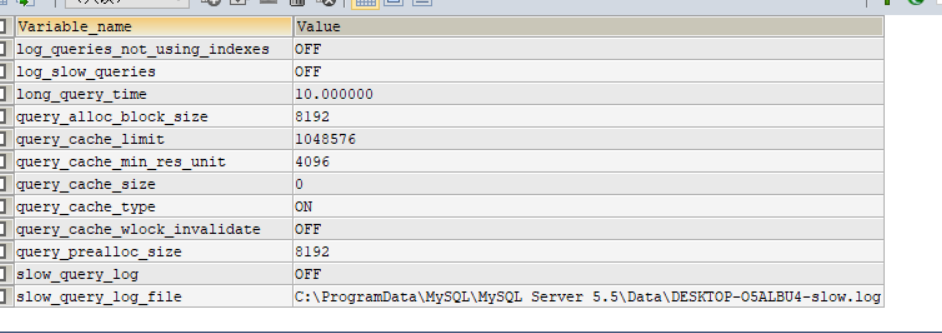
執行下面這行代碼可以找到慢查詢日志的位置
SHOW VARIABLES LIKE '%quer%';
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/282601.html
標籤:其他